

一、基本语法
数据操作
数据导入
Load
从本地路径加载,加载完本地文件仍然存在
load data local inpath ‘…/‘ [overwrite] into table t1;
从hdfs加载,加载完文件已经被转移
load data inpath ‘../‘ [overwrite] into table t1;
Insert
插入查询结果数据
insert into table t1 partition(…) values (),()…
insert into table t1 partition(…) select … from …where…
as select
import
数据导出
小结
DDL命令
建库
建表
内部表 & 外部表

分区表

备注:分区字段不是表中已经存在的数据,可以将分区字段看成伪列 
加载数据到指定分区
分桶表

创建分桶表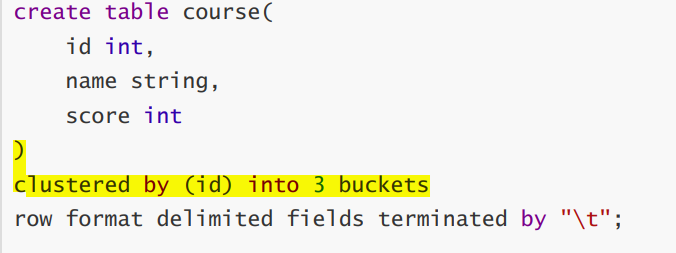
注意:加载数据时,先给普通表load,再采取insert into的方式给桶表插入。(必须以普通表为跳板)
- 分桶规则:分桶字段.hashCode % 分桶数
分桶表加载数据时,使用 insert… select … 方式进行
网上有资料说要使用分区表需要设置 hive.enforce.bucketing=true,那是Hive
1.x 以前的版本;Hive 2.x 中,删除了该参数,始终可以分桶;
修改表 & 删除表
alter table …
—rename to
—change column
—add colums…
DQL [重中之重]
1.基本查询
1、列别名 asselect ``current_date ``as ``currdate;``
2、对列使用函数sum(sal)后一般也要跟一个别名,方便后面查询
2.where & group by
注意:后面都不能使用列的别名
WHERE子句紧随FROM子句,使用WHERE子句,过滤不满足条件的数据
- where子句针对表中的原始数据发挥作用;having针对查询结果(聚组以后的结果)发挥作用
- where子句不能有分组函数;having子句可以有分组函数
GROUP BY语句通常与聚组函数一起使用,按照一个或多个列对数据进行分组,对每个组进行聚合操作。
- group by 分组后的数据,再进行筛选只能用having,不能使用where
- having只用于group by分组统计之后
3.表连接
注意连接条件on,以及一般给表取别名方便调用。
Hive总是按照从左到右的顺序执行,Hive会对每对 JOIN 连接对象启动一个MapReduce 任务。
4.排序子句
注意:
—可以按照别名排序
—可以多列排序
—排序字段 必须 出现在select子句中
全局排序(order by)
每个MR内部排序(sort by)
分区排序(distribute by)
Cluster By
排序小结

系统函数
日期函数【重要】
— 时间戳转日期
— 日期转时间戳
— 字符串转时间(字符串必须为:yyyy-MM-dd格式)
条件函数【重要】
if语句
case when【常用】

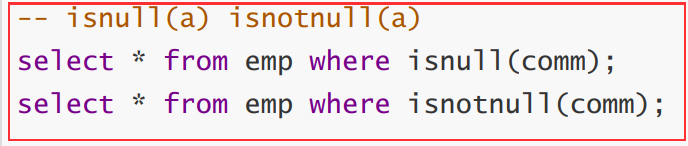
isnull
nvl
—替换空值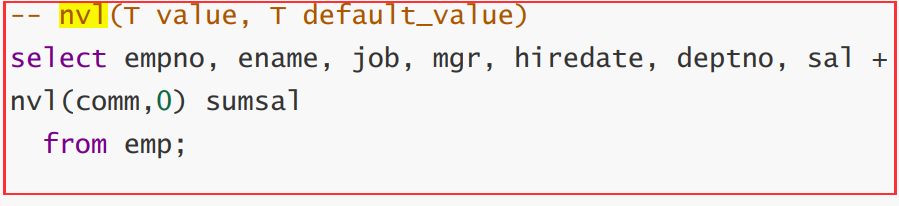
UDTF函数【重要】
explode
— 就是将一行中复杂的 array 或者 map 结构拆分成多行
lateral view
语法:lateral view udtf() 表名 as 列名;
lateral view 常与 表生成函数explode结合使用 ,解决 UDTF 不能添加额外列的问题
案例分析1:
001 1,2,3
002 1,2
将其转化为:
001 1
001 2
001 3
002 1
002 2
第一步:先split将字符串转为数组array
第二步:使用explode对array进行拆分
第三步:lateral view 加入uid字段
案例分析2:详见课件,不在这里整理。

