- JavaScript如何运行的?
- 原型和原型链
- 闭包
- 执行上下文
- 代码执行的两个阶段
- 可迭代对象 和 可枚举属性
- for…in 和 for…of 的区别
- HashRouter 和 HistoryRouter 的区别
- 面向对象
- V8 的内存管理
- 如何通过扫描知道是没有引用的呢?
- 异步 I/O 的好处
- 元编程
- 手写 Symbol
- 函数式编程
- this 的指向问题总结
- 宏任务微任务,微任务队列,消息队列 题目
- 装箱与拆箱
- toString 和 toLocaleString 的区别
- Object.defineProperty 和 Proxy 比较
- 继承的多种方式
- try catch 能捕获 promise 的错误吗?🤔
- ajax 和 fetch 的区别
- Symbol
- 对象到原始值的转换
- npm 模块安装机制(为什么输入 npm install 就可以自动安装相关模块?)
- DOCTYPE 的作用
- JS 获取盒模型的高度和宽度
- 编译器转换代码的步骤
JavaScript如何运行的?
JS 代码 =》解析成AST(伴随词法分析、语法分析) =》生成字节码(V8)=》生成机器码(编译器)
原型和原型链
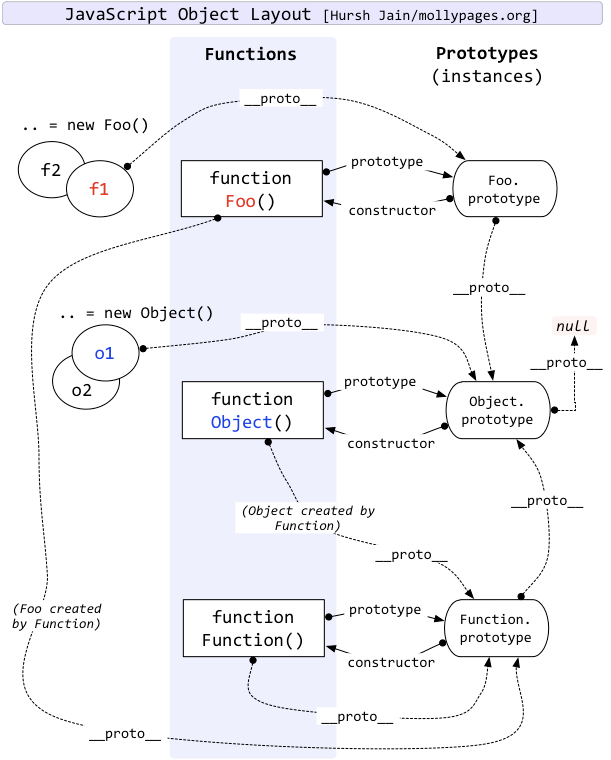
每个函数都又prototype属性,该属性指向原型
每个对象都有proto属性,指向该对象的构造函数的原型,其实这个属性指向了 [[prototype]],但是这个是内部属性,我们访问不到,所以用proto来访问。
对象可以通过__proto__来寻找不属于该对象的属性,__protot__将对象连接起来组成原型链
Function.prototype.a = () => alert(1)Object.prototype.b = () => alert(2)function A() {}const a = new A()console.log(A.prototype)a.a()a.b()
这个代码会报错,因为 a.a 找不到,因为 a 是挂载到 Function.prototype 上的,而不是挂载到 Object.prototype 上的,依照原型链查找规则是找不到的;如果想调用,得使用 constructor 找它的构造函数,通过a.constructor.__proto__.a()或者a.constructor.constructor.a()调用
闭包
闭包是一个函数以及捆绑的词法环境的组合,闭包可以让内部函数访问外部函数的作用域,在JavaScript中,闭包会随着函数的创建而同时被创建
我们知道在正常情况下外部函数是无法访问内部函数的,因为函数执行之后,上下文就会被销毁,但是在外层函数中返回了这个函数,而这个函数引用了外层函数的变量,那么外界便可以通过返回的函数访问原外层函数的变量值。
闭包在处理速度和内存消耗方面对脚本性能具有负面作用
闭包的作用:模块化、实现私有变量(模块模式)、块级作用域 、读取函数内部的变量
闭包的危害:引起内存泄漏,性能问题
执行上下文
定义:一段代码执行所需要的所有信息叫做”执行上下文“
执行上下文在 ES3 中,包含 3 个部分:
- scope:作用域,也常叫做作用域链
- variable object:变量对象,用于存储变量的对象
- this value:this 值
ES5 中,改进了命名方式:
- lexical environment: 词法环境,当获取变量时使用
- variable environment:变量环境,当声明变量时使用
- this value: this 值
ES2018 中,this 被归为了 lexical environment,同时增加了不少内容
- lexical environment: 词法环境,当获取变量或 this 值时使用
- variable environment:变量环境,当声明变量时使用
- code evaluation state:用于恢复代码执行位置
- Function:执行的任务是函数时使用,表示正在被执行的函数
- ScriptOrModule:执行的任务是脚本或模块时使用,表示正在被执行的代码
- Realm,使用的基础库和内置对象实例
- Generator:仅生成器上下文有这个属性,表示当前生成器
作用域
ES6 之前,只有 函数作用域 和 全局作用域。
作用域链
逐次向上查找,直到找到或者到达全局作用域
块级作用域
作用域限制在代码块中
let、const 与暂时性死区
就是在变量声明前不可访问。var 可以,因为 var 可以变量提升
函数参数默认值的问题
function foo(arg1 = arg2, arg2) {console.log(arg1, arg2)}foo('arg1', 'arg2') // 'arg1', 'arg2'
一个函数的第一个参数默认是第二个参数,如果第一个参数没有传递,则会使用第二个参数作为第一个参数的实参。但是执行arg1 = arg2会被当做暂时性死区处理。比如第一个参数传递undefined(注意,传递null并不会报错, arg1 会被当成null)。
在函数中用let声明变量,但是变量名和函数形参名字一样也会报错。这是由于函数参数名出现在其“执行上下文/作用域”中导致的。
代码执行的两个阶段
- 代码预编译阶段
代码预编译阶段会由编译器将 JavaScript 代码编译成可执行的代码。
对 JavaScript 代码中变量的内存空间进行分配,变量提升就是在这个阶段完成的。- 进行变量声明
- 对变量声明进行提升,但是值为 undefined
- 对所有非表达式的函数声明进行提升
- 代码执行阶段
代码执行阶段的主要任务是执行代码逻辑,执行上下文在这个阶段会全部创建完成。
总结:
- 第一道工序就是在 预编译阶段 创建变量对象(Variable Object VO),此时只是创建,而未进行赋值。
- 下一道工序代码执行阶段,变量对象会转为激活对象(Active Object AO),即完成 VO 向 AO 的转换。此时,作用域链也确定了。它由当前执行环境变量对象和外层已经完成的激活对象组成,这道工序保证了函数和变量的有序访问,如果在当前作用域没有找到,就会继续向上查到直到全局作用域。
调用栈
正常来讲,在函数执行完毕并出栈时,函数内部的局部变量在下一个垃圾回收节点会被回收,该函数对应的执行上下文将会被销毁。这也正是我们在外界无法访问函数内定义的变量的原因。
可迭代对象 和 可枚举属性
个人理解:一个符合迭代协议的对象
迭代协议:可迭代协议、迭代器协议
可迭代协议
可迭代协议允许 JavaScript 对象定义或者定制它们的迭代行为
例如:在一个 for…of 结构中,哪些值是可以被遍历到的
要成为可迭代对象:一个对象必须实现@@iterator方法。这意味着对象(或者它原型链上的某个对象)必须有一个键为@@iterator的属性,可以通过常量Symbol.iterator访问该属性
[Symbol.iterator]: 一个无参的函数,其返回值为一个符合迭代器协议的对象
迭代器协议
迭代器协议定义了产生一系列值的标准方式。当值为有限个时,所有值都被迭代完毕之后,则会返回一个默认返回值
只有实现了一个拥有特定语义的 next() 方法,一个对象才能成为迭代器
next: 一个无参或者可以接受一个参数的函数,应该返回且必须返回拥有包含 done 和 value 属性的对象
done(boolean):如果迭代器可以产生序列中的下一个值,则为 false(等价于没有指定这个属性);如果迭代器已将序列迭代完毕,则为 true。这种情况下,value 是可选的
可枚举属性
就是内部可枚举标志设置为 true 的属性
for…in 和 for…of 的区别
for…of 定义:for…of 语句在可迭代对象上创建一个迭代循环,调用自定义迭代钩子,并为每个不同属性的值执行语句
语法:
for (variable of iterable) {// statements}
for…in 定义:for…in 语句以任意顺序迭代一个对象的除 Symbol 以外的可枚举属性,包括继承的可枚举属性。
for…in 是为遍历对象属性而构建的,不建议与数组一起用。
区别:
主要区别在于迭代方式:
for…in 语句以任意顺序迭代对象的可枚举属性,包括原型链上的可枚举属性
for…of 语句遍历可迭代对象定义要迭代的数据
对于对象来说,for…in 遍历获取的是对象的键值,for…in 遍历获取的是对象的键名
比如:我们在 Object 的原型和 Array 的原型上添加了自定义的属性
Object.prototype.customProp = function () {}Array.prototype.customProps = function () {}const obj = [1, 2, 3]for (let key in obj) {console.log(key)}// 0 1 2 customProps customProp
要避免这种情况,需要添加if (obj.hasOwnProperty)来判断
而使用 for…of
Object.prototype.customProp = function () {}Array.prototype.customProps = function () {}const obj = [1, 2, 3]for (let key of obj) {console.log(key)}// 1 2 3
并不会出现自定义在原型链上的属性
HashRouter 和 HistoryRouter 的区别
Why
Ajax 局部刷新,导致浏览器的 URL 不会发生任何变化而完成了请求。本次浏览的网页在用户下次使用 URL 访问时,将无法重新呈现,使用路由可以解决这个问题
单页应用应用利用了 JavaScript 动态变换网页内容,避免了页面重载。路由提供了浏览器的地址变化,网页内容也跟随变化
单纯的网站路由地址改变网页不会变化,因此我们的路由主要通过监听事件,并利用 js 实现动态改变网页内容
实现方式:hash 模式/history 模式
明显区别:hash 会在浏览器地址后面增加#,history 可以自定义路由
hash 模式
hash 指的是地址中 # 后面的内容,也成为散列值。散列值不会随请求发送到服务端,所以改变 hash,不会重新加载页面
可以通过hashchange事件监听 hash 值的改变,通过window.location.hash获取和改变 hash 值
<a>可以设置为页面的元素 ID,用作锚点跳转
history 模式
window.hitory 属性指向 Histpory 对象,表示当前窗口的浏览历史。当发生改变时,只会改变页面路径,不会刷新页面
浏览器工具栏的前进后退按钮就是对 History 对象进行操作
History 对象主要有两个属性:
- History.lenvth:当前窗口访问过的网址数量(包括当前网页)
- History.state:History 栈顶的状态值,通常是 undefined
方法:
- History.back():等同于点击浏览器的后退键。对第一个访问的网址,该方法无效果
- History.forword():等同于点浏览器的前进键。对于最后一个访问的网站无效。
- History.go():接受一个整数为参数,以当前网址为基准,移动到参数指定的网址。如果参数超过了实际存在的范围,该方法无效;如果不指定参数,默认为 0,相当于刷新当前页面
- pushState(object, title, url):该方法在历史中添加一条记,不会刷新页面,只是导致 History 对象发生变化,地址栏会有变化
