Yarn 是什么?
Yarn 出现的背景
解决 npm 安装速度慢,稳定性差的问题。在 npm 还处于 V3 的时候,npm 还没有 package-lock.json 文件,当时的 npm 安装速度慢,稳定性差,所以在 2016 年, Yarn 就出现了。
Yarn 的优点
- 稳定:通过 yarn.lock 机制,保证了稳定性,不管安装顺序如何,在相同的依赖关系,不同的环境下,都可以用相同的安装方式进行安装。
- 采用扁平化的安装模式:将依赖包的不同版本,根据一定的策略,归结为单个版本,避免创建多个副本产生冗余。
- 网络性能更好:采用排队请求的方法,类似并发请求池,能更好的利用网络资源。并且还有很好的失败重试机制。
- 缓存机制:实现离线缓存。
相比于 npm,yarn 还有一个特点,就是 yarn.lock 中子依赖的版本号,并不是确定的版本号,在这种情况下,单 yarn.lock 是确定不了 node_modules 目录结构,还需要和 package.json 进行配合才能确定 node_modules 的目录结构。
synp 一个可以将 package-lock.json 和 yarn.lock 文件进行相互装换的工具。
Yarn 缓存
yarn cache dir查看 Yarn 的缓存目录。
yarn 默认使用 prefer-online 模式,也就是优先使用网络数据,如果网络数据请求失败,再去请求缓存数据。
- yarn cache ls:列出当前缓存的包列表。
