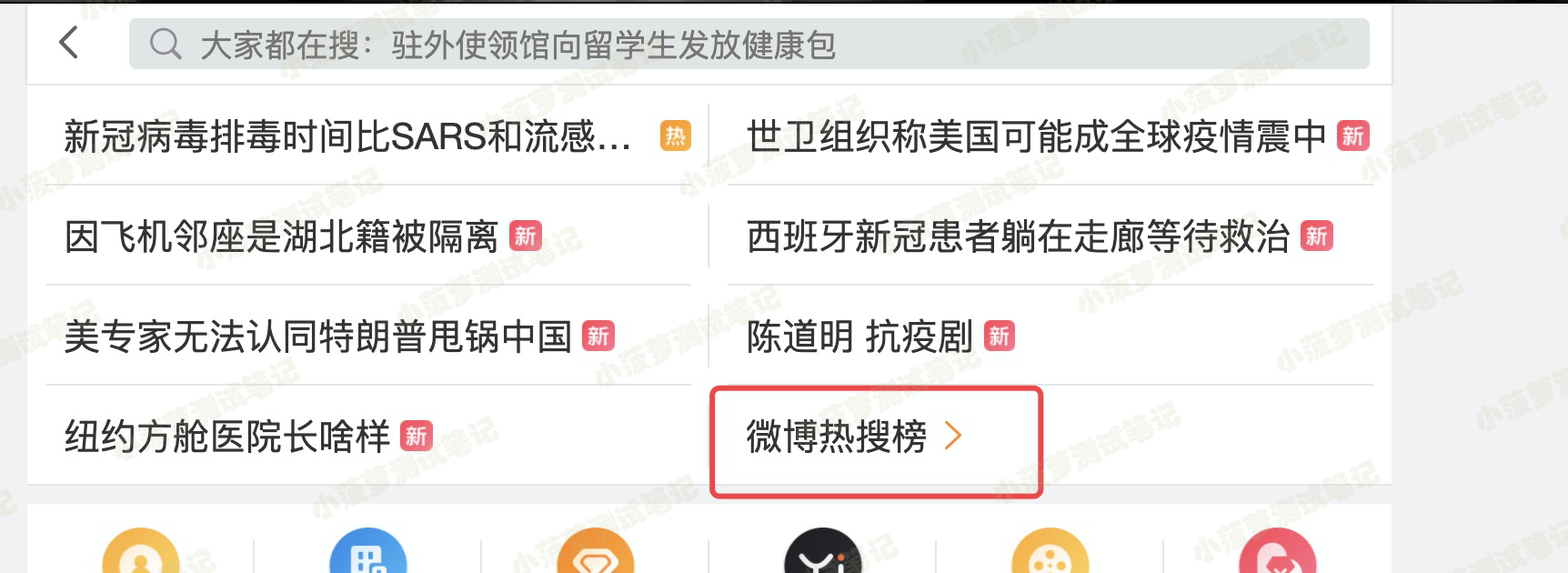
实战题目
- 访问:https://m.weibo.cn/
- 点击:大家都在搜
- 点击:微博热搜榜
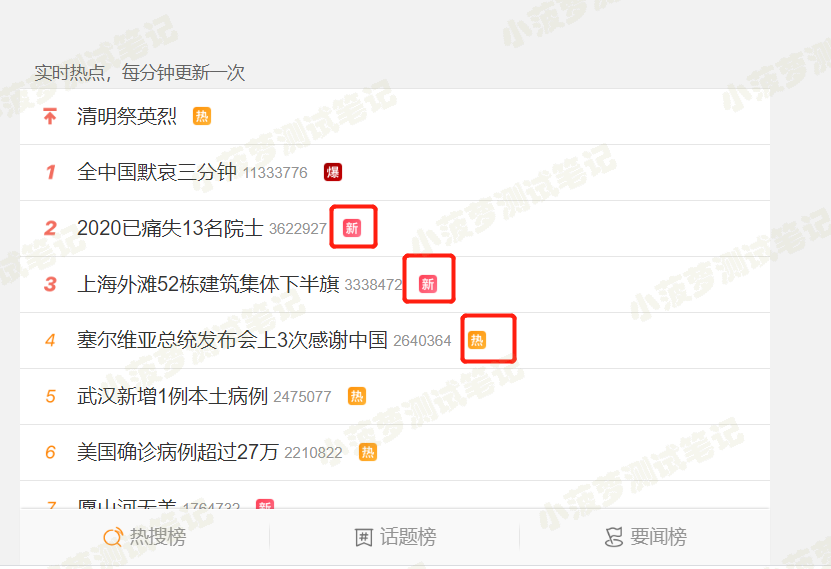
- 找到:实时热点,每分钟更新一次
- 将其中带有 热、沸、新字样的热搜信息获取到,并注明属于三种当中的哪一种
代码思路(人为测试时的操作步骤)
主要是第五步可能会有点困难
- 首先,定位到热点列表
- 循环,先获取热点文本
- 然后,后面的图标都是在放在 span 标签里面的,所以要获取span标签
- 最后,获取 img 标签,通过图片路径 src 属性判断是属于哪种热点新闻
代码
#!/usr/bin/env python# -*- coding: utf-8 -*-"""__title__ =__Time__ = 2020/3/25 14:08__Author__ = 小菠萝测试笔记__Blog__ = https://www.cnblogs.com/poloyy/"""from time import sleepfrom selenium import webdriver# 需要将驱动路径改成自己的路径哦driver = webdriver.Chrome(executable_path=r"../resources/chromedriver.exe")url = "https://m.weibo.cn/"driver.get(url)# 点击搜索框driver.find_element_by_class_name("m-search").click()sleep(2)# 点击【微博实时搜索】driver.find_element_by_class_name("card-main").find_elements_by_class_name("m-item-box")[-1].click()sleep(2)# 查找listlists = driver.find_element_by_class_name("card11").find_element_by_class_name("card-list").find_elements_by_class_name("card4")# 循环热搜列表for i in lists:text = i.find_element_by_class_name("main-text").textspan = i.find_elements_by_class_name("m-link-icon")if span:src = span[0].find_element_by_tag_name("img").get_attribute("src")if "hot" in src:print(f"{text} 是 很热的头条")elif "new" in src:print(f"{text} 是 新的头条")elif "fei" in src:print(f"{text} 是 沸腾的头条")elif "recom" in src:print(f"{text} 是 推荐的头条")else:print(f"{text} 是 普通的头条")

若有收获,就点个赞吧
0 人点赞
