观察者
负责将事件分类
- process.nextTick —— idle 观察者,效率最高,消耗资源小,但是会阻塞 CPU 的后续调用
- setTimeout —— IO 观察者,精确度不高,可能有延迟执行的情况发生,且因为动用了红黑树,所以资源消耗大
- setImmediate —— check 观察者,消耗的资源小,也不会造成阻塞,但是效率是最低的
优先级:idle 观察者 => Promise.then => IO 观察者 => check 观察者
macro-task:script 整体代码,setTimeout,setInterval,setImmediate,IO,UI rendering
micro-task:process.nextTick,Promise,Object.observe,MutationObserver
Node.js 运行原理
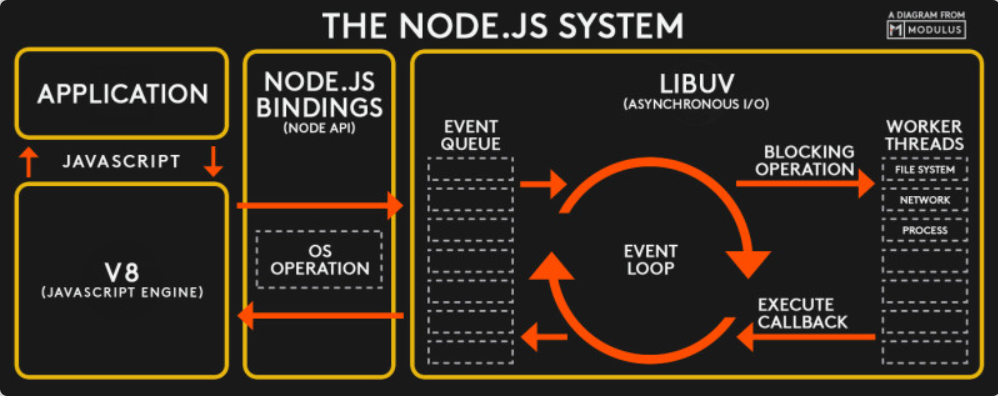
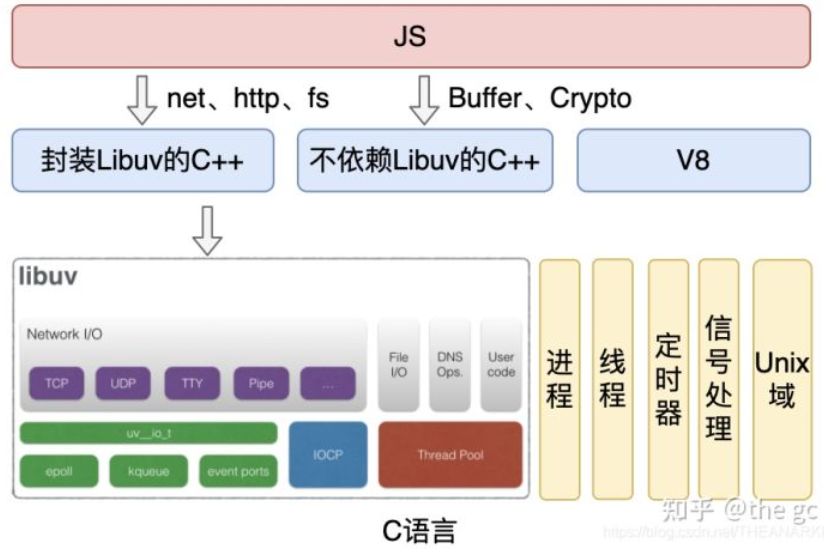
- 应用层:JavaScript 交互层,常见的就是 Node.js 的模块,比如 http, fs
- V8 引擎层:利用 V8 引擎来解析 JavaScript 语法,进而和下层 API 交互
- Node API 层:为上层模块提供系统调用,一般由 c 语言来实现,和操作系统进行交互。
- LIBUV 层:是跨平台的底层封装,实现了事件循环、文件操作等,是 Node.js 实现异步的核心
事件循环
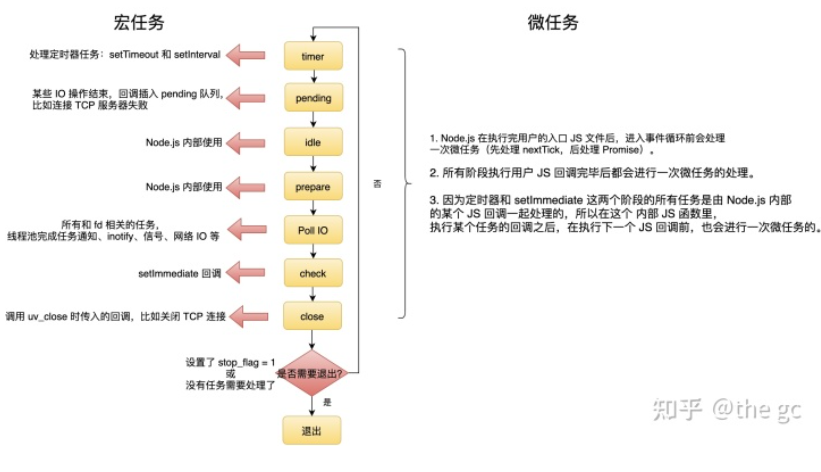
Nodejs 的事件循环分为7个阶段
timer 阶段主要是处理定时器相关的任务,pending 阶段主要是处理 poll IO 阶段回调里产生的回调。check、prepare、idle 阶段是自定义的阶段,这三个阶段的任务每次事件循环都会被执行。poll io 阶段主要是处理网络IO、信号、线程池等任务。closing 阶段主要是处理关闭的 handle,比如关闭服务器事件循环是 Node.js 处理非阻塞 I/O 操作的机制 事件循环让 Node.js 可以通过将操作转移到系统内核中来执行非阻塞 I/O 操作
