RDD基础
RDD包含5个特征
RDD 是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
1. 一个分区的列表
2. 一个计算函数compute,对每个分区进行计算
3. 对其他RDDs的依赖(宽依赖、窄依赖)列表
4. 对key-value RDDs来说,存在一个分区器(Partitioner)【可选的】
5. 对每个分区有一个优先位置的列表【可选的】
简单总结:
- 分区
- 只读
- 依赖
- 缓存
- checkpoint
- RDD支持 checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint后的RDD不需要知道它的父RDDs了,它可以从 checkpoint 处拿到数据。
Transformation算子
map(func)
filter(func)
flatMap(func) 先映射后扁平化
mapPartitions(func) 高效算子
mapPartitionsWithIndex(func)
groupBy(func) 按key分租
glom() 将一个分区形成一个数组RDD[array]返回
sample 采样
distinct 去重
coalesce 缩减分区
repartition 重新分区 shuffle
面试题,Repartition 和 Coalesce 关系与区别 ?
关系:
- 两者都是用来改变 RDD 的 partition 数量的,repartition 底层调用的就是 coalesce 方法: coalesce(numPartitions, shuffle = true)
区别:
- repartition 一定会发生 shuffle,coalesce 根据传入的参数来判断是否发生 shuffle 。
- 一般情况下增大 rdd 的 partition 数量使用 repartition,减少 partition 数量时使用 coalesce。
intersection 交
union 并
subtract 差
cartesian 笛卡尔积
zip 拉链操作,组合为key-value形式的RDD
宽依赖(shuffle):groupBy、distinct、repartition、sortBy、intersection、union、subtract
Action算子
collect() / collectAsMap()
stats 返回统计信息
count / mean / stdev / max / min
reduce(func) / fold(func) / aggregate(func)
first()
take()
top()
takeSample()
foreach() / foreachPartition()
saveAsTextFile() / SaveAsSequenceFile() / SaveAsObjectFile()
PairRDD
一、map
mapValues / flatMapValues / keys / values
二、聚合操作
groupByKey / reduceByKey / foldByKey / aggregateByKey
combineByKey(OLD) / combineByKeyWithClassTag (NEW) => 底层实现
subtractByKey:类似于subtract,删掉 RDD 中键与 other RDD 中的键相同的元素
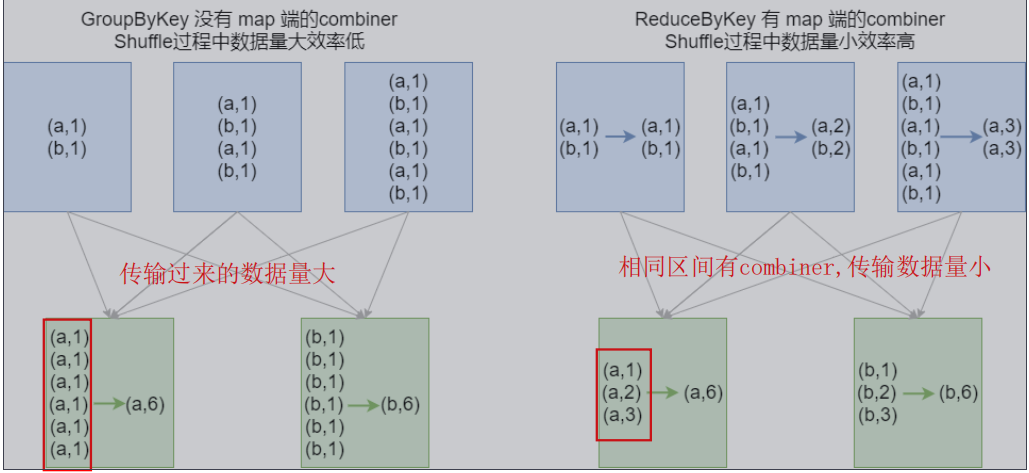
面试题,groupByKey和reduceByKey的区别?
