LLMs and Chatting to Your Knowledge Base. Humans just love to chat to robots. This week I’ve met with several Sr. Business Analysts across finance, insurance and retail companies. And one common theme amongst them is this:
We’d love to chat to our business knowledge repositories… Be able to search and retrieve interesting stuff using a chatbot… using something like… you know: a Large Language Model? Could we do “this thing” in-house?
Wait! Which LLM are you talking about? There is no such thing as “a sausage.” There are many varieties of sausages. Like sausages, LLMs come in many varieties and flavours too. Just for example think of all the LLaMA models out there. Checkout: A brief history of LLaMA models.
So I guess the first thing to understand is: Which type of LLM are you going to use? What’s the LLM’s license? Is it closed or open-sourced? And: Do you understand The Economics of Large Language Models? All this has significant implications when building LLM chat apps. In the paper Harnessing the Power of LLMs in Practice, the researchers have done a terrific job in describing the evolutionary tree of LLMs, and its main branches: Transformer-based, decoder-only, encoder-only, and encoder-decoder models. Checkout this diagram, afaik one of the best I’ve seen on this subject: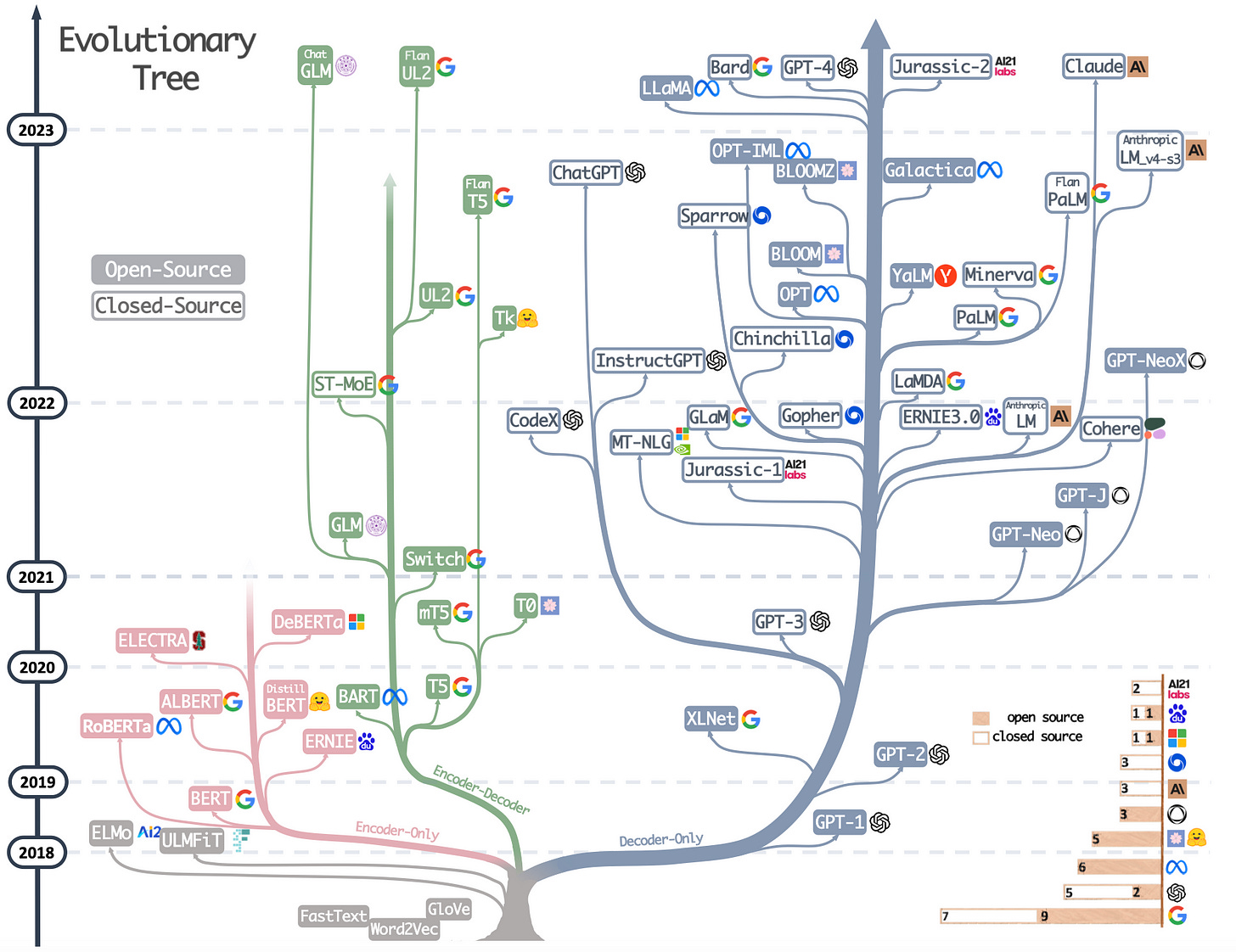
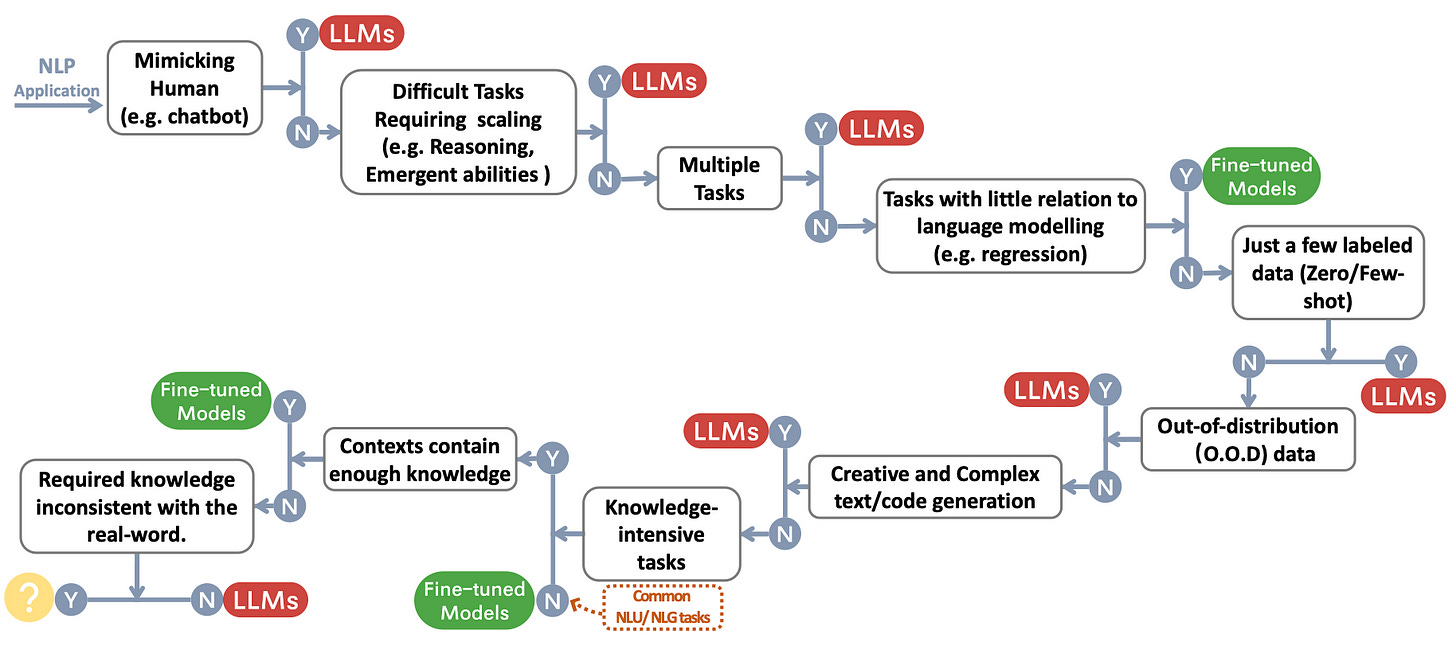
Search, Knowledge Retrieval, Embeddings with LLMs…Not easy stuff. Yes sure: you can build a toy bot chatting to a small PDF repo and so on. But here we’re talking about building an enterprise chatbot for business repositories with 100s of millions of long-form documents. Accuracy, speed and efficiency are big matters in business.
LLMs & knowledge retrieval shortcomings. In Knowledge Retrieval Architecture for LLM’s (2023), Matt provides a great overview of the shortcomings of knowledge retrieval for existing LLM’s. He also describes a tentative architecture for addressing those shortcomings. This is a great read.