┌───────────────────────┐┌─>│ timers ││ └──────────┬────────────┘│ ┌──────────┴────────────┐│ │ I/O callbacks ││ └──────────┬────────────┘│ ┌──────────┴────────────┐│ │ idle, prepare ││ └──────────┬────────────┘ ┌───────────────┐│ ┌──────────┴────────────┐ │ incoming: ││ │ poll │<─────┤ connections, ││ └──────────┬────────────┘ │ data, etc. ││ ┌──────────┴────────────┐ └───────────────┘│ │ check ││ └──────────┬────────────┘│ ┌──────────┴────────────┐└──┤ close callbacks │└───────────────────────┘
- timers:此阶段执行已经被 setTimeout 和 setInterval 的回调函数调度
这里面的定时器也是不准的,因为在指定时间过后,系统调度或者其他回调的执行可能延迟它们 - pending callbacks:处理 poll io 阶段回调里产生的回调
- idle/prepare:仅在 Node.js 内部使用
- poll:检索新的 I/O 事件,执行与 I/O 相关的回调(几乎所有情况下,除了关闭的回调函数,那些由计时器和 setImmediate()调度的之外),node 将在此阻塞。
poll 阶段控制 timers 什么时候执行 - check:
setImmediate()在这里调用回调,setImmediate 并不是立马执行,而是当事件循环 poll 中没有新的事件处理时就执行该部分,即先执行回调函数,再执行 setImmediate - close callbacks:一些关闭回调,例如
socket.on('close', ...)
