深入剖析浏览器中页面的渲染过程
浏览器的内部结构
从结构上来说,浏览器主要包括了八个子系统:
- 用户界面
- 浏览器引擎
- 渲染引擎
- 网络子系统
- JavaScript 解释器
- XML 解释器
- 显示后端
- 数据持久性子系统

这些子系统,组合构成了我们的浏览器。
页面的加载和渲染过程,离不开网络子系统、渲染引擎、JavaScript 解释器和浏览器引擎。
Chrome 多进程架构
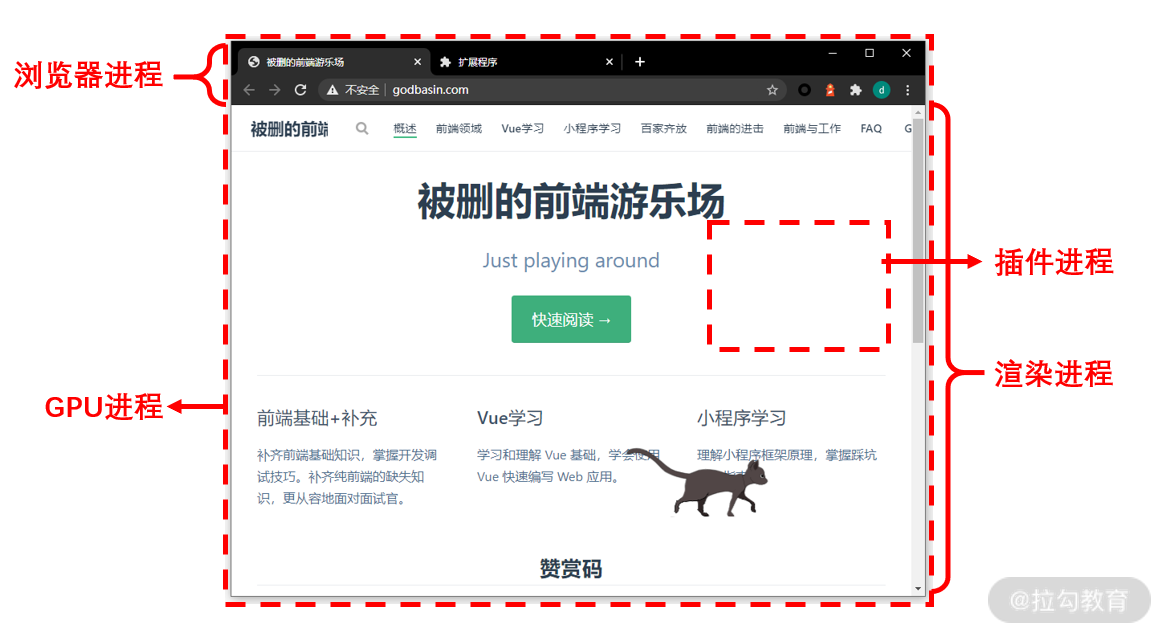
浏览器采用的多进程架构,主要包括四个进程
- 浏览器进程:选项卡之外的所有内容都由浏览器进程处理,浏览器进程主要控制和处理用户可见的 UI 部分(包括地址栏、书签、后退、前进按钮)和用户不可见的隐藏部分(例如网络请求和文件访问)
- GPU 进程:该进程用于完成图像处理任务,同时还支持分解成多个进程进行处理。
- 渲染器进程:Chrome 浏览器中支持多个选项卡(tab 页),其中每个选项卡在单独的渲染器进程中运行,渲染器进程中主要用于控制和处理选项卡的网站内容显示。
- 插件进程:管理 Chrome 浏览器中的各个插件。
对于 “在浏览器中输入 URL,按下回车键,到浏览器渲染页面”这个过程,浏览器内部会通过浏览器进程和渲染器进程,进行很多交互逻辑,最终才得以将页面内容显示在屏幕上
其中,浏览器进程和渲染器进程同样支持多线程。
渲染器进程中的线程:
- GUI 渲染线程
- 负责对浏览器界面进行渲染
- JavaScript 引擎线程
- 负责解析和执行 JavaScript 脚本
- 定时器触发线程
- setTimeout 和 setInterval 所在的线程
- 事件触发线程
- 负责处理浏览器事件,并将事件触发后需要执行的代码放置到 JavaScript 引擎中执行
Chrome 浏览器进程中的线程:
- UI 线程
- 绘制浏览器的按钮和输入字段
- 网络线程
- 用于处理网络请求,以及从服务器接收数据
- 存储线程
- 用于控制对文件的访问
在页面的加载过程中:涉及 GUI 渲染线程和 JavaScript 引擎线程间的互斥关系,因此页面中的
<script>和<style>元素涉及不合理会影响页面加载速度。(此处可能涉及 defer 和 async 的区别)
在 UI 线程、网络线程、存储线程、浏览器事件触发线程、浏览器定时器触发线程中,I/O 事件通过异步任务完成时触发的函数回调,解决了单线程的 JavaScript 阻塞问题
浏览器中页面的渲染过程
首先,我们将浏览器中页面的渲染过程分为两部分:
- 页面导航:用户输入 URL,浏览器进程 进行请求和准备处理
- 页面渲染:获取到资源后,渲染器进程 负责选项卡内部的渲染处理
1. 页面导航过程
当用户在地址栏中输入内容时,浏览器内部会进行如下处理:
- 首先 浏览器进程 中的 UI 线程会进行处理:
- 如果是 URI,则会发起网络请求来获取网站内容
- 如果不是,则进入搜索引擎
- 如果需要发起网络请求,请求过程由网络线程来完成。HTTP 请求响应如果是 HTML 文件,则将数据传递到渲染器进程;如果是其他文件,则意味着下载请求,此时会将数据传递到下载管理器
- 如果请求响应为 HTML 内容,此时浏览器应导航到请求站点,网络线程便通知 UI 线程数据准备就绪。
- 接下来,UI 线程会寻找一个渲染器进程来进行网页渲染。当数据和渲染器进程都准备好后,HTML 数据通过 IPC 从浏览器进程传递到渲染器进程中