- yarn cache dir:显示缓存数据的目录。
- yarn cache clean:清除所有缓存数据。
yarn 默认会使用 “prefer-online” 的模式,也就是先尝试从远程仓库下载,如果连接失败则尝试从缓存读取。yarn 也提供了 --offline 参数,即通过 yarn add --offline 安装依赖。
另外 yarn 还支持配置离线镜像,通过以下命令设置离线缓存仓库。
yarn config set yarn-offline-mirror ./npm-packages-offline-cache
Yarn 安装机制和背后思想

检测包
检查是否存在 npm 相关的一些文件,比如 package-lock.json 文件等,如果有会提醒用户,可能会产生冲突。当然还会有 cup 和 os 的检查。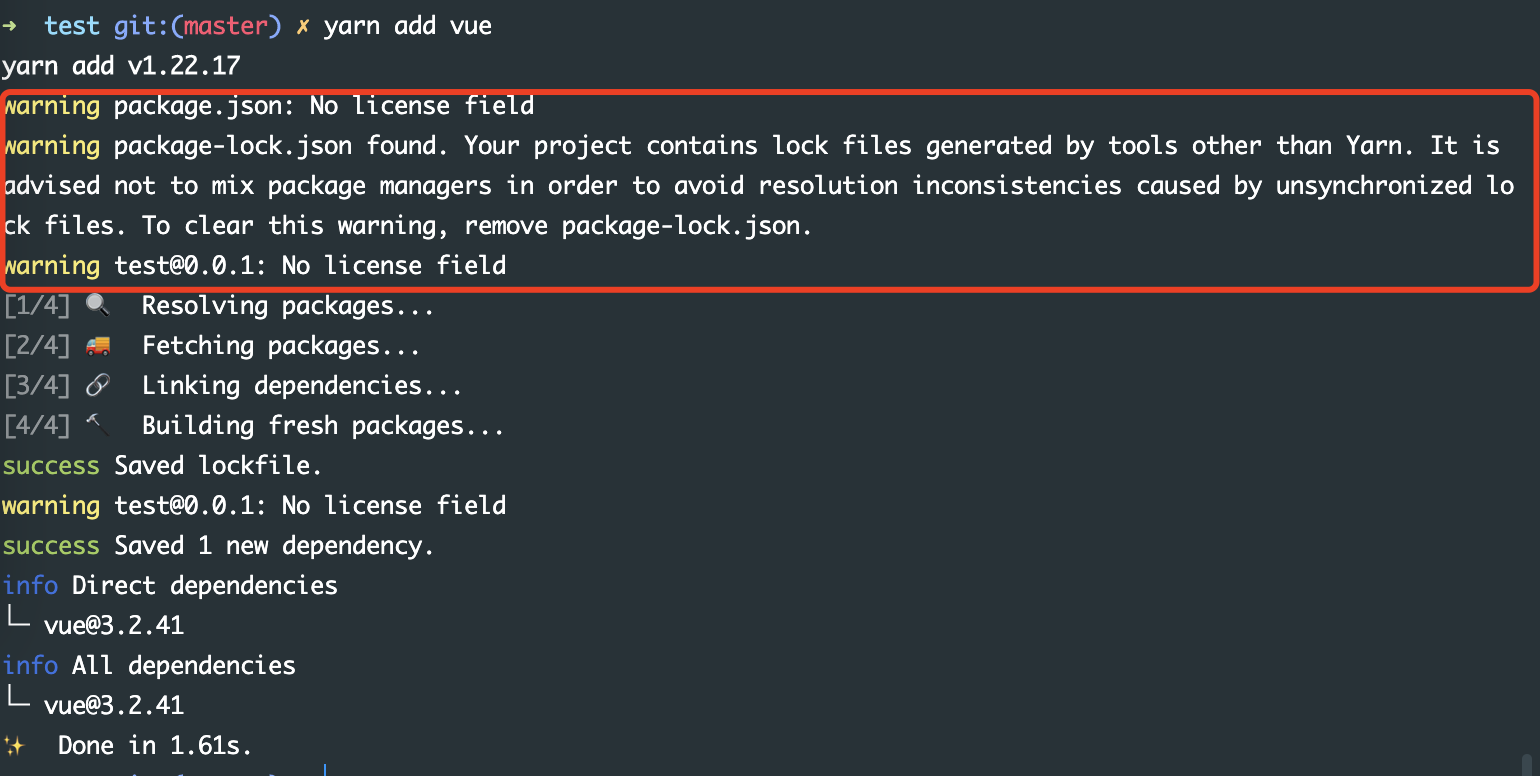
解析包
解析依赖树中的所有包的版本信息。由于依赖树是一个多层嵌套的结构,所有在这一步会进行一个递归解析。整个流程如下: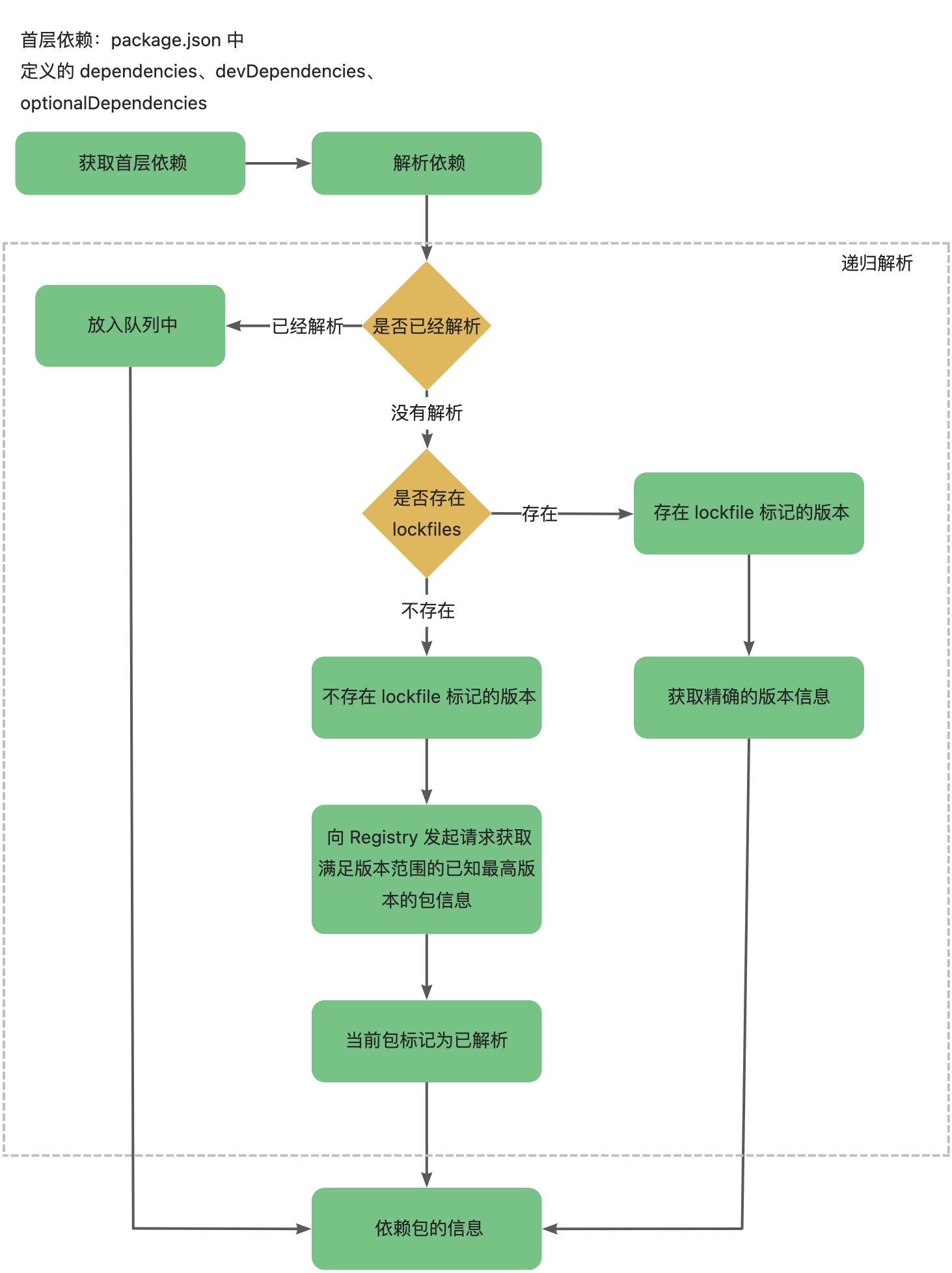
这个解析包的过程,目的就是获取所有包的版本信息和详细信息。
获取包
包资源的来源有两个地方,一个是网络,一个是缓存。网络我们知道是从网上进行资源包的下载,缓存也就是在我们电脑上的缓存目录中回去资源包。但是 Yarn 如何区分我们的包是要在网络上下载还是从缓存中进去查找了?