每个阶段都有一个 FIFO (先进先出) 队列来执行回调。
当事件循环进入给定的阶段,它将执行特定于该阶段的任何操作,然后执行该阶段队列中的回调,直到队列用尽或最大回调数已执行。当该队列已用尽或达到回调限制,事件循环将移动到下一阶段
轮询
功能:
- 计算应该阻塞和轮询 I/O 的时间。
- 然后,处理轮询队列里的事件。
当事件循环进入轮询阶段且 没有被调度的计时器时,将发生以下两种情况之一:
- 如果轮询队列不是空的,事件循环将循环访问回调队列并同步执行它们,直到队列已用尽,或者达到了与系统相关的硬性限制。
- 如果轮询队列是空的:
- 如果脚本被
setImmerdiate()调度,则事件循环将结束轮询阶段,并继续检查阶段(check)以执行那些被调度的脚本。 - 如果脚本未被
setImmediate()调度,则事件循环将等待回调被添加到队列中,然后立即执行
- 如果脚本被
一旦轮询队列为空, 事件循环将检查已达到时间阈值的计时器。如果一个或多个计时器已准备就绪,则事件循环将绕回计时器阶段以执行这些计时器的回调。
检查阶段
此阶段允许在轮询阶段完成后立即执行回调。如果轮询阶段变为空闲状态,并且脚本使用setImmediate()后被排列在队列中,则事件循环可能继续到 检查阶段 而不是等待
通常,在执行代码时,事件循环最终会命中轮询阶段,在那等待传入连接、请求等。但是,如果回调已使用setImmediate()调度过,并且轮询阶段变为空闲状态,则它将结束此阶段,并接续到检查阶段而不是继续等待轮询事件。
setImmediate() 对比 setTimeout()
- setImmediate 设计为当事件循环 poll 中没有新的事件处理时就执行该部分,即先执行回调函数,再执行 setImmediate
- setTimeout 在最小阈值(ms 单位)过后运行脚本
如果二者都从主模块内调用,则计时器将受进程性能的约束,所以先后顺序不确定。首先进入的是 timers 阶段,如果我们的机器性能一般,那么进入 timers 阶段,此时已经达到 setTimeout 的时间阈值,那么 setTimeout 回调会首先执行。如果没有达到,那么在 timers 阶段的时候,下限时间没到,setTimeout 回调不执行,事件循环来到了 poll 阶段,这个时候队列为空,于是往下继续,先执行了 setImmediate() 回调函数,之后在下一个事件循环再执行 setTimeout 的回调函数
总结:我们在 执行启动代码 的时候,进入 timers 的时间延迟其实是随机的,并不是确定的,所以会出现两个函数执行顺序随机的情况。
如果二者放入一个 I/O 循环内调用,setImmediate 总是被优先调用
// timeout_vs_immediate.jsconst fs = require('fs')fs.readFile('./hook.js', () => {setTimeout(() => {console.log('timeout')}, 0)setImmediate(() => {console.log('immediate')})})// immediate// timeout// fs.readFile 的回调是在 poll 阶段执行的,当其回调执行完毕之后,// poll 队列为空,而 setTimeout 入了 timers 的队列,此时有代码 setImmediate ,// 于是事件循环先进入了 check 阶段执行回调,之后在下一个事件循环再在 timers 阶段中执行回调。
使用 setImmediate() 相对于 setTimeout 的主要优势是,如果 setImmediate 在 I/O 周期内被调度的,那它将会在其中任何的定时器之前执行。跟这里存在多少个定时器无关。
process.nextTick()
process.nextTick 从技术上讲不是事件循环的一部分。
所有传递到 process.nextTick() 的回调函数将在事件循环继续之前解析。这可能造成一些糟糕的情况,因为它允许你通过递归 process.nextTick() 调用来饿死你的 I/O (让事件循环机制无法进入下一个阶段),阻止事件循环到达轮询阶段。
let barfunction someAsyncApiCall(callback) {callback()}someAsyncApiCall(() => {console.log('bar', bar)})bar = 1// bar undefined
因为在调用 someAsyncApiCall 时,提供给它的回调是在事件循环的同一阶段内被调用,因为 someAsyncApiCall() 实际是同步执行的。结果,回调函数在尝试引用 bar,但作用域中可能还没有该变量,因为脚本尚未运行完成。
通过将回调置于 process.nextTick() 中,允许在调用回调之前初始化所有的变量、函数等。它还具有不让事件循环继续的优点,适用于让事件循环继续之前,警告用户发生错误的情况。
let barfunction someAsyncApiCall(callback) {process.nextTick(callback)}someAsyncApiCall(() => {console.log('bar', bar)})bar = 1// bar 1
process.nextTick 对比 setImmediate
- process.nextTick 在同一个阶段立即执行
- setImmediate 在事件循环的接下来的迭代或 ‘tick’ 上触发
process.nextTick 比 setImmediate 触发的更快
process.nextTick 对比 Promise
这两个都可以理解为一个微任务。 nextTick 的优先级比 promise 高。
什么是线程池?Node 中哪个库去处理它?