- object: 通过该方法可以将该对象内容传递到新页面中,可以为 null
- title:’’
- url:新的网址,必须和当前页面处在是同一个域,跨域会报错。如果设置了一个新的锚点值(即 hash),并不会触发 hashchange 事件。反过来,如果,URL 的锚点值变了,则会在 History 对象创建一条浏览记录
- replaceState(object, title, url):replaceState() 是修改了当前的历史记录项而不是新建一个
- popstate:history 对象变化时触发
区别
hash 有#号,history 没有#号,hash 兼容性比 history 好,hash#后面的 url 后面不会发送到服务器,不需要在服务器层面上进行任何处理,刷新不会存在 404 问题,不需要服务器配置;history 每访问一个页面都需要服务器进行路由匹配生成 html 文件再发送给浏览器,消耗大量的资源,浏览器刷新时会报 404 错误,需要服务器配置一个回调路由。
面向对象
面向对象的三大特征:封装、继承、多态。
成员属性和方法,公开、私有、静态
公开:在外使用对象.属性或方法名,可以被自由的调用和继承
私有:对内不对外,使用对象.属性或方法名,无法被调用,但在类中的所有方法可以自由的访问它;也无法被继承
静态:静态属性和静态方法,是属于构造函数的,只能通过类名.属性或方法声明的,无法通过实例获取
在 JavaScript 中,私有属性和方法都是通过作用域模拟的,在 ES2022 中加入了#字段来表示私有属性和方法。
封装
因为对象需要对自己负责,对象的很多东西都不需要或者不可以暴露给外部。
所以,封装的主要作用是解决数据的安全性,内在也体现了“每个对象对自己负责”的原则。
方法的封装:就是将方法私有化,同时需要提供用于设置和读取的 set/get 方法,让外部使用我们提供的方法
属性的封装:属性私有化,同时需要提供用于设置和读取的 set/get 方法
继承
主要目的是为了解决代码的复用
实现代码的复用有两种方式:组合 和 继承
那么什么时候该用组合?什么时候该用继承呢?
多态
同一个操作,作用于不同的对象,会产生不同的结果。
即发出一个相同的指令后,不同的对象会对这个指令有不同的反应。
好处:灵活、解耦
耦合度:模块和模块之间,代码和代码之间的关联度
紧耦合就是它们之间的关联度大,代码很难维护,很容易出 bug,而且出现一个 bug,其他 bug 很可能像滚雪球一样增长,猝不及防。
多态性,要求我们面向接口编程。
TS 中我们可以定义一个方法不去实现,并且将这个方法置为抽象方法,当时我们的类也就必须为抽象类了,在前面添加 abstract 字段。然后让子类继承的时候去继承并实现这个方法(子类中也必须要包含这个抽象类中的抽象方法)
V8 的内存管理
V8 是有内存限制的,因为它最开始是为浏览器设计的,不太可能遇到大量内存的使用场景。关键原因还是垃圾回收所导致的线程暂停执行的时间过长。根据官方说法,以 1.5G 内存为例,V8 一次小的垃圾回收需要 50ms,而一次非增量的,即全局的垃圾回收更需要 1s。这显然是不可接受的,所以 V8 先知道了内存使用的大小,但是 NodeJS 是可以通过配置修改的,更好的做法是使用 Buffer 对象,因为 Buffer 的内存是底层 C++ 分配的,不占用 JS 内存,所以不受 V8 限制。
V8 采用了分代回收的策略,将内存分为两个生代:新生代和老生代。V8 采用了两个垃圾回收器,主垃圾回收器(主要负责老生代的垃圾回收)和副垃圾回收器(主要负责新生代的垃圾回收器)
新生代
新生代中为存活时间较短的对象
新生代内存中的垃圾回收主要通过 Scanvenge 算法进行,具体实现时主要采用了 Chaney 算法。新生代的堆内存被分为多个 Semispace,每个 Semispace 分为两部分——from 和 to,只有 from 的空间是使用中的,分配对象空间时,只在 from 中进行分配,to 是闲置的。进行垃圾回收时按照如下步骤进行:
- 找出 from 中还在使用的对象,即存活的对象
- 将这些活着的对象全部复制到 to
- 翻转 from 和 to,这时候 from 中全部是存活的对象,to 全部是死亡对象
- 对 to 进行全部回收

可以看到在新生代中我们复制的对象是存活的对象,死亡对象都留在原地,最后被全部回收。这是因为对于大多数新增变量来说,可能只是使用以下,很快就需要释放,那在新生代中每次回收会发现存活的是少数,死亡的是多数。那我们复制 ide 就是少数对象,这样效率更高。
如果一个变量在新生代中经过几次复制还活着,那它生命周期可能比较长,会晋升到老生代。
有两种情况会对对象进行晋升:
- 新生代垃圾回收过程中,当一个对象经过多次复制后还存活,移动到老生代。
- 在 from 和 to 进行反转的过程中,如果 to 空间的使用量超过了 25%,那么 from 的对象全部晋升到老生代
老生代
老生代存放的是生命周期较长的对象,他的结构是一个连续的结构。

老生代垃圾回收有两种方式:标记清除和标记合并。
标记清除
标记清除式标记死亡的对象,直接其空间释放掉。在标记清除方法清除掉死亡对象后,内存空间就变成不连续的了,所以出现了另一个方案:标记合并。

标记合并
这个方案有像新生代的 Cheney 算法,将存活的移动到一边,将需要被回收的对象移动到另一边,然后对需要被回收的对象区域进行整体的垃圾回收。
与新生代算法相比,老生代主要操作死亡对象,因为老生代都是生命周期较长的对象,每次回收死亡的比较少;而新生代主要操作的存活对象,因为新生代都是生命周期较短的对象,每次回收存活的较少。这样无论新生代还是老生代,每次回收时都尽可能操作更少的对象,效率就提高了。
如何通过扫描知道是没有引用的呢?
