一、Hbase基础
HBase的特点
- 海量存储
- 底层基于HDFS存储海量数据
- 列式存储
- HBase表的数据是基于列族进行存储的,一个列族包含若干列
- 极易扩展
- 底层依赖HDFS,当磁盘空间不足的时候,只需要动态增加DataNode服务节点就可以
- 高并发
- 支持高并发的读写请求
- 稀疏
- 稀疏主要是针对HBase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
- 数据的多版本
- HBase表中的数据可以有多个版本值,默认情况下是根据版本号去区分,版本号就是插入数据的时间戳 (timestamp)
- 数据类型单一
- 所有的数据在HBase中是以字节数组进行存储
HBase的应用
HBase适合海量明细数据的存储,并且后期需要有很好的查询性能(单表超千万、上亿,且并发要求高)
HBase数据模型
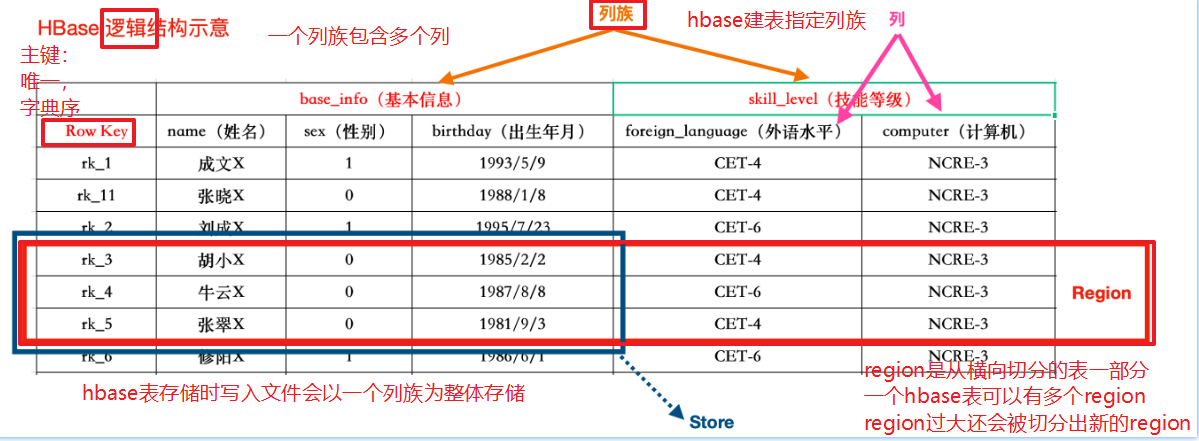
逻辑结构
物理结构【实际】
核心结构:
- RowKey
- 每行数据主键,唯一,字典顺序存储
- ColumnFamily
- 列族,info
- ColumnQualifier
- 列,依赖于列族存在。info:name, info:age
- TimeStamp
- 时间戳,数据的版本
- Cell
- 一个列可以存储多个版本的数据,每个版本为一个Cell
- Region
- 按照rowkey划分,不能跨RegionServer
