学习资源
- LangChain 中文入门教程
- LLM 大语言模型综述 LLM_大预言模型综述.pdf
- 大型语言模型(LLM)技术精要 https://zhuanlan.zhihu.com/p/597586623
- LLM总结(掘金) https://juejin.cn/post/7221508167652900923
- 【视频】李沐老师的论文解读 https://www.bilibili.com/video/BV1AF411b7xQ/
- 【视频】GPT 论文精读 https://player.bilibili.com/player.html?bvid=BV1AF411b7xQ&autoplay=0
- 【视频】吴恩达 ChatGPT工程师 https://www.youtube.com/watch?v=XQGtZHv4cho
- 教程 hugging-llm https://github.com/datawhalechina/hugging-llm
优质学习资源
① Will兄从海量资料中整理的Web3和AIGC项目/文集(相信我,你会被震撼到)② 个人体验最好的 AI 总结摘要工具 Glarity
[https://three-recorder-52a.notion.site/1c01142d07dc4e3da4ebe7c3c420d4c7](https://t.co/M0xh2s6jYI)<font style="color:rgb(15, 20, 25);"> </font>
③ AIGC工具/资源导航
[https://chrome.google.com/webstore/detail/chatgpt-glarity-summarize/cmnlolelipjlhfkhpohphpedmkfbobjc](https://t.co/8mDq8avB2Z)<font style="color:rgb(15, 20, 25);"> </font>
④ AIGC工具使用体验分享和推荐
[https://bytedance.feishu.cn/base/AIMAbnJxQaNgSGsBAtwcdAkLnvf?table=tblmZTd8VuUOOONh&view=vew0Eo17BB](https://t.co/eO4WIlls3J)<font style="color:rgb(15, 20, 25);"> </font>
5 GPT/AIGC/LLM/NLP/ChatGPT 学习 https://gofurther.feishu.cn/docx/Enofdl25BotoVrxth8ec4rNBn5c AIGC 交流群 工具沉淀 https://bytedance.feishu.cn/base/AIMAbnJxQaNgSGsBAtwcdAkLnvf?table=tblGkLEeCaE14GMp&view=vewO8guFzR ## Prompt + Youtube: Prompt Engineering Overview: https://www.youtube.com/watch?v=dOxUroR57xs&ab_channel=ElvisSaravia PromptPerfect 提示词工程
[https://bytedance.feishu.cn/docx/D9Wvd6nAB](https://t.co/saUXCPCnLn)
https://promptperfect.jinaai.cn/home
模型
- 可商用的 LLMs 列表 A list of open LLMs available for commercial use
Chatbot Arena Leaderboard Updates (Week 2) | LMSYS Org
大语言模型调研汇总 https://zhuanlan.zhihu.com/p/614766286 开源大语言模型汇总 https://mp.weixin.qq.com/s/BQOJNwfkApiZnFveMDBQ-w通用大语言模型
- ChatGML https://github.com/THUDM/ChatGLM-6B
- MOSS https://github.com/OpenLMLab/MOSS
- LLaMA https://github.com/facebookresearch/llama
- Alpaca https://github.com/tatsu-lab/stanford_alpaca
- 中文LLaMA&Alpaca大语言模型 https://github.com/ymcui/Chinese-LLaMA-Alpaca
专业领域模型
- 华佗 https://github.com/scir-hi/huatuo-llama-med-chinese - 本项目开源了经过中文医学指令精调/指令微调(Instruct-tuning) 的LLaMA-7B模型。我们通过医学知识图谱和GPT3.5 API构建了中文医学指令数据集,并在此基础上对LLaMA进行了指令微调,提高了LLaMA在医疗领域的问答效果。
模型微调
lamini
https://github.com/lamini-ai/lamini
Official repo for Lamini’s data generator for generating instructions to train instruction-following LLMs.Lamini数据生成器的官方存储库,用于生成指令以训练遵循指令的LLM。 What’s here?
- A 71K dataset of instructions used for finetuning your own instruction-following LLM (like ChatGPT, which was also trained to follow instructions).
一个 71K 的指令数据集,用于微调你自己的指令遵循 LLM(如 ChatGPT,它也被训练为遵循指令)。 - The code for the data generator, which only needs 100 datapoints to start generating 70k+ datapoints. You can customize the original 100+ datapoints to your own domain, to focus the data generator on that domain.
