一、会员活跃度分析
第2节 日志数据采集
taildir source特点:
- 使用正则表达式匹配目录中的文件名
- 监控的文件中,一旦有数据写入,Flume就会将信息写入到指定的Sink
- 高可靠,不会丢失数据
- 不会对跟踪文件有任何处理,不会重命名也不会删除
不支持Windows,不能读二进制文件。支持按行读取文本文件
HDFS Sink 都会采用滚动生成文件的方式,滚动生成文件的策略有:
基于时间。hdfs.rollInterval 30秒
- 基于文件大小。hdfs.rollSize 1024字节
- 基于event数量。hdfs.rollCount 10个event
- 基于文件空闲时间。hdfs.idleTimeout 0
- 基于HDFS文件副本数:minBlockReplicas。默认值与 hdfs 副本数一致。设为1是为了让 Flume 感知不到hdfs的块复制,此时其他的滚动方式配置(时间间隔、文件大小、events数量)才不会受影响
存在的问题以及解决:Flume放数据时,使用本地时间;不理会日志的时间戳 ?
解决:使用自定义拦截器实现
- 获取 event 的 header
- 获取 event 的 body
- 解析body获取json串
- 解析json串获取时间戳
- 将时间戳转换为字符串 “yyyy-MM-dd”
- 将转换后的字符串放置header中 (为什么?)
- 返回event
日志数据采集小结
- 使用taildir source 监控指定的多个目录,可以给不同目录的日志加上不同header
- 在每个目录中可以使用正则匹配多个文件
- 使用自定义拦截器,主要功能是从json串中获取时间戳,加到event的header中
- hdfs sink使用event header中的信息写数据(控制写文件的位置)
- hdfs文件的滚动方式(基于文件大小、基于event数量、基于时间)
-
json数据处理
1、使用内建函数处理
get_json_object(string json_string, string path)
json_tuple(jsonStr, k1, k2, …)
2、使用UDF处理
3、使用SerDe处理序列化反序列化方式。
序列化是对象转换为字节序列的过程;反序列化是字节序列恢复为对象的过程。
活跃会员分析
每日活跃会员
dwd每日启动明细表 ===> 每日活跃会员
启动日志中,不同设备ID出现的次数(按照设备ID进行group by操作)