关键在于:Yarn 根据包相关的信息生成一个 path 路径,然后判断系统中是否存在这个路径,如果存在,说明系统中存在缓存,不需要重新下载,如果不存在就需要重新下载。
包的相关信息生成 path 路径:cacheFolder+slug+node_modules+pkg.name 生成一个 path。
但是这里需要注意一下,yarn 默认会使用 “prefer-online” 的模式,如果关闭这种模式就会走缓存,利用 path 判断系统中是否存在该 path,如果存在证明已经有缓存,不用重新下载。
对于需要重新下载的包,还需要判断是是在本地目录(可设置镜像为本地目录地址)中获取还是从网络中获取。完全的流程如下: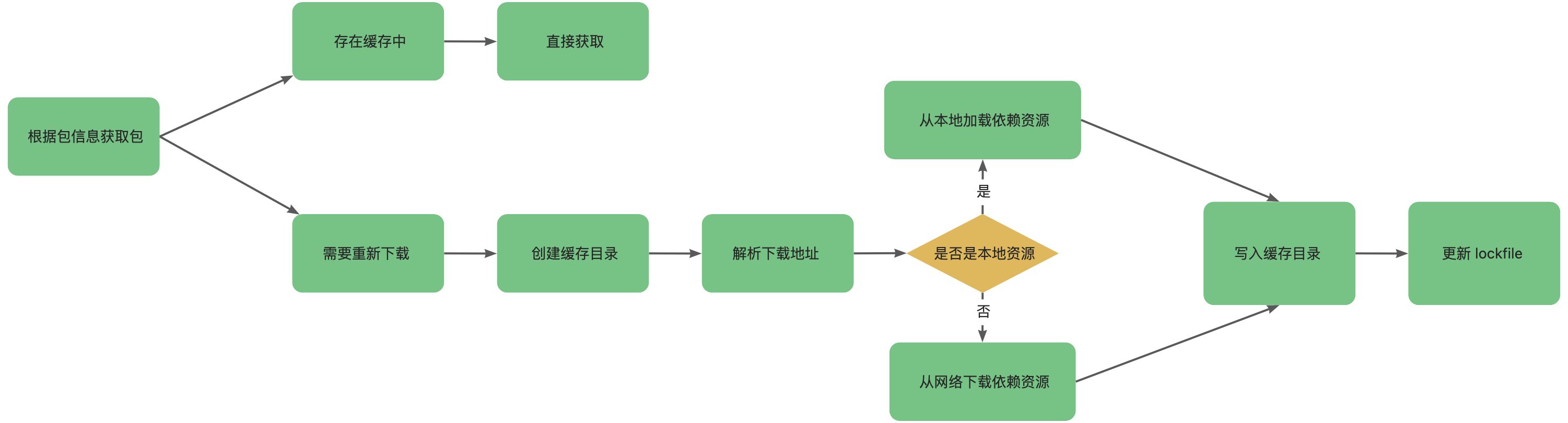
整个过程的目的是获取依赖资源包。
链接包
这一步的目的是将依赖资源包放入到项目的 node_modules 中。这里在复制依赖之前,首先会解析 peerDependencies,如果找不到符合 peerDependencies 的依赖包会警告提示,然后将依赖资源复制到项目的 node_modules 中。具体的流程如下: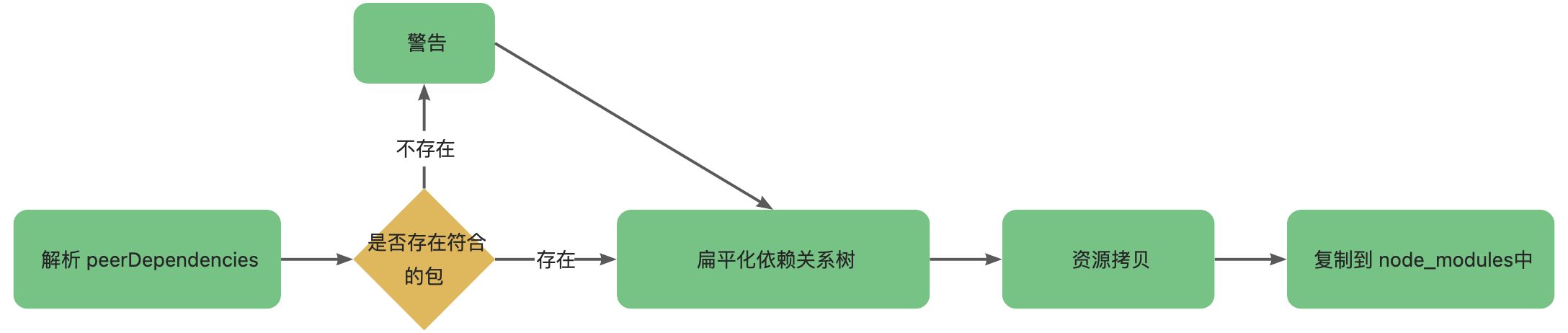