数据生成器的代码,只需要100个数据点就可以开始生成70k+数据点。您可以将原始 100+ 数据点自定义到您自己的域,以便将数据生成器集中在该域上。
算力资源
- GPU选型
- AutoDL AI 算力云
- google colab
chatgpt 访问通道
- ideachat https://ideachat.top/aff/SHUANG
- chatgpt 付费代理
Prompt相关
- sharegpt
- https://sharegpt.com/
- chatgpt的 prompt 和结果分享站点
- prompthero
- https://prompthero.com/
- 最流行的 Prompt 站点
项目
langchain-ChatGLM
基于本地知识的 ChatGLM 问答 https://github.com/imClumsyPanda/langchain-ChatGLM 一种利用 ChatGLM-6B + langchain 实现的基于本地知识的 ChatGLM 应用。增加 clue-ai/ChatYuan 项目的模型 ClueAI/ChatYuan-large-v2 的支持。 本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。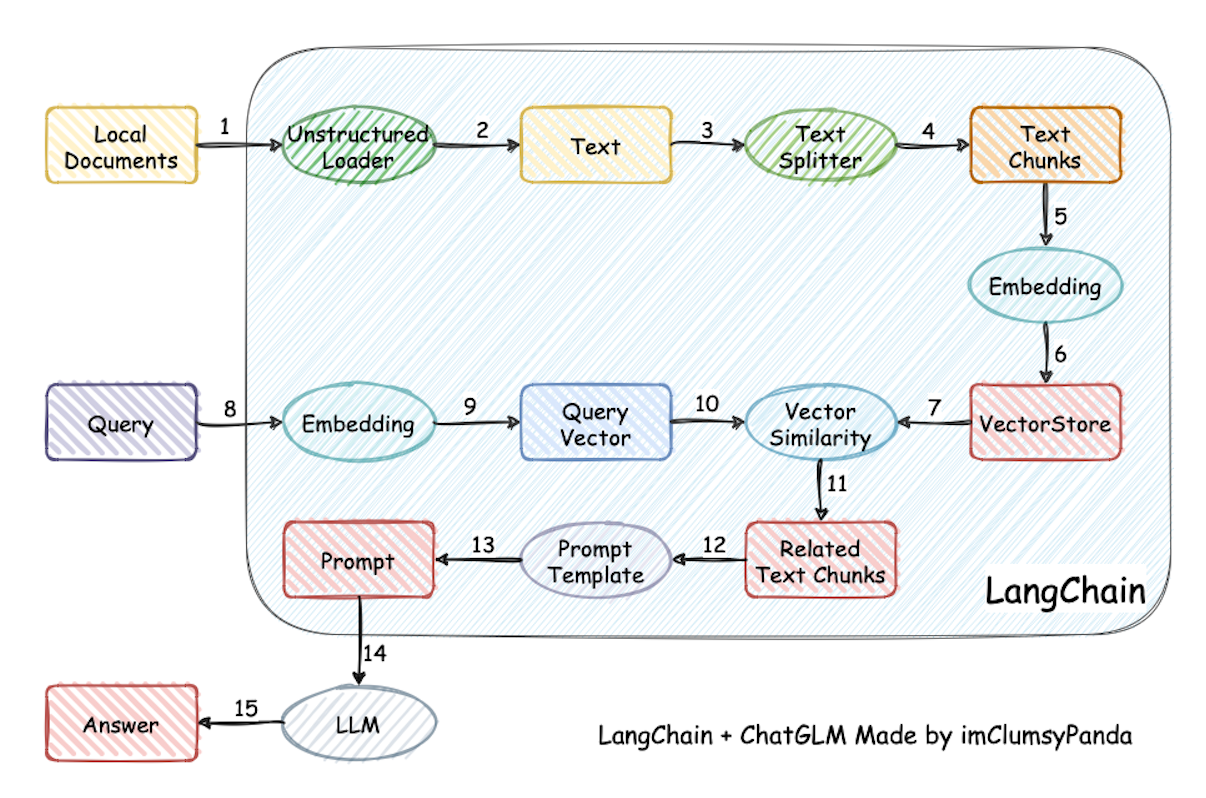
IBM Dromedary
Dromedary is an open-source self-aligned language model trained with minimal human supervision. For comprehensive details and insights, we kindly direct you to our project page and paper. Dromedary是一个开源的自对齐语言模型,在最小的人工监督下进行训练。关于全面的细节和见解,我们恳请您参阅我们的项目页面和论文。
闻达
闻达:一个LLM调用平台。为小模型外挂知识库查找和设计自动执行动作,实现不亚于于大模型的生成能力。基于本地知识的 ChatGLM 应用实现
https://www.heywhale.com/mw/project/643977aa446c45f4592a1e59
评估与数据
在 OpenAI GPT 系列 / Google PaLM 系列 / DeepMind Chinchilla 系列 / Anthropic Claude 系列的研发过程中,MMLU / MATH / BBH 这三个数据集发挥了至关重要的作用,因为它们比较全面地覆盖了模型各个维度的能力。
最值得注意的是 MMLU 这个数据集,它考虑了 57 个学科,从人文到社科到理工多个大类的综合知识能力。
- 今日头条 中文文本分类数据集
https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset
C-Eval
https://github.com/SJTU-LIT/ceval/blob/main/README_zh.md
C-Eval是全面的中文基础模型评估套件,涵盖了52个不同学科的13948个多项选择题,分为四个难度级别,如下所示。更多详情,请访问我们的网站或查看我们的论文。
LLM 工具
- ChatGPT Plus:通过 GPT-4 高效获取知识
- Copilot:高效写代码
- Cursor:帮助我理解开源代码,我觉得阅读开源代码是提升技术的好方式
- Poe.com:与 ChatGPT 互为补充
- Bing Chat:具备联网能力,能检索一些新知识
- https://chat.lmsys.org/ 切换多个开源模型进行聊天,评测
- FastChat https://github.com/lm-sys/FastChat 1. 一个用于训练、服务和评估基于大型语言模型的聊天机器人的开放平台。
文章摘录
这几天看到GPT技术在往两个截然相反的方向发展得越来越离谱了,变化也是真的太快太快了。
- 一个是 AutoGPT 路线,主打一个AI联网自主行动的能力,面对复杂需求时甚至可以分裂成多个AI协同完成任务。
- 另一个是 GPT4ALL,作为开源的LLM模型可以被部署到个人电脑上,不需要网络、Token、API,只接受主人给它的资源,最后形成一个私有化的知识应答系统,任何一台普通配置的电脑都能运行。
如果AutoGPT代表的是科幻电影里那种「天网」类型,让AI在无干预的情况下自己解决问题,那么GPT4ALL就是把AI又重新封装到了U盘里,专注于服务私人场景。