- 渲染器进程接收 HTML 数据后,将开始加载资源并渲染页面
- 渲染器进程完成渲染后,通过 IPC 通知浏览器进程页面已加载
如果当前页面跳转到其他网站,浏览器将调用一个单独的渲染进程来处理新导航,同时保留当前渲染进程来处理unload这类事件
总结,页面导航主要依赖浏览器进程。其中上述步骤 5 便是页面的渲染过程,该过程同样依赖渲染器进程
2. 页面渲染过程
页面的渲染过程主要由渲染器进程负责,它的核心工作是将 HTML、CSS 和 JavaScript 转换为可交互的页面
渲染器进程渲染页面的流程:
- 解析(Parser):解析 HTML/CSS/JavaScript 代码
- 布局(Layout):定位坐标和大小、是否换行、各种
position/overflow/z-index属性等计算 - 绘制(Paint):判断元素渲染层级顺序
- 光栅化(Raster):将计算后的信息转换为屏幕上的像素
1.解析
渲染器进程的主线程会解析以下内容
- 解析 HTML 内容,产生一个 DOM 节点树
- 解析 CSS,产生 CSS 规则树
- 解析 JavaScript 脚本,由于 JavaScript 脚本可以通过 DOM API 和 CSSOM API 来操作 DOM 节点树和 CSS 规则树,因此该过程中会等待 JavaScript 运行完成才继续解析 HTML
解析完成后,我们得到了 DOM 节点树和 CSS 规则树
2. 布局
通过解析之后,渲染器进程知道每个节点的结构和样式,但是如果需要渲染页面,浏览器还需要进行布局,布局过程便是渲染树的创建过程,通过 DOM 节点树和 CSS 规则树来构造渲染树(Render Tree)
在这个过程中,像 header 或 display: none 的元素,会存在于 DOM 节点树中,但是不会被添加到渲染树中
3. 绘制
在绘制的步骤中,渲染器主线程会遍历渲染树来创建绘制记录
为了不对每个小的变化都进行完整的布局计算,渲染器会将更改的元素和它的子元素进行 脏位标记,表示该元素需要重新布局。
其中,全局样式更改会触发 全局布局,部分样式或元素更改会触发增量布局,增量布局是异步完成的,全局布局则会同步触发。
如果渲染树发生了变化,则渲染器会触发重绘(Repaint)和 重排(Reflow)
- 重绘:屏幕的一部分要重画,比如某个 CSS 的背景色变了,但是尺寸没有变
- 重排:元素的尺寸变了(渲染树的一部分或全部发生了变化),需要重新验证并计算渲染树
重排需要涉及变更的所有结点几何尺寸和位置,成本比重绘的成本高的多很多。所以我们要注意避免频繁地进行增加、删除、修改 DOM 节点、移动 DOM 的位置、Resize 窗口、滚动等操作,因为这些操作可能会导致性能降低
4. 光栅化
通过解析、布局和绘制过程,浏览器获得了文档的结构、每个元素的样式、绘制顺序等信息。将这些信息转换为屏幕上的像素,这个过程可以称为光栅化
光栅化可以被 GPU 加速,光栅化后的位图会被存储在 GPU 中。根据前面介绍的渲染流程,当页面布局变更了会触发重排和重绘,还需要重新进行光栅化。此时如果页面中有动画,则主线程中过多的计算任务可能会影响动画的性能
因此,现代的浏览器通常使用合成的方式,将页面的各个部分分成若干层,分别对其栅格化(将他们分成不同的瓦片),并通过合成器线程进行页面的合成
合成过程如下:
- 当主线程创建了合成层并确定了绘制顺序,便将这些信息提交给合成器线程
- 合成器线程将每个图层栅格化,然后将每个图块发送给光栅线程
- 光栅线程栅格化,并将它们存储在 GPU 中
- 合成器线程通过 IPC 提交给浏览器进程,这些合成帧被发送到 GPU 进程处理,并显示在屏幕上
合成器线程、光栅线程都运行在渲染器进程内部
合成的真正目的:在移动合成层的时候不用重新栅格化。因为有了合成器线程,页面才可以独立于主线程进行流畅的滚动
到这里,页面才真正渲染到了屏幕上。
网页渲染流程
- 获取 dom 层
- 对每个图层节点计算样式 ( Recalculate Style)
- 为每个节点图层生成图形和位置 Layout
- 每个节点绘制填充到图层(即将其成为纹理)位图中 Paint
- 绘制好的这个图交给 GPU,GPU 会对这些纹理做一些操作,比如旋转、缩放
- 复合多个图层到页面生成最终的图像 Compsite Layers
- Composite Layers (自占线程) 的流程?—— 5/6 两步的详细展开
- 图层通过 CPU 绘制好的时候,主线程会把图层 commit 到合成线程
- 合成线程根据 viewport 将图层进行分块 tile,每个图块的大小对应了像素点
- GPU 将小 tiles 生成位图,通过栅格化来完成生成位图 raster
- 所有的图块都被栅格化后,合成线程会生成一个绘制图块的 DrawQuad,然后再交给浏览器
- 浏览器里面有一个 viz 组件,专门用来接收 DrawQuad,将这些页面的内容绘制到内存中,最终 Chrome 应用程序看见页面
- 当 GPU 接收到 CPU 绘制的图层进行旋转、缩放以后,先绘制一张分辨率低的图,继续绘制,绘制完成后替换掉
会独立成层的:
- 根元素
- transform
- 半透明
- CSS 滤镜
- canvas
- video
- overflow
GPU 会参与的
- CSS3D
- video
- webgl
- transform
- CSS 滤镜
- will-change:transform
浏览器的缓存机制
浏览器会先去看 强缓存 ( Expires 和 Cache-Control )判断是否过期,如果有效,直接从缓存中读取;如果无效了则进行 协商缓存 ( Last-Modified / If-Modified-Since 和 Etag/If-None-Match ),顾名思义,协商缓存就是和服务端协商是否使用缓存,若协商缓存失效,则代表请求的缓存失效,返回 200,并重新返回资源和缓存标识,再次存入浏览器缓存中;生效则返回 304,并从缓存中读取资源。
协商缓存由于要和服务端协商,所以要经过 DNS 域名解析,之后建立 TCP 连接
浏览器缓存的位置:
- Service Worker:浏览器 独立线程 进行缓存,基于 web worker实现。
- Memory Cache: 内存缓存
- Disk Cache: 硬盘缓存
- Push Cache: 推送缓存 ( HTTP 2 中的)
输入网址后,会查找内存缓存,没有再找硬盘。都没有就发请求 普通刷新,内存缓存可用,如果匹配上会被优先使用,其次是磁盘缓存。 强制刷新:浏览器不适用缓存,因此发送得请求头均带有
Cache-Control:no-cache,服务器直接返回 200 和新内容
- 协商缓存:必须和服务端沟通过才知道的