ps.Hive中在group by查询的时候要求出现在select后面的列都必须是出现在group by后面的
分区表:dt是按照日期的分区字段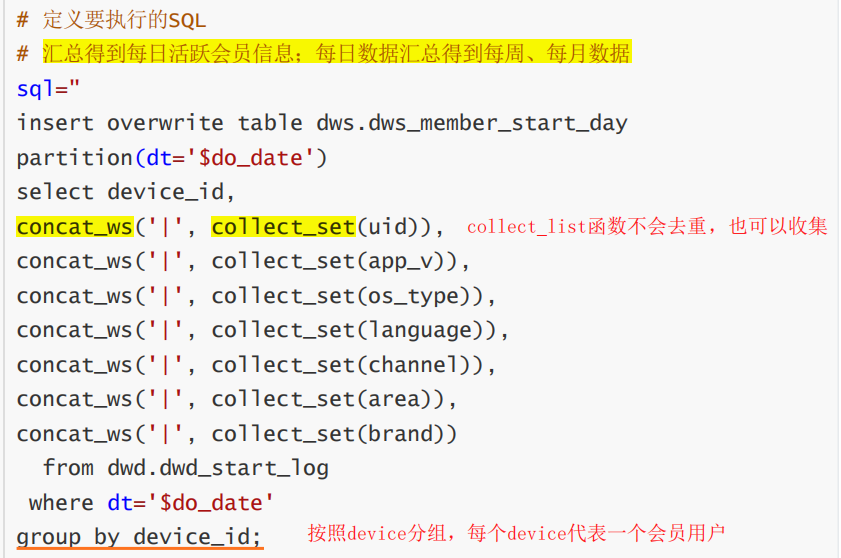
Hive操作:
collect_set,列转行,并去重
collect_list,列转行,不去重每周活跃会员(一周之内有登录即可)
每日活跃会员 => 每周活跃会员
求出下周一,减去7天 ==》本周一
- next_day可以返回指定日期之后一周中特定的日期
- 本周一到当前活跃 == 周活跃会员
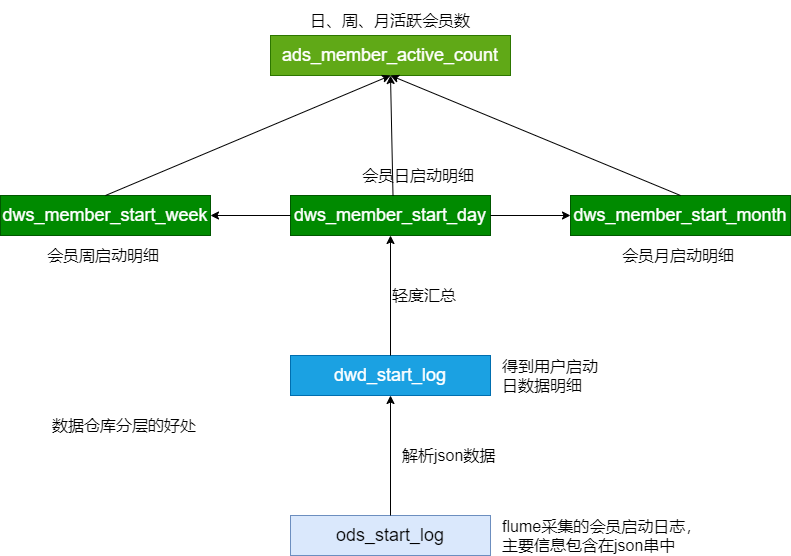

每月活跃会员
每日活跃会员 => 每月活跃会员
- 求出本月1号,到当前时间

新增会员分析

- 分析方法
- t1是每日启动表,t2是全量数据(不包含当日启动的数据)
- 最后将查询结果插入t2表中,作为新的全量数据

留存会员分析
需求:计算1日,2日,3日的会员留存数,留存率
- 核心思路
- t1日启动信息(今天),t2新增会员信息(前一天)
- where筛选:在前一天成为新增会员,且今天登陆的device_id

小结
会员活跃度—活跃会员数、新增会员、留存会员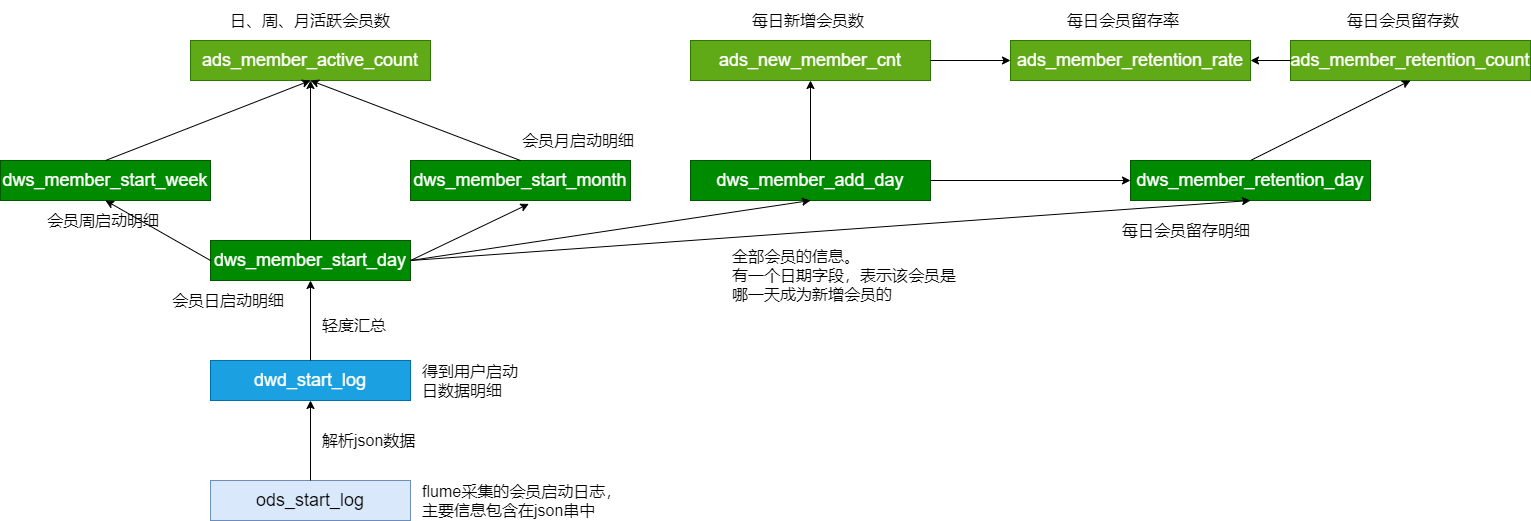
二、广告业务分析(pass)
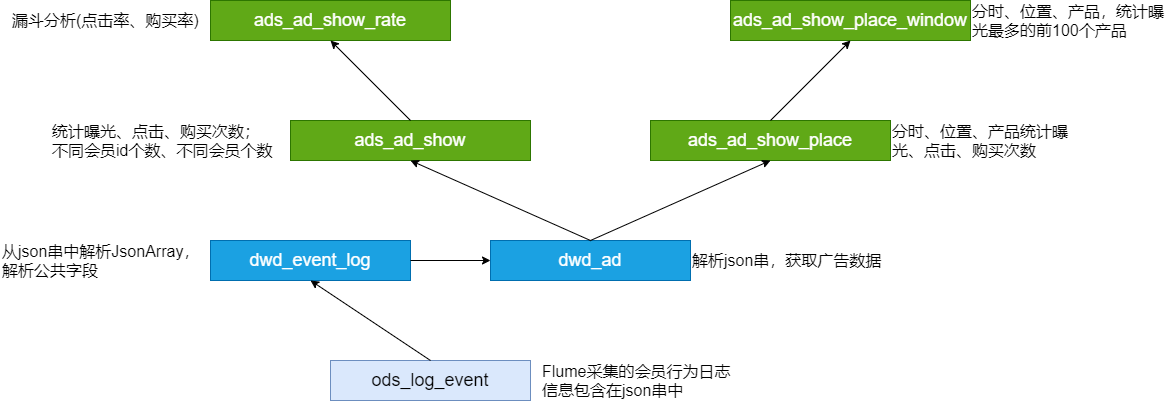
第5节 广告点击次数分析
第6节 漏斗分析(点击率购买率)
第7节 广告效果分析
三、核心交易分析
第2节 业务数据库表结构
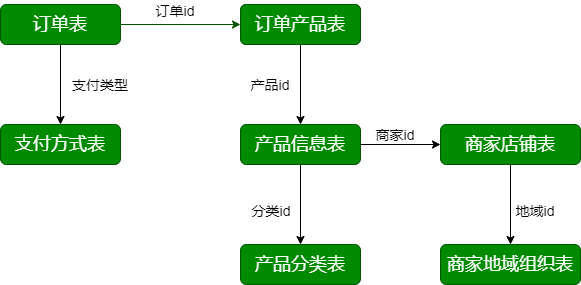
第3节 数据导入
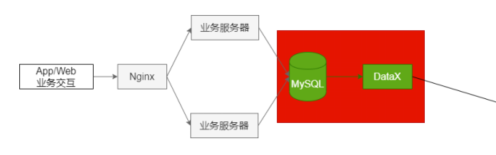
全量导入:
增量导入:
第4节 ODS层建表与数据加载
所有的表都是分区表;字段之间的分隔符为 , ;为表的数据数据文件指定了位置;
第5节 缓慢变化维与周期性事实表
缓慢变化维(SCD;Slowly Changing Dimensions)。在现实世界中,维度的属性随着时间的流失发生缓慢的变化(缓慢是相对事实表而言,事实表数据变化的速度比维度表快)。
处理缓慢变化维的方法有以下几种常见方式:
(1)保留原值
(2)直接覆盖
(3)增加新属性列
(4)快照表
每天保留一份全量数据。
适用范围:维表不能太大
使用场景多,范围广;一般而言维表都不大。 **(5)拉链表 (重点!)
