https://www.vertabelo.com/blog/all-about-indexes-part-2-mysql-index-structure-and-performance/
数据库索引加快了数据检索操作。但是我们为这些利益付出了代价。
在本文中,我们将重点介绍MySQL索引背后的结构。我们还将通过使用大型数据集来测试同一数据库的两个版本(一个带有索引,另一个没有索引)来衡量数据库性能。
这是我们系列中有关数据库索引的第二篇文章。如果您错过了第一个,请单击此处。
索引使用什么结构?
MySQL支持几种不同的索引类型。最重要的是BTREE和HASH。这些类型也是其他DBMS中最常见的类型。
在开始描述索引类型之前,让我们快速回顾一下最常见的节点类型:
- 根节点–树形结构中的最高节点
- 子节点–另一个节点(父节点)指向的节点
- 父节点–指向其他节点的节点(子节点)
- 叶节点–没有子节点的节点(位于树结构的底部)
- 内部节点–所有“非叶”节点,包括根节点
- 外部节点–叶节点的别称
二叉搜索树
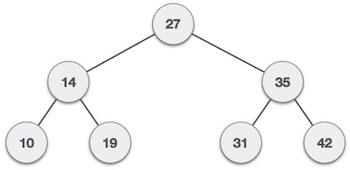
现在,让我们考虑二叉搜索树(BST)结构。这些结构不是数据库索引,但是最好了解它们如何工作。您很快就会看到数据库使用的树结构(B树和B +树)是相似的。
BST是对节点进行排序的二叉树。在上图中,我们看到节点X左侧的值小于X,节点X右侧的值较大。这就是任何BST的组织方式。
当我们在BST中搜索值时,我们从根节点开始,然后将搜索到的值与根节点的值进行比较。如果搜索到的值小于根值,我们将转到左侧的子树。如果更高,那么我们转到正确的子树。如果我们找到了价值,那就完成了。如果到达叶节点而没有找到我们的值,我们知道它不在我们的树中。
就像搜索值一样,开始向BST添加新值。(当然,一旦找到适合我们值的位置,过程就会更改。)例如,如果要添加值“ 30”,则将其添加为节点“ 31”的左子节点(30大于27,因此我们向右移动; 30小于35,因此我们向左移动; 30小于31,因此我们再次向左移动。)
当我们想从BST中删除一个值时,情况就更加复杂了。在某些情况下,我们甚至可能需要重新排列树。存在三种可能的情况:
- 删除没有子节点的节点–我们将简单地从BST中删除该节点。在我们的示例中,这些是节点“ 10”,“ 19”,“ 31”和“ 42”。
- 删除具有一个子节点的节点–我们将删除的节点替换为子节点。如果节点“ 31”在左侧子树中具有“ 30”作为子节点,并且我们将其删除,则只需将“ 31”替换为“ 30”。
- 删除具有两个子节点的节点–这是最复杂的情况。在这种情况下,我们将在已删除节点的右子树中找到最小的元素,并将其放在已删除节点的位置。因此,如果删除节点“ 27”,我们将在右侧子树中寻找最小值,即“ 31”。我们将节点“ 27”替换为节点“ 31”。
B树
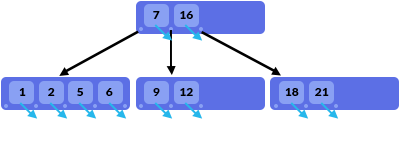
在B树*是大多数MySQL存储引擎的基本索引结构。B树中的每个节点的值介于d和_2d之间。每个节点中的值进行排序。每个节点都有0到_2d + 1*个子节点。每个子节点都在值之前,之后或之间附加。(在上图中,值“ 9”和“ 12”介于值“ 7”和“ 16”之间。)
B树中的值的排序方式与二叉搜索树中的值类似。值“ X”左侧的子节点的值小于X。值“ X”右侧的子节点的值大于X(请参见图片)。
与BST相比,B树是平衡树:树的所有分支具有相同的长度。
在B树中搜索值也对应于在BST中搜索。首先,我们检查根节点中是否存在该值。如果不是,我们选择适当的子节点,然后在该节点中查找值。
从B树中添加和删除值通常不会创建新节点:每个节点中的值数量可以变化。当然,这意味着我们将有一些空白空间,因此B树比密集树需要更多的磁盘空间。
添加值必须同时保持值的顺序和树的平衡。首先,我们将找到应在其中添加值的叶节点。如果叶节点中有足够的空间,我们将简单地添加该值。结构和树的深度不会改变。