**ETag & If-None-Match**:Etag 由服务端生成,客户端通过 If-None-Match 来验证资源是否修改。
第一次请求,客户端发起 HTTP GET 请求一个文件,然后服务端处理请求,返回响应报文,响应头包括 Etag;第二次请求,客户端发送的请求报文的请求头包括 If-None-Match,而它的值就是 Etag 的值。服务端会判断客户端发送过来的 If-None-Match 和服务端的 Etag 值是否相同,如果相同,就把 If-None-Match 设置为 false,状态码置为 304,响应体为空,使用缓存。- 如果一样,返回
304,语义为Not Modified,不返回内容(body),只返回header,告诉浏览器直接用缓存 - 如果不一样,返回
200和最新内容
- 如果一样,返回
**Last-Modified & If-Modified-Since**:存放是资源最后修改时间,服务端会拿If-Modified-Since和Last-Modified的时间比较,- 如果
If-Modified-Since的时间不等于Last-Modified的时间,那么说明改过了,返回200和新内容 - 如果一样,也就是没有更新,返回
304,不返回内容,只返回头,客户端直接用缓存
- 如果
**ETag**的优先级比**Last-Modified**高,因为Last-Modified只能精确到秒,如果在同一秒内多次修改,是看不出区别的;而ETag每次修改都会生成新的。但是,ETag如果设计为一个 hash 值,每次请求都要计算这个值,需要额外耗费服务器资源
If-modified-since 只存在于get或head请求中
强缓存:不用跟服务器协商,直接用本地缓存的
- Expires:一个时间,在这个时间前,客户端浏览器都不会发起请求,而是直接使用缓存资源
Cache-Control:
通过它定义不同的值来定义缓存策略
- max-age=2000:资源能被缓存的最大时间,这里单位是 s
- no-cache:每次请求时,缓存会将此请求发送到服务器,服务器端会验证请求中描述的请求是否过期,若未过期,返回 304,缓存才使用本地缓存副本(协商缓存)
- no-store:缓存中不得存储关于任何客户端请求和服务端响应的内容
- private:抓门用于某个用户的,中间人不能缓存此响应,该响应只能用于浏览器私有缓存中
- public:该响应可以被任何中间人(中间代理、CDN 等)缓存
- 如果在 Cache-Control 响应头设置了 max-age,Expires 头就会被忽略
如果不想让浏览器缓存:
DOM、CSS、JS
解析和渲染不是一回事
- 众所周知,JS 的执行会阻塞 DOM 的解析,所以,我们一般会将 JS 脚本放在 body 的最后。但是,这样会阻塞 DOM 的渲染,即需要等待 JS 脚本执行完毕,页面才会渲染。
- 众所周知,CSS 不会阻塞 DOM 树的解析,但是 CSS 会阻塞 DOM 树的渲染。否则,像老式 IE 浏览器,会出现页面先是乱的情况
- CSS 会不会影响 DOMContentLoaded 事件?—— 如果 html 中同时存在 JS 和 CSS,而 JS 在 CSS 前面,就不会影响;如果 JS 在 CSS 后面,那么就会影响,即 DOMContentLoaded 要等到 CSS 加载完成才加载。
如何解析请求回来的HTML代码,DOM树又是如何构建的?