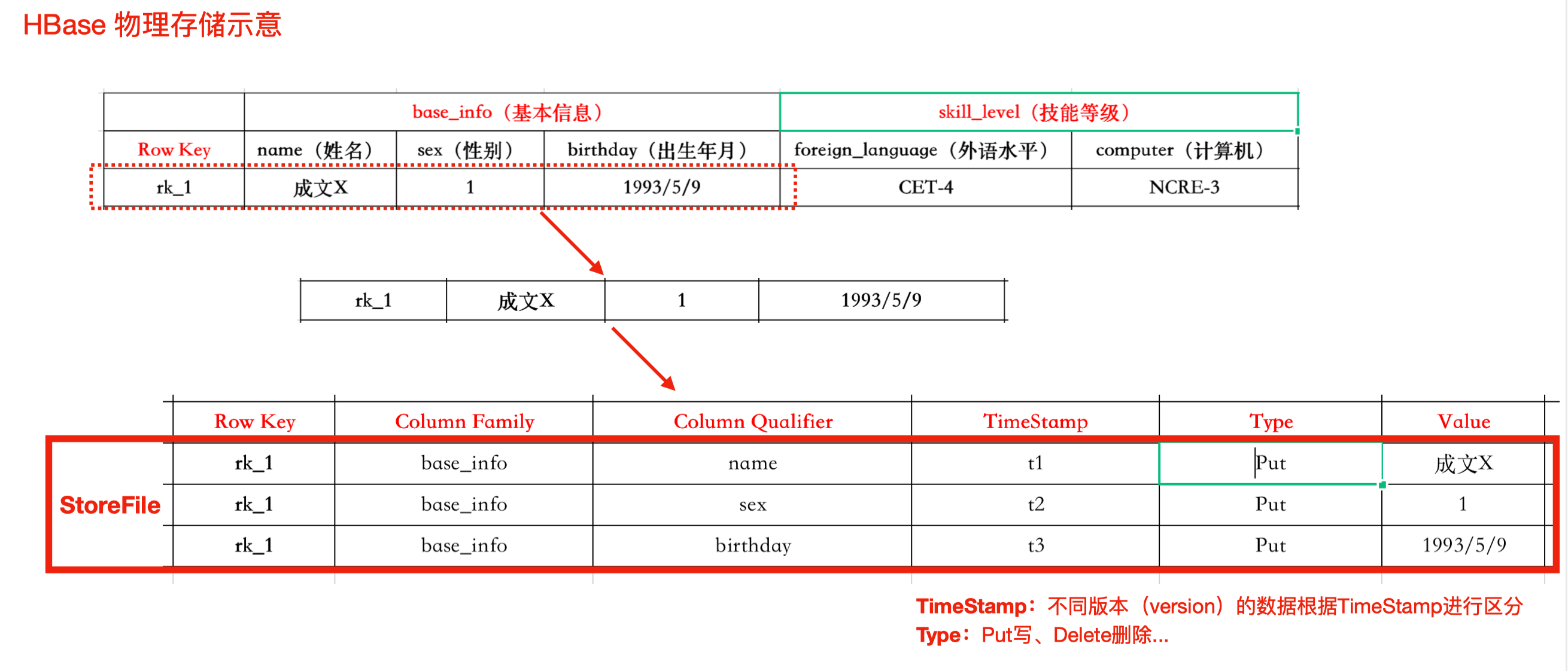
注意
- 每条数据对应一次操作(对列族中的某一列)。
- 每个store保存一个列族。
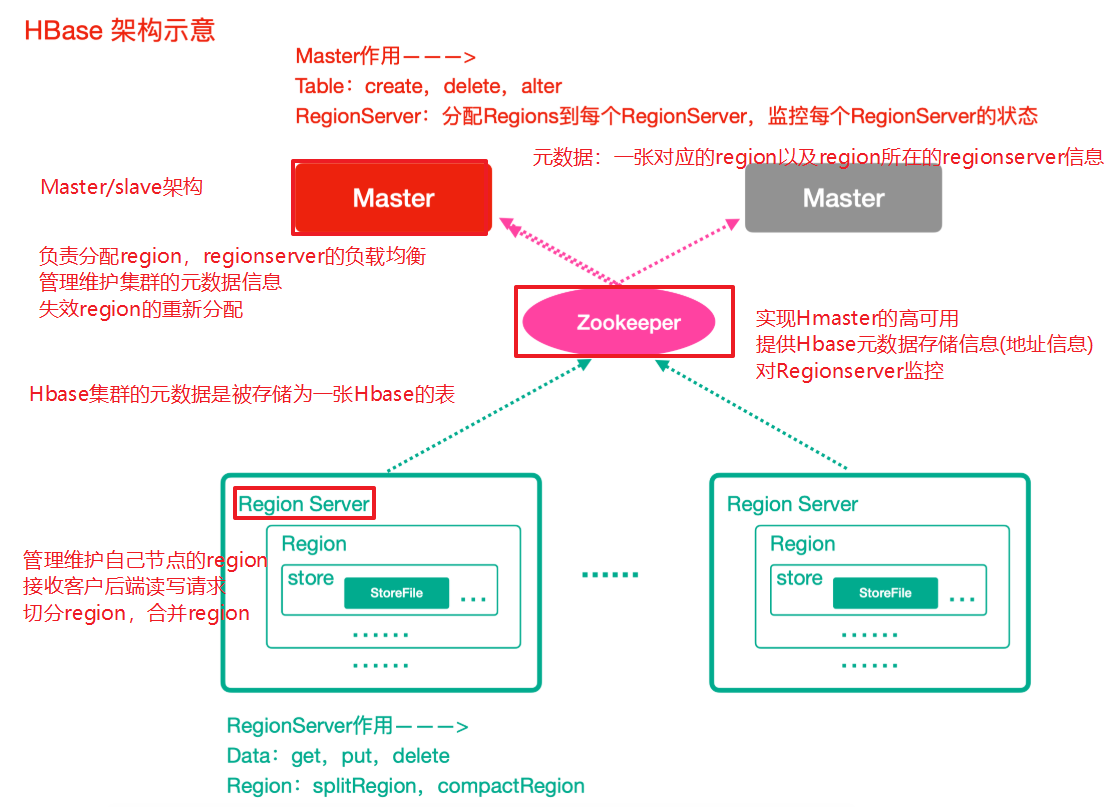
Hbase整体架构
- Zookeeper
- 实现了HMaster的高可用
- 保存了HBase的元数据信息,是所有HBase表的寻址入口
- 对HMaster和HRegionServer实现了监控
- HMaster(Master)
- 为HRegionServer分配Region ,维护整个集群的负载均衡
- 维护集群的元数据(表的位置等,)信息
- 发现失效的Region,并将失效的Region分配到正常的HRegionServer上
- HRegionServer(RegionServer)
- 负责管理Region
- 接受客户端的读写数据请求
- 切分在运行过程中变大的Region
- Region
- 每个HRegion由多个Store构成
- 每个Store保存一个列族(Columns Family),表有几个列族,则有几个Store
- 每个Store由一个MemStore和多个StoreFile组成,MemStore是Store在内存中的内容,写到文件
后就是StoreFile。StoreFile底层是以HFile的格式保存(MemStore(内存) = StoreFile(文件))
HBase shell 基本操作
