Redisson 分布式锁
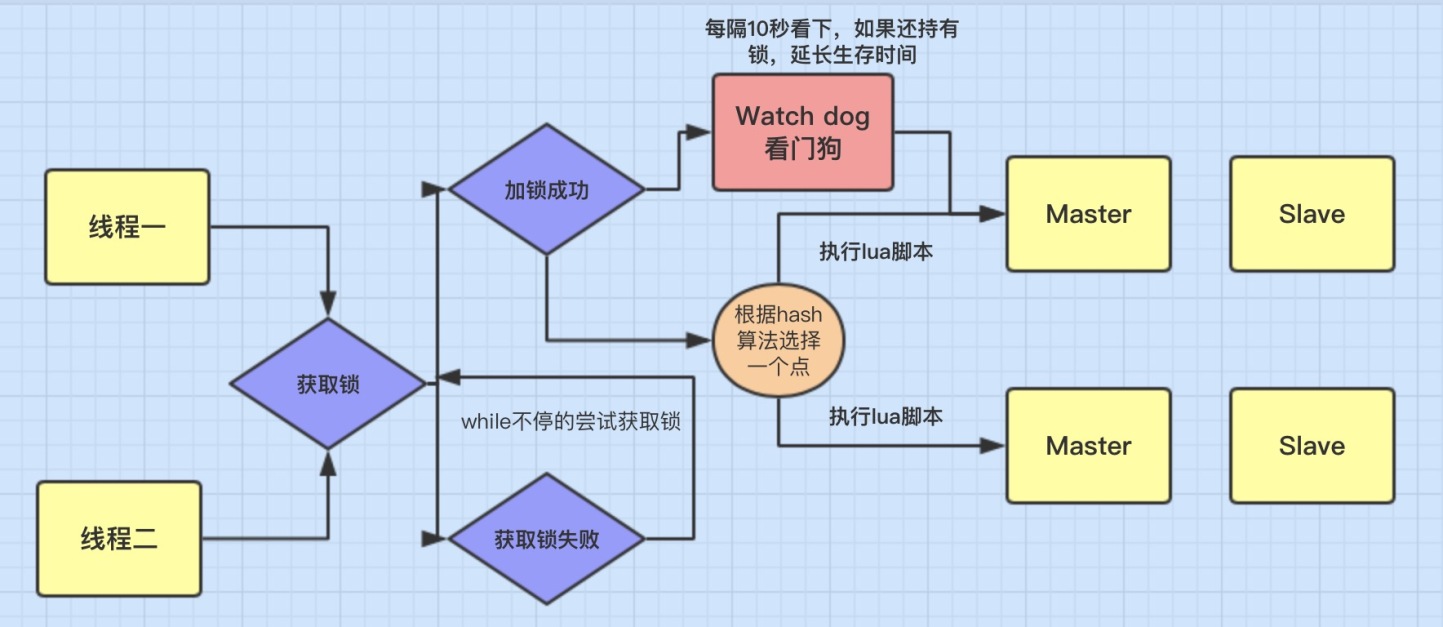
加锁机制
- 线程去获取锁,获取成功:执行 lua 脚本,保存数据到 redis 数据库。
- 线程去获取锁,获取失败:一直通过 while 循环尝试获取锁,获取成功后,执行 lua 脚本,保存数据到 redis 数据库。
watch dog 自动延期机制
这个比较难理解,找了些许资料感觉也并没有解释的很清楚。这里我自己的理解就是:
在一个分布式环境下,假如一个线程获得锁后,突然服务器宕机了,那么这个时候在一定时间后这个锁会自动释放,你也可以设置锁的有效时间(不设置默认30秒),这样的目的主要是防止死锁的发生。
但在实际开发中会有下面一种情况: ```java //设置锁1秒过去 redissonLock.lock(“redisson”, 1);
/**
- 业务逻辑需要咨询2秒 */ redissonLock.release(“redisson”);
/**
- 线程1 进来获得锁后,线程一切正常并没有宕机,但它的业务逻辑需要执行2秒,这就会有个问题,
- 在 线程1 执行1秒后,这个锁就自动过期了,
- 那么这个时候 线程2 进来了。那么就存在 线程1 和 线程2 同时在这段业务逻辑里执行代码,这是不合理的。
- 而且如果是这种情况,那么在解锁时系统会抛异常,因为解锁和加锁已经不是同一线程了,具体后面代码演示。
*/
`` 所以这个时候看门狗就出现了,它的作用就是 线程1 业务还没有执行完,时间就过了,线程1 还想持有锁的话,就会启动一个 watch dog 后台线程,不断的延长锁 key 的生存时间。<br />注意` 正常这个看门狗线程是不启动的,还有就是这个看门狗启动后对整体性能也会有一定影响,所以不建议开启看门狗。为啥要用lua脚本呢?