- groupByKey 没有map端的combiner,shuffle过程中传输的数据量大,效率低(不同key直接分组,传输)
- ReduceByKey 有map段的combiner,shuffle过程中传输的数据量小,效率高(相同key聚合,不同key分组, 传输)
三、排序操作
sortByKey sortByKey函数作用于PairRDD,对Key进行排序。
四、join操作
cogroup / join / leftOuterJoin / rightOuterJoin / fullOuterJoin
五、Action操作
collectAsMap / countByKey / lookup(key)
RDD高阶
1、RDD依赖关系
WordCount依赖分析
相关指令:rdd1.toDebugString 查看血缘关系rdd1.dependencies 查看依赖关系
依赖有2个作用:其一用来解决数据容错;其二用来划分stage。
程序执行过程: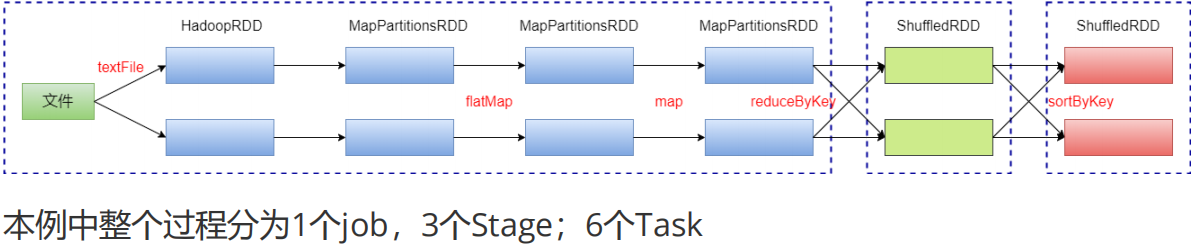
- job划分:一个Action(count,collect…)算子,产生一个job
- stage划分:一次shuffle(宽依赖),就是stage的分界点。是task的集合,taskSet。
- task划分:一个stage中,包含多个task。在Executor执行,一个分区对应一个Executor。
- 所以,task是一个分区中,一个satge范围内,从左到右的计算过程(hadoopRDD ->MapPartitionsRDD)
2、RDD持久化/缓存
lazy的,需要action操作触发
persist() / cache() :标记持久化,使用cache()方法时,会调用persist(MEMORY_ONLY)
unpersist()方法手动地把持久化的RDD从缓存中移除;
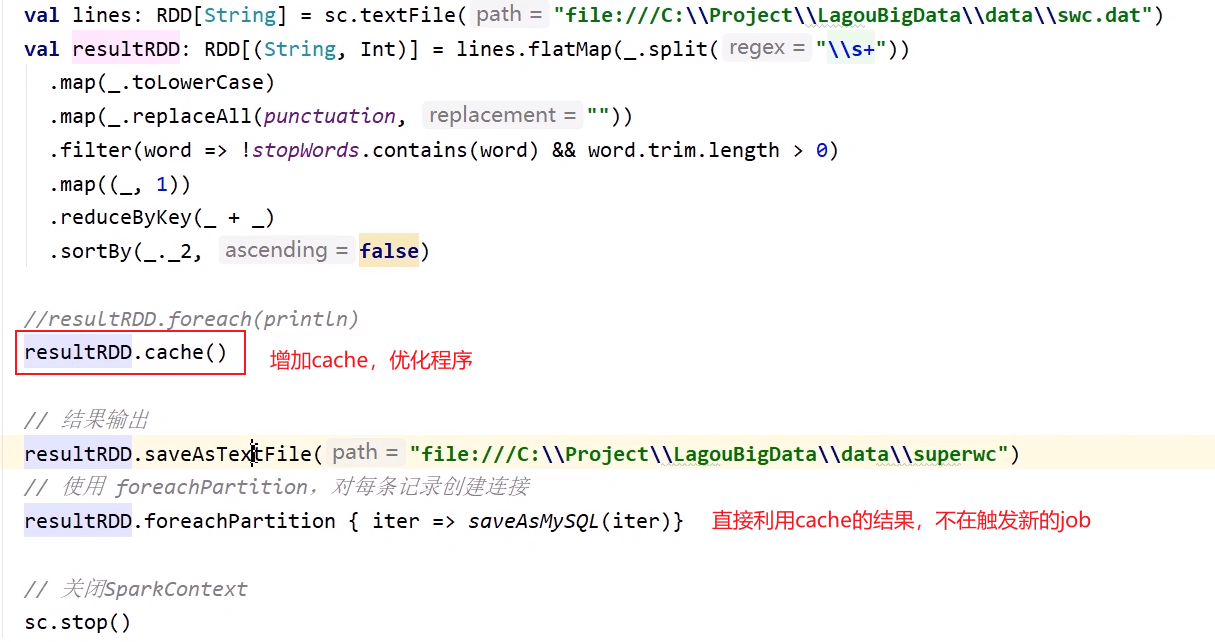
wordcount程序中cache优化
3、RDD容错checkpoint
- lazy的
- DAG中的Lineage过长,如果重算,则开销太大,此时依赖链可以丢掉,所以斩断了依赖链
- 在宽依赖上做 Checkpoint 获得的收益更大
面试题,缓存机制和checkpoint的区别?