构建包
Yarn 的扁平化机制
在 npm v2 的时候,安装机制非常简单,就是在安装依赖的时候将依赖放到 node_modules 中。但是这种模式天然存在一定的劣势,比如:项目中有包 A, 包 A 依赖了包 B,包 B 有依赖了包 C,在这种情况下,就会递归形成一个依赖地狱。
依赖地狱:
- 不经依赖层次非常深,还不利于调试和问题的排除。
- 还会有大量重复的依赖包在项目中冗余存在。
这里举一个示例,在 npm v2 的时候项目中安装 express 模块,你会发现依赖是一层一层层层嵌套下去。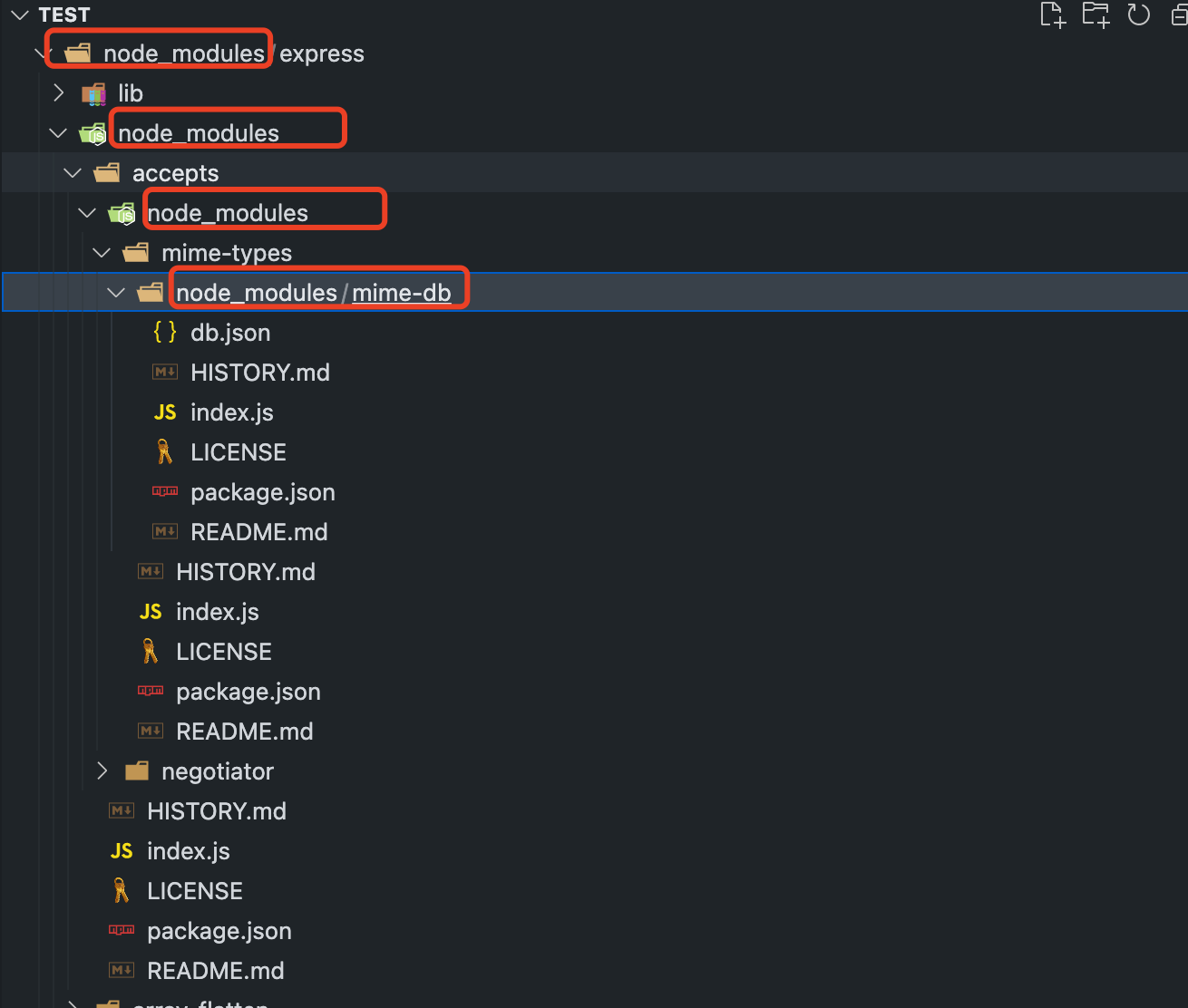
在 npm v2 中,重复问题使得安装结果浪费了较大的空间资源,也使得安装过程过慢,甚至会因为目录层级太深导致文件路径太长,最终在 Windows 系统下删除 node_modules 文件夹出现失败情况。
