它跟Set(集合)一样不能有重复的元素,但是多了排序的功能,而且是自动排序,不需要维护的,也就是你添加或更新元素,底层自动就帮你排序了。所以当你需要一个有序且不重复的集合列表,那么Sorted set将是一个不错的选择。 注:
注:
- 指令中的members实际就是value,这里改为value方便理解。
- 分数值可以是整数值或双精度浮点数。
- score保存的数据也可以是double值,但基于浮点数的特征,可能会丢失精度,排序可能错误,使用是需谨慎。score储存范围:-9007199254740992 ~ 9007199254740992。
基本命令:
添加数据:
注:当多个value的score相同时,会通过value进行排序。例如 adc 和 acc 的score一样,但c在d前,因此是acc在前,adc在后。zadd key score1 value1 score2 value2 ...
获取数据:
注:[ withscores ] 为返回 score 的值。zrange key start stop [withscores] //返回指定索引范围内的数据zrevrange key start stop [withscores] //倒序返回指定索引范围内的数据
删除数据:
zrem key value1 value2
根据score获取数据:
zrangebyscore key min max [withscores] [limit offset count] //指定score的范围进行数据获取zrevrangebyscore key min max [withscores] //指定score的范围进行数据倒序获取
注:[ withscores ] 意为返回 score 的值;[ limit offset count ] 意为截取 offset(起始索引)+ count (数量)的数据, limit 3 10 就是返回 3~13
根据条件删除数据:
zremrangebyrank key start stop //删除指定索引范围内的数据zremrangebyscores key min max //删除指定排序范围内的数据
注:
mix & max 用于限定搜索查询的条件;
start & stop 用于限定查询,作用于索引,表示开始索引和结束索引;
获取集合数量:
zcard key //返回key中的数据总数zcount key min max //返回指定scores范围内的数据数
交集、并集:
zinterstore newkey numkey key1 key2 ... //将指定的key中的交集存入newkeyzunionstore newkey numkey key1 key2 ... //将指定的key中的并集存入newkey
注:
numkey 的值和 key 的值要一致,例如 要合并3个key: zunionstore newUnion 3 box1 box2 box3;
求交集时,只有所有key中都有交集才会返回数据;
如果需要整合 score 的值,可以添加 aggregate sum|min|max;
//求key1、key2的交集,且score是二者中最大值zinterstore newkey numkey key1 key2 aggregate max
拓展操作:
获取数据对应的索引:
zrank key value //获取数据的索引zrevrank key value //倒序获取数据的索引
获取数据对应的score值:
zscore key value
修改数据对应的score值:
zincrby key increment value //自增或者自减increment
实际案例:
计数器组合排序功能(排行榜):