线程池由 libuv 处理。
libuv 是一个多平台 C 库,支持异步 I/O 的操作,例如文件系统、网络和并发
RPC
node rpc
远程过程调用,其实就是像调用本地函数一样调用其他进程或者机器上的函数
我们常见的 RPC 协议有基于 HTTP 的,有基于 TCP 的。
比如,我们常用的客户端和服务端的通信协议就是 REST 协议,也就是 HTTP JSON 的方式。
这种方式的优点是:实现简单、标准化,很适合对外的 OpenAPI 的场景;而它的缺点就是 HTTP 传输效率低,短连接开销大,有用信息少,包含了大量了 HTTP 头部
常用于内网通信的是基于 TCP 的 RPC 协议,优点是:能更灵活地对协议的字段进行定制,减少网络开销提高性能,实现更大的吞吐量和并发数。
缺点就是:需要更多的关注底层复杂的细节,跨平台难度大,实现代价更高,比较适合内部系统之间追求极致的性能的场景。
在 Node 中实现 RPC 主要就是对 Buffer 的操作。设计 RPC 的构成需要 Header + Payload(类似于 HTTP 的 body)。
与 ajax 通信不同的是 RPC 协议采用的是二进制协议,也就是二进制流的方式,所以这里涉及到序列化和反序列化。
序列化:数据结构或对象转换成二进制串
反序列化:二进制串转换成数据结构或对象
package.json 字段
name —— 必需
version —— 必需
description
keywords []
homepage
license
files
就是你的包作为依赖项被别人下载的时候在别人的node_modules下这个包会包含哪些文件,你可以在 files 数组里指定
可以提供一个 .npmignore 文件来指定排除哪些文件,但是 files 字段中包含的文件不能通过这个排除。
无论如何设置,始终包含 package.json、README、LICENSE、主字段中的文件
repository
author
typings
声明文件和你的 JavaScript 一起传递
如果主声明文件名是 index.d.ts 并且位置在包的根目录(与index.js并列),就不需要指定了
main
定义这个package的入口文件位置,如果没有设定,那么会去找根目录的index.js
在不支持ES6的nodejs中,指向的是cjs模块系统的入口位置
在支持es6的nodejs版本中,只要显示定义type: module就指向es模块系统的位置
module
browser
exports
可以按要求指定用户使用不同语法和路径时导入你的哪个包
优先级比 main 字段高
用法
"exports": {".": {"import": "./dist/fre.js","require": "./dist/fre.umd.js"},"./jsx-runtime": {"import": "./jsx-runtime.js","require": "./jsx-runtime.js"}}
这样引入的时候
如果是 import 引入,那么就会找 dist/fre.js,如何是 require 引入,就会找 dist/fre.umd.js
main、module、browser的优先级
- webpack+ web + esm:
browser = browser+ mjs > module > browser+cjs > main - webpack + web + commonjs:
browser = browser+ mjs > module > browser+cjs > main在构建web应用时,使用esm或cjs对加载优先级没有影响 - webpack + node + esm/cjs:module > main
- node + cjs:只有main字段有效
- node + esm:只有main字段有效
Koa 的洋葱模型
What
Koa 的洋葱模型是以 next()函数为分割点,先由外到内执行 Request 的逻辑,然后再由内到外执行 Response 的逻辑,这里的 request 的逻辑,我们可以理解为是 next 之前的内容,response 的逻辑是 next 函数之后的内容,也可以说每一个中间件都有两次处理时机。
Why
因为很多时候,在一个 app 里面有很多个中间件,有些中间件需要依赖其他中间件的结果,洋葱模型可以保证执行的顺序,如果没有洋葱模型,执行顺序可能出乎我们的预期。
比如,前面的中间件需要使用到后面中间件添加的东西,从头到尾链式调用是做不到的。
How
compose
在 node 中如何查看请求的耗时?