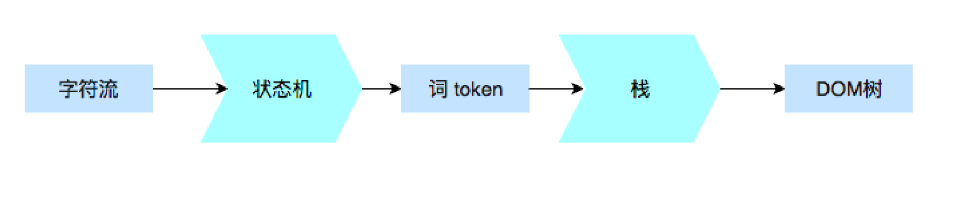
解析代码
词(token)是如何被划分的
<p class="a">text fuck shit</p>
拆分:
- <p “标签开始”的开始
- class=”a” 属性
“标签开始”的结束
- text text text 文本
- 标签结束
| 示例词 | 解释 |
| —- | —- |
|
| “开始标签”的结束 | | | 结束标签 | | hello world | 文本节点 | | | 注释 | | <![CDATA[hello world!]]> | CDATA数据节点 |
构建DOM树
使用栈
比如:
<html><head><title>cool</title></head><body><img src="a" /></body></html>
栈顶元素就是当前节点
遇到属性,就添加到当前节点
遇到文本节点,如果当前节点是文本节点,则跟文本节点合并,否则入栈成为当前节点的子节点
遇到注释节点,作为当前节点的子节点
遇到tag start就入栈一个节点,当前节点就是这个节点的父节点
遇到tag end 就出栈一个节点(还可以检查是否匹配)
浏览器如何把CSS规则应用到节点上并添加上CSS属性的
构建DOM的过程,从父到子,从先到后,一个一个节点构造,并且挂载到DOM树上,这个过程,CSS属性是可以被同步计算出来的。在这个过程,我们依次拿到上一步构造好的元素,去检查它匹配到了哪些规则,再根据规则的优先级,做覆盖和调整。
选择器有个特点:选择器的出现顺序,必定跟构建DOM树的顺序一致,这是一个CSS设计的原则,即保证选择器在DOM树构建到当前节点时已经可以准确地判断是否匹配,不需要后续节点信息
CSS构建的操作
后代选择器 “空格”
a#b .cls {width: 100px;}
可以把一个CSS选择器按照compound-selector来拆分成数段,每当满足一段条件的时候,就前进一段。比如上面的例子中,当我们匹配到了a#b的元素,才会开始检查它所有的子元素是否匹配.cls。除此之外,还需要处理后退的情况,比如,
<a id="b"><span>1</span><span class="cls">2</span></a><span class="cls">3</span>
当遇到</a>时,必须使得规则a#b .cls 后退一步,这样三个span才不会被选中
:::success
多数浏览器的实现是从右往左比配的
:::
后继选择器 “~”
这里给选择器的激活,带上一个条件:父元素。
后继节点和当前节点父元素相同是充分必要条件
子代选择器 “>”
div>.cls {border: 1px solid green;}<div><span>1</span><span class="cls">2</span><span>3<span>4</span></span><span>5</span></div>
这段代码,当DOM树构造到div时,匹配了CSS规则的第一段,因为是子代选择器,我们激活后面.cls选择条件,并且指定父元素必须是当前div。于是后续的构建树过程中,span2就被选中了
直接后继选择器 “+”
一个最简单的思路就是:可以把它当作检查元素自身的选择器来处理。
即我们可以把#id+.cls都当作检查某一个元素的选择器
逗号分隔
选择器重合
可以使用树形结构来进行一些合并
#a .cls {}#a span {}#a>span {}
#a<空格>.cls<空格>span>span
这里的树必须带上连接符
浏览器进行到这一步,我们已经可以给DOM添加了用于展示的CSS属性,接下来,浏览器的工作就是确定每一个元素的位置
浏览器的排版

若有收获,就点个赞吧
0 人点赞