不是引用计数
V8 垃圾回收机制
垃圾回收是通过 GC Root(全局的 window 对象(位于每个 iframe 中)、文档 DOM 树、存放栈上变量)标记空间中活动对象和非活动对象。从 GC Roots 出发,遍历 GC Root 中的所有对象,能遍历到的对象,则该对象是可访问的(reachable),那么必须保证这些对象应该在内存中保留,也称可访问的对象为活动对象;通过 GC Roots 没有遍历到的对象,则是不可访问的(unreachable),那么这些不可访问的对象就可能回收,称不可访问的对象为非活动对象。
- 主线程停下来进行 GC,叫全停顿(stop-the-world)为了解决全停顿带来的卡顿,V8 内部还有并行、并发、增量等垃圾回收技术
- 并行回收:在执行一个完整的垃圾回收过程中,垃圾回收器会使用多个辅助线程来执行垃圾回收。
- 增量回收:垃圾回收器将标记工作分解为更小的块,并且穿插在主线程不同的任务之间执行。
- 并发回收:回收器在执行 JavaScript 的过程,辅助线程能够在后台完成的执行垃圾回收的操作
三色标记法
- V8 提出了三色标记法,黑色和白色,还额外引入了灰色。黑色表示这个节点被 GC Root 引用到了,而且该节点的子节点都已经标记完成了;白色表示这个节点还没有被访问到,如果在本轮遍历结束时还是白色,那么这块数据就会被回收
- 灰色表示这个节点被 GC Root 引用到,但是子节点还没被垃圾回收器标记处理,也表示目前正在处理这个节点;
- 为啥会有灰色?
window.a = {}; window.a.b = {}; window.a.b.c = {}; 扫完之后,使 window.a.b = d; 导致 b 切开了,但是 d 确实闲置。增量垃圾回收器添加了一个约束条件:不能让黑色节点指向白色节点
写屏障机制,会强制将引用的白色节点变成灰色的,这样就保证了黑色节点不能指向白色节点的约束条件。这个方法也叫 强三色不变性,因为在标记结束的时候所有白色对象,对于垃圾回收器来说,都是不可达到的,可以安全释放。在 V8 中,每次执行如 window.a.b = vlaue 的写操作之后,V8 会插入写屏障代码,强制将 value 这块内存标记为灰色。
- 为啥会有灰色?
异步 I/O 的好处
- 前端可以通过异步 I/O 可以消除 UI 堵塞
- 假设请求资源 A 的时间为 M,请求资源 B 的时间为 N,那么同步的请求耗时为 M+N。如果采用异步方式占用时间就是 max(M, N)
- I /O 是昂贵的,分布式 I/O 是更昂贵的
- NodeJS 适用于 I/O 密集型,而不适用于 CPU 密集型
高防 IP =》负载均衡(nginx、lvs、k8s)=》pm2(后台守护进程)=》后台
元编程
让对象可以遍历
var obj = {a: 2,b: 3,}Object.defineProperty(obj, Symbol.iterator, {enumerable: false, // 为 true时,该属性才能出现在对象的枚举属性中,可枚举的属性可以用 for...in遍历或者用Object.keyswritable: false, // 可写configurable: true, // 当且仅当该属性的 configurable 键值为 true时,该属性的描述符才能被改变value: function () {var o = thisvar index = 0var keys = Object.keys(o)return {next: function () {return {value: o[keys[index++]],done: index > keys.length,}},}},})for (let v of obj) {console.log(v)}
改写 toPrimitive
var obj = {[Symbol.toPrimitive]: (i => () =>++i)(0),}if (obj == 1 && obj == 2 && obj == 3) {console.log('yes')}
反射 Reflect
是一个内建对象,提供了一些方法可以用来拦截 JavaScript 的一些操作
function Tree() {return new Proxy({}, handler)}const handler = {get(target, key, receiver) {if (!(key in target)) {target[key] = Tree()}return Reflect.get(target, key, receiver)},}var tree = new Tree()tree.fuck.shit.name = 'ha0ran'console.log(tree) // { fuck: { shit: { name: 'ha0ran' } } } --node环境
手写 Symbol
函数式编程
纯度
幂等性
偏应用函数
带一个函数参数和该函数的部分参数
const partial =(f, ...args) =>(...moreargs) =>f(...args, ...moreargs)const add = (a, b, c) => a + b + cconst plus = partial(add, 2, 3)plus(4)
应用:函数的柯里化
把一个多参数的函数转换为一个嵌套一元函数的过程
传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数
const curry =(fn, arr = []) =>(...args) =>(arg => (arg.length === fn.length ? fn(...arg) : curry(fn, arg)))([...arr, ...args])
是一种预加载函数的方法,通过传递较少的参数,得到一个已经记住了这些参数的新函数。
是对参数的缓存,是一种非常高效的编写函数的方法
对应的有,反柯里化
Function.prototype.unCurring = function () {var self = thisreturn function () {var obj = Array.prototype.shift.call(arguments)return self.apply(obj, arguments)}}var push = Array.prototype.push.unCurring(),obj = {}push(obj, 'first', 'two')console.log(obj)
函数组合
compose
const compose = (f, g) => x => f(g(x))
Point Free
把一些对象自带的方法转化为纯函数,不要命名转瞬即逝的中间变量
声明式和命令式代码
惰性调用,惰性值,惰性函数
高阶函数
函数当参数,把传入的函数做一个封装,然后返回这个封装的函数,达到一个更高的抽象
尾调用优化
函数内部的最后一个动作是函数调用。该调用的返回值,直接返回给函数。函数调用自身,称为递归。如果尾调用自身,就称为尾递归。
递归需要保存大量的调用记录,很容易发生栈溢出错误,如果使用尾递归优化,将递归变为循环,那么只需要保存一个调用记录,这样就不会发生栈溢出错误了。
蹦床函数:
function runStack(n) {if (n === 0) return 100return runStack.bind(null, n - 2)}// 崩床函数function trampoline(f) {while (f && f instanceof Function) {f = f()}return f}trampoline(runStack(1000000))