- 如果是在 Koa 中,由于有洋葱模型,我们可以先记录一下时间,然后使用
next()中转控制权,在下一个中间件里面请求,在next()下面再记录一下时间,这时候请求就已经响应结束了,两个时间相减就是请求的耗时 - 使用
process.hrtime,首先用这个记录时间,然后在 http.request 里面监听 end 事件,在 end 事件里使用process.hrtime记录时间,然后两个时间相减就行了
RESTful 架构
是什么
Representational State Transfer -> 表现层状态转化
表现层,资源是一种信息实体,它可以有很多外在表现形式。我们把资源具体呈现出来的形式,叫做它的表现层
状态转化:访问一个网站,就是客户端和服务器的一个互动过程,在这个过程中,肯定要涉及数据和状态的变化。HTTP 协议是一个无状态的协议,这就意味着所有的状态都保存在服务端,因此,如果客户端想要操作服务器,必须通过某种手段,让服务端发生“状态转化”。而这种转化是建立在表现层之上的,所以就是表现层状态转化。客户端用到的手段,只能是 HTTP 协议。具体来说,就是 HTTP 协议里面四个表示操作方式的动词,GET、POST、PUT、DELETE。分别对应四种操作:GET 获取资源,POST 新建资源(也可以用来更新)、PUT 更新资源、DELETE 删除资源。
总结:RESTful 架构就是:
- 每一个 URI 代表一种资源
- 客户端和服务器之间,传递这种资源的某种表现层
- 客户端通过四个 HTTP 动词,对服务器端资源进行操作,实现表现层状态转化
设计
URI 不能包含动词。因为资源表示一种实体,所以应该是名词,动词应该放在 HTTP 协议中
URI 中不要加入版本号,因为不同的版本,可以理解为同一种资源的不同表现形式,所以应该采用同一个 URI,版本号可以在 HTTP 请求头的 Accept 字段中进行区分
NPM
运行npm run的时候,npm会先在当前目录的 node_modules/.bin查找要执行的程序,如果找到则运行。如果没有找到,则从全局的node_modules/.bin中查找,如果全局中还没有找到,那么就从系统的环境变量中查找同名的可执行程序。
NPM 的安装机制
优先将依赖包安装在当前项目目录,使得不同项目的依赖各成体系,同时还减轻了包作者的 API 兼容性压力
缺点:同一个依赖包可能会在我们电脑上安装两遍
流程:
- 检查并获取 npm 配置:命令行设置的 npm 配置 => env 环境变量设置的 npm 配置 => 项目级的
.npmrc文件=> 用户级的.npmrc文件(~/.npmrc) => 全局级的.npmrc文件($PREFIX/etc/npmrc) => npm 内置的.npmrc文件(/path/to/npm/npmrc) - 检查项目中是否有 package-lock.json 文件
- 如果有
- 一致,直接使用 package-lock.json 中的信息,从缓存或网络资源中加载依赖
- 不一致,按照 npm 版本进行处理,目前是如果 package.json 声明的依赖版本规范和 package-lock.json 安装版本兼容,则根据 package-lock.json 安装;如果不兼容,按照 package.json 安装,并更新 package-lock.json
- 如果没有,则根据 package.json 递归构建依赖树,按照构建好的依赖树下载完整的依赖资源,下载时会检查是否存在相关资源缓存 - 存在,则将缓存内容解压到 node_modules 中 - 不存在,从 npm 远程仓库下载包,检验包的完整性,并添加到缓存,同时解压到 node_modules
- 如果有
最后生成 package-lock.json
构建依赖树时,当前依赖项目不管是直接依赖还是子依赖的依赖,都应该按照扁平化原则,优先将其放置在 node_modules 根目录。在这个过程中,遇到相同的模块就判断已放置在依赖树中的模块版本是否符合新模块的版本范围,如果符合就跳过,否则就在当前模块的 node_modules 下放置该模块
npm 的缓存机制
缓存存在_cacache文件夹中
- content-v2:二进制文件。扩展名改为 .tygz,然后解压,得到的结果就是 npm 包的资源
- index-v5:content-v2 的索引
- tmp
缓存如何被存储并被利用?