拉链表适合于:表的数据量大,而且数据会发生新增和变化,但是大部分是不变的(数据发生变化的百分比不大),且是缓慢变化的(如电商中用户信息表中的某些用户基本属性不可能每天都变化)。主要目的是节省存储空间。
适用场景:
表的数据量大
表中部分字段会被更新
表中记录变量的比例不高
需要保留历史信息
拉链表案例分析
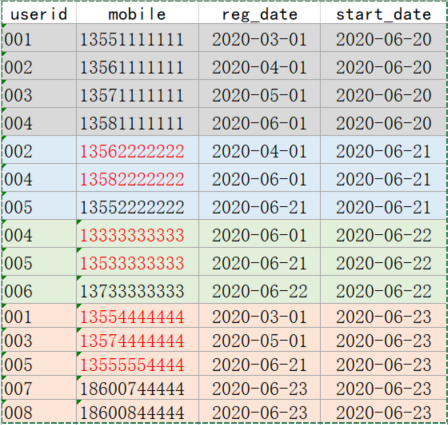
userinfo(分区表) => userid、mobile、regdate => 每日变更的数据(修改的+新增的) / 历史数据(第一天)
userhis(拉链表)=> 多了两个字段 start_date / end_date
步骤:
- userinfo初始化(2020-06-20)。获取历史数据
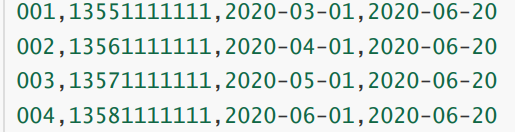
- 初始化拉链表(2020-06-20)。userinfo (从info表中导入)=> userhis

- 次日新增数据userinfo(dt = 2020-06-21);获取新增数据

- 构建拉链表(userhis)(2020-06-21)【最最核心】
userinfo(2020-06-21) + userhis(旧) => userhis(新)
— userinfo: 当日更新的数据(出现过的数据的修改+新增数据)
— userhis:历史数据
新增数据全部加入,并增加start_date和end_date字段,变为拉链表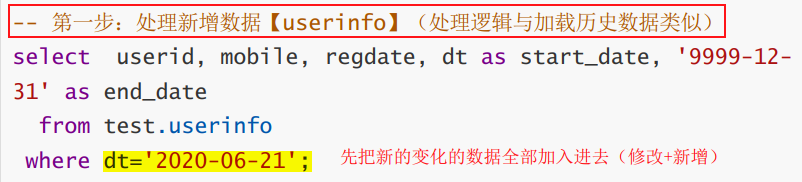
处理结果: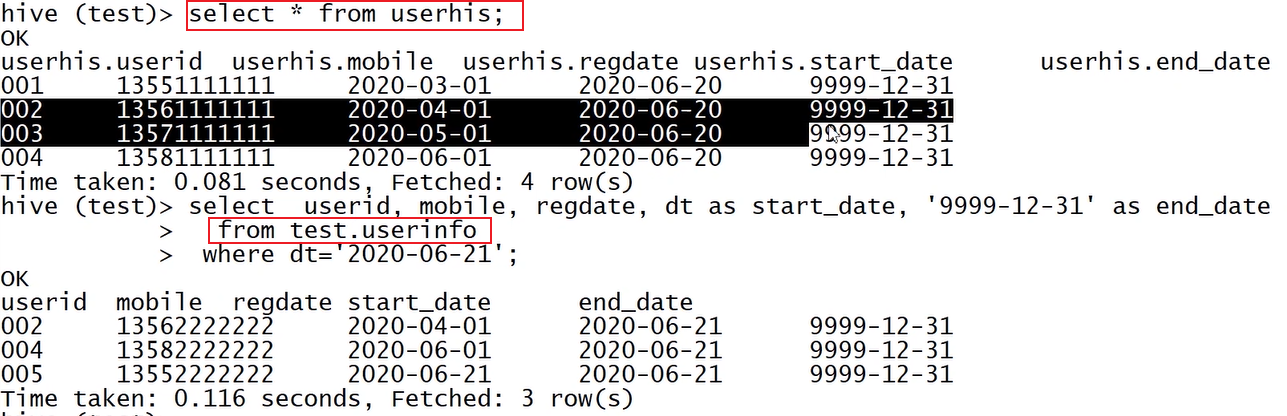

历史数据应该出现在
—变化的:【userhis】+【userinfo(更新)】 userinfo(dt = 2020-06-01) right join userhis
—不变的:【userhis】,不做处理
right join结果分析:
如果链接结果不为null,说明数据发生变化,将旧数据的(userhis,B表)的end_date改为当前日期-1
连接结果为null,说明数据没有变化,end_date不变
5. 最终的处理(新增+历史数据)
实现第四步两个结果的union all 操作,并 insert overwrite 进新的拉链表中(userhis)。
select * from userhis cluster by userid,start_date;
案例总结
- 初始化,将第一天的表增加start_date和end_date字段,做成拉链表userhis【旧】
- 第二天的新增数据表,userinfo处理
- userinfo中的全部数据,是userhis【新】的一部分
- userinfo right join userhis【旧】
- 连接结果不为null,说明数据发生变化,将旧数据的(userhis,B表)的end_date改为当前日期-1