错误使用:
正确:

或者等价于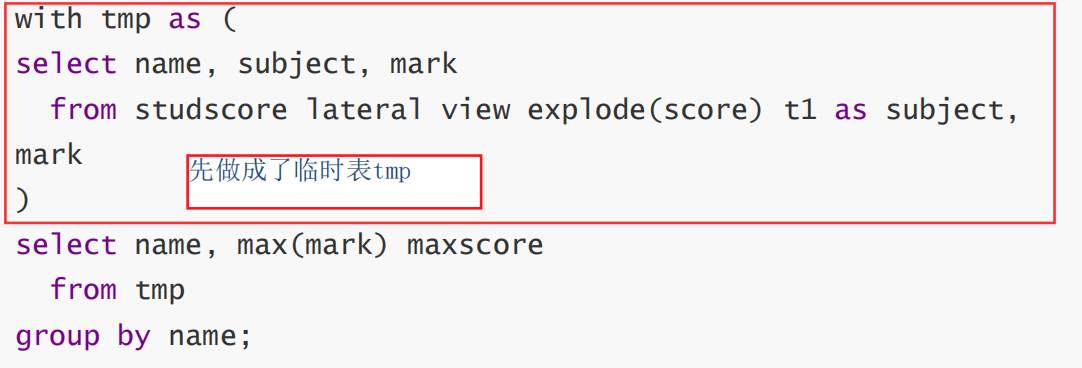
窗口函数【重要】

1. over 关键字
- 使用窗口函数之前一般要要通过over()进行开窗

2. partition by子句
- 在over窗口中进行分区,对某一列进行分区统计,窗口的大小就是分区的大小

3. order by 子句
order by 子句对输入的数据进行排序
- 注意 order by + sum,实现累计和
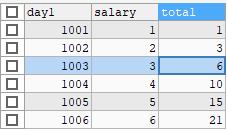

