6 数据ETL
拉链表的实现(见数仓项目总结):处理周期性事实表和维表
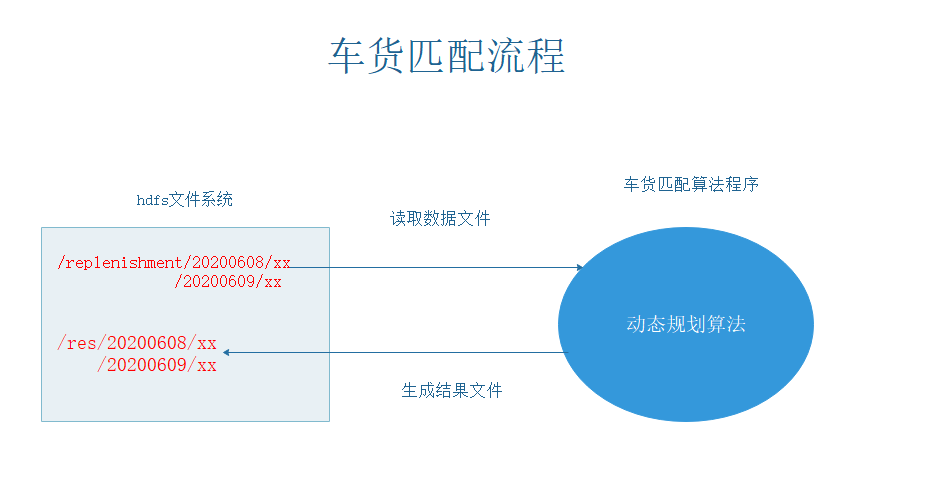
9 车货匹配
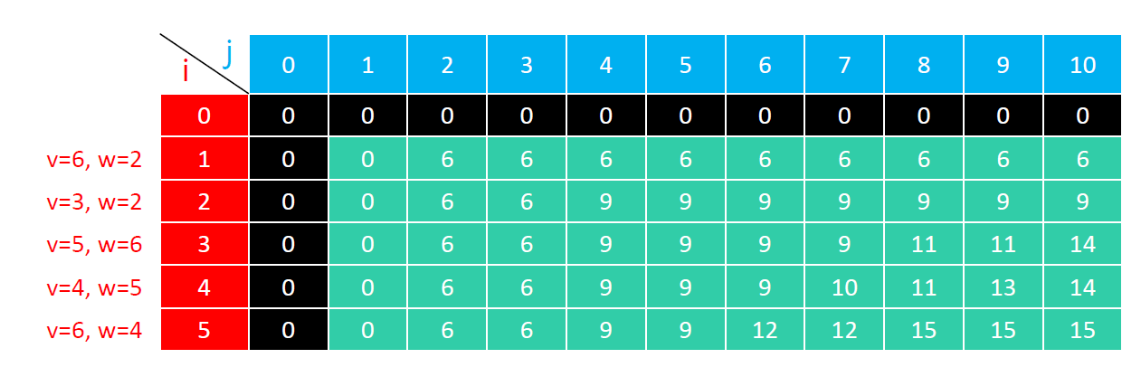
01背包问题
输入:
values[]:价值数组
weights[]:重量数组
capacity:容量
输出:
最大总价值
dp(i, j) 是 最大承重为 j、有前 i 件物品可选 时的最大总价值
- 初始化
- dp(i, 0)—承重为0、dp(0, j)—物品数量为0, 初始值均为 0
- 装不下 :背包容量 < 商品重量
dp[i][j]=dp[i-1][j];
- 装得下 : 装 / 不装
dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - weights[i - 1]] + values[i - 1]);
车货匹配
输入:
volarr[]:货物的体积数组
capacity:车辆的容积
输出:
每辆车实际装的最大货物体积
dp[i][j]含义:前i件物品在不超过最大容积j时的体积,j == capacity
- 定义dp数组
int[][] dp=new int[volumeArr.length+1][capacity+1];
- 状态转移
- 装不下:车辆容积 < 货物体积
dp[i][j]=dp[i-1][j];
- 装得下:装 / 不装
dp[i][j] = Math.max(dp[i - 1][j - volumeArr[i - 1]] + volumeArr[i - 1], dp[i - 1][j]);
Structed Streaming
Structured Streaming最核心的思想就是将实时到达的数据看作是一个不断追加的unbound table无界表,到达流的每个数据项(RDD)就像是表中的一个新行被附加到无边界的表中.这样用户就可以用静态结构化数据的批处理查询方式进行流计算,如可以使用SQL对到来的每一行数据进行实时查询处理;
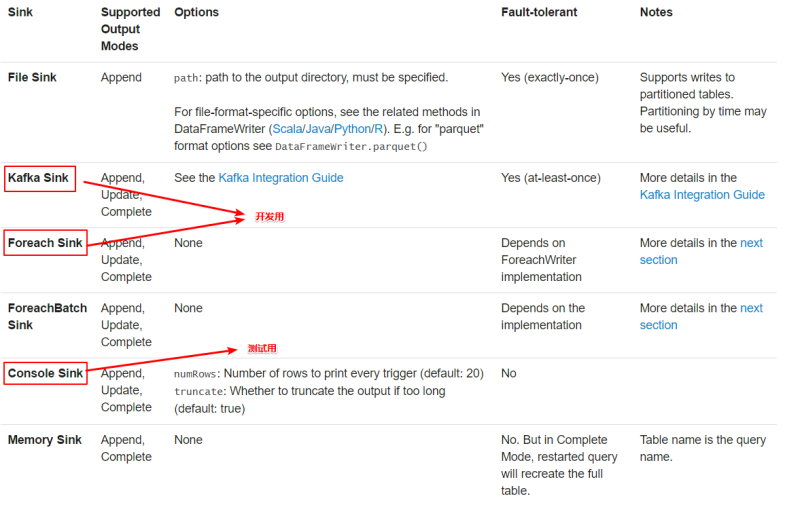
output mode
1.Append mode:默认模式,新增的行才输出,每次更新结果集时,只将新添加到结果集的结果行输出 到接收器。仅支持那些添加到结果表中的行永远不会更改的查询。因此,此模式保证每行仅输出一次。例如,仅查询select,where,map,flflatMap,fifilter,join等会支持追加模式。不支持聚合
2.Complete mode: 所有内容都输出,每次触发后,整个结果表将输出到接收器。聚合查询支持此功能。仅适用于包含聚合操作的查询。
3.Update mode:更新的行才输出,每次更新结果集时,仅将被更新的结果行输出到接收器(自Spark2.1.1起可用),不支持排序
output sink