详见讲义
二、HBase原理深入
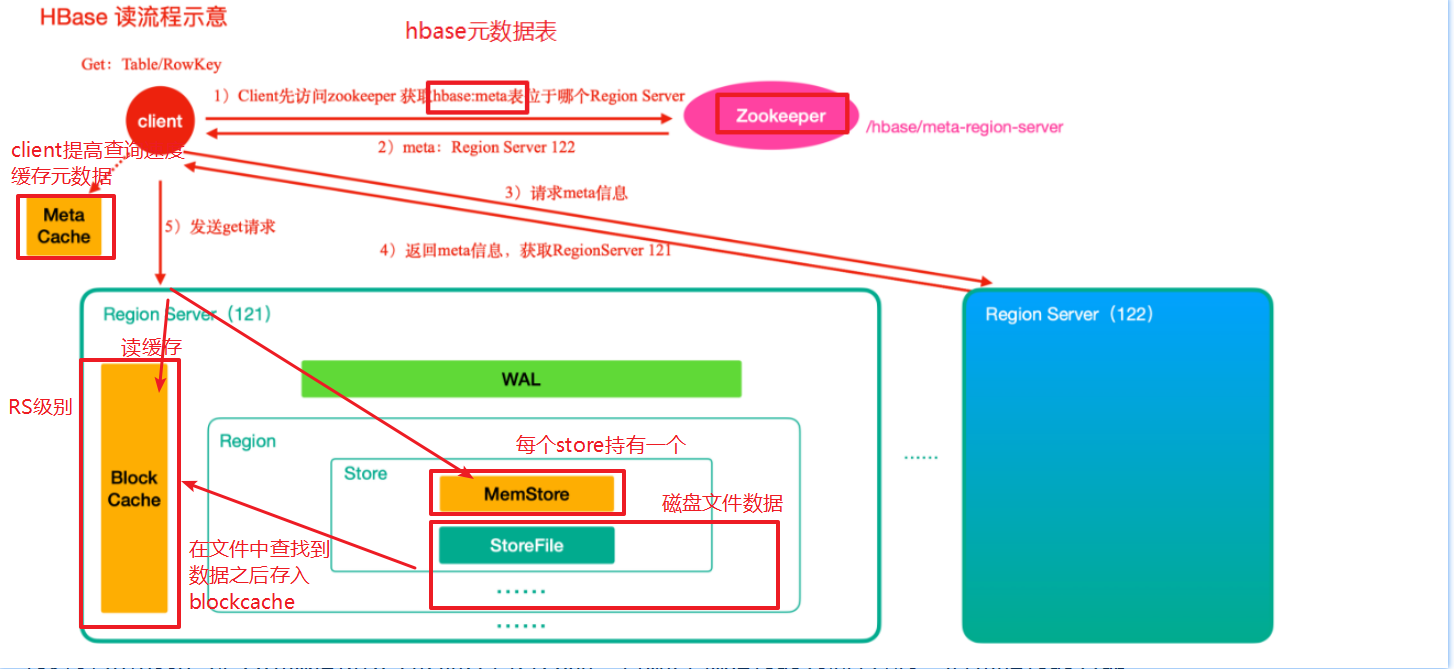
读数据流程
zk -> meta表 -> namespace,table,rowkey -> region -> region server -> memstore,blockcahe ->storefile -> blockcache
- 访问Zookeeper,找到存放hbase的元数据hbase:meta表的位置(位于其中的一个服务器上linux122)
- 访问linux122,获取meta表信息,根据要查询的namespace(数据库)、表名(table)和rowkey(主键)信息,找到对应的region信息
- 根据region信息找到对应的Region Server(linux121)
- 访问Region Server(linux121)
- 先从menstore查找数据,否则从BlockCache上读取
- 如果BlockCache中也没有找到,再到StoreFile上进行读取 (从storeFile中读取到数据之后,不是直接把结果数据返回给客户端,而是把数据先写入到BlockCache中,目的是为了加快后续的查询;然后在返回结果给客户端。 )
- HBase上Regionserver的内存分为两个部分 :
- 一部分作为Memstore,主要用来写数据;
- 另外一部分作为BlockCache,主要用于读数据 ;
写数据流程