- 连接结果为null,说明数据没有变化,end_date不变
- union all a和b的结果,insert overwrite 进入userhis【新】,拉链表得到更新
insert overwrite table test.userhisselect userid, mobile, regdate, dt as start_date, '9999-12- 31' as end_datefrom test.userinfowhere dt='2020-06-21'
union all
select B.userid,B.mobile,B.regdate,B.start_Date,case when B.end_date='9999-12-31' and A.userid is not nullthen date_add('2020-06-21', -1) // 日期-1else B.end_date // 还是原来的end_date,不变end as end_datefrom (select * from test.userinfo where dt='2020-06-21') Aright join test.userhis Bon A.userid=B.userid;
拉链表小结
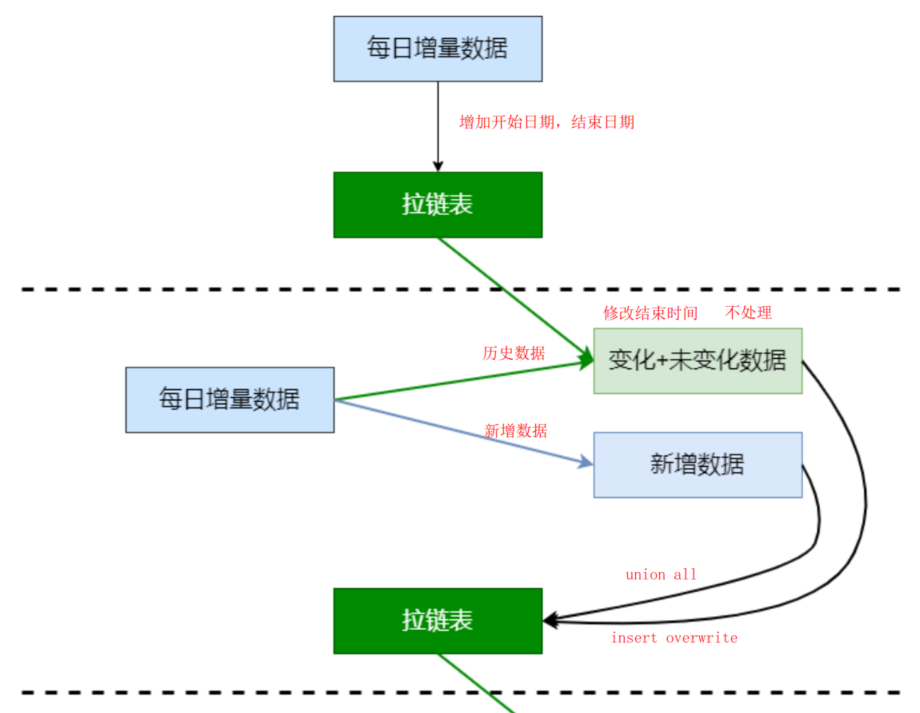
1、历史数据 => 初始化拉链表(开始日期:当日;结束日期:9999-12-31)【只执行一次】
2、拉链表的每日处理【每次加载数据时处理】
新增数据。每日新增数据(ODS) => 开始日期:当日;结束日期:9999-12-31
历史数据。拉链表(DIM) 与 每日新增数据(ODS) 做左连接
连接上数据。数据有变化,结束日期:当日;
未连接上数据。数据无变化,结束日期保持不变;
拉链表的回滚【理解】
目的:要将拉链表恢复到 rollback_date 那一天的数据
横坐标是数据的产生和结束事件轴。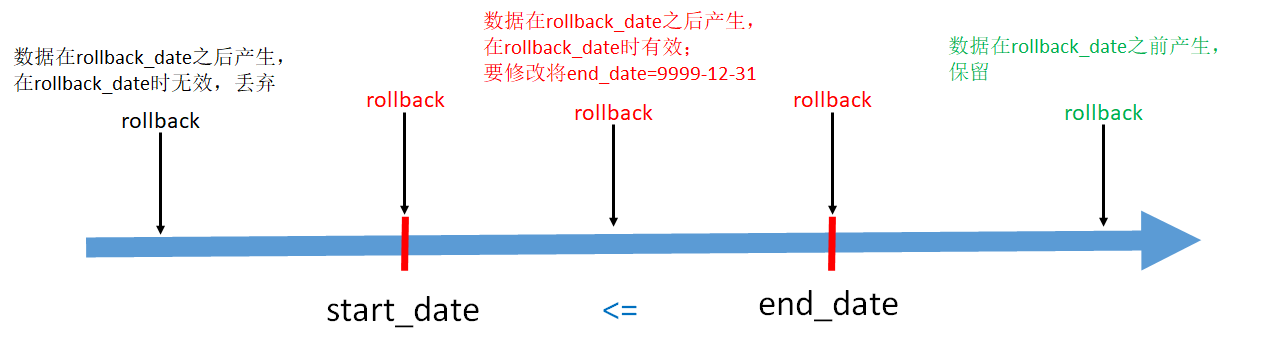
- end_date < rollback_date,即结束日期 < 回滚日期。表示该行数据在rollback_date 之前产生,这些数据需要原样保留
- start_date <= rollback_date <= end_date,即开始日期 <= 回滚日期 <= 结束日期。这些数据是回滚日期之后产生的,但是需要修改。将end_date 改为 9999-12-31
- 其他数据不用管
周期性事实表
拉链表处理
比如说,订单表,具有有效时间
拉链表中的数据分两部实现:新增数据(ods_orders) —>A表、历史数据(dwd_orders) —>B表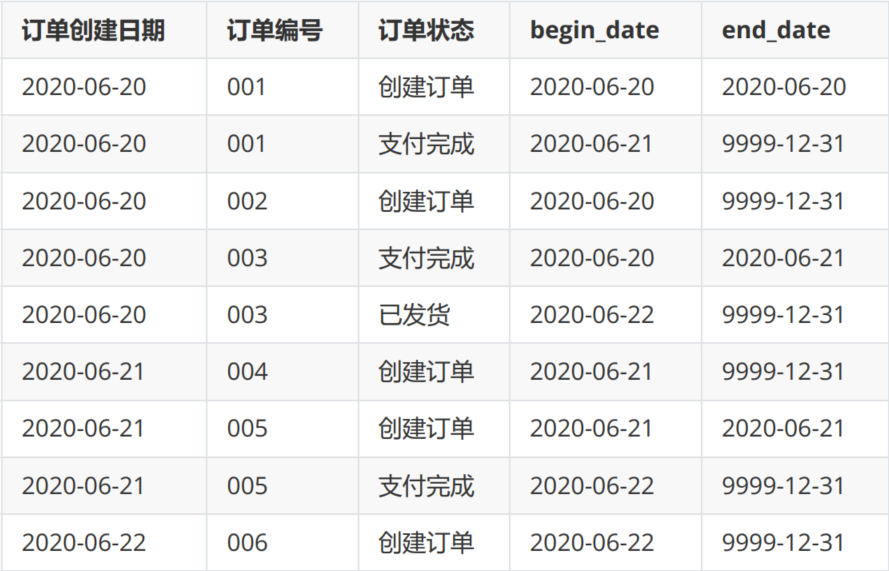
step1: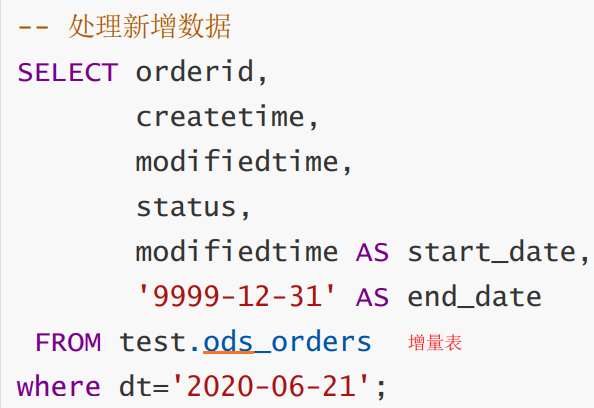
step2:
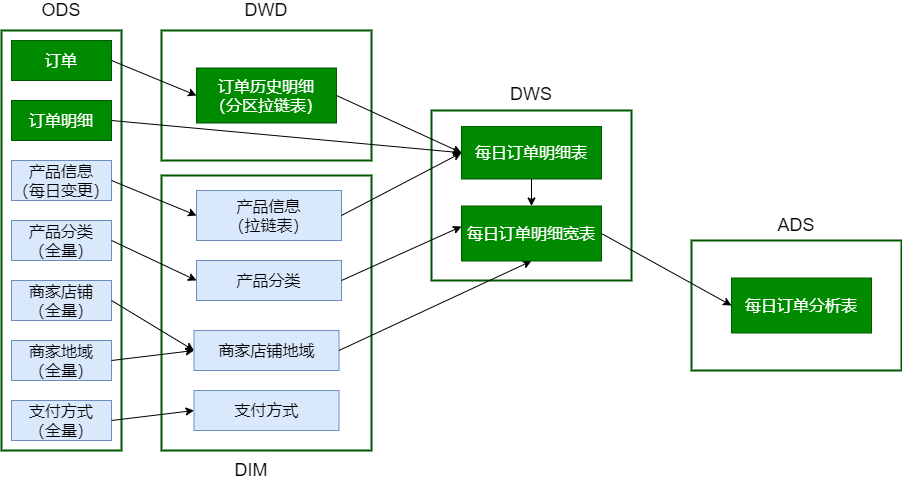