函子 Functor
- 任何具有 map 方法的数据结构,都可以当作函子的实现
- 函子遵守一些特定规则的容器类型
- Functor 是一个对于函数调用的抽象,我们赋予容器自己去调用函数的能力
this 的指向问题总结
- 普通函数
- 非显示或者叫隐式地简单调用函数时
- 在严格模式下,this 会被绑定到 undefined 上
- 在非严格模式下,会被绑定到全局对象 window/global 上
- 非显示或者叫隐式地简单调用函数时
- 由 new 调用构造函数时,构造函数内的 this 会被绑定到新创建的对象上
- 通过 call/apply/bind 显示调用函数时,函数体内的 this 会被绑定到指定参数的对象上
- 通过上下文对象调用函数时,this 会被绑定到该对象上
- 在箭头函数中,this 的指向是由外层作用域来决定的。
宏任务微任务,微任务队列,消息队列 题目
function taskOne() {console.log('1 task one ...')setTimeout(() => {Promise.resolve().then(() => {console.log('2 task one micro in macro ...')})setTimeout(() => {console.log('3 task one macro ...')}, 0)}, 0)taskTwo()}function taskTwo() {console.log('4 task two ...')Promise.resolve().then(() => {setTimeout(() => {console.log('5 task two macro in micro...')}, 0)})setTimeout(() => {console.log('6 task two macro ...')}, 0)}setTimeout(() => {console.log('7 running macro ...')}, 0)taskOne()Promise.resolve().then(() => {console.log('8 running micro ...')})1 4 8 7 2 6 5 3
装箱与拆箱
https://juejin.cn/post/6844904042066345992
我们可以在基本类型值(比如字符串“hello”)上访问属性 & 调用方法,但是基本类型值并不支持属性和方法的设置。但是我们可以这么做,是因为引擎内部做了装箱与拆箱的操作
基础类型与复杂类型
基本类型值( primitives ) 存储的是一个简单值;复杂类型值 (即对象,objects )则使用引用访问,我们通过引用记录的地址,找到对象数据在内存中实际存储的位置,并进行操作。这是两种类型值本质的不同
调用方法和访问属性是对象上所特有的访问数据的方式。但是在原始类型比如数字类型上也可以有属性和方法—— 其实是 JS 引擎里背地做了 装箱和拆箱 的操作。
装箱
装箱就是把原始类型转换为对应的包装对象
比如:
let num = 9527// 数值包装成 Number 对象new Number(num)let str = 'showBuger'// 字符串包装成 String 对象new String(str)
这个过程是不可见的,是 JS 内部做了这样的转换。所以我们才可以看起来能够直接在原始类型上访问属性和调用方法。
拆箱
拆箱就是把包装对象转为对应的原始类型值表现形式
let num = 9527let str = 'showBuger'// 将 new Number 拆箱成 9527new Number(num).valueOf() // 9527// 将 new String 拆箱成 showBugernew String(str).valueOf() // 'showBuger'
为什么要这么做?
- 方便。操作基本数据类型值得场景还是挺多的,如果每次都要手动进行装箱未免有些麻烦。
- 省内存。存储同一个数据,对象对内存的开销比基本数据类型值要打。有了拆装箱的操作,就可以只在使用的时候暂时包装成对象访问,其余时间还是以基本类型值得形式存在,能够节省不少得内存。
null/undefined 没有对应得包装函数
toString 和 toLocaleString 的区别
toLocaleString 返回对象的字符串表示,该字符串与机器执行环境的地区对应
toString 返回对象的字符串表示
除此之外,对于数字而言,如果数字长度超过 3,toLocaleString 会用 , 分割。而 toString 不会。
对于日期而言,两者区别还是挺大的,比如
let dt = new Date()console.log(dt.toLocaleString()) // 2022/3/21 下午6:12:05console.log(dt.toString()) // Mon Mar 21 2022 18:12:05 GMT+0800 (中国标准时间)
Object.defineProperty 和 Proxy 比较
Proxy 的优势:
- Proxy可以直接监听整个对象而不是属性。Proxy 只需要做一层代理就可以监听同级结构下的所有属性变化。对于深层的,还是需要遍历的
- Proxy 可以监听数组的变化
- Proxy 中有些拦截方法,比如ownKeys、deleteProperty、has 等是Object.defineProperty 不具备的
- Proxy 有性能优化
Object.defineProperty 的优势:
- 兼容性好,支持IE9,而Proxy 存在浏览器兼容性问题,而且无法用polyfill磨平
Object.defineProperty的劣势:
- Object.defineProperty 只能劫持对象属性,因此我们需要对每个对象的每个属性进行遍历
- Object.definedProperty 不能监听数组
- Object.defineProperty 不能对 Map、Set 这些数据结构监听
- Object.defineProperty 不能监听新增和删除操作
继承的多种方式
原型链
// 主要代码SubType.prototype = new SuperType()
缺点:多个实例对引用类型的操作会被篡改
经典继承(盗用构造函数)
function SuperType() {}function SubType() {SuperType.call(this)}let instance1 = new SubType()
缺点:
- 只能继承父类的实例属性和方法,不能继承原型属性/方法
- 无法实现复用,每个子类都有父类实例函数的副本,影响性能
组合继承
function SuperType() {}function SubType() {SuperType.call(this)}SubType.prototype = new SuperType()// 重写SubType.prototype的constructor属性,指向自己的构造函数SubTypeSubType.prototype.constructor = SubType
缺点:在使用子类创建实例对象时,其原型中会存在两份相同的属性/方法。
原型式继承
利用一个空对象作为中介,将某个对象直接赋值给空对象构造函数的原型
// 实际上就是Object.create的实现。function object(o) {function F() {}F.prototype = oreturn new F()}
缺点:
- 原型链继承多个实例的引用类型属性指向相同,存在篡改的可能。