当 npm install 执行时,通过 pacote 把相应的包解压在对应的 node_modules 下面。npm 在下载依赖时,先下载到缓存中,再解压到项目的 node_modules 下。pacote 依赖 npm-registry-fetch 来下载包,npm-registry-fetch可以通过设置 cache 属性,在给定的路径下生成缓存数据。
接着,在每次安装资源时,根据 package-lock.json 的 integrity、version、name 信息生成一个唯一的key,这个 key 能够对应到index-v5目录下的缓存记录,如果发现有缓存资源,就会找到 tar 包的 hash,根据 hash 再去找缓存的 tar 包,并再次通过pacote把对应的二进制文件解压到相应的 node_modules 下面,省去了网络下载资源的开销
npm link
- 为目标 npm 模块创建创建软链接,将其链接到全局 node 模块安装路径中
- 为目标模块的可执行 bin 文件创建软链接到全局 node 命令安装路径的 bin 中
npx
npx 可以直接执行 **node_modules/.bin** 文件夹下的文件,在运行命令时,npx 可以自动去 node_modules/.bin 路径和环境变量$PATH 里面检查命令是否存在,而不需要再在 package.json 中定义相关的 script
npx 执行模块时会优先安装依赖,但是在安装执行之后会删除此依赖,这就避免了全局安装模块带来的问题
多源镜像和企业级部署私服原理
npm 中的源(registry),其实就是一个查询服务。以 npmjs.org 为例,它的查询服务网址是https://registry.npmjs.org,这个网址后面跟上模块名,**就会得到一个JSON对象**,里面是该模块所有版本的信息。
为什么需要一个私有 npm 镜像呢?
npm 下载速度缓慢,严重影响 CI/CD 流程或本地开发效率。部署镜像后,一般可以确保高速、稳定的 npm 服务,而且使发布私有模块更加安全,审核机制也可以保障私服上的 npm 模块质量和安全
镜像问题
Yarn
npm 还处在 v3 的时候,为了解决 npm 安装速度很慢,稳定性也较差的缺点
yarn 为一些问题提供了一些解决方案:
- 确定性:通过
yarn.lock等机制,保证了确定性。即不管安装顺序如何,相同的依赖关系在任何机器和环境下,都可以以相同的方式被安装 - 采用模块扁平安装模式:将依赖包的不同版本,按照一定的策略,归结为单个版本,以避免创建多个副本造成冗余
- 网络性能更好:Yarn 采用了请求排队的理念,类似并发连接池,能够更好地利用网络资源;同时引入了更好的安装失败时的重试机制
- 采用缓存机制,实现了离线模式
相比 npm,yarn 另外一个显著区别是 yarn.lock 中子依赖的版本号不是固定版本,这就说明单独一个 yarn.lock 确定不了 node_modules 目录结构,还需要和 package.json 文件进行配合
yarn 默认优先使用网络数据,如果网络数据请求丢失,再去请求缓存数据
yarn 安装机制
- 检测
- 解析包
- 获取包
- 链接包
- 构建包
检测:
检测项目中是否存在一些 npm 相关文件,比如 package-lock.json 等,如果有,会提示:这些文件的存在可能会导致冲突;在这个步骤中,也会检查 OS、CPU 等信息
解析包:
解析依赖树中每一个包的版本信息,首先获取当前项目中 package.json 中的 dependencies、devDependencies、optionalDependencies(找不到或者失败时可以跳过)的内容,这属于首层依赖
接着采用遍历首层依赖的方式获取依赖包的版本信息,以及递归查找每个依赖下嵌套依赖的版本信息,并将解析过和正在解析的包用一个 Set 数据结构来存储,这样就能保证同一个版本范围内的包不会被重复解析
对于没有解析的包 A,首次尝试从 yarn.lock 中获取版本信息,并标记为已解析
如果在 yarn.lock 中没有找到包 A,则向 Registry 发起请求获取满足版本范围的已知最高版本的包信息
至此,就确定了所有依赖的具体版本信息以及下载地址
获取包:
首先需要检查缓存中是否存在当前的依赖包,同时将缓存中不存在的依赖包下载到缓存目录(前提是 prefer-online 关闭了)
如何判断缓存中是否存在当前的依赖包?——其实 yarn 会根据 cacheFolder+slug+node_modules+pkg.name 生成一个 path,判断系统中是否存在该 path,如果存在证明有缓存,不用重新下载,这个 path 也就是依赖包缓存的具体路径
对于没有命中缓存的包,yarn 会维护一个 fetch 队列,按照规则进行网络请求。如果下载包地址是一个 file 协议,或者是相对路径,说明其指向一个本地目录,此时调用 Fetch From Local 从离线缓存中获取包;否则调用 Fetch From External 获取包。最终获取结果使用 fs.createWriteStream 写入到缓存目录下
为什么有 HTTP 还要用 RPC
序列化协议
json、xml、protobuf
Thrift 也是二进制协议

若有收获,就点个赞吧
0 人点赞