- cache机制用于,多次使用同一个RDD,重用
- 都是做 RDD 持久化的
- cache:内存,不会截断血缘关系,使用计算过程中的数据缓存。
- checkpoint:磁盘,截断血缘关系,在 ck 之前必须没有任何任务提交才会生效,ck 过程会额外提交一次任务。
4、RDD分区器
- 只有PairRDD才有分区器
- HashPartitioner哈希分区器
- 最简单、最常用,也是默认提供的分区器。对于给定的key,计算其hashCode,并除以分区的个数取余,如果余数小于0,则用 余数+分区的个数,最后返回的值就是这个key所属的分区ID。该分区方法可以保证key相同的数据出现在同一个分区中。
- RangePartitioner
- 简单的说就是将一定范围内的数映射到某一个分区内。在实现中,分界的算法尤为重要,用到了水塘抽样算法。sortByKey会使用RangePartitioner。
5、广播变量
- 广播变量将变量在节点的 Executor 之间进行共享(由Driver广播出去);
- 广播变量用来高效分发较大的对象。向所有工作节点(Executor)发送一个较大的只读值,以供一个或多个操作使用。
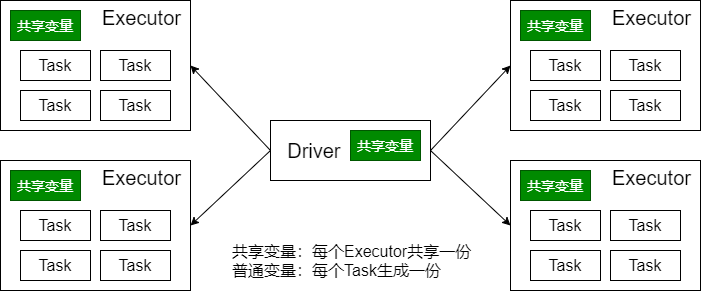
应用场景:
Map Side Join (map端的join操作)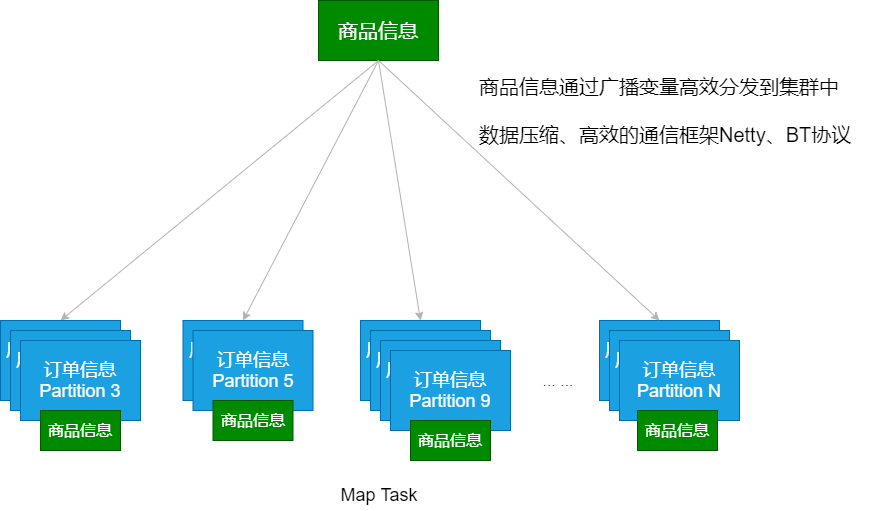
6、累加器
累加器的作用:可以实现一个变量在不同的 Executor 端能保持状态的累加;
- 累计器在 Driver 端定义,读取;在 Executor 中完成累加;
- 累加器也是 lazy 的,需要 Action 触发;
- Action触发一次,执行一次,触发多次,执行多次;
7、TopN的优化
- aggregateByKey替代groupByKey
- 每个分区取前n个

aggregateByKey中的定义:
第一行:分区内部的操作
第二行:分区间的操作
Spark原理初级
1、作业模式提交
Standalone 模式下四个组成部分:
- Driver:用户编写的 Spark 应用程序就运行在 Driver 上,由Driver 进程执行
- Master:主要负责资源的调度和分配,并进行集群的监控等职责
- Worker:Worker 运行在集群中的一台服务器上。负责管理该节点上的资源,负责启动启动节点上的 Executor
- Executor:一个 Worker 上可以运行多个 Executor,Executor通过启动多个线程(task)对 RDD 的分区进行并行计算
SparkContext 中的三大组件:
- DAGScheduler:负责将DAG划分成若干个Stage
- TaskScheduler:将DAGScheduler提交的 Stage(Taskset)进行优先级排序,再将task 发送到 Executor
- SchedulerBackend:定义了许多与Executor事件相关的处理,包括:新的executor注册进来的时候记录executor的信息,增加全局的资源量(核数);executor更新状态,若任务完成的话,回收core;其他停止executor、remove executor等事件