第6节 DIM层建表加载数据
DIM层主要处理维表,灰色的都是维表,随时间缓慢变化,一般表较小。
维表处理:
- 大表(产品信息表 ):拉链表
- 小表(产品分类表、商家店铺表、商家地域组织表、支付方式表 ):每日快照
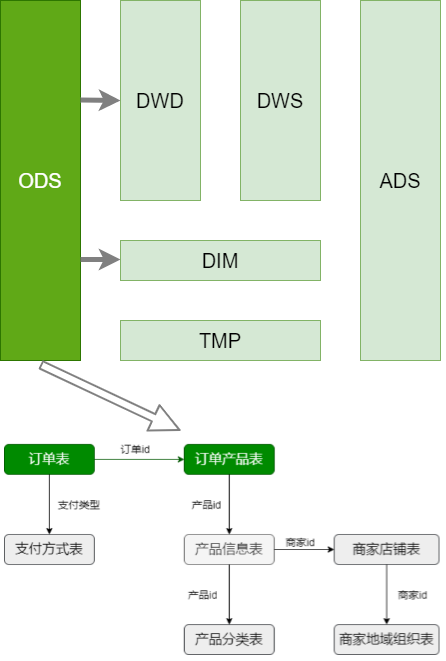
逆规范化
宽表
6.1 商品分类表
思想:将ods_trade_product_category 表中商品的一级、二级、三级分类展开到一张表中dim_trade_product_cat ,方便查询。
实现:表连接left join ,通过子分类去找父分类,一级一级向上找,三级找二级,二级找一级。
最终效果: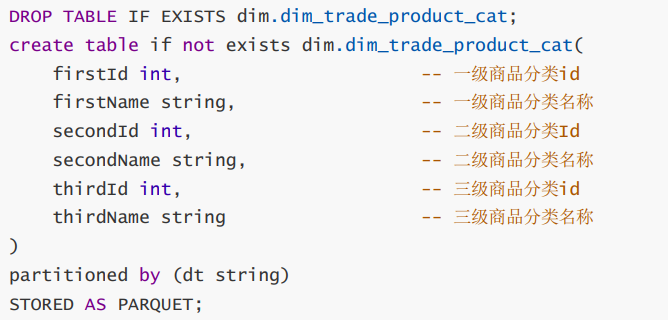
6.2 商品地域组织表
ods.ods_trade_shops + ods_trade_shop_admin_org == dim_trade_shops_org
思想:商家店铺表、商家地域组织表 => 一张维表 ,在一行数据中体现:商家信息、城市信息、地域信息。
实现:表连接,获取商家信息(商家店铺表),通过区域id去匹配(商家地域组织表 )中的id,再通过父子关系匹配到城市id信息。

6.3 支付方式表
对ODS中表ods_trade_payments 的信息做了裁剪,只保留了必要的信息dim_trade_payment 。

6.4 商品信息表 【做拉链表】
处理方式:
1、历史数据 => 初始化拉链表(开始日期:当日;结束日期:9999-12-31)【只执行一次】
2、拉链表的每日处理【每次加载数据时处理】
- 新增数据。每日新增数据(ODS) => 开始日期:当日;结束日期:9999-12-31
- 历史数据。拉链表(DIM) 与 每日新增数据(ODS) 做左连接
- 连接上数据。数据有变化,结束日期:当日;
- 未连接上数据。数据无变化,结束日期保持不变;
第7节 DWD层建表加载数据
7.1 订单表
周期性事实表dwd_trade_orders ;为保留订单状态,可以使用拉链表进行处理;
- 与维表不同,订单事实表的记录数非常多
- 订单有生命周期;订单的状态不可能永远处于变化之中(订单的生命周期一般在15天左右)
- 订单是一个拉链表,而且是分区表
- 分区的目的:订单一旦终止,不会重复计算
- 分区的条件:订单创建日期;保证相同的订单在用一个分区
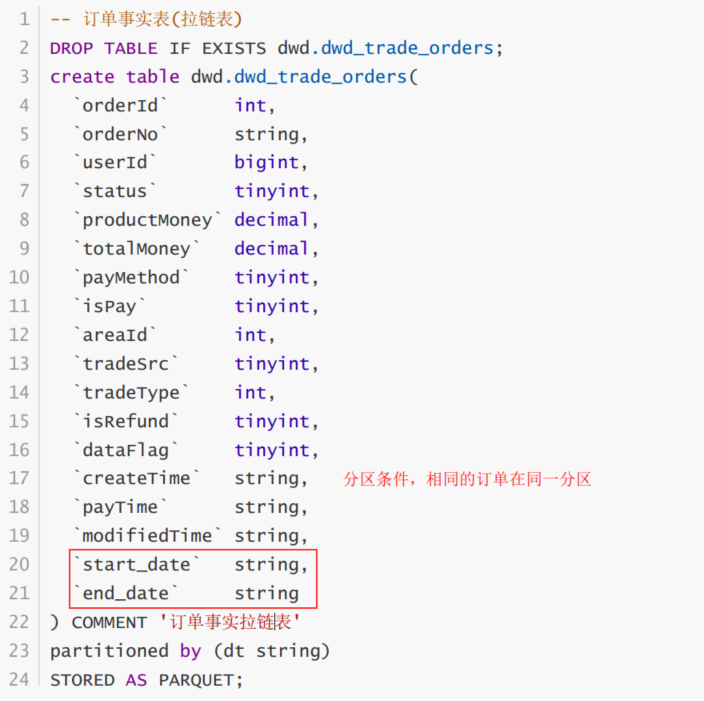
7.2 订单产品表
普通的事实表,用常规的方法进行处理;
- 如果有数据清洗、数据转换的业务需求,ODS => DWD
如果没有数据清洗、数据转换的业务需求,保留在ODS,不做任何变化。这个是本项目的处理方式
第8节 DWS层建表及数据加载
第9节 ADS层开发
详见讲义
用到的表:dws.dws_trade_orders_w 订单明细宽表
只要在订单明细宽表中设置相应的查询条件即可查询!