- 首先从zk找到meta表的region位置 (linux122)
- 然后读取meta表中的数据,meta表中存储了用户表的region信息
- 根据namespace、表名和rowkey信息。找到写入数据对应的region信息
- 找到这个region对应的regionServer (linux121),然后发送请求
- 把数据分别写到HLog(write ahead log)和memstore各一份
- memstore达到阈值后把数据刷到磁盘,生成storeFile文件
- 删除HLog中的历史数据
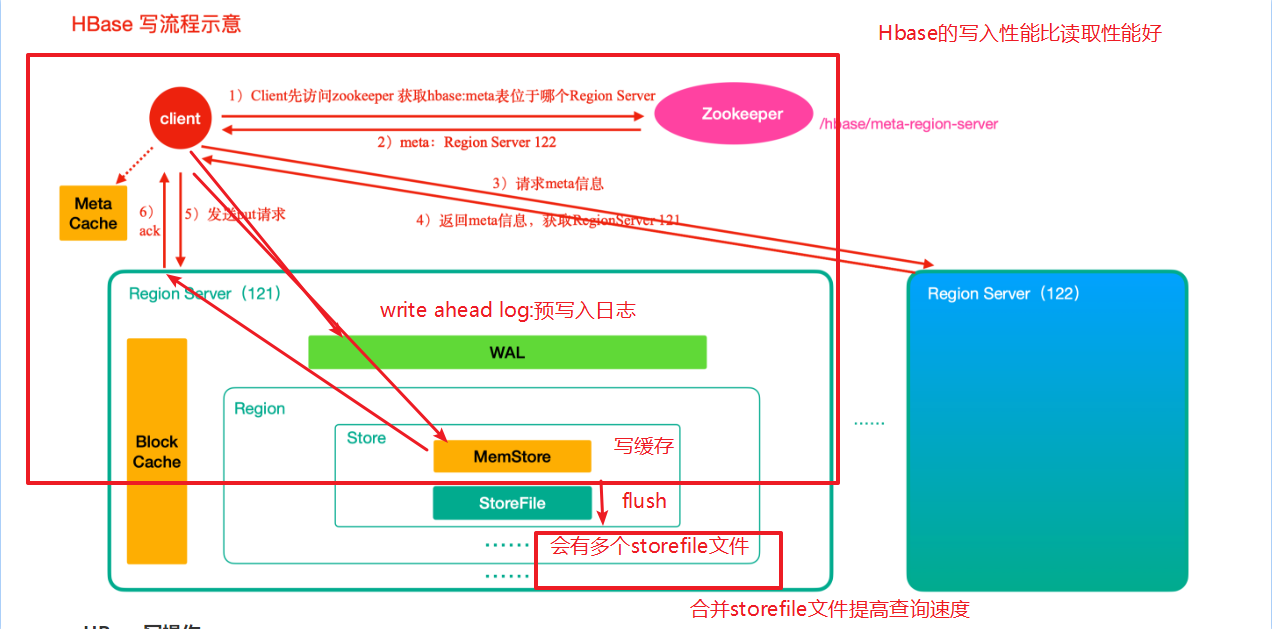
region server中的三个模块:
- block cache : 读缓存
- 读的时候,先找
- memstore:写缓存
- store file:磁盘文件
Flush(刷写)及Compact(合并)机制
Flush机制
1)当memstore的大小超过这个值的时候,会flush到磁盘,默认为128M
2)当memstore中的数据时间超过1小时,会flush到磁盘
3)HregionServer的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大
小的40%
4)手动flush :flush tableName
阻塞机制
Hbase周期性检查是否满足以上memstore刷写标准,满足 则进行刷写 。但是,在下次周期性检查之前,数据疯狂写入Memstore中 ?