Standalone模式下作业提交步骤:
1、启动应用程序,完成SparkContext的初始化
2、Driver向Master注册,申请资源
3、Master检查集群资源状况。若集群资源满足,通知Worker启动Executor
4、Executor启动后向Driver注册(称为反向注册)
5、Driver完成DAG的解析,得到Tasks,然后向Executor发送Task
6、Executor 向Driver汇总任务的执行情况
7、应用程序执行完毕,回收资源
2、shuffle原理
见原理深入部分~
3、RDD编程优化
略~
SparkSQL
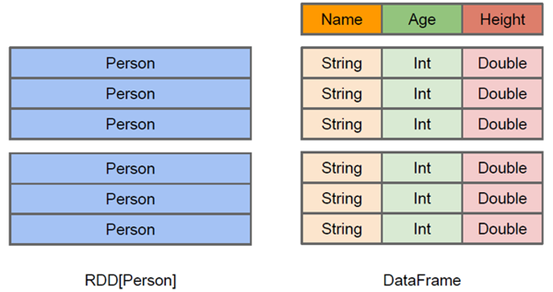
1、DataFrame
- DataFrame可以看做分布式 Row 对象的集合
- DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema
- DataFrame也支持嵌套数据类型(struct、array和map)
- DataFrame = RDD[Row] + Schema;
2、DataSet
- 与DataFrame相比,保存了类型信息,是强类型的,提供了编译时类型检查;
- 调用Dataset的方法先会生成逻辑计划,然后Spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行。
- DataFrame表示为DataSet[Row],即DataSet的子集。
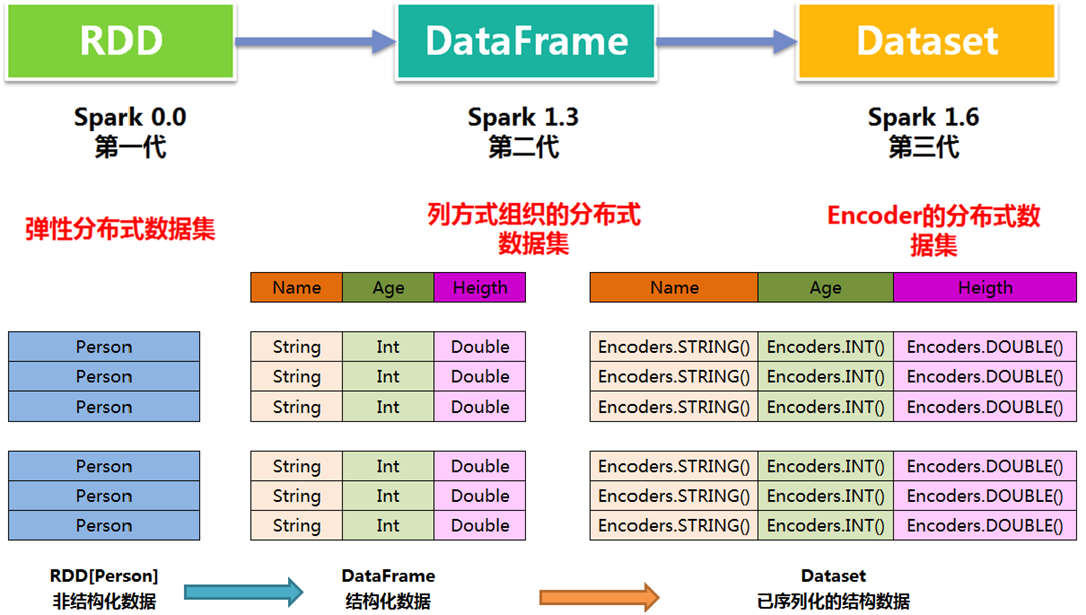
3、三者的区别(与RDD的关系)
DataFrame = RDD[Row] + Schema
1、与RDD和Dataset不同,DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值
2、DataFrame与Dataset均支持 SparkSQL 的操作
Dataset = RDD[case class].toDS
1、Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同;
2、DataFrame 定义为 Dataset[Row]。每一行的类型是Row,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用前面提到的getAS方法或者模式匹配拿出特定字段;
3、Dataset每一行的类型都是一个case class,在自定义了case class之后可以很自由的获得每一行的信息;
4、三者的转换关系
核心:
Dataset = RDD[case class]
DataFrame = RDD[Row] + Schema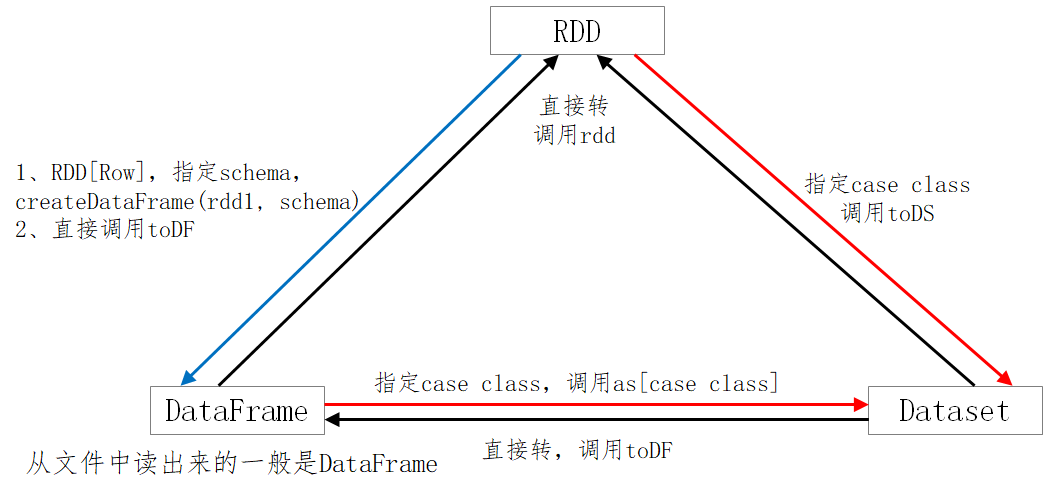
5、输入输出
SparkSQL内建支持的数据源包括:Parquet、JSON、CSV、Avro、Images、 BinaryFiles(Spark 3.0)。其中Parquet是默认的数据源。
面试题,append 和 overwrite 的区别?