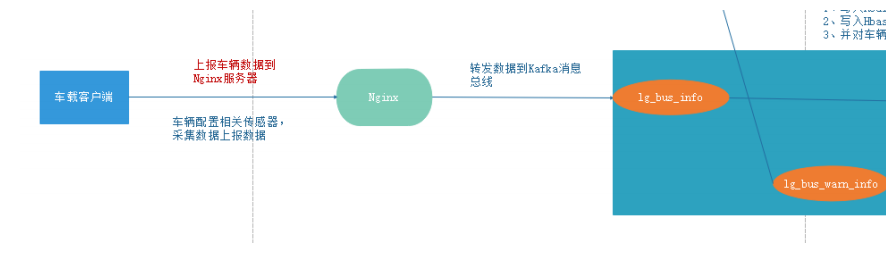
实时数据采集
一、主要架构
- 通过nginx整合kafka的生产者的代码,将消息发送到kafka指定的topic中
- 发送消息到nigix,会由kafka的生产者自动生产到指定主题,在通过消费者去消费
二、模拟车载客户端采集数据
java程序模拟
- 传感器信息模拟

- 处理http消息

- 主程序,拼接消息

接收消息示意: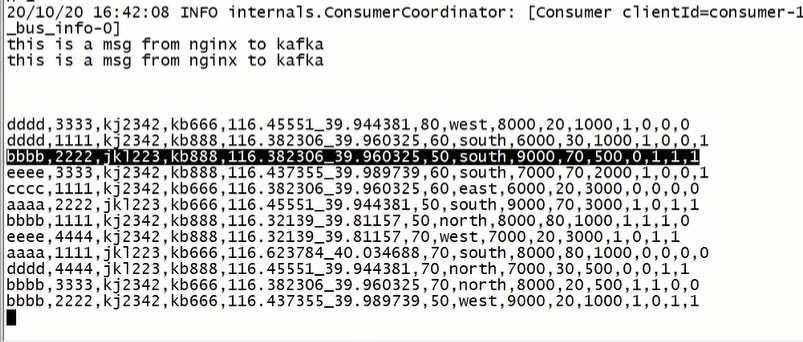
轨迹数据处理
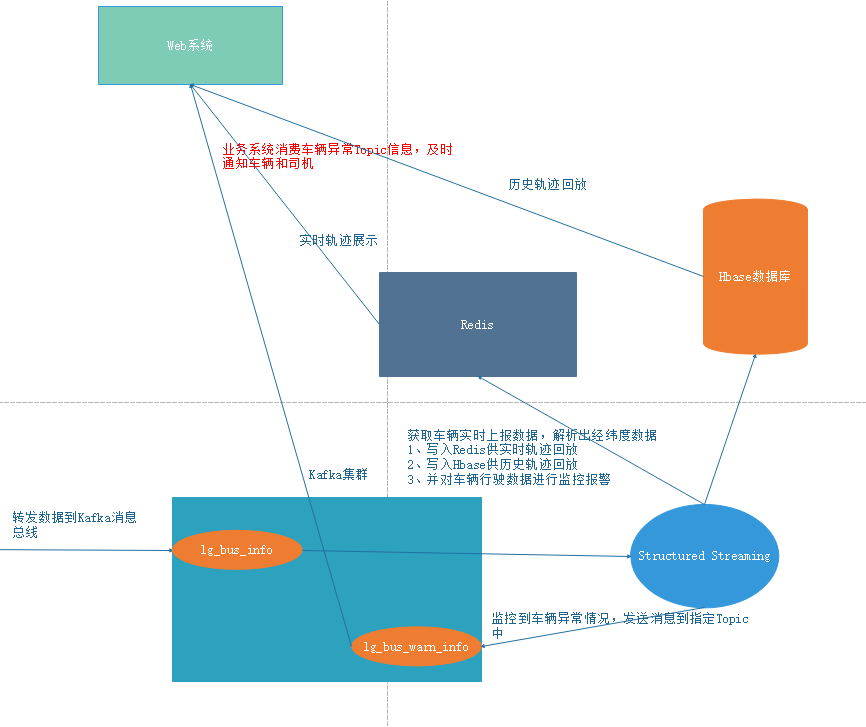
Structured Streaming整合Kafka
数据写入Redis


数据写入Hbase
实现HbaseWriter处理数据
- rowkey设计:

ETL数据仓库

若有收获,就点个赞吧
0 人点赞