在我们的示例中,添加值“ 22”将非常简单。我们只需将其添加到第三个叶节点。如果要添加值“ 4”,则将拆分第一个叶节点。这总是在发生溢出的情况下发生。值“ 1”和“ 2”将形成一个新的叶子节点(左边的叶子节点);值“ 4”将是中间节点(并插入到父节点中),而值“ 5”和“ 6”将形成另一个新的叶子节点(右侧)。
如果那里发生溢出,我们将以相同的方式拆分父节点。在极端情况下,我们必须拆分根节点,树的深度会增加。
当我们想从B树中删除一个值时,我们将找到该值并将其删除。如果该删除导致下溢(存储在节点中的值的数量太少),我们将不得不将节点合并在一起。这与添加值时发生的情况恰好相反。我们将将该节点与包含最多值的相邻节点合并。如果新合并的节点包含太多值(溢出),我们将其拆分为左,中和右,并重新排列树结构。
在数据库索引中使用B-Tree时,每个节点都保留索引值和指向它来自的行的指针。例如,如果索引在列id上,则树将同时保留值“ 7”和指向id = 7的行的指针。当我们搜索id = 7的行时,我们可以在B树中快速找到值7,然后按照指针获取实际行。
要记住的重要一点是,在B树结构中,每个节点都包含键值,指向该值的指针以及指向与父节点中的值相比越来越小的值的子节点的指针。当然,叶节点不会指向任何子节点。
使用B树索引,我们可以使用相等运算符(=或<=>),将产生范围的运算符(>,<,> =,<=,BETWEEN)和LIKE运算符。
我们也可以在多个列上创建索引。如果我们在(first_name,last_name)对上创建了索引,则可以使用任一个术语进行搜索,但是当我们仅使用这些属性之一时,索引也将起作用。
最后,最好注意的是,当最常访问的数据靠近根节点时,B树的性能会更好。
B +树
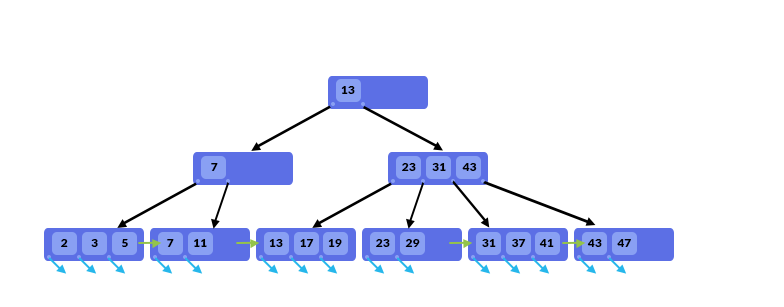
的*_B +树_结构是类似的B树结构。最重要的区别是:
- 内部节点仅存储值。他们不存储指向实际行的指针。叶节点存储值和行指针。这减小了内部节点的大小,从而允许在同一内存页面上存储更多节点。反过来,这增加了分支因子。随着分支因子的增加,树的高度减小,从而导致更少的磁盘I / O操作。
- B + Tree中的叶节点是链接的,因此我们只需一次扫描即可进行完整扫描。当我们需要查找给定范围内的所有数据时,这将非常有用。由于行指针存储在内部节点和叶节点中,因此在B树中是不可能的。
- 与在B树中执行删除操作相比,在B树结构中执行删除操作要容易得多。这是因为我们不需要从内部节点中删除值。在B + Tree结构中,我们将重复相同的值;在B树结构中,每个值都是唯一的。在B + Tree中,我们将在叶节点中存储一个值和一个数据指针,但是该值也可以存储在内部节点(用于指向子节点的位置)中。
- B-Tree的优点是我们可以很快找到靠近根的值,而在B + Tree中,我们需要一直寻找到叶节点的任何值。
InnoDB存储引擎使用B + Tree结构来存储索引。
哈希索引
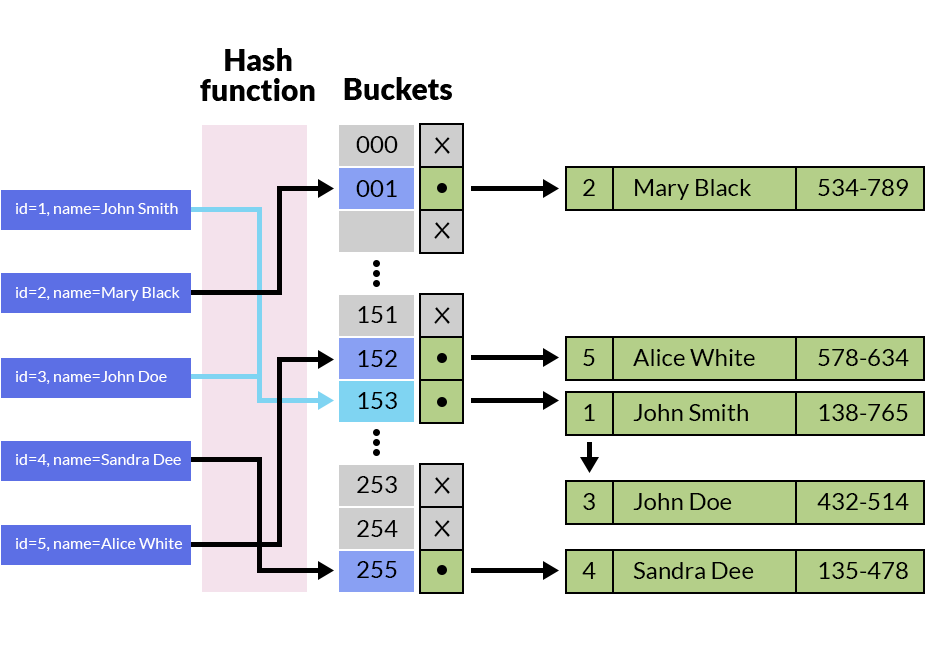
*_哈希索引_与哈希技术直接相关。看上面的图片。在左侧,我们看到了用于查找数据的一组键值。在这种情况下,它们是数值。哈希函数用于计算实际数据存储区的存储地址。这将为我们提供与每个键值相关的记录的位置。
值基于哈希函数的值存储在存储桶中。当我们想搜索一个值时,我们将使用哈希函数来计算可以存储数据的地址。我们将在存储桶中查找数据。如果找到它,就完成了。如果找不到我们的值,则意味着它不在索引中。
添加新值的工作原理类似:我们将使用哈希函数来计算存储数据的地址。如果该地址已被占用,我们将添加新的存储桶并重新计算哈希函数。再一次,我们将整个键用作函数的输入。结果是实际的地址(在磁盘内存中),我们可以在其中找到所需的数据。
更新或删除值包括:首先搜索一个值,然后在该内存地址上执行所需的操作。
测试相等性(=或<=>)时,哈希表索引非常快。这是因为我们正在使用整个密钥,而不仅仅是部分密钥。当我们要查找范围,使用<或>运算符或加快子句的ORDER BY部分时,各个部分都无法帮助我们。
MySQL,MyISAM和其他引擎中的索引类型