SaveMode.Append。若表存在,则追加在该表中;若该表不存在,则会先创建表,再插入数据(在原有分区)
SaveMode.Overwrite。先将已有的表及其数据全都删除,再重新创建该表,最后插入新的数据(在原有分区)==全量刷新
6、UDF & UDAF
需要定义并注册,使用在spark sql中
- UDF(User Defined Function),自定义函数。函数的输入、输出都是一条数据记录,类似于Spark SQL中普通的数学或字符串函数。实现上看就是普通的Scala函数;
- UDAF(User Defined Aggregation Funcation),用户自定义聚合函数。函数本身作用于数据集合,能够在聚合操作的基础上进行自定义操作(多条数据输入,一条数据输出);类似于在group by之后使用的sum、avg等函数;
- UDTF(爆炸函数),一条输入,多条输出
7、Spqrk SQL原理
JOIN操作
(1)Broadcast Hash Join
Broadcast Hash Join 的实现是将小表的数据广播到 Spark 所有的 Executor 端,这 个广播过程和我们自己去广播数据没什么区别:
- 利用 collect 算子将小表的数据从 Executor 端拉到 Driver 端
- 在 Driver 端调用 sparkContext.broadcast 广播到所有 Executor 端
- 在 Executor 端使用广播的数据与大表进行 Join 操作(实际上是执行map操作)
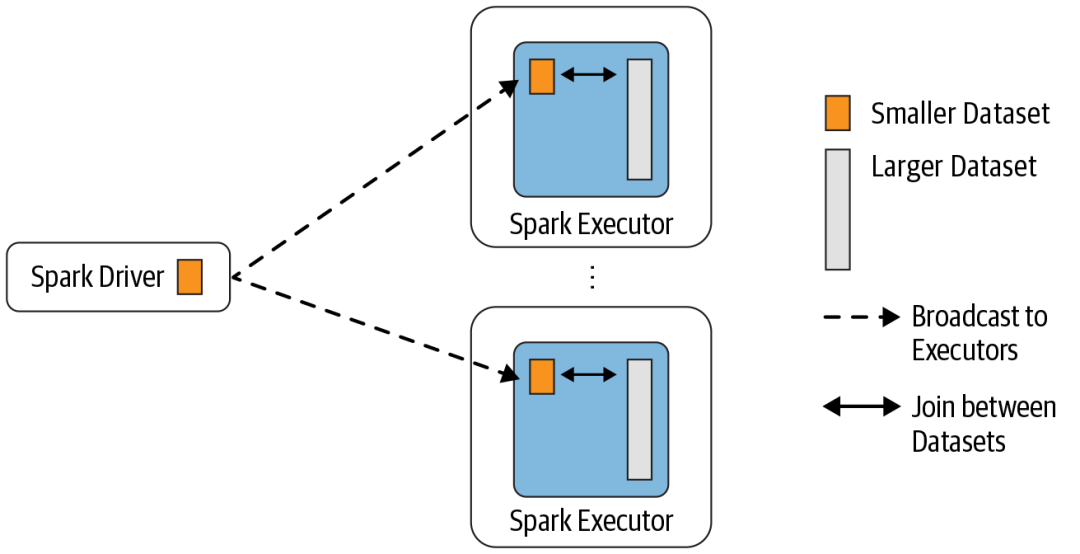
(2)Shuffle Hash Join-不常用
当表中的数据比较大,又不适合使用广播,这个时候就可以考虑使用 Shuffle Hash Join。
计算思想:
- 把大表和小表按照相同的分区算法和分区数进行分区(根据参与 Join 的 keys 进行分区),这样就保证了 hash 值一样的数据都分发到同一个分区中。