小结:
四、数仓理论
数据仓库概述
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳 定的(Non-Volatile)、反映历史变化的(Time Variant)数据集合,用于支持管理决策 (Decision-Making Support)。
四大特征:面向主题的
- 集成的
- 稳定的
- 反映历史变化的



数据仓库建模方法
ER模型
釆用ER模型建设数据仓库模型的出发点是整合数据,将各个系统中的数据以整个企 业角度按主题进行相似性组合和合并,并进行一致性处理,为数据分析决策服务,但 是并不能直接用于分析决策。其建模步骤分为三个阶段:
- 高层模型:一个高度抽象的模型,描述主要的主题以及主题间的关系,用于描述 企业的业务总体概况
- 中层模型:在高层模型的基础上,细化主题的数据项
- 物理模型(也叫底层模型):在中层模型的基础上,考虑物理存储,同时基于性能和平台特点进行物理属性的设计,也可能做一 些表的合并、分区的设计等
维度模型
实际最常用的建模方法
维度建模从分析决策的需求出发构建模型,为分析需求服务,重点关注用户如何更快 速地完成需求分析,同时具有较好的大规模复杂查询的响应性能。其典型的代表是星型模型,以及在一些特殊场景下使用的雪花模型。其设计分为以下几个步骤:
- 选择需要进行分析决策的业务过程
- 选择数据的粒度
- 识别维表
-
1. 星型模型
特点:
星型模是一种多维的数据关系,它由一个事实表和一组维表组成;
- 事实表在中心,周围围绕地连接着维表;
- 事实表中包含了大量数据,没有数据冗余;
- 维表是逆规范化的,包含一定的数据冗余;
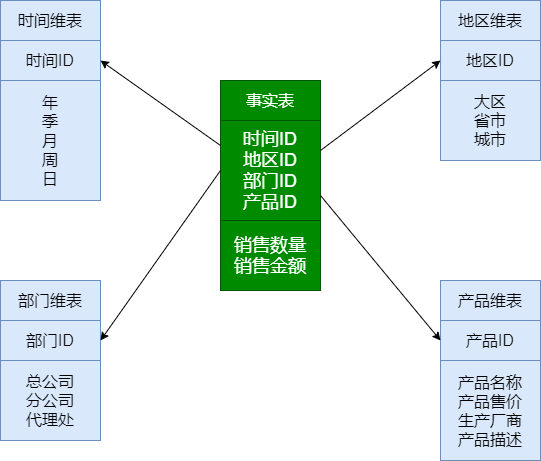
- 星型模型存在数据冗余,所以在查询统计时只需要做少量的表连接,查询效率高;
- 星型模型不考虑维表正规化的因素,设计、实现容易;
- 在数据冗余可接受的情况下,实际上使用星型模型比较多;
2. 雪花模型
雪花模式是星型模型的变种,维表是规范化的,模型类似雪花的形状;
特点:雪花型结构去除了数据冗余。(图中对地区维表进一步细分)
其实反过来相当于宽表操作(星型模型)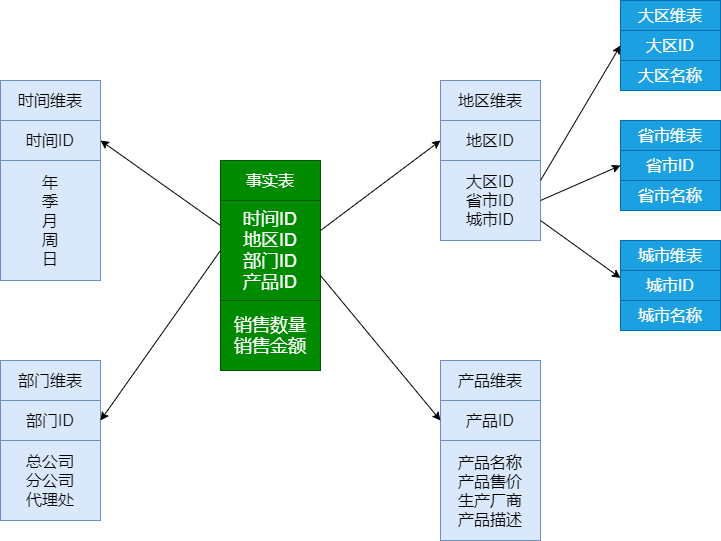
3. 事实星座
数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享,这种模式 可以看做星型模式的汇集,因而称作星系模式或者事实星座模式。