会触发阻塞机制,此时无法写入数据到Memstore,数据无法写入Hbase集群。
Compact合并机制
minor compact 小合并
- 将Store中多个HFile(StoreFile)合并为一个HFile (没有物理移除)
minor compact文件选择标准
合并Store中所有的HFile为一个HFile
- 真正移除,默认7天执行一次(建议手动,取消自动7天)
Region 拆分机制
1.ConstantSizeRegionSplitPolicy
(0.94版本前默认切分策略 )
当region大小大于某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region
2.IncreasingToUpperBoundRegionSplitPolicy

3.SteppingSplitPolicy
(2.0版本默认切分策略 )
只有第一次阈值为size*2,之后都按照最大划分
默认size =128m
如果region个数等于1,切分阈值为flush size * 2 (256mb),否则为MaxRegionFileSize。这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region(256,2048…),而是适可而止。
表的预分区(region)
防止一个表刚创建的时候,所有读写请求都访问同一个regionServer的同一个region 。
- 增加数据读写效率
- 负载均衡,防止数据倾斜
- 方便集群容灾调度region
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护
Region 合并
冷合并
热合并
三、Hbase优化
协处理器 Coprocessor
将业务运算代码封装到Coprocessor中并在RegionServer上运行,即在数据实际存储位置执行,最后将运算结果返回到客户端。利用协处理器,用户可以编写运行在 HBase Server 端的代码。 (移动代码 替代 移动数据)
协处理器类型
- Observer

- Endpoint

RowKey设计
- RowKey长度原则
- RowKey散列原则
- RowKey唯一原则
-
热点
检索habse的记录首先要通过row key来定位数据行。当大量的client访问hbase集群的一个或少数几个节点,造成少数region server的读/写请求过多、负载过大,而其他region server负载却很小,就造成了“热点”现象 。
解决: 预分区
- 加盐
- 给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同
- 哈希
- 哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
- 反转
- 牺牲了rowkey的有序性
二级索引
- HBase表按照rowkey查询性能是最高的。rowkey就相当于hbase表的一级索引!!
- hbase的二级索引其本质就是建立hbase表中列与行键之间的映射关系。
常见的二级索引我们一般可以借助各种其他的方式来实现,例如Phoenix或者solr或者ES等
布隆过滤器
应用:
之前再讲hbase的数据存储原理的时候,我们知道hbase的读操作需要访问大量的文件,大部分的实现通过布隆过滤器来避免大量的读文件操作。
- Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。
- 布隆过滤器返回true,在结果不一定正确(存在重复现象),如果返回false则说明确实不存在
原理示意图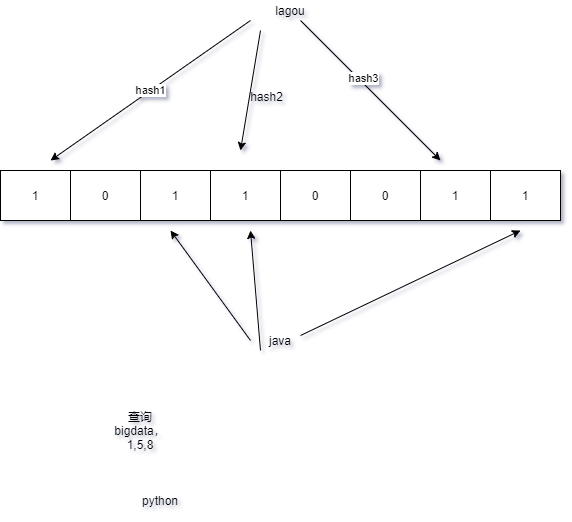

若有收获,就点个赞吧
0 人点赞