- 然后 在同一个 Executor 中两张表 hash 值一样的分区就可以在本地进行 hash Join 了。
- 在进行 Join 之前,还会对小表的分区构建 Hash Map。
Shuffle hash join 利用了分治思想,把大问题拆解成小问题去解决。
(3)Shuffle Sort Merge Join
实现思想:
- 将两张表按照 join key 进行shuffle,保证join key值相同的记录会被分在相应的分区
- 对每个分区内的数据进行排序
- 排序后再对相应的分区内的记录进行连接
从头遍历,碰到key相同的就输出,如果不同,左边小就继续取左边,反之取右边。从而大大提高了大数据量下sql join的稳定性。
排序后,利用两个指针交替移动。不会倒退回去。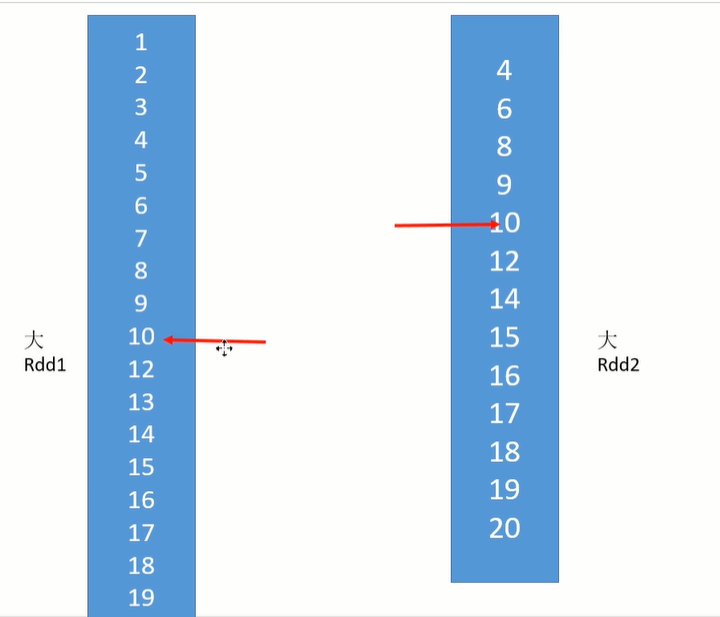
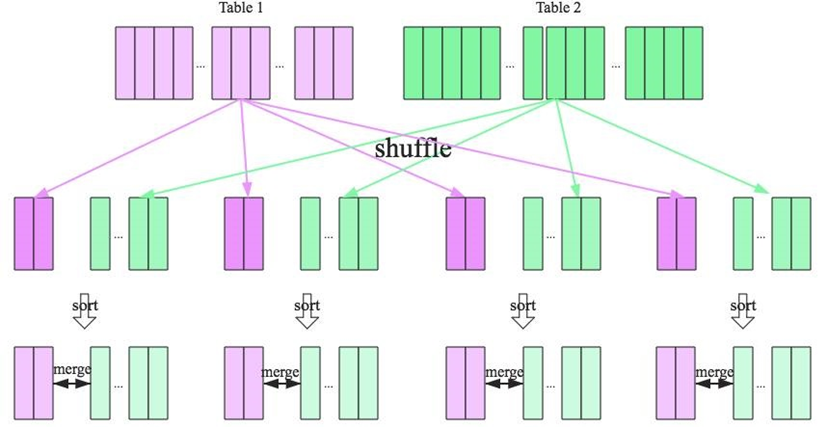
SQL解析流程
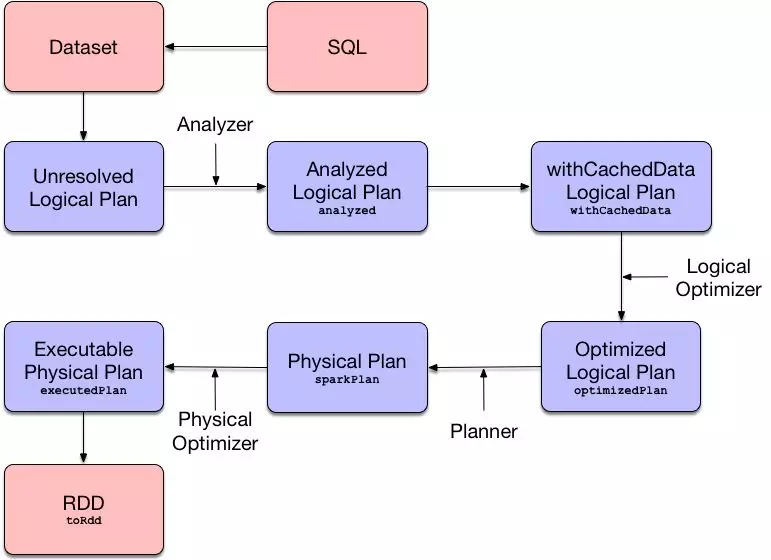
正常的 SQL 执行先会经过 SQL Parser 解析 SQL,然后经过 Catalyst 优化器处理,最后到 Spark 执行。Catalyst 优化的过程又分为很多个过程,其中包括∶
- Analysis∶主要利用 Catalog 信息将 Unresolved Logical Plan 解析成 Analyzed logical plan
- Logical Optimizations∶利用—些 Rule (规则)将 Analyzed logical plan 解析成 Optimized Logical Plan
- Physical Planning∶ 前面的 logical plan 不能被 Spark 执行,而这个过程是把 loqical plan 转换成多个物理执行计划
- physical plans∶在多个执行计划中选择最佳的 physical plan
- Code Generation∶ 这个过程会把 SQL 查询生成 Java 字节码
面试题,cache 缓存级别?