对于这种嵌套的依赖方式,Yarn 使用扁平化的模式。所有的依赖不再一层层嵌套了,而是全部在同一层,这样也就没有依赖重复多次的问题了,也就没有路径过长的问题了。
我们切换 Yarn,在项目中在安装一次 express。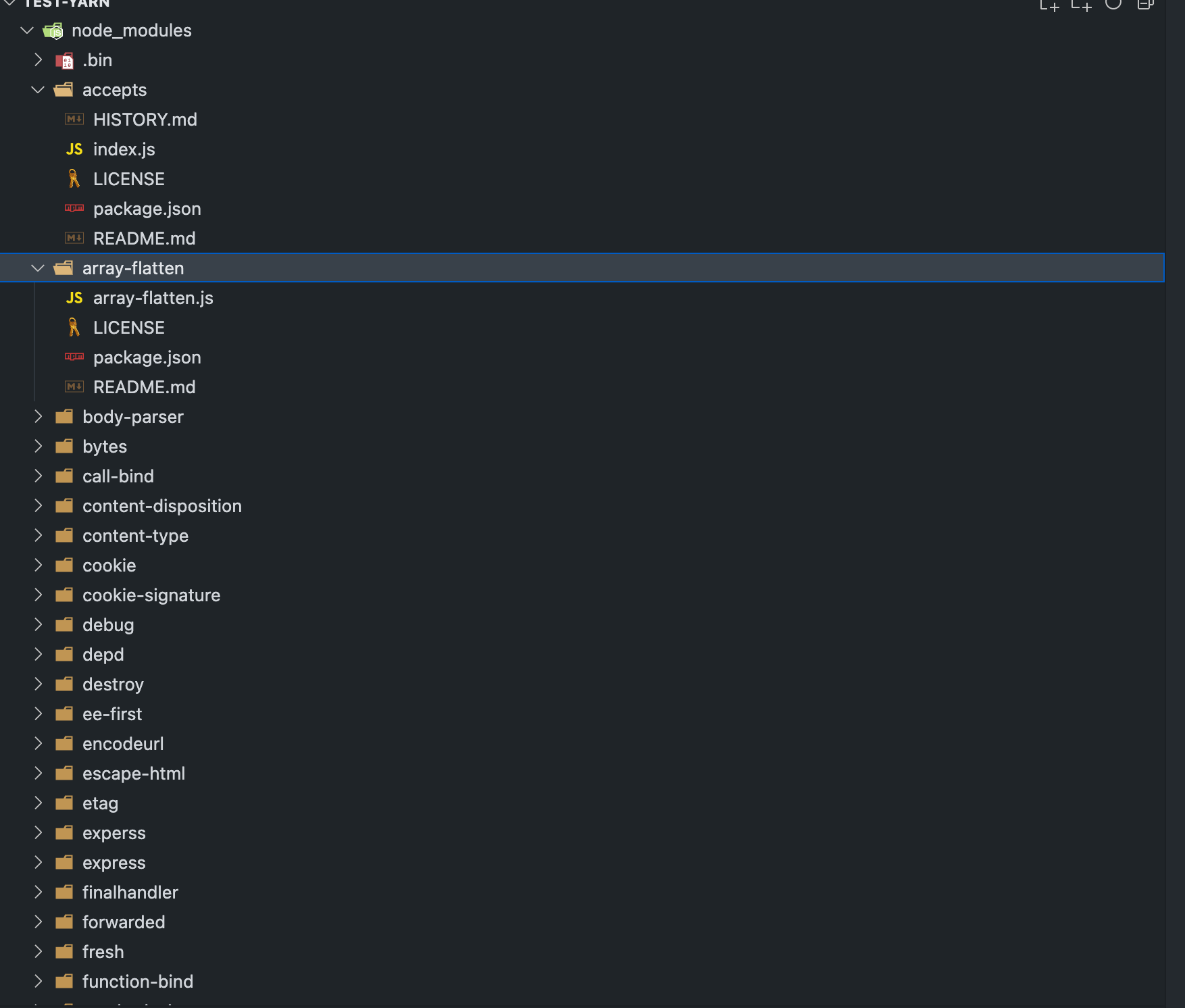
你会发现所有的依赖,没有多层的 node_modules 嵌套。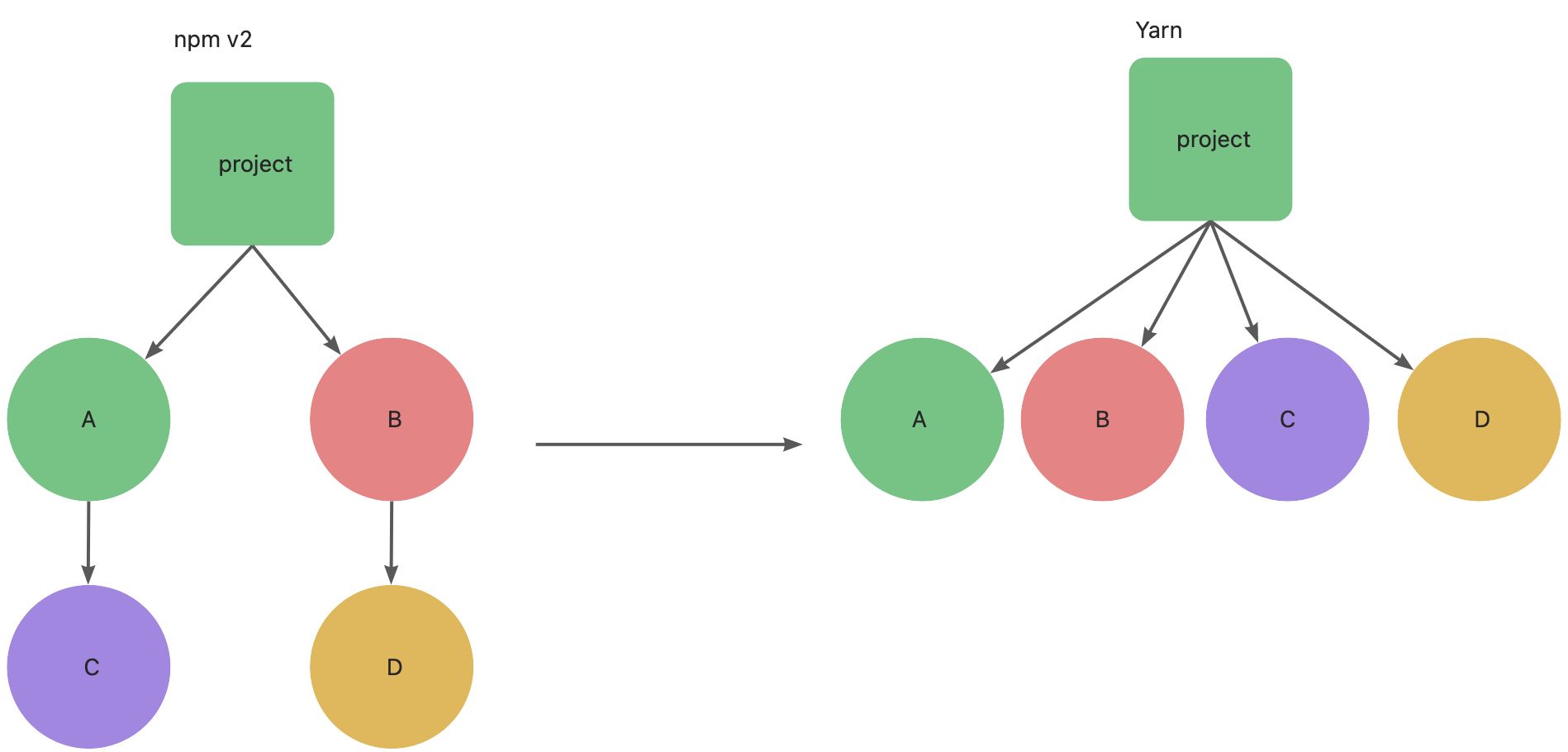
但是这里也不完全是这样,在 Yarn 控制的项目中,当一个依赖包在同一个项目中出现多个版本的时候,还是会出现多层版本 node_modules。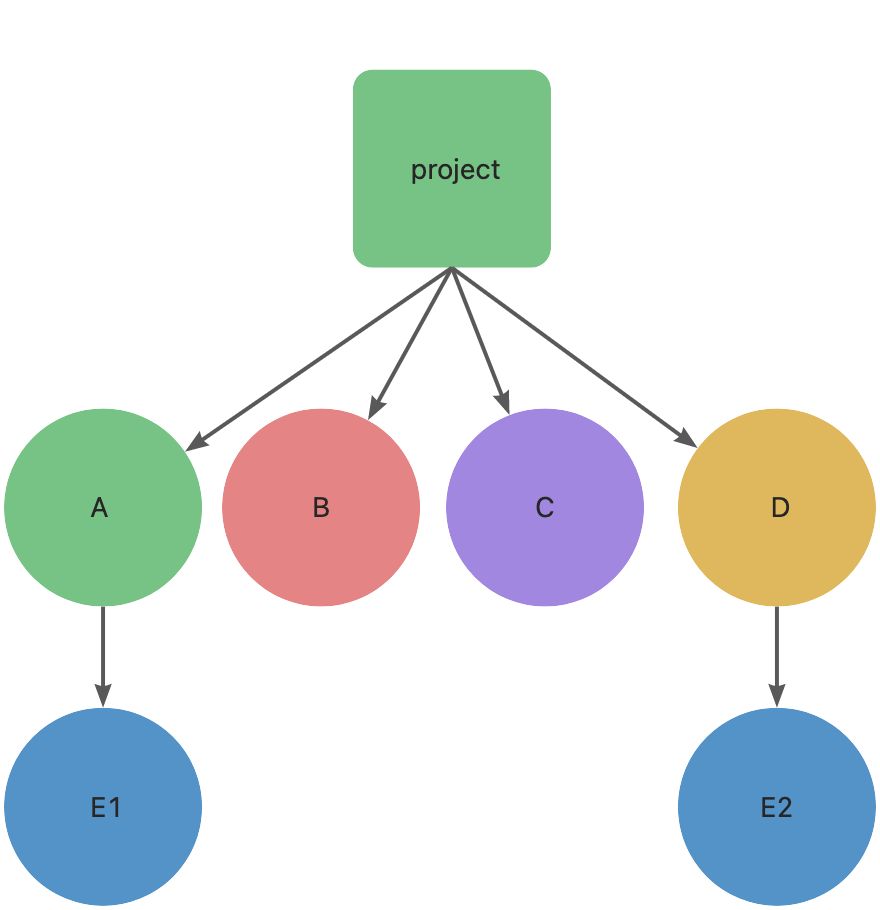
对于 Yarn 的扁平化机制,只能说是不完全的扁平化机制,并且这种扁平化机制也引入了新的问题,那就是幽灵依赖,也就是你明明没有声明在 dependencies 里的依赖,但在代码里却可以 require 进来,原因就是这种扁平化机制导致的。
在后来 npm v3 也实现了这种变化平机制,和 Yarn 非常的类似,但是不完全一样。
npm v3 和 yarn 的扁平化有什么不一样?