- 无法传递参数
寄生式继承
在原型式继承的基础上,增强对象,返回构造函数
function createAnother(original) {let clone = object(original) // object 就是上面的objectclone.sayHi = function () {// 以某种方式来增强对象console.log('hi')}return clone // 返回这个对象}
缺点:
- 原型链继承多个实例的引用类型属性指向相同,存在篡改的可能
- 无法传递参数
寄生式组合继承
function Person() {}function Child() {Person.call(this)}let prototype = Object.create(Person.prototype) // 创建对象,创建父类原型的一个副本prototype.constructor = Child // 增强对象,解决重写原型导致默认 constructor 丢失的问题Child.prototype = prototype // 赋值对象,将新创建的对象赋值给子类的原型
try catch 能捕获 promise 的错误吗?🤔
结论:
- try catch 不能捕获异步代码,所以不能捕获 promise.reject() 的错误,并且 promise 故意将异步行为封装起来,从而隔离外部的同步代码
- try catch 能对 promise 的 reject() 落定状态的结果进行捕获
- try catch 能捕捉到的异常,必须是 主线程执行 已经进入了 try catch,但是 try catch 尚未执行完的时候抛出来的,意思是如果将 try catch 分为前中后,只有中才能捕获到异常
为什么要捕获错误,处理错误
当网页中的 JavaScript 脚本发生错误时,不同浏览器的处理方式不同,而且也只会在浏览器输出,有一个良好的错误处理策略可以让用户知道到底发生了什么,防止用户流失。为此,必须理解各种捕获和处理 JavaScript 错误的方式
try catch 基本介绍
try catch 无法阻止 finally 块 执行
try {window.somefunction()console.log('try')} catch (e) {console.log(e, 'catch')} finally {console.log('finally')}
finally 的作用
- loading 的取消,不管报错没,loading 必须是要取消的
- 比如做一些清楚,销毁的操作
return 语句无法阻止 finally 的执行
🤔try catch 是如何捕获错误的?什么时候才能捕获错误?
try catch 之前:不能捕获到
try catch 能捕捉到的异常,必须是主线程执行 已经进入 try catch,但 try catch 尚未执行完的时候抛出来的
try {console.log(666)a.} catch (e) {console.log(e)}
666 不会打印,因为这里出现了 语法异常,语法异常在语法检查阶段就报错了,线程执行尚未进入 try catch 代码块,所以无法捕获异常。
try catch 进行中:不能捕获到
try {console.log('try里面')setTimeout(() => {console.log('try里面的setTimeout')window.seomeNonefunctin()}, 0)} catch (e) {console.log('error', e)}setTimeout(() => {console.log('我要执行')}, 100)
这里没有 catch 到错误,是因为 try catch 是同步代码;
Promise 的异常捕获
如果不设置参数,Promise 内部抛出的错误,不会反应到外部
- 可以用
then方法捕获:
无法捕获resolve()回调中出现的异常,需要无限链式调用 then 回调去捕获异常;无法中断后序的 then
const createPromise = new Promise((resolve, reject) => {setTimeout(() => {reject('promise')}, 100)})createPromise.then(res => {console.log(res, 'resolved')},err => {console.log(err, 'reject')throw new Error('reject1')}).then(null, err => {console.log('reject2', err)})// promise reject// reject2 Error: reject1
能够在 reject 的回调函数里面去使用 try catch,因为这里面就是同步代码
const createPromise = new Promise((resolve, reject) => {setTimeout(() => {resolve('promise')}, 100)})createPromise.then(res => {console.log(res, 'resolved')window.someNonefunction()},err => {console.log(err, 'reject')}).then(null, err => {console.log('reject2', err)})// promise resolved// reject2 TypeError: window.someNonefunction is not a function
- promise.catch 捕获异常
因为 promise 对象的错误具有冒泡性,会一直向后传递。也就是说,错误总会被下一个 catch 语句捕获,catch()方法返回的还是一个 promise 对象,因此后面还可以接着调用 then 方法。
这个方法就是一个语法糖,调用它就相当于调用 Promise.then(null, onRejected)
- async/await 结合 try…catch 使用
- async 函数完全可以看作多个异步函数,包装成的一个 Promise 对象,而 await 命令就是内部 then 命令的语法糖
- async 函数返回一个 Promise 对象,可以使用 then 方法添加回调函数。当函数执行那个的时候,一旦遇到 await 就会提前返回,等到异步操作完成,再接着执行函数体内后面的语句。
- await 表达式会暂停当前 async 函数的执行,等待 Promise 处理完成。
- 若 Promise 正常处理(fullfilled),其回调的 resolve 函数参数作为 await 表达式的值,继续执行 async 函数
- 若 Promise 处理异常(rejected),await 表达式会把 Promise 的异常原因抛出
- await 如果返回的是 reject 状态的 promise,如果不被捕获抛出,就会中断 async 函数的执行
- await 操作符后的表达式的值不是一个 Promie,则返回该值本身。
- async awiat 函数中,通常使用 try/catch 来捕获异常
总结:await 之后的返回就是 resolve 和 reject 回调的结果
try catch 啥使用用,以及如何报错
ajax 和 fetch 的区别
XMLHttpRequest 是规范,是标准Fetch 是规范,是标准,是基于 Promise 设计的
Ajax:
英文全称为Asynchronous JavasScript and XML, 异步的JavaScript和XML技术(通常使用JSON,因为JSON更加轻量以及本身是JavaScript的一部分)。意思是用 JavaScript 执行异步网络请求。是指一套综合了多项技术的浏览器端网页开发技术。
优点:
能在不更新整个页面的前提下维护数据,使得web应用更快地回应用户动作,并避免了在网络上发送那些没有改变的信息。
主要涉及到:HTML 或 XHTML、CSS、JavaScript、DOM、XML、XSLT、以及最重要的 XMLHttpRequest。
Axios
Axios 是一个基于 Promise 的网络请求库,作用与于 Node.js 和浏览器中。它是 isomorphic (即同一套代码可以运行在浏览器和 Node.js 中)的。在服务端它使用原生 Node.js http 模块,而在客户端则使用 XMLHttpRequest
客户端 Axios 主要特性有:
- 从浏览器创建 XMLHttpRequest
- 支持 Promise API
- 拦截请求和响应
- 转换请求和响应数据
- 取消请求
- 自动转换 JSON 数据
- 客户端支持方旭 XSRF
Fetch
Fetch 是一个现代的概念,等同于 XMLHttpRequest,它提供了许多与 XMLHttpRequest 相同的功能,但是被设计成更具可扩展性和高效性
Fetch 的核心在于对 HTTP 接口的抽象,包括 Request、Response、Headers、Body,以及用于初始化异步请求的global fetch。Fetch 是基于 Promise 的。fetch()方法必须接受一个参数——资源的路径。无论请求成功与否,都返回一个 Promise 对象。resolve 对应请求的 Response。
Fetch 和 Axios/Ajax 的关系
- Ajax 是一种代表异步 JavaScript + XML 的模型(技术集合), 所以 Fetch 也是 Ajax 的一个子集
- 在之前,我们常说的 Ajax 默认是指以 XHR 为核心的技术合集,而在有了 fetch 之后,Ajax 不再单单指 XHR。我们将以 XHR 为核心的 Ajax 技术称作 传统 Ajax
- Axios 属于传统 Ajax,因为它是基于 XHR 进行的封装
axios 的拦截器原理
本质就是一个 promise 链。
axios 首先创建了一个队列(用数组代替),初始值为[dispatchRequest, undefined],请求拦截器会添加到队头,响应拦截器会添加到队尾,每次添加都是fullfilled, rejected两种状态同时添加,然后使用的时候,从队头两两拿出。这样就实现了请求拦截器 => 请求 => 响应拦截器这一顺序。并且,先添加的请求拦截器后执行,先添加的响应拦截器先执行fetch 什么时候会 reject?出现 404 或者 500 的时候会 resolve 吗?
fetch 当且仅当网络故障或者请求被阻止的时候,才会被标记为 reject
当接收到一个代表错误的状态码,即使响应的 HTTP 状态码是 404/500,从 fetch 返回的 promise 也不会被标记为 reject,相反,会被标记为 resolve,但是会把 resolve 返回的 ok 属性,设置为 false,其他成功的时候 promise 被 resolve 且 Response.ok 属性设置为 true
Symbol
Symbol是 ES6 新推出的一种基础数据类型,它表示独一无二的值,用来作为对象属性的唯一标识符
可以选择一个字符串作为参数或者不传,但是相同的参数的两个 Symbol 值不相等,不论全等还是==。
不是一个完整的构造函数,不能用**new Symbol()**来创建
- Symbol 值可以显示为字符串,也可以转为布尔值,但是不能转换为数值。隐式地创建一个新的 string 类型的属性名也会报错,例如
Symbol("foo") + "bar"会报错。 - Symbol 在
for...in迭代中不可枚举。 - 在使用
JSON.stringify()时以 Symbol 键的属性会被忽略。 - 围绕原始数据类型创建一个显示包装器对象从 ES6 开始不再被支持,所以
new Symbol()会报错。但是,原有的原始包装器对象,如new Boolean、new String以及new Number因为遗留原因被保留。
想要创建Symbol包装器函数,可以使用Object包一下
方法
Symbol.for()
用于将描述相同的Symbol变量指向同一个Symbol 值const s1 = Symbol.for('1')const s2 = Symbol.for('1')console.log(s1 === s2) // true
它与**Symbol()**的区别是**Symbol()**定义的值每次都是新建,即描述相同值也不相等Symbol.for()定义的值会先检查给定的描述是否已经存在,如果不存在才会新建一个值,否则描述相同则他们就是同一个值。Symbol.keyFor()
Symbol.keyFor()用来检测该字符串参数作为名称的Symbol值是否已经被登记,返回一个已登记的Symbol类型值的key// 比如用 let a1 = Symnol.for('a')创建了一个描述值 a// 然后用 Symbol.keyFor(a1) 就会返回 'a'// 但是Symbol()创建的描述值就不行// let a2 = Symbol('a')// Symbol.keyFor(a2) // undefined
属性
description
用来返回 symbol 数据的描述
let a = Symbol('acc')a.description // 'acc'Symbol.keyFor(a) // undefined
description能返回所有 Symbol 类型数据的描述,而Symbol.keyFor()只能返回Symbol.for()的描述
使用场景
- 对象添加属性
在对象上添加属性时,避免出现相同的属性名,产生一个属性给改写或覆盖的情况
注意:- 需要通过方括号的形式访问 symbol 属性 ```javascript let n = Symbol(‘N’)
let obj = { name: ‘hello ha0ran’, age: 20,
[n]: 100,
}
console.log(obj[n]) // 100
- 迭代属性时,某些情况不能得到该 symbol 属性,如 `for in`, `for of`- 作为私有属性可以用 Symbol 的唯一性来模拟类的私有方法和私有变量```javascriptconst speak = Symbol()class Person {[speak]() {console.log(123)}}let person = new Person()person[speak]()
Symbol.toStringTag
Symbol.toStringTag是一个内置 symbol,它通常作为对象的属性键使用,对应的属性值应该为字符串类型,这个字符串用来表示该对象的自定义类型标签。通常只有 Object.prototype.toString()方法会去读取这个标签并把它包含在自己的返回值中。
Symbol.toStringTag 的属性特性:
- writable: false
- enumable: false
- configurable: false
许多内置的 JavaScript 对象类型即便没有 toStringTag 属性,也能被 toString() 方法识别并返回特定的类型标签
Object.prototype.toString.call({}) // [object object]