DataFrame 的 cache 默认采用 MEMORY_AND_DISK
RDD cache 默认采用 MEMORY_ONLY
面试题,Spark Shuffle 默认并行度 ?
参数 spark.sql.shuffle.partitions 决定 默认并行度 200
面试题,BroadCast join实现过程?
先将小表数据查询出来聚合到 driver 端,再广播到各个 executor 端,使表与表 join 时 进行本地 join,避免进行网络传输产生 shuffle。
面试题 ,SparkSQL 中 join 操作与 left join 操作的区别?
- join 和 SQL 中的 inner join 操作很相似,返回结果是前面一个集合和后面一个集合中匹配成功的,过滤掉关联不上的。
- leftJoin 类似于 SQL 中的左外关联 left outer join,返回结果以第一个 RDD 为主,关联不上的记录为空null。
部分场景下可以使用 left semi join 替代 left join:
因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,性能更高, 而 left join 则会一直遍历。但是 left semi join 中最后 select 的结果中只许出现左表中的列 名,因为右表只有 join key 参与关联计算了。
Spark Streaming
1、运行流程
1、客户端提交Spark Streaming作业后启动Driver,Driver启动Receiver,Receiver接收数据源的数据
2、每个作业包含多个Executor,每个Executor以线程的方式运行task,Spark Streaming至少包含一个receiver task(一般情况下)
3、Receiver接收数据后生成Block,并把BlockId汇报给Driver,然后备份到另外一个 Executor 上
4、ReceiverTracker维护 Reciver 汇报的BlockId
5、Driver定时启动JobGenerator,根据Dstream的关系生成逻辑RDD,然后创建Jobset,交给JobScheduler
6、JobScheduler负责调度Jobset,交给DAGScheduler,DAGScheduler根据逻辑RDD,生成相应的Stages,每个stage包含一到多个Task,将TaskSet提交给TaskSchedule
7、TaskScheduler负责把 Task 调度到 Executor 上,并维护 Task 的运行状态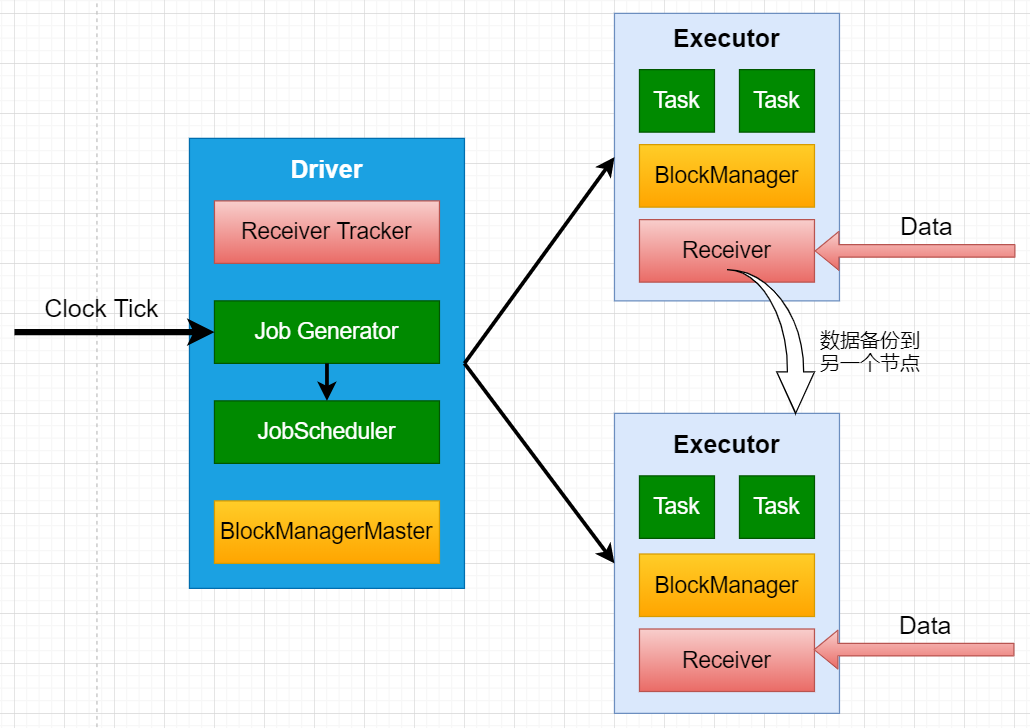
2、Spark Streaming 优缺点
特点:
粗粒度、批处理
优点:
- 粗粒度、快速高效、准实时
- 处理仅处理一次(EOS)、容错恢复机制
- 易与RDD交互
缺点:
延迟、汇总到一定量的数据后再处理
3、Structured Streaming
将数据源映射为一张无界长度的表,通过表的计算,输出结果映射为另一张表。
4、DStream转换操作
无状态转化操作(stateless)