使用score值作为投票数,通过修改score的值实现排序的变动,索引即为榜单的顺序。由于是根据score的值做榜单,因此需要倒序获取数据。
榜单数据:
zadd hotnew 100 new1 200 new2 300 new3 400 new4 500 new5 600 new6 700 new7
获取数据:
zrevrange hotnew 0 0 //获取榜单第一zrevrange hotnew 0 -1 //获取排行榜
添加点击量:
zincrby hotnew 888 new6
逾期失效功能:
处理VIP会员、限时讨论等具有时效性的信息。将过期时间设置到 score ,先根据时效性不同进行月、星期、今天、最近一小时分段存放,对一小时内将要到期的数据利用排序特性来管理,通过对比 time 来进行移除,实现会员的过期。( 底层是hash且支持排序,比string、list的过期效率要高)
设置一小时后要到期的会员:
zadd viptoday 1620152111 user:01 1620153111 user:02 1620156111 user:03
查看当前系统的时间:
time
移除到期的会员:
zremrangebyscore viptoday 0 1620155111
权重任务处理:
将权重储存到 score 中,通过倒序进行处理。如果遇到多条件,需要进行数据截断或者补全处理。
例如已知发货权重:外贸101 > 国内102 > 自用10,总裁006 > 经理007 > 员工009,现有外贸员工101009、国内经理102007、国内员工102008、自用经理10007,如何指定 ?
数据储存:由于自用的长度与其他地区不符合,又因为优先级最低,因此需要补全到三位数 :103。
zadd sendbox 101009 order:id:01 102007 order:id:02 102008 order:id:03 103007 order:id:04
发货顺序:
zrange sendbox 0 -1 withscores
通讯APP列表排序:
以 QQ为例,置顶用户为 list 类型,普通用户为 zset 类型,一旦有消息时用户会改变排序进行展示。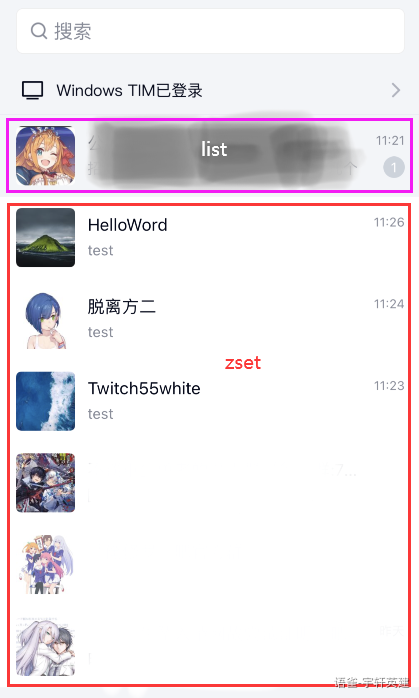
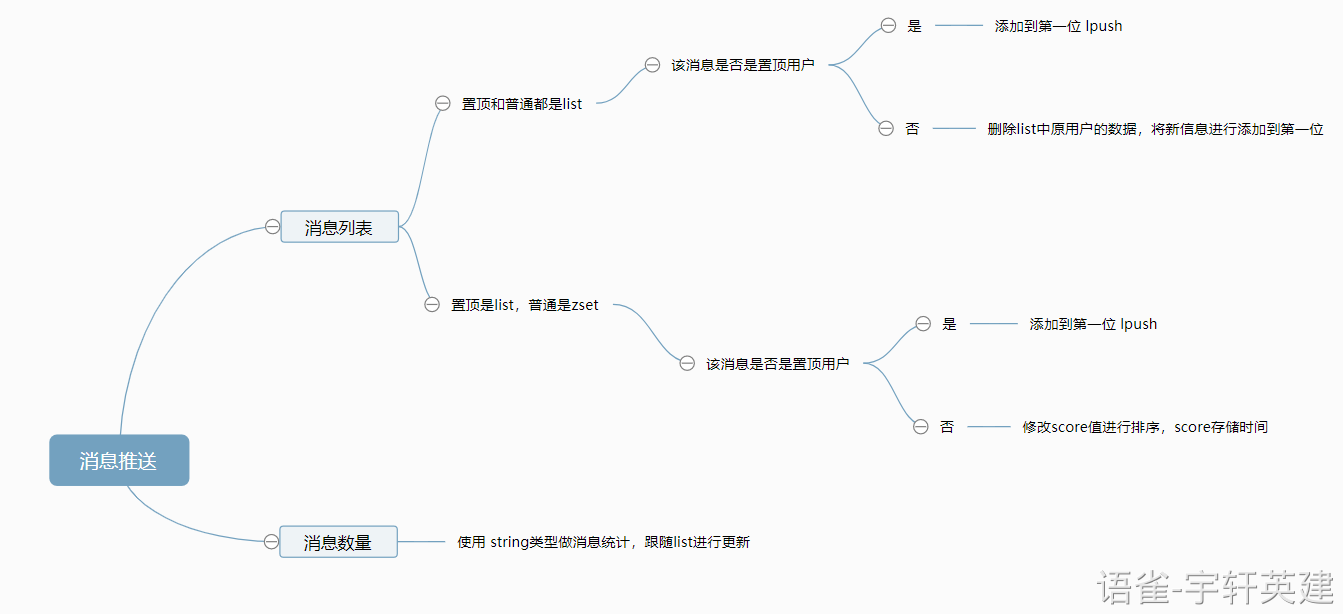
设置置顶用户:
lpush timtop dmbjz xiaoming
设置普通列表用户:
zadd timlist 100 aaa 200 bbb 300 ccc 400 ddd 500 eee
发送一个 ccc 用户的新消息:
zscore timlist ccc //获得ccczincrby timlist -300 ccc //减少300,变为首位
发送一个指定用户的新消息:
lrem timtop 1 dmbjzlpush timtop dmbjz
数据查询底层原理:
zset使用了类似二分法的方式,采用skiplist的数据结构进行处理,时间复杂度是O(logN),与红黑树一致。
跳跃表原理:
Zset
在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。也就是说,时间复杂度为O(n)。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。假如我们每相邻两个节点增加一个指针,让指针指向下下个节点,如下图:
这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半(上图中是7, 19, 26)。现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数据大的节点时,再回到原来的链表中进行查找。比如,我们想查找23,查找的路径是沿着下图中标红的指针所指向的方向进行的:

- 23首先和7比较,再和19比较,比它们都大,继续向后比较。
- 但23和26比较的时候,比26要小,因此回到下面的链表(原链表),与22比较。
- 23比22要大,沿下面的指针继续向后和26比较。23比26小,说明待查数据23在原链表中不存在,而且它的插入位置应该在22和26之间。
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。利用同样的方式,我们可以在上层新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如下图:

在这个新的三层链表结构上,如果我们还是查找23,那么沿着最上层链表首先要比较的是19,发现23比19大,接下来我们就知道只需要到19的后面去继续查找,从而一下子跳过了19前面的所有节点。可以想象,当链表足够长的时候,这种多层链表的查找方式能让我们跳过很多下层节点,大大加快查找的速度。
下图为 zset 的 skiplist创建过程: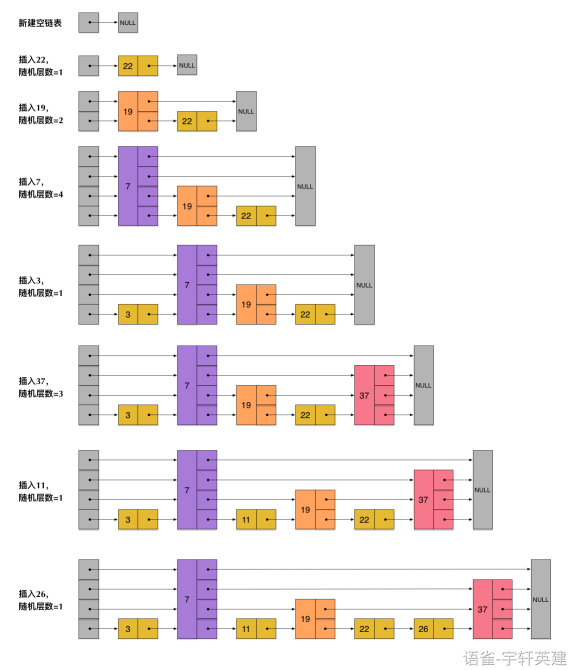
从上面skiplist的创建和插入过程可以看出,每一个节点的层数(level)是随机出来的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。

若有收获,就点个赞吧
0 人点赞