特点:公用维表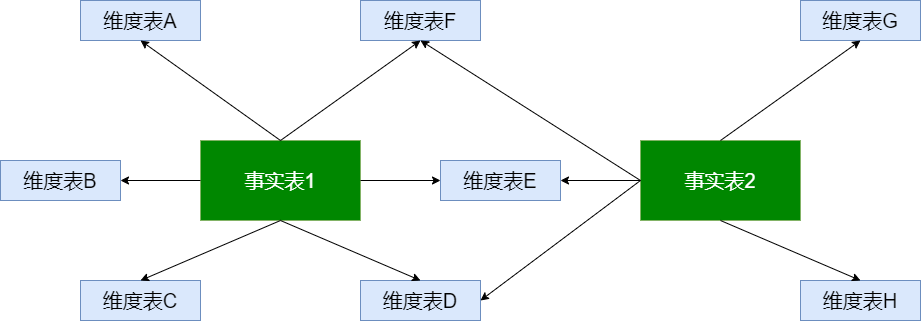
数据仓库分层
分层作用:
- 清晰的数据结构
- 将复杂的问题简单化
- 减少重复开发
- 屏蔽原始数据的异常
- 数据血缘的追踪
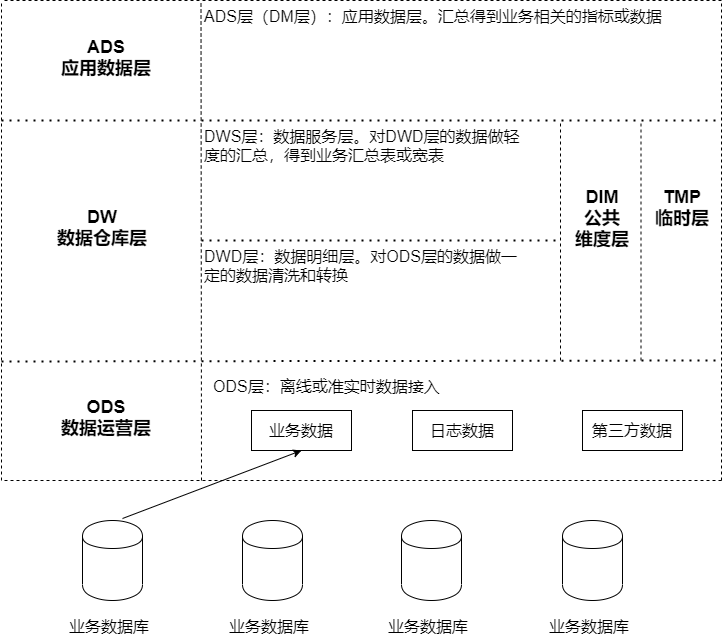
ODS层
ODS(Operation Data Store 数据准备区)。数据仓库源头系统的数据表通常会原 封不动的存储一份,这称为ODS层,也称为准备区。它们是后续数据仓库层加工数据的来源。
DW层
DW(Data Warehouse 数据仓库层)。包含DWD、DWS、DIM层,由ODS层数据 加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
- DWD(Data Warehouse Detail 细节数据层)
- 是业务层与数据仓库的隔离层。以业务过程作为建模驱动,基于每个具体的业务过程特点,构建细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,也即宽表化处理;
- DWS(Data Warehouse Service 服务数据层)
- 基于DWD的基础数据,整合汇总成分析某一个主题域的服务数据。以分析的主题为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表;
- 公共维度层(DIM)
- 基于维度建模理念思想,建立一致性维度;
- TMP层
- 临时层,存放计算过程中临时产生的数据;
ADS层
- ADS(Application Data Store 应用数据层)
- 基于DW数据,整合汇总成主题域的服务数据,用于提供后续的业务查询等。
QA
- HIVE中影响map个数的因素?
- HDFS集群规定的文件块大小,set dfs.block.size = 128m/256m
- input文件的个数
- input文件的大小(ps:map和输出文件无关)
- HIVE支持的计算引擎?
- MR
- TEZ
- Spark
- Flink
- 每一层的设计,都有哪些表
会员分析模块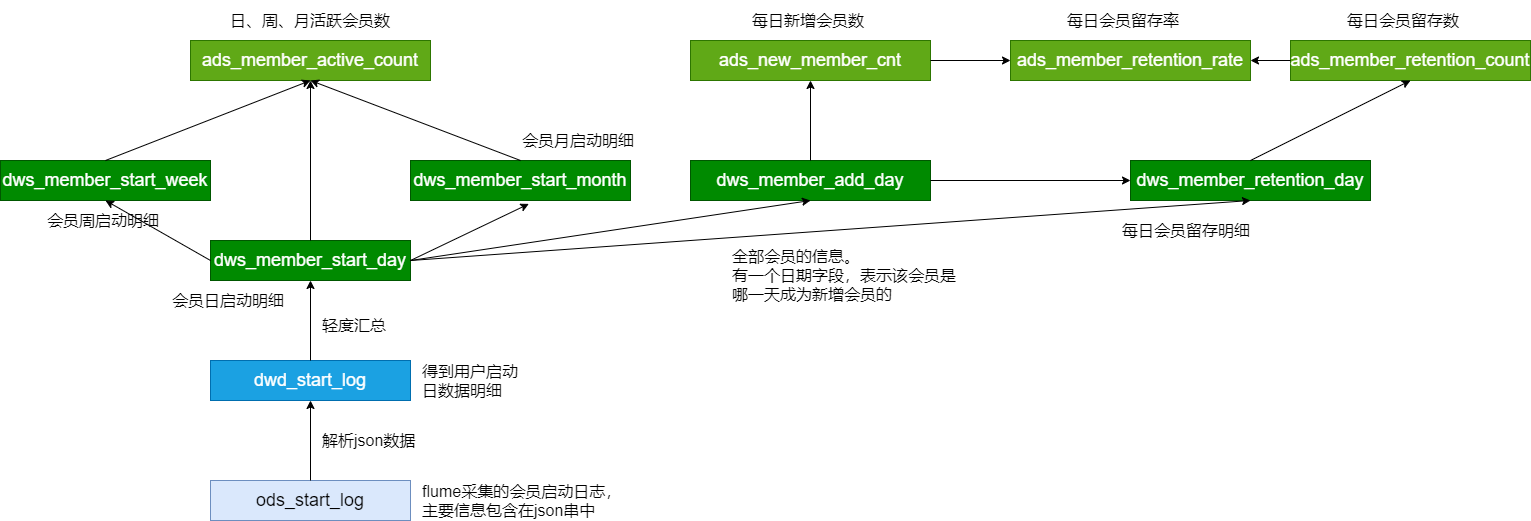
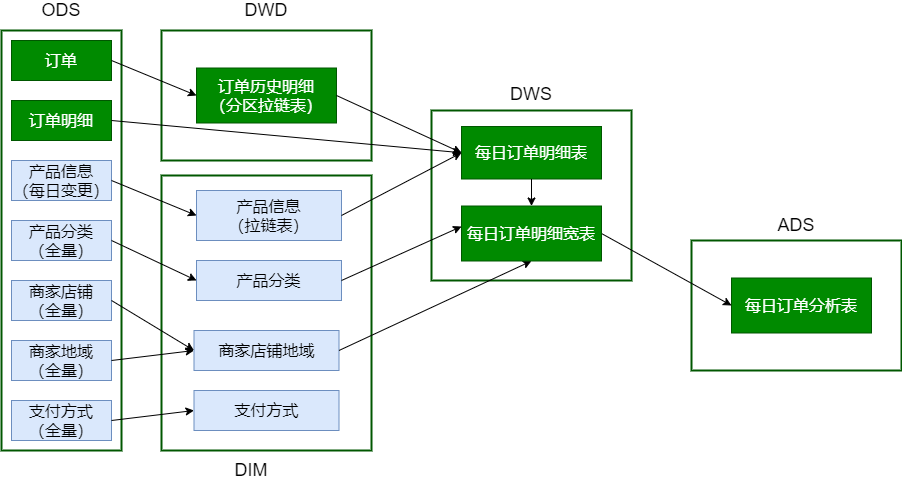
1、OLTP和OLAP的区别?