可以把 ChatGPT 看作是万维网上所有文本的模糊 JPEG。它保留了万维网上的大部分信息,就像 JPEG 保留了高分辨率图像的大部分信息一样。但是,如果你要寻找精确的比特序列,你无法找到它,你得到的只是一个近似值。但是,因为这个近似值是以语法文本的形式呈现的,而 ChatGPT 擅长创建语法文本,所以它通常是可以接受的。你看到的仍然是一张模糊的 JPEG,但模糊发生的方式不会使图片整体看起来不那么清晰。 这种与有损压缩的类比不仅仅是一种理解 ChatGPT 通过使用不同的单词重新打包万维网上找到的信息的方法,它也是一种理解“幻觉”或对事实性问题的无意义回答的方法。而大语言模型(如 ChatGPT)都很容易出现这种情况。这些幻觉是压缩后的产物。但是,就像施乐复印机产生的错误标签一样,它们似乎是可信的,要识别它们就需要将它们与原件进行比较。在这种情况下,这意味着要么是万维网,要么是我们自己对世界的认识。当我们这样想的时候,这样的幻觉一点也不令人惊讶。如果一种压缩算法被设计成在 99% 的原始文本被丢弃后重建文本,我们应该预料到它生成的很大一部分内容将完全是捏造的。参考
[1]https://github.com/facebookresearch/llama
[2]https://huggingface.co/google/mt5-xxl/tree/main
[3]https://huggingface.co/bigscience/T0
[4]https://huggingface.co/EleutherAI/gpt-neox-20b/tree/main
[5]https://huggingface.co/Salesforce/codegen-16B-nl
[6]https://github.com/google-research/google-research/tree/master/ul2
[7]https://github.com/google-research/t5x/blob/main/docs/models.md#flan-t5-checkpoints
[8]https://github.com/bigscience-workshop/xmtf
[9]https://openi.pcl.ac.cn/PCL-Platform.Intelligence/PanGu-Alpha
[10]https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
[11]https://huggingface.co/facebook/opt-iml-30b
[12]https://huggingface.co/bigscience/bloom
[13]https://github.com/bigscience-workshop/xmtf
[14]https://github.com/THUDM/GLM-130B
[15]https://huggingface.co/facebook/galactica-120b
[16]https://huggingface.co/datasets/bookcorpus
[17]https://www.gutenberg.org/
[19]https://www.tensorflow.org/datasets/catalog/c4
[20]https://huggingface.co/datasets/cc_news
[21]https://github.com/rowanz/grover/tree/master/realnews
[22]https://huggingface.co/datasets/spacemanidol/cc-stories
[23]https://skylion007.github.io/OpenWebTextCorpus/
[24]https://files.pushshift.io/reddit/
[25]https://dumps.wikimedia.org/
[26]https://cloud.google.com/bigquery/public-data?hl=zh-cn
[28]https://arxiv.org/abs/2303.03915
[30]https://github.com/microsoft/DeepSpeed
[31]https://github.com/NVIDIA/Megatron-LM
[32]https://github.com/google/jax
[33]https://github.com/hpcaitech/ColossalAI

若有收获,就点个赞吧
0 人点赞