先举一个示例:项目中有 A、B1.0、C 和 B2.0 四个依赖。正常情况下,依赖关系如下: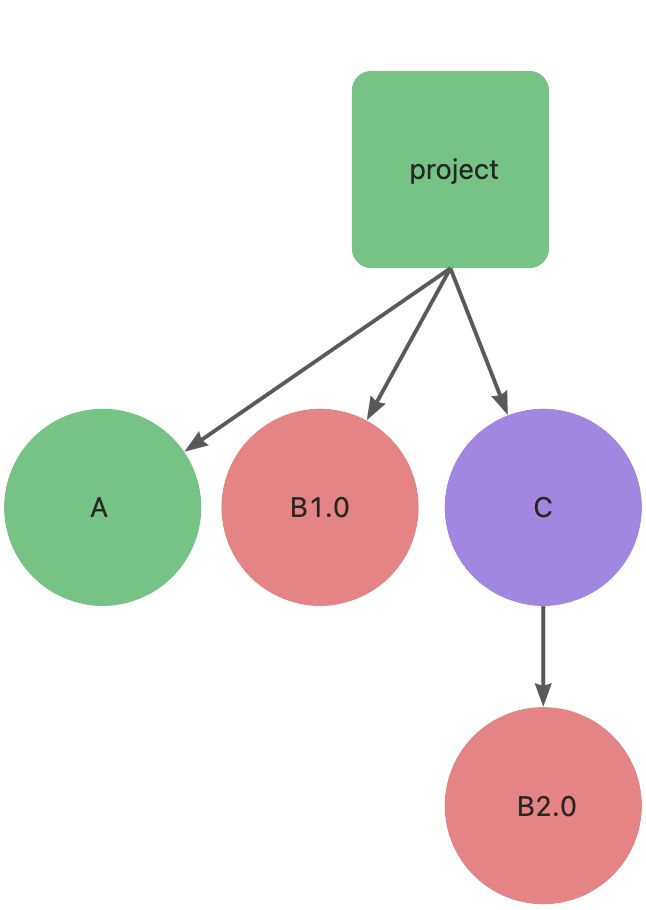
由于有同一个包的多个版本,虽然扁平化,但是还是有嵌套。接着项目中安装依赖 D,D 也依赖 B2.0,这时依赖关系如下: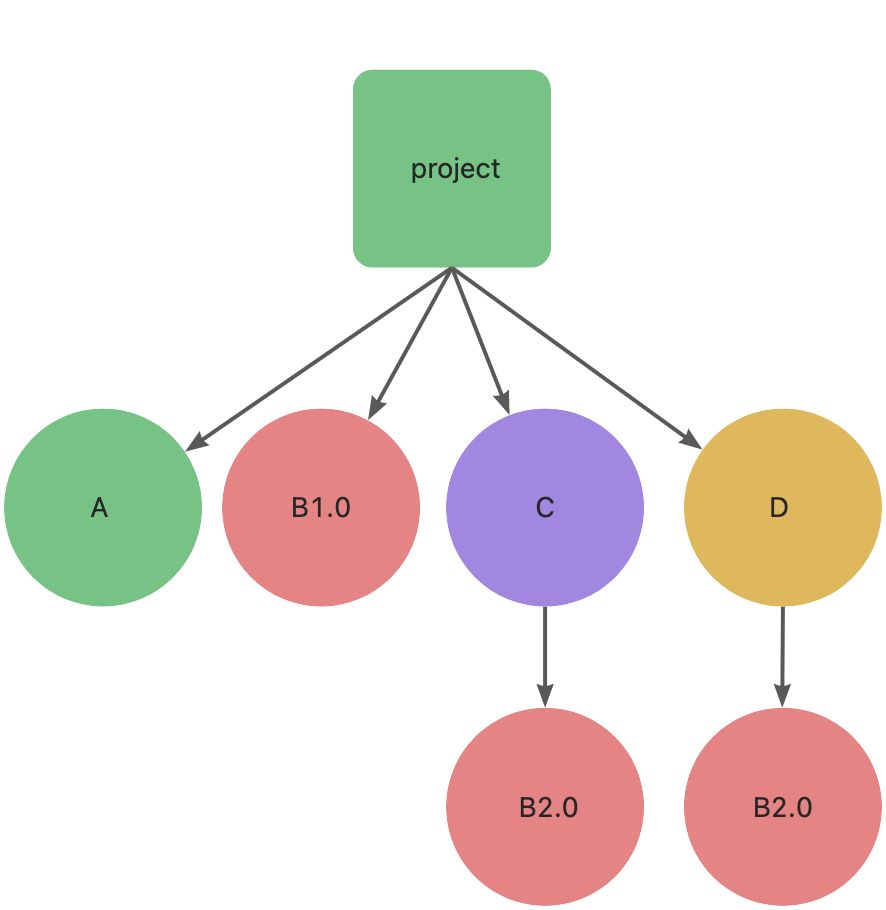
这里大家可能会奇怪,为什么不是把 B2.0 扁平化到顶层中?
