关于Adaboost算法的部分学习
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
比如目前火热的人脸识别技术,为了达到提高人脸检测的准确率的目的,采用adaboost算法训练出的人脸最优分类器对待测图像进行人脸检测,对检测出的人脸候选矩形区域adaboost算法训练出的人眼最优分类器进行人眼检测,进一步确定人脸候选矩形是否真的含有人脸对象,即基于Adaboost人眼检测的人脸检测算法。
Adaboost算法的特点:
Aadboost 算法系统具有较高的检测速率,且不易出现过适应现象。但是该算法在实现过程中为取得更高的检测精度则需要较大的训练样本集,在每次迭代过程中,训练一个弱分类器则对应该样本集中的每一个样本,每个样本具有很多特征,因此从庞大的特征中训练得到最优弱分类器的计算量增大。典型的Adaboost 算法采用的搜索机制是回溯法,虽然在训练弱分类器时每一次都是由贪心算法来获得局部最佳弱分类器,但是却不能确保选择出来加权后的是整体最佳。在选择具有最小误差的弱分类器之后,对每个样本的权值进行更新,增大错误分类的样本对应的权值,相对地减小被正确分类的样本权重。且执行效果依赖于弱分类器的选择,搜索时间随之增加,故训练过程使得整个系统的所用时间非常大,也因此限制了该算法的广泛应用。另一方面,在算法实现过程中,从检测率和对正样本的误识率两个方面向预期值逐渐逼近来构造级联分类器,迭代训练生成大量的弱分类器后才能实现这一构造过程。由此推出循环逼近的训练分类器需要消耗更多的时间。 ——————《百度百科》
相关符号定义:
D(i):训练样本集的权值分布;
w:每个训练样本的权值大小;
h:弱分类器;
H:基本分类器;
H:最终的强分类器;
e:误差率;
α:弱分类器的权值;
Adaboost算法流程:
(1)首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权值: w=1/N, 这样训练样本集的初始权值分布D1(i):
(2进行迭代t=1,….,T
(a)选取一个当前误差率最低的弱分类器h作为第t个基本分类器Ht,并
计算弱分类器h:X→{-1,1},该弱分类器在分布Dt上的误差为:
PS:由上述式子可知,Ht(x)在训练数据集上的误差率e就是被H(x)误分类**
(b)计算该弱分类器在最终分类器中所占的权重(弱分类器权重用a表示) :
(c)更新训练样本的权值分布D: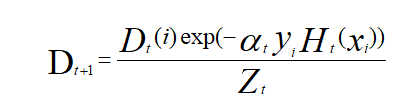
其中Z为归一化常数
(3) 最后,按弱分类器权重a组合各个弱分类器,即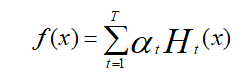
通过符号函数sign的作用,得到一个强分类器为:

若有收获,就点个赞吧
0 人点赞