这个不用多说,主要是如果你的业务逻辑复杂的话,通过封装在 lua 脚本中发送给 redis,而且 redis 是单线程的,这样就保证这段复杂业务逻辑执行的原子性。可重入加锁机制
Redisson 可以实现可重入加锁机制的原因,我觉得跟两点有关:
- Redis 存储锁的数据类型是 Hash 类型
- Hash 数据类型的 key 值包含了当前线程信息。
下面是redis存储的数据:
这里表面数据类型是 Hash 类型,Hash 类型相当于我们 java 的 <key,<key1,value>> 类型,这里 key 是指 「redisson」
它的有效期还有9秒,我们再来看里们的key1值为078e44a3-5f95-4e24-b6aa-80684655a15a:45它的组成是:「guid + 当前线程的ID」。后面的 value 是就和可重入加锁有关。(GUID:Globally Unique Identifier,即全局唯一标识)
举图说明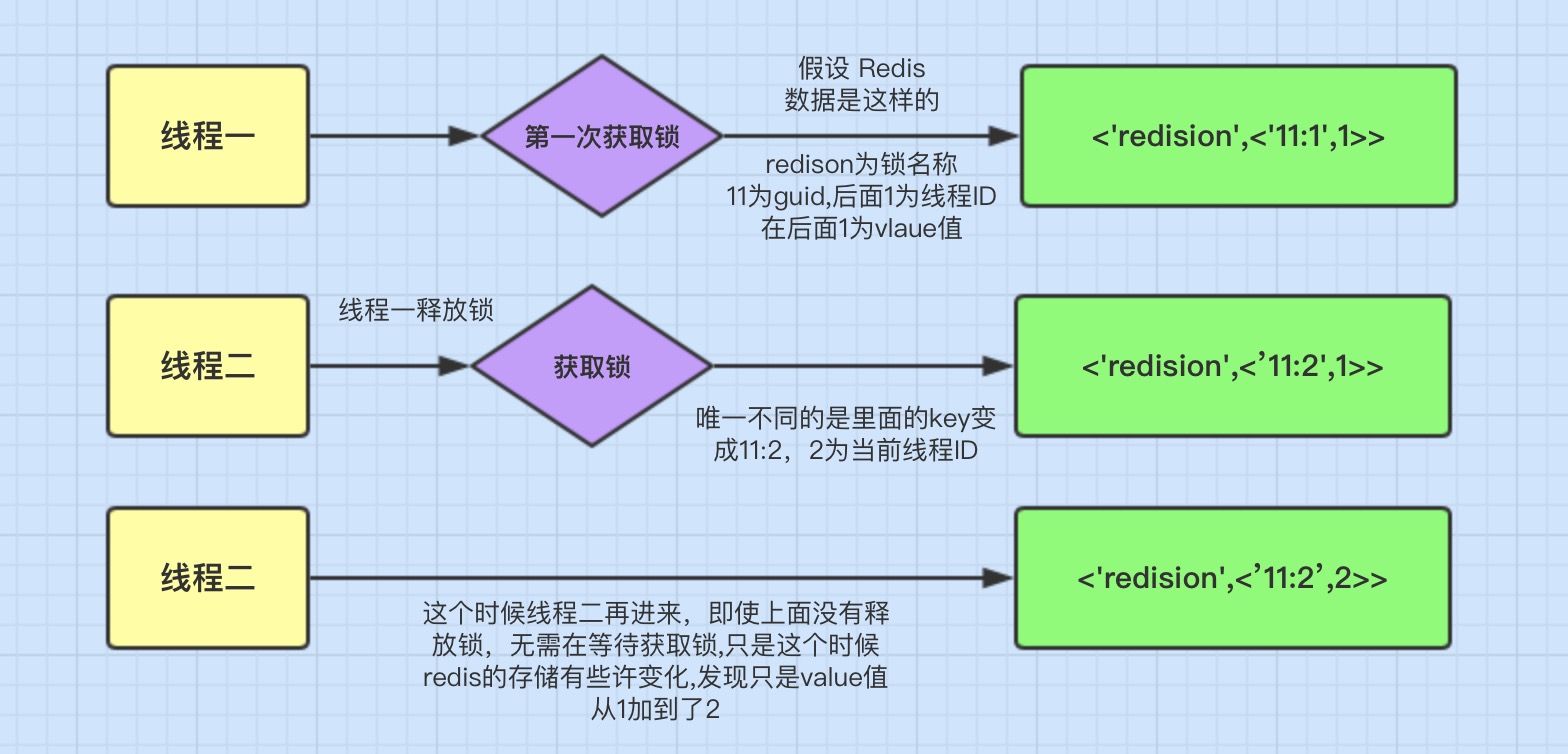
上面这图的意思就是可重入锁的机制,它最大的优点就是相同线程不需要在等待锁,而是可以直接进行相应操作。
Redis分布式锁的缺点
Redis分布式锁会有个缺陷,就是在 Redis 哨兵模式下:客户端1 对某个master节点写入了 redisson 锁,此时会异步复制给对应的 slave节点。但是这个过程中一旦发生 master节点宕机,主备切换,slave 节点从变为了 master 节点。
这时客户端2 来尝试加锁的时候,在新的 master 节点上也能加锁,此时就会导致多个客户端对同一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。缺陷在哨兵模式或者主从模式下,如果 master 实例宕机的时候,可能导致多个客户端同时完成加锁。
- 解决方式:参考 Redis 的 Redlock 算法
Zookeeper 实现分布式锁
方案一