MySQL同时使用BTREE(B树和B +树)和HASH索引。MyISAM仅使用BTREE索引,而MEMORY / HEAP和NDB可以同时使用HASH和BTREE。默认情况下,MEMORY / HEAP和NDB将使用HASH索引结构。
如果要指定索引结构,则需要在CREATE INDEX语句中添加USING BTREE或USING HASH。在VERTABELO中,我们通过在“索引”部分中设置“使用”值来实现。
性能测试:数据库和预期结果
在浏览器中编辑模型
authoridfirst_namelast_namebirth_dateintvarchar(255)varchar(255)datePKNbook_detailsidbook_titleeditionpublisherpublish_yearlanguage_idintvarchar(255)textvarchar(255)intintPKNNNFKgenreidgenre_nameintvarchar(255)PKbook_genreidbook_details_idgenre_idintintintPKFKFKbook_authoridbook_details_idauthor_idintintintPKFKFKbookidbarcodebook_details_idsection_idintvarchar(255)intintPKFKFKbookshelfidnamedescriptionintvarchar(255)varchar(255)PKsectioniddesignationbookshelf_idintvarchar(255)intPKFKlanguageidlanguage_nameintvarchar(255)PK
我们将测试两个完全相同的数据库的性能,一个使用索引,另一个不使用索引。为了简单起见,即使两个数据库的主键都有索引,我们也将它们称为已索引和未索引的数据库。这两个数据库的结构在上述模型中进行了介绍,并在本系列的第1部分中进行了详细介绍。
在测试数据库中,我已经添加了1,000,000记录时,对**book**,**book_details**,**book_genre**和**book_author**表格。
在第一篇文章中,我们使用以下语句创建了三个索引:
CREATE INDEX book_details_idx_1 ON book_details (book_title);CREATE INDEX author_idx_1 ON author (first_name,last_name);CREATE INDEX author_idx_2 ON author (last_name,first_name);
要从第二个数据库中删除这些索引,我们使用以下语句:
DROP INDEX book_details_idx_1 ON book_details;DROP INDEX author_idx_1 ON author;DROP INDEX author_idx_2 ON author;
预期结果:
使用索引的数据库还应该使用更多的磁盘空间。请记住,索引是结构化的,并存储来自索引属性的值的副本以及指向记录的指针。可以预期,用于查找和排序数据的查询(SELECT,ORDER BY)将比未索引数据库更快地在索引数据库上执行。但是,当我们使用INSERT,DELETE和UPDATE查询时,未索引数据库的性能应更好。
性能测试:数据库大小
每个MySQL服务器实例都会在information_schema数据库中存储有关每个数据库的所有相关数据。在这里,我们可以找到有关服务器,表,列,视图,触发器等上的数据库的所有相关数据。
我们将查询information_schema数据库以找到两个示例数据库的大小:
SELECTROUND(SUM(information_schema.tables.data_length + information_schema.tables.index_length) / (1024 * 1024), 2) AS "MB"FROM information_schema.tablesWHERE information_schema.tables.table_schema = "indexes_performance";