4. Window子句(更细划分)
5. 排名函数


6. 序列函数


二、案例练习
SQL常见面试题(第7-2部分)
1.连续值求解问题
1)按照uid开窗,日期排序row_number
2)日期-row_number 得到gid
3)按照uid,gid进行group by,筛选count >= 7天的数据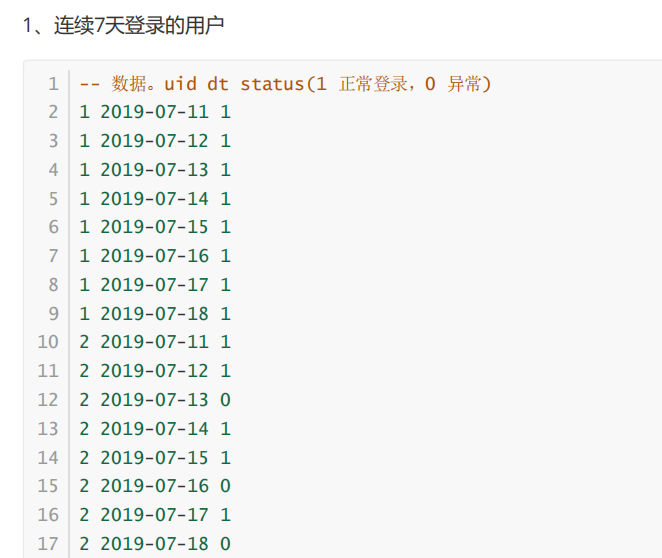
步骤:
- 使用 row_number 在组内给数据编号(rownum)
select uid,dtrow_number() over( partition by uid order by dt) rownumfrom uloginwhere status = 1; // 如果没有这一列,可以省略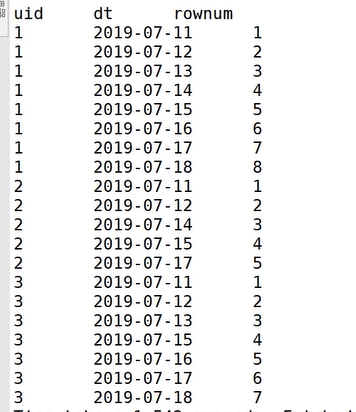
- 某个值 - rownum = gid,得到结果可以作为后面分组计算的依据
dt - rownumselect uid,dtrow_number() over( partition by uid order by dt) rownum
// date函数中不可以使用rownumdata_sub( dt,row_number() over( partition by uid order by dt) ) gidfrom uloginwhere status = 1; 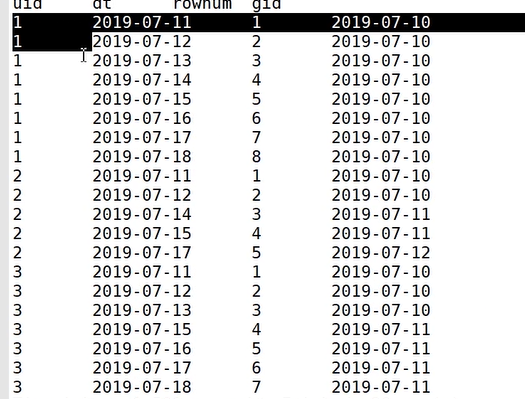 v
v
- 根据求得的gid,作为分组条件,求最终结果
select uid, count(*) logincount
from (select uid, dt,
date_sub(dt, row_number() over (partition by uid order by dt)) gid
from ulogin
where status=1) t1
group by uid, gid 非常关键!!连续的gid数值是相同的
having logincount>=7; 
2.TOPN问题
步骤:
— 上排名函数,分数一样并列,所以用dense_rank
— 将上一行数据下移,计算和前一位选手的分差,相减即得到分数差 (lag)
— 处理 NULL (nvl)
案例:统计每班成绩的前3名,并计算分差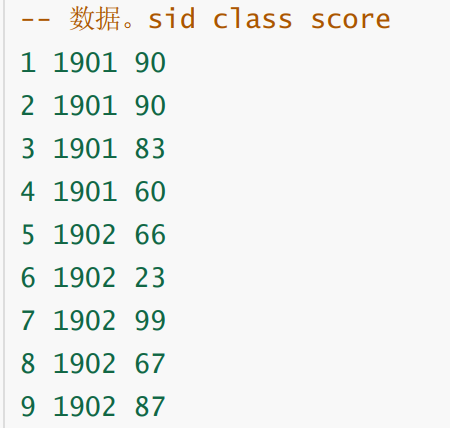
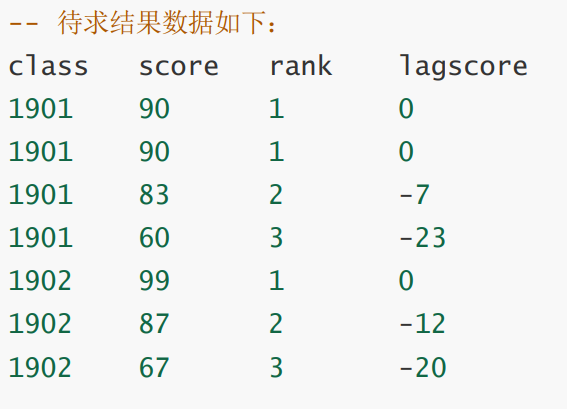
SQL:
— select sid,class,score,