- OLTP(On-Line Transaction Processing 联机事务处理),也称面向交易的处理系统。主要针对具体业务在数据库系统的日常操作,通常对少数记录进行查询、修改。 用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。 传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
- OLAP(On-Line Analytical Processing 联机分析处理),一般针对某些主题的历史数据进行分析,支持管理决策。
2、范式建模和纬度的区别?
http://www.uml.org.cn/sjjmck/202107032.asp?artid=24145
2.1.范式建模(E-R模型)
将事物抽象为“实体”、“属性”、“关系”来表示数 据关联和事物描述;实体:Entity,关系:Relationship,这种对数据的抽象 建模通常被称为ER实体关系模型
ER模型是数据库设计的理论基础,当前几乎所有的OLTP系统 设计都采用ER模型建模的方式,且该建模方法需要满足3NF。Bill Inom提出的数仓理论,推荐采用ER关系模型进行建模,BI架构提出分层架构,数仓底层ods、dwd也多采用ER关系模型就行设计。
但是 逐渐随着企业数据的高增长,复杂化,数仓全部使用ER模型建模 显得越来越不合时宜。为什么呢,因为其按部就班的步骤,三范式等,不适合现代化复杂,多变的业务组织。
E-R模型建模的步骤(满足3NF)如下:
1.抽象出主体 (教师,课程)
2.梳理主体之间的关系 (一个老师可以教多门课,一门课可以被多个老师教)
3.梳理主体的属性 (教师:教师名称,性别,学历等)
4.画出E-R关系图
2.2.维度建模
维度建模,是数据仓库大师Ralph Kimball提出的,是数据仓库工程领域最流行的数仓建模经典。
维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。维度建模是面向分析的,为了提高查询性能可以增加数据冗余,反规范化的设计技术。
Ralph Kimball提出对数据仓库维度建模,并且将数据仓库中的表划分为事实表、维度表两种类型。
- 建模过程:
- 1)选择业务过程
- 2)声明粒度
- 3)确定维度
- 4)确定事实
3.2.1.事实表
事实表根据粒度的角色划分不同,可分为事务事实表、周期快照事实表、累积快照事实表。注意:这里需要值得注意的是,在事实表的设计时,一定要注意一个事实表只能有一个粒度,不能将不同粒度的事实建立在同一张事实表中。
- 事务事实表,用于承载事务数据,通常粒度比较低,它是面向事务的,其粒度是每一行对应一个事务,它是最细粒度的事实表,例如产品交易事务事实、ATM交易事务事实。
- 周期快照事实表,按照一定的时间周期间隔(每天,每月)来捕捉业务活动的执行情况,一旦装入事实表就不会再去更新,它是事务事实表的补充。用来记录有规律的、固定时间间隔的业务累计数据,通常粒度比较高,例如账户月平均余额事实表。
- 累积快照事实表,用来记录具有时间跨度的业务处理过程的整个过程的信息,每个生命周期一行,通常这类事实表比较少见。
3.2.2.维度表
维度,顾名思义,业务过程的发生或分析角度。比如从颜色、尺寸的角度来比较手机的外观,从cpu、内存等较比比较手机性能维。维度表一般为单一主键,在ER模型中,实体为客观存在的事物,会带有自己的 描述性属性,属性一般为文本性、描述性的,这些描述被称为维度。
比如商品,单一主键:商品ID,属性包括产地、颜色、材质、尺寸、单价等, 但并非属性一定是文本,比如单价、尺寸,均为数值型描述性的,日常主要的维度抽象包括:时间维度表、地理区域维度表等
案例:某电商平台,经常需要对订单进行分析,以某宝的购物订单为例,以维度建 模的方式设计该模型
涉及到事实表为订单表、订单明细表,维度包括商品维度、用户维度、商家维度、区域维度、时间维度(根据最终要统计的指标来确定,需要处理哪些纬度)
3、星型模型和雪花模型主要区别就是对维度表的拆分
对于雪花模型,维度表的涉及更加规范,一般符合3NF,有效降低数据冗余,维度表之间不会相互关联,但是
而星型模型,一般采用降维的操作,反规范化,不符合3NF,利用冗余来避免模型过于复杂,提高易用性和分析效率,效率相对较高。
4、拉链表
使用场景
- 表的数据量大
- 表中部分字段会被更新,大部分是不变的
- 表中记录变量的比例不高
- 需要保留历史信息
主要目的
- 节省存储空间
- 弊端
- 维护麻烦

若有收获,就点个赞吧
0 人点赞