其实这取决于模块 A 和 C 的安装顺序。因为 A 先安装,所以 A 的依赖 B v1.0 率先被安装在顶层 node_modules 中,接着 C 和 D 依次被安装,C 和 D 的依赖 B v2.0 就不得不安装在 C 和 D 的 node_modules 当中了。因此,模块的安装顺序可能影响 node_modules 内的文件结构。
这样一解释大家可能又奇怪了,这扁平化感觉没有什么用呀?
其实不然还是有用的,假设这时候项目又添加了一个依赖 E ,E 依赖了 B1.0 ,安装 E 之后,我们会得到这样一个结构: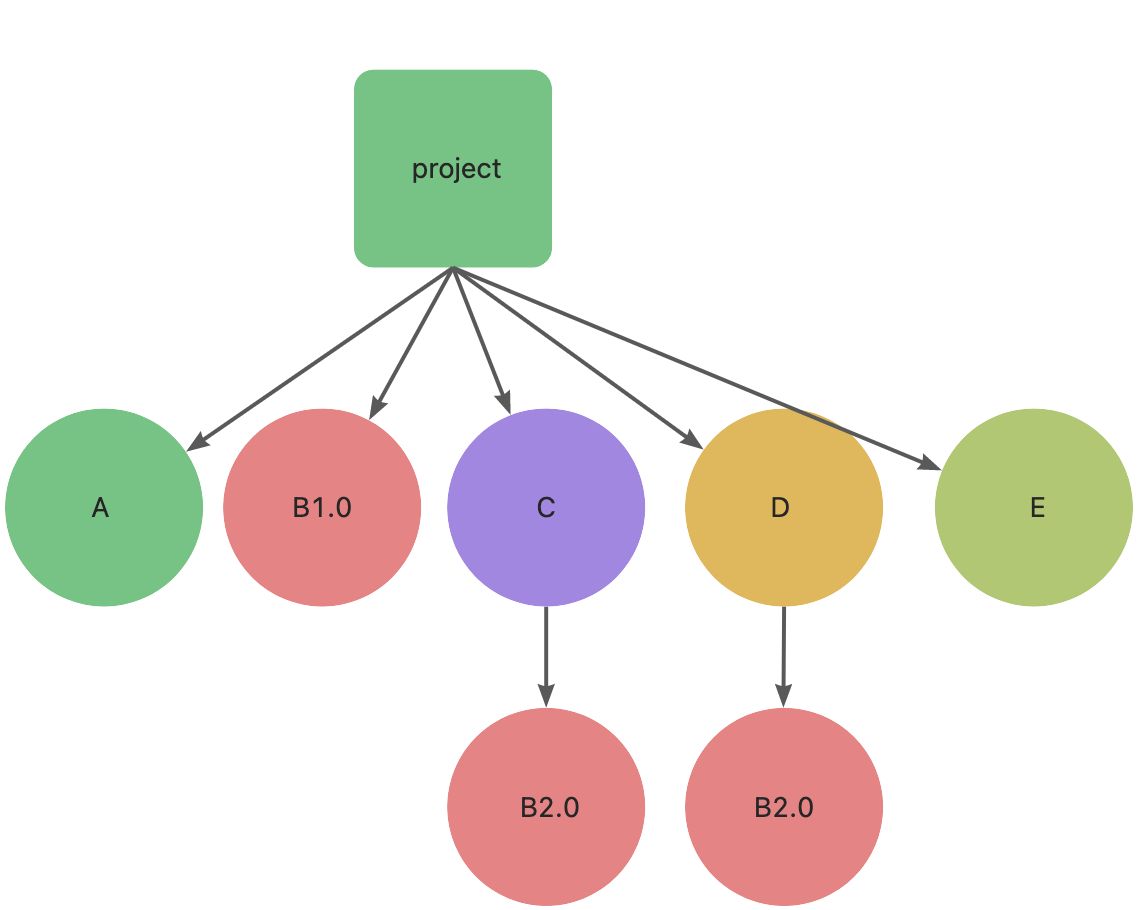
这时,B1.0 依赖包就被利用起来了,不会多次安装。
但是假设这时候项目想把 E1.0 升级到 E2.0,并且 E2.0 依赖了 B2.0 ,就是形成这样一个结构: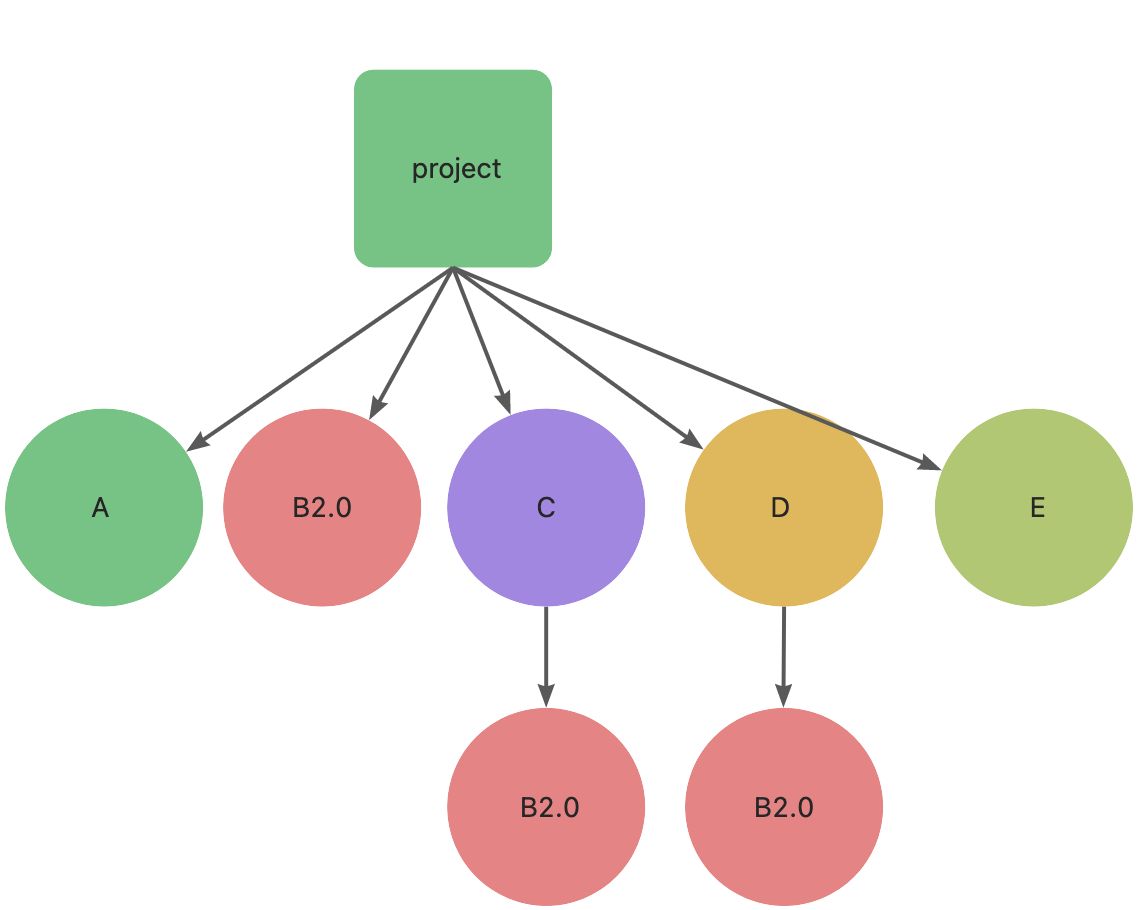