dense_rank() over(partition by class order by socre) as rank
from stu;
— 首先打包以上查询为tmp
- 统计前三
with tmp as (
select sno, class, score,
dense_rank() over (partition by class order by score desc) as rank
from stu
)
- 计算分差
select class,score,rank,
nvl( score - lag(score) over (partition by class order by socre desc), 0) lagscore // 分差
from tmp
where rank <=3;
3.行转列问题
原始数据格式:
实现效果:
SQL实现:
为什么还要sum一下?(统计数量)
4.UDTF案例
实现一行输入,多行输出
explode(map,struct结构体) lateral view
表名:studscore 字段名:name,score
第一步: explodeselect explode(score) as (subject,score) from studsocre;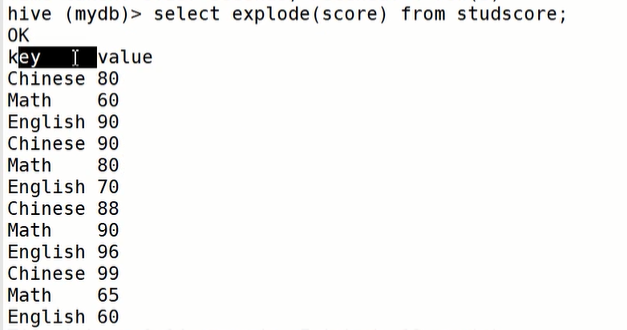
第二步:lateral view 关联其他非explode字段select name, subject,markfrom studscorelateral view explode(score) t1 as subject,mark;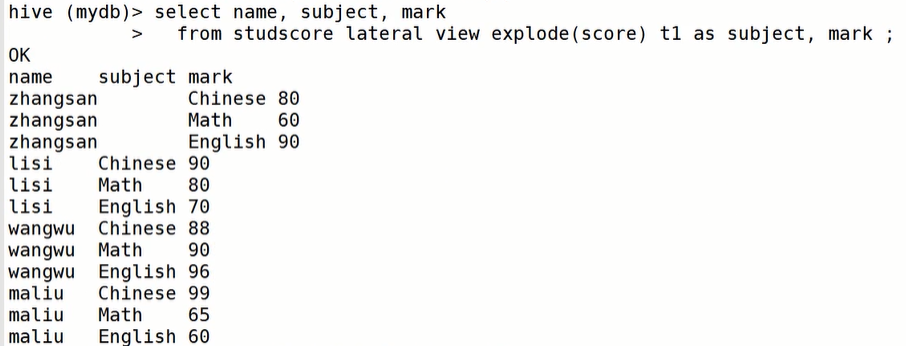
HIVE综合案例(第11部分)
三、面试题
本节内容参考高频面试题库~
1.Hive的结构组成?
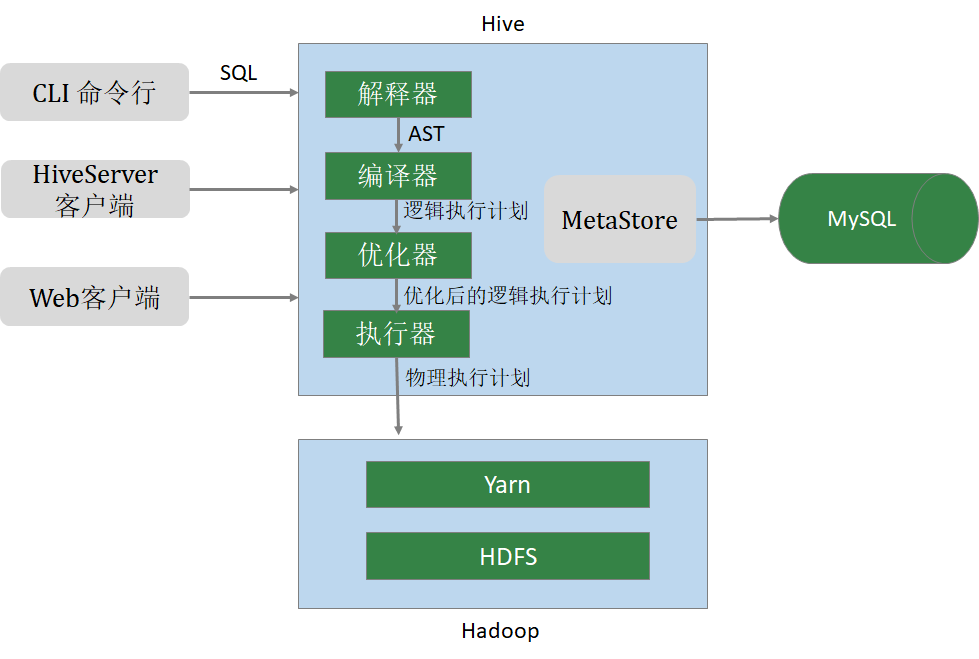
元数据管理(MetaStore)
- Hive将元数据存储在关系数据库中(如mysql、derby)。Hive的元数据包括:数据库名、表名及类型、字段名称及数据类型、数 据所在位置等;
驱动程序(Driver)
- 解析器 (SQLParser) :使用第三方工具(antlr)将HQL字符串转换成抽象语法树(AST);对AST进行语法分析,比如字段是否存在、SQL语义是否有误、表是否存在;
- 编译器 (Compiler) :将抽象语法树编译生成逻辑执行计划;
- 优化器 (Optimizer) :对逻辑执行计划进行优化,减少不必要的列、使用分区等;