正如预期的那样,索引数据库的大小为315 MB,而未索引数据库的大小为289 MB。这似乎没有太大的区别,但大约是10%,我们只使用了三个索引。
我们将通过以下查询对这两个数据库进行更详细的研究:
SELECTa.table_name,a.MB AS "table size; data + index (MB) / INDEX",a.index_MB AS "index size (MB) / INDEX",b.MB AS "table size; data + index (MB) / NO INDEX",b.index_MB AS "index size (MB) / NO INDEX"FROM(SELECTinformation_schema.tables.table_name AS table_name,ROUND(SUM(information_schema.tables.data_length + information_schema.tables.index_length) / (1024 * 1024), 2) AS "MB",ROUND(SUM(information_schema.tables.index_length) / (1024 * 1024), 2) AS "index_MB"FROM information_schema.tablesWHERE information_schema.tables.table_schema = "indexes_performance"GROUP BY information_schema.tables.table_name) AS aLEFT JOIN(SELECTinformation_schema.tables.table_name AS table_name,ROUND(SUM(information_schema.tables.data_length + information_schema.tables.index_length) / (1024 * 1024), 2) AS "MB",ROUND(SUM(information_schema.tables.index_length) / (1024 * 1024), 2) AS "index_MB"FROM information_schema.tablesWHERE information_schema.tables.table_schema = "indexes_performance_no"GROUP BY information_schema.tables.table_name) AS bON a.table_name = b.table_name
结果是:
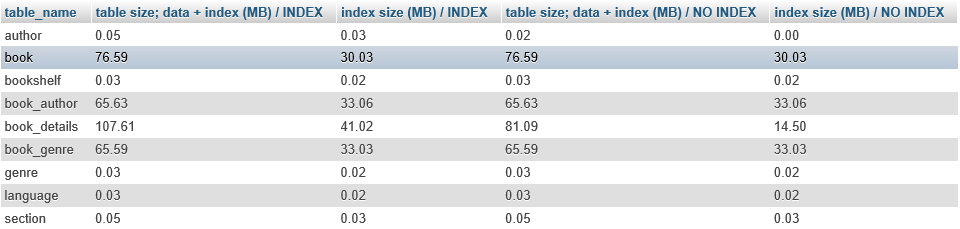
第一列是表名,两个数据库都相同。第二和第三列属于索引数据库,而第四和第五列属于未索引数据库。第二和第四列是数据大小和索引大小的总和,而第三和第五列是索引大小。
正如预期的那样,**book_details**和**author**表在索引数据库中更大。我们还可以看到,即使在未添加自定义索引的数据库中,也为索引保留了约110 MB的空间。这是在主键属性上创建的索引的大小。数据库大小的几乎所有差异都来自**book_details**表上添加的自定义索引。
性能测试:查询速度
我们将使用相同的数据库,但是这次我们将测量执行三个SELECT查询以及一个包含许多数据更改的存储过程所需的时间。
- 我们将使用的第一个查询非常简单:
```sql SET @start_time = NOW();
SELECT book_details.book_title, COUNT(*) AS result FROM book_details GROUP BY book_details.book_title;
SET @end_time = NOW();