我丢,明明依赖包 B 只有一个版本了,为什么不会提升到顶层中了?原因就是 npm 包的安装顺序对于依赖树的影响很大。模块安装顺序可能影响 node_modules 内的文件数量。
对于这种问题,我相信你一定知道怎么解决。我们可以删除 node_modules,重新安装,利用 npm 的依赖分析能力,得到一个更清爽的结构。
删除在重新安装这种方式虽然很暴力,但是不够优雅,优雅的方式是使用 npm dedupe 命令。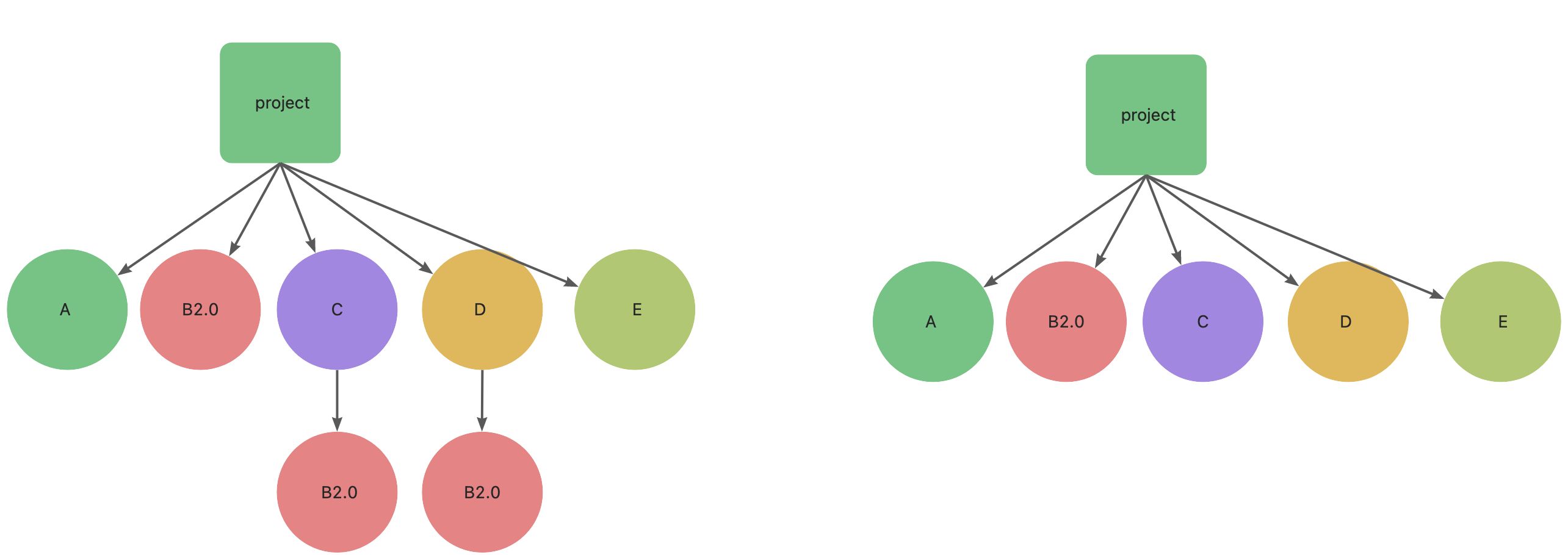
实际上,Yarn 在安装依赖时会自动执行 dedupe 命令。这也就是 npm v3 和 Yarn 的区别。
总结
Yarn 和 npm ,殊途同归,都是包管理工具,都是为了进一步解放和优化生产力。但是不管是哪种工具,你应该做的就是全面了解其思想,优劣胸中有数,这样才能驾驭它。
参考

若有收获,就点个赞吧
0 人点赞