- 执行器 (Executr) :把逻辑执行计划转换成可以运行的物理计划;
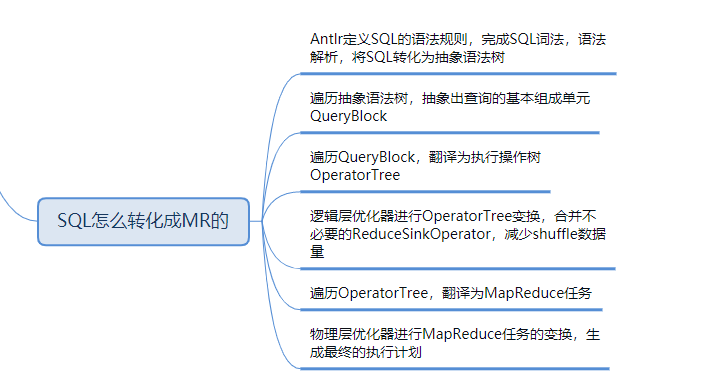
1.1 SQL转MR任务过程?
2.Hive和传统数据库比较?
- 查询语言相似。HQL <=> SQL 高度相似
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询
语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
- 数据规模。Hive存储海量数据;RDBMS只能处理有限的数据集;
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模
的数据;而RDBMS可以支持的数据规模较小。
- 执行引擎。Hive的引擎是MR/Tez/Spark/Flink;RDBMS使用自己的执行引擎
Hive中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而RDBMS
通常有自己的执行引擎。
- 数据存储。Hive保存在HDFS上;RDBMS保存在本地文件系统 或 裸设备
Hive 的数据都是存储在 HDFS 中的。而RDBMS是将数据保存在本地文件系统或裸设
备中。
- 执行速度。Hive相对慢(MR/数据量);RDBMS相对快;
Hive存储的数据量大,在查询数据的时候,通常没有索引,需要扫描整个表;加之
Hive使用MapReduce作为执行引擎,这些因素都会导致较高的延迟。而RDBMS对数据
的访问通常是基于索引的,执行延迟较低。当然这个低是有条件的,即数据规模较小,
当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出并行的优
势。
- 可扩展性。Hive支持水平扩展;通常RDBMS支持垂直扩展,对水平扩展不友好
Hive建立在Hadoop之上,其可扩展性与Hadoop的可扩展性是一致的(Hadoop集群
规模可以轻松超过1000个节点)。而RDBMS由于 ACID 语义的严格限制,扩展行非常
有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右。
- 数据更新。Hive对数据更新不友好;RDBMS支持频繁、快速数据更新
Hive是针对数据仓库应用设计的,数据仓库的内容是读多写少的。因此,Hive中不建
议对数据的改写,所有的数据都是在加载的时候确定好的。而RDBMS中的数据需要频
繁、快速的进行更新。
3.默认分隔符?