- 每个批次的处理不依赖于之前批次的数据。常见的 RDD 转化操作,例如 map、filter、reduceByKey 等
- 无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化DStream 中的每一个 RDD。
常见的无状态转换包括:map、flatMap、filter、repartition、reduceByKey、groupByKey;直接作用在DStream上
有状态转化操作(stateful)
需要使用之前批次的数据 或者是 中间结果来计算当前批次的数据。有状态转化操作包括:基于滑动窗口的转化操作或追踪状态变化的转化操作
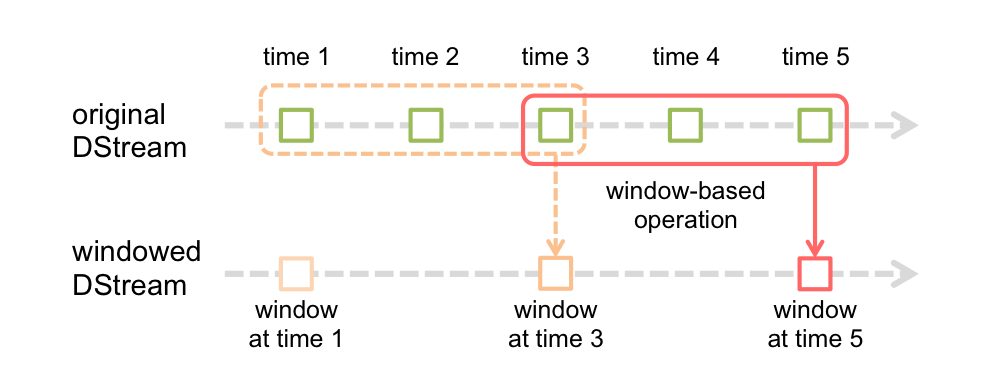
1.窗口操作
Window Operations可以设置窗口大小和滑动窗口间隔来动态的获取当前Streaming的状态。
- 基于窗口的操作会在一个比 StreamingContext 的 batchDuration(批次间隔)更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
- 参数:窗口长度、滑动间隔


2.状态追踪操作 updateStateByKey
5、DStream输出操作

通用的输出操作 foreachRDD,用来对 DStream 中的 RDD 进行任意计算。在foreachRDD中,可以重用 Spark RDD 中所有的 Action 操作。
- 在 RDD的 foreachPartition 中定义连接,每个分区创建一个连接
- 可以考虑使用连接池
- 连接定义在 RDD的 foreach 算子中,则遍历 RDD 的每个元素时都创建连接,得不偿失
6、连接Kafka方式
(1)基于 Receiver 的方式
- 数据都是存储在 Spark Executor 的内存中的
- 丢失数据
- 启用 Spark Streaming 的预写日志机制(损失性能)
(2)Direct Approach
- 替代掉使用 Receiver 来接收数据
- 减少不必要的CPU占用;减少了 Receiver接收数据写入BlockManager,然后运行时再通过blockId、网络传输、磁盘读取等来获取数据的整个过程,提升了效率;无需WAL,进一步减少磁盘IO;
- 周期性地查询 Kafka,来获得每个 topic+partition 的最新的 offset,从而定义每个 batch 的 offset 的范围
- Direct方式生的RDD是KafkaRDD,它的分区数与 Kafka 分区数保持一致,便于 把控并行度
- 注意:在 Shuffle 或 Repartition 操作后生成的RDD,这种对应关系会失效
- 高性能,只要 Kafka 中作了数据的复制,那么就可以通过 Kafka 的副本进行恢复
7、Offects管理
获取偏移量
存储偏移量
Redis管理
拓展:手撕SQL题
1、UDAF实现count(distinct(*))的功能?
Spark原理及源码解读
一、作业执行原理
二、Spark shuffle详解

若有收获,就点个赞吧
0 人点赞