SELECT TIMEDIFF(@end_time, @start_time) AS difference;
为了返回执行查询所需的时间,在查询之前和之后立即设置@start_time 和 @end_time_ _。他们的差异将告诉我们此操作花费了多长时间。<br />建立索引的数据库返回的结果比未建立索引的数据库快17倍。未索引版本被迫对信息进行顺序搜索,从而解决了时差问题。> **提示:MySQL支持以下语句:**> - DESCRIBE –通常用于描述表结构> - EXPLAIN和EXPLAIN EXTENDED –用于描述查询执行计划> - SHOW WARNINGS -用于在执行观察到的语句后显示有关条件(错误,警告等)的信息DESCRIBE,EXPLAIN和EXPLAIN EXTENDED放在查询的前面。显示警告应放在其后。2. 我们将使用的第二个查询更加复杂,我们可以预期两个数据库的执行时间都会增加:```sqlSET @start_time = NOW();SELECT author.first_name, author.last_name, COUNT(*)FROM book_details, book_author, authorWHERE book_details.id = book_author.book_details_idAND book_author.author_id = author.idGROUP BY author.first_name, author.last_nameORDER BY author.first_name, author.last_name;SET @end_time = NOW();SELECT TIMEDIFF(@end_time, @start_time) AS difference;
在这种情况下,建立索引的数据库给我们的结果比未建立索引的数据库快两倍。
- 我们将稍微修改第二个SELECT查询,添加一个选择条件:
SET @start_time = NOW();SELECT author.first_name, author.last_name, COUNT(*)FROM book_details, book_author, authorWHERE author.first_name = "Ernest"AND book_details.id = book_author.book_details_idAND book_author.author_id = author.idGROUP BY author.first_name, author.last_nameORDER BY author.first_name, author.last_name;SET @end_time = NOW();SELECT TIMEDIFF(@end_time, @start_time) AS difference;
索引数据库再次返回其结果的速度是未索引数据库的两倍。这是由于我使用了索引列;GROUP BY和ORDER BY子句在可用时使用索引。当然,该索引必须按在GROUP BY和ORDER BY子句中使用的顺序包含相同的列。
所有三个测试用例的结果均符合预期。当我们使用SELECT查询以及需要对返回值进行排序时,索引可以显着提高性能。
- 最后的性能测试执行的是删除从10,000行的存储过程
**book**,**book_details**,**book_genre**和**book_author**表格; 产生随机值;然后在所有四个表中添加10,000行。我不会粘贴过程代码,因为这样做太大(而且毫无意义)。
此过程需要在索引数据库上增加50%的时间。这凸显了一个事实,即在我们添加,更改或删除记录时,索引数据库需要时间来修改索引结构。
索引是非常强大的数据库结构。处理较小的数据集时,您可能不需要它们。但是随着事情变得复杂,索引在整体性能中起着至关重要的作用。我们介绍了三种常用的索引结构,并考虑了它们的优缺点。在测试过程中,我们已经表明,索引在检索和更改数据时会带来更好的性能。

若有收获,就点个赞吧
0 人点赞