字段:不同列名
元素:hobby下有 game和sport
键值对:语文:80 英语:90
4.内部表和外部表?
desc formatted t1; 查看表的详细结构信息
- 内部表(管理表)
- 表的定义(元数据)和数据 均被删除
- 外部表
- create external table t2
- 只删除表的定义
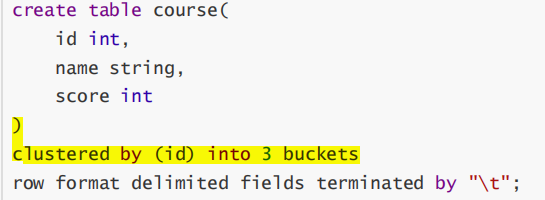
5.分桶表?
分桶规则:
- 分桶字段.hashCode % 分桶个数
步骤:
- 先创建普通表
- 在创建分桶表
- 从普通表中select数据insert到分桶表中
6.四个by的区别?
- Sort By 分区内有序
- sort by为每个reduce产生一个排序文件,在reduce内部进行排序,得到局部有序的结果;
- Order By 全局有序
- 只有一个reduce; 出现在select语句的结尾;对最终的结果进行排序。
- Distrbute By 先分区再排序
- 要写在sort by之前;
- 类似于MR中的分区操作,可以结合sort by操作,使分区数据有序;