另外一些对象则不然, toString() 方法能识别它们是因为引擎为他们设置好了,比如
Object.prototype.toString.call(new Map()) // [object Map]Object.prototype.toString.call(function* () {}) // [object GeneratorFunction]Object.prototype.toString.call(Promise.resolve()) // [object Promise]
自己创建的类就不行,如果 toString() 找不到 toStringTag 标签就会返回 object
class MyClass {}Object.prototype.toString.call(new MyClass()) // [Object object]
所以可以自己加上标签
class MyClass {get [Symbol.toStringTag]() {return 'ha0ran'}}Object.prototype.toString.call(new MyClass()) // [object ha0ran]
对象到原始值的转换
转换规则
- 所有的对象在布尔上下文 ( context ) 中均为
true。所以对于对象,是不存在to-boolean转换。只有字符和数值转换。 - 数值转换发生在对象 相减 或 应用数学函数时。例如
Date对象可以相减,date1 - date2的结果是两个日期之间的差值。 - 至于字符串转换——通常发生在像
alert(obj)这样输出一个对象和类似的上下文中
类型转换有三种变体,发生在各种情况下,称之为 hint。
- ‘string’:对象到字符串的转换,例如当我们对一个对象进行 alert 时
- ‘number’:对象到数字的转换,例如我们进行数学运算时
- 显示转换:Number()
- 数学运算
- 一元加法
- 相减
- 大于或小于的比较
- ‘default’:当运算符不确定期望值的类型时。比如,二元加法既可用于字符串的连接,也可用于数字相加。
为了进行转换,JavaScript 尝试查找并调用三个对象方法:
- 调用
obj[Symbol.toPrimitive](hint)——带有 symbol 键Symbol.toPrimitive(系统 symbol)的方法,如果这个方法存在的话。 - 否则,如果 hint 是
'string'——尝试obj.toString()和obj.valueOf(),无论哪个存在 否则,如果 hint 是
'number'或'default'——尝试obj.valueOf()和obj.toString(),无论哪个存在。Symbol.toPrimitive
```javascript let user = { name: ‘showBuger’, age: 21,
alert(`hint: ${hint}`)return hint == 'string' ? `{name: "${this.name}"}` : this.age
}, }
alert(user) // hint: string -> {name: ‘showBuger’} alert(+user) // hint: numebr -> 21 alert(user + 500) // hint: default -> 521
`user[Symbol.toPrimitive]`方法处理了所有的转换情况。<a name="5fbb40b5"></a>#### toString / valueOf如果没有 `Symbol.toPrimitive` ,那么 JavaScript 将尝试寻找 `toString` 和 `valueOf` 方法。- 对于 'string' hint:`toString`,如果它不存在,那么 `valueOf` (因此,对于字符串转换,优先 `toString`)- 对于其他 hint:`valueOf`,如果它不存在,则 `toString`(因此,对于数学运算,优先 `valueOf`)。`toString` 和 `valueOf` 提供了一种可选的老派的实现转换的方法,这些方法必须返回一个原始值,如果 `toString` 和 `valueOf` 返回了一个对象,那么返回值就会被忽略。(和这里没有方法的时候相同)<br />普通对象具有 `toString` 和 `valueOf` 方法:- `toString` 返回一个字符串 `"[object Object]"`- `valueOf` 返回对象自身<a name="b5a1bd71"></a>### 相关题1. `a == 1 && a == 2 && a == 3`为 true```javascript// 改写 toString 或 valueOf 都可以class A {constructor(value) {this.value = value}toString() {return this.value++}}let a = new A(1)if (a == 1 && a == 2 && a == 3) {console.log('pass')}// 使用代理/劫持let value = 1Object.defineProperty(global, 'a', {// node 下改成 windowget() {return value++},})if (a === 1 && a === 2 && a === 3) {console.log('pass')}
实现一个无限累加函数 :add(1)(2)(3) = 6 ```javascript function add(a) { function sum(b) {
a = b ? a + b : areturn sum
}
sum.toString = function () {
return a
}
return sum }
console.log(+add(1)) // 1 console.log(+add(1)(2)) // 3
3. 实现多参数传递累加:add(1)(3, 4)(3, 5)```javascriptfunction add() {let args = Array.prototype.slice.call(arguments)function fn() {let args_fn = Array.prototype.slice.call(arguments)return add.apply(null, args.concat(args_fn))}fn.toString = function () {return args.reduce((a, b) => a + b)}return fn}console.log(+add(1, 2, 3)(4)(5)) // 15
npm 模块安装机制(为什么输入 npm install 就可以自动安装相关模块?)
npm 模块安装机制
- 发出 npm install 命令
- 查询 node_modules 目录中是否已经存在指定模块
- 如果存在,那么不再重新安装
- 如果不存在
- npm 向 registry 查询模块压缩包的网址
- 下载压缩包,存放在根目录下的 .npm 目录中
- 解压压缩包到当前项目的 node_modules 目录
DOCTYPE 的作用
DOCTYPE 是 Document Type 的简写,在 HTML 代码中,用来说明当前代码 XHTML 或者 HTML 的哪一种规范。如果没有这个,浏览器将怪异模式解析网页代码。
JS 获取盒模型的高度和宽度

若有收获,就点个赞吧
0 人点赞