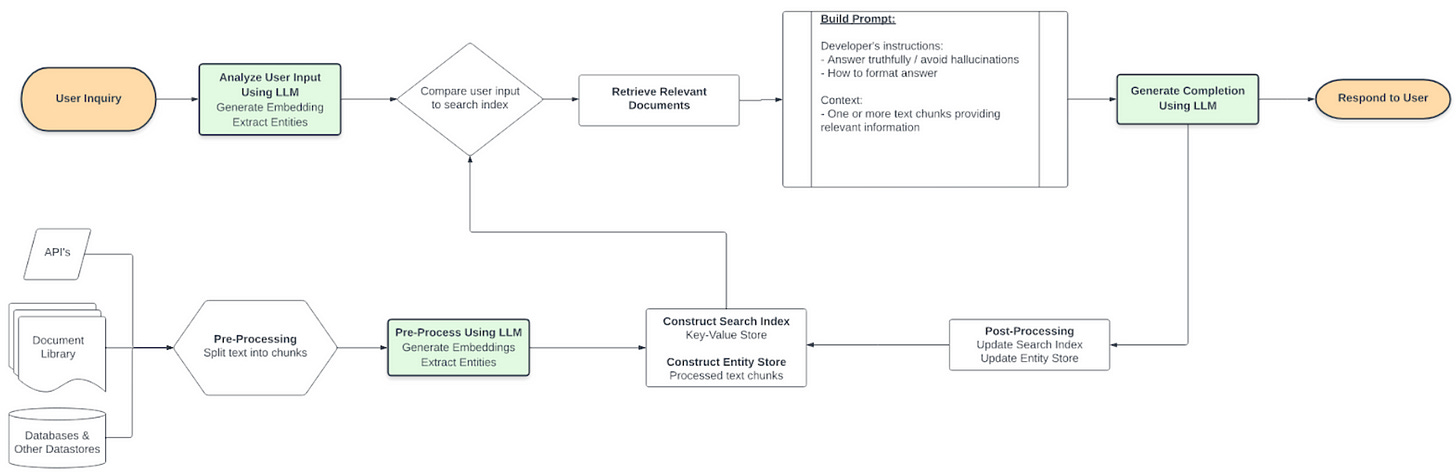
LLMs and embedding long-form documents, still an issue. Because the way LLMs work, stuff like chunking the long-form text and performing embedding is still inefficient.This is a great example on how to use the GPT-4 API to build a chatGPT chatbot for multiple Large PDF. It’s a framework that makes it easier to build scalable AI/LLM apps and chatbots. The tech stack includes: LangChain, Pinecone, Typescript, OpenAI, and Next.js.
Search and retrieval with LLMs may deliver hallucinations. Not just because you’ve nicely chained some clever prompt instructions, applied embeddings, and some vector search DB, you’ll avoid LLM hallucinatory answers. That’s not good in business apps.
In this rather obscure paper: Precise Zero-Shot Dense Retrieval without Relevance Label, researchers @CMU came up with a new method called Hypothetical Document Embeddings__ (HyDE.) that deals with hallucinations from embeddings. Not intuitive. HyDE is an embedding search technique that begins by generating a hypothetical answer and then using that hypothetical answer as the basis for searching the embedding system. Brian wrote a nice post with examples on how to do Q&A with ChatGPT + Embeddings & HyDE. Combining semantic search, embeddings and LLM is hard. Distance similarity and vector search won’t guarantee you 100% accurate results. Add to that tens of business users hitting the LLM chat with some generic, ambiguous queries. Ploughing ahead, Dylan has built Semantra: a tool that uses semantic search, embeddings and HugginFace Transformers. The purpose of Semantra is to make running a specialized semantic search engine easy, friendly, configurable, and private/secure.LLMs and Chatbots. The offspring of LLaMA and Alpacas has ignited the birth of many open-sourced, instruction-following, fine-tuned LLM models. This repo from Chensung is really cool: LLM as a Chatbot Service, it enables you to build Chatbots with LLMs like: LLaMA/ StableLM/ Dolly/ Flan/ - based Alpaca models.
- Call Annie! Your always available AI friend. Click on the link to talk or call her on +1 (640)-225-5726 now
- Play Prompt Golf with GPTWorld: A puzzle to learn about prompting
- Talk to Wikipedia using [obviously] wikipediaGPT
- ReadFive Worlds of AI: “AI-Fizzle,” “Futurama,” ”AI-Dystopia,” “Singularia,” and “Paperclipalypse.”
10 Link-o-Troned
- [a must read] A Cookbook of Self-Supervised Learning
- [free course]ChatGPT Prompt Engineering for Developers
- Introducing AgentLLM: Browser-native Auto-agents
- L.I.T. Large-scale Infinite Training
- [deep dive] Transformers from Scratch
- DeepFloyd IF: New Text-to-Image SoTA, Research Licence
- StableVicuna: World’s 1st Open-source RLHF LLM Chatbot
- Fine-tuning an LLM with H2O LLM Studio
- ResearchGPT: Automated Data Analysis and Interpretation
- ICLR 2023 — 10 Topics & 50 Papers You Shouldn’t Miss

若有收获,就点个赞吧
0 人点赞