解释:先按 deptno 分区,在分区内按 salcomm 排序
- cluster by 先分区再排序
- 当 Distribute by 和 Sorts by 字段相同时,可以使用 Cluster by 方式 简化。
- 只能升序
7.排名函数
见上~
8.Hive优化方法?
详见Hive讲义第十部分—hive调优策略
- MapJoin
- hive默认在reduce端进行join
- 行列过滤
- 列处理:在 SELECT 中,只拿需要的列,如果有,尽量使用分区过滤,少用 SELECT *。
- 行处理:在分区剪裁中,当使用外关联时,如果将副表的过滤条件写在 Where 后面, 那么就会先全表关联,之后再过滤。(先过滤,再关联??)
- 列式存储
- 采用分区技术
- 合理设置 Map 数
- 通常情况下,作业会通过 input 的目录产生一个或者多个 map 任务。
- 决定因素有:input 的文件总个数,input 的文件大小,集群设置的文件块大小。
- 是不是 map 数越多越好?
- 答案是否定的。如果一个任务有很多小文件(远远小于块大小 128m),则每个小文件也会被当做一个块,用一个 map 任务来完成,而一个 map 任务启动和初始化的时间远远大 于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的 map 数是受限的。
- 是不是保证每个 map 处理接近 128m 的文件块,就高枕无忧了?
- 不一定。比如有一个 127m 的文件,正常会用一个 map 去完成,但这个文件只有一个或者两个小字段,却有几千万的记录,如果 map 处理的逻辑比较复杂,用一个 map 任务去做,肯定也比较耗时。
针对上面的问题 2 和 3,我们需要采取两种方式来解决:即减少 map 数和增加 map 数;
- 小文件进行合并
- 在 Map 执行前合并小文件,减少 Map 数:CombineHiveInputFormat 具有对小文件进行 合并的功能(系统默认的格式)。HiveInputFormat 没有对小文件合并功能。
- 合理设置 Reduce 数
- 不是越多越好
- 有多少个 Reduce,就会有多少个输出文件,如果生成了很多个小文件,那 么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题;
- 两个原则:处理大数据量利用合适的 Reduce数;使单个 Reduce 任务处理数据量大小要合适;
- 开启 map 端 combiner(不影响最终业务逻辑)
- 压缩(选择快的)
- 设置 map 端输出、中间结果压缩。(不完全是解决数据倾斜的问题,但是减少了 IO 读 写和网络传输,能提高很多效率)
- 开启 JVM 重用
9. Hive 解决数据倾斜方法?
- 常见现象?
- 除了某个reduce(某分区内数据太多),其余的都已经执行完毕,处于等待状态。
- 解决方法?
(1)group by
解决方式:采用 sum() group by 的方式来替换 count(distinct)完成计算。
(2)mapjoin
(3)开启数据倾斜时负载均衡 (两次MR任务)set hive.groupby.skewindata=true;
操作:当选项设定为 true,生成的查询计划会有两个 MRJob。
第一个 MRJob 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 GroupBy Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;
第二个 MRJob 再根据预处理的数据结果按照 GroupBy Key 分布到 Reduce 中(这个过程可以保证相同的原始 GroupBy Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
理解:它使计算变成了两个 mapreduce,先在第一个中在 shuffle 过程 partition 时随机给 key 打标记,使每个 key 随机均匀分布到各个 reduce 上计算,但是这样只能完成部分计算,因为相同 key 没有分配到相同 reduce 上。
所以需要第二次的 mapreduce,这次就回归正常shuffle,但是数据分布不均匀的问题在第 一次 mapreduce 已经有了很大的改善,因此基本解决数据倾斜。因为大量计算已经在第一次 mr 中随机分布到各个节点完成。
(4)控制空值分布
将为空的 key 转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分不到多个 Reducer。
注:对于异常值如果不需要的话,最好是提前在 where 条件里过滤掉,这样可以使计算量大大减少。
10.Hive 里边字段的分隔符用的什么?为什么用\t?有遇到过字段里边有\t 的情况吗,怎么处理的?
hive 默认的字段分隔符为ascii 码的控制符\001(^A),建表的时候用 fields terminated by ‘\001’ 。
遇到过字段里边有\t 的情况,自定义 InputFormat,替换为其他分隔符再做后续处理
11.Hive中文件存储格式?
Hive支持的存储数的格式主要有:TEXTFILE(默认格式) 、SEQUENCEFILE、 RCFILE、ORCFILE、PARQUET。
- textfile为默认格式,建表时没有指定文件格式,则使用TEXTFILE,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;
- sequencefile,rcfile,orcfile格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从表中用insert导入sequencefile、rcfile、 orcfile表中。
- TEXTFILE、SEQUENCEFILE 的存储格式是基于行存储的;
- ORC和PARQUET 是基于列式存储的。
详细介绍:
- TEXTFILE(基础)
- Hive默认的数据存储格式,数据不做压缩,磁盘开销大,数据解析开销大。
- SEQUENCEFILE(基础)
- 二进制文件格式,其具有使用方便、可分割、可压缩的特点。一般建议使用BLOCK压缩。
- RCFILE(熟悉)
- 是一种类似于SequenceFile的键值对数据文件
- 基于行列混合存储的RCFile
- 先水平划分(行组row group),再垂直划分(列式存储数据)
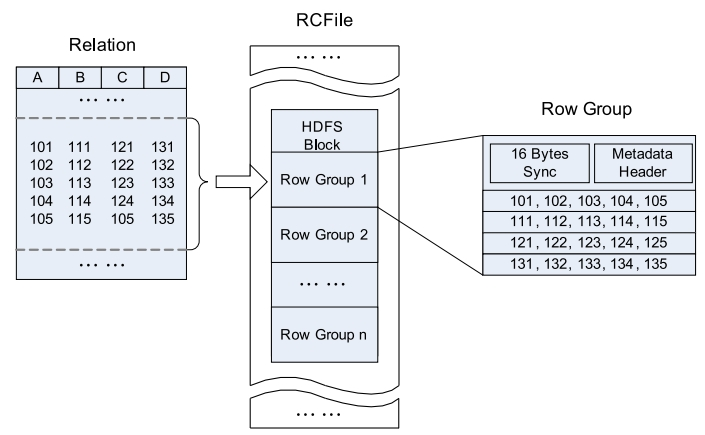
- ORCFILE(暂时不作要求)
- PARQUET(熟悉)
- 新型列式存储格式
- 二进制方式存储的,不能直接读取的
下图是一个行组row group的示例: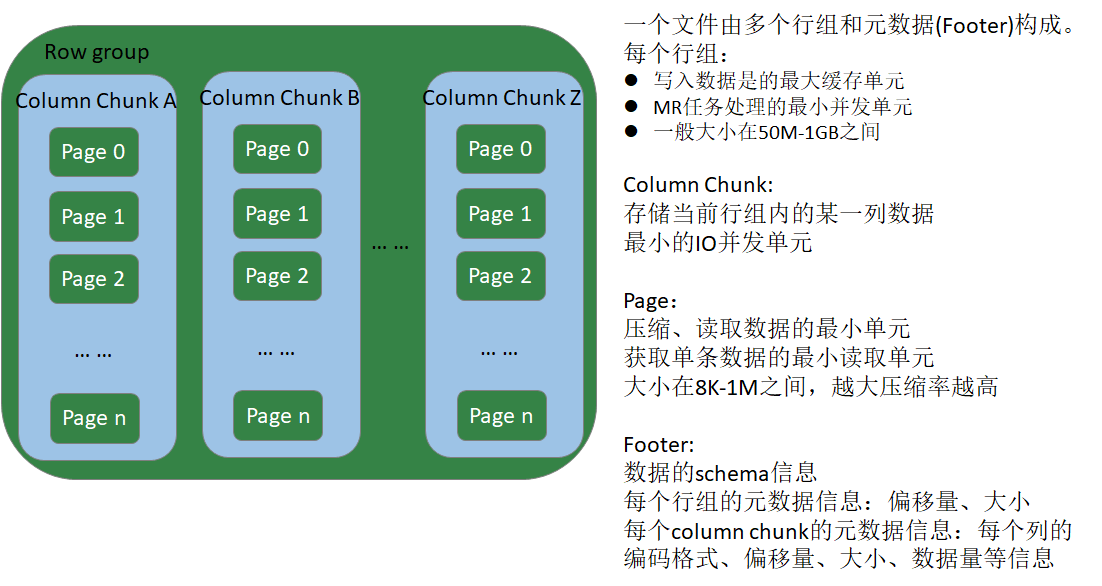

若有收获,就点个赞吧
0 人点赞