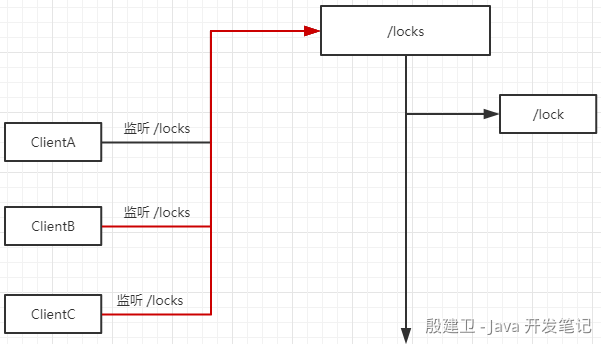
比如 ClientA、ClientB、ClientC 都在 Zookeeper 的 /locks 节点下创建子节点 /lock,按照 Zookeeper 本身的节点特性,在同一级节点里面,节点的名称必须是唯一的,所以只会有一个客户端成功创建 /lock 节点,其他客户端都失败,失败之后其他客户端都会监听 /locks 节点的变化,如果 /locks 的子节点发生变化了,会触发 Watcher 通知,这样其他客户端就会收到事件,再一次争抢锁。
这种实现方案存在一个问题,叫惊群效应,比如存在很多客户端都在监听 /locks 节点的子节点变化,一旦某个获得了锁的客户端释放了锁,会触发大量是 Watcher 事件,去通知其他客户端来争抢锁,而最终只会有一个客户端获得锁,当我们的客户端比较多的情况下,不建议使用这种方案。方案二
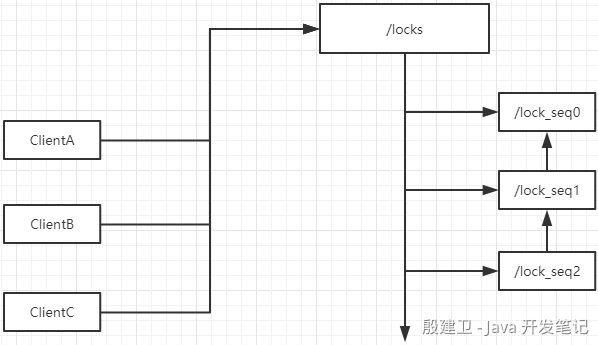
ClientA、ClientB、ClientC 都在 Zookeeper 的 /locks 节点下创建一个有序子节点,而获得锁的操作是在所有节点中获取一个序号最小的节点,表示该节点对应的客户端获得了锁,其他节点会进入等待状态,并且其他的节点会向上监听,也就是说,/lock_seq2 节点会监听 /lock_seq1 节点,/lock_seq1 节点会监听 /lock_seq0 节点,当 /lock_seq0 节点释放了锁,/lock_seq1 节点会收到事件,会再次判断 /lock_seq1 节点是不是所有节点中序号最小的节点,如果是的话就表示获得锁。
1)接收到请求后,在/locks节点下创建一个临时顺序节点。 2)判断自己是不是当前节点下最小的节点:是,获取锁,不是,对前一个节点进行监听。 3)获取到锁,处理完业务后,delete节点释放锁,然后下面的节点将收到通知,重复第二步判断。
参考文档

若有收获,就点个赞吧
0 人点赞
