一、缓存雪崩
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
由于原有缓存失效,新缓存未到期间所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。
解决方案
1. 方法一
常见方式就是给过期时间加个随机时间。
注意这个随机时间不是几秒哈,可以长达几分钟。因为如果数据量很大,按照上述例子,加上 Redis 是单线程处理数据的。那么几秒的缓冲不一定能够保证新数据都被加载完成。
所以过期时间宁愿设置长一点,也好过短一点。反正最后都是会过期掉,最终效果是一样的。而且过期时间范围加大,key 会更加分散,这样也是一定程度缩短 Redis 在过期 key 时候的阻塞时间。
2. 方法二
加互斥锁,但这个方案会导致吞吐量明显下降。所以还是要看实际业务,像上述例子就不合适用。
3. 方法三
热点数据不设置过期。不过期的话,正常业务请求自然就不会打到数据库了。
二、缓存击穿
缓存击穿是指一个热点 key 过期或被删除后,导致线上原本能命中该热点 key 的请求,瞬间大量地打到数据库上,最终导致数据库被击垮。
1. 方法一
2. 方法二
加互斥锁:互斥锁可以控制查询数据库的线程访问,但这种方案会导致系统的吞吐量下降,需要根据实际情况使用。
三、缓存穿透
缓存穿透是指查询一个一定不存在的数据,这样就导致用户查询的时候,在缓存中找不到对应key的value,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击应用,这就是漏洞。
解决方案
1.方法一
验证拦截:做好参数校验,接口层进行校验,如鉴定用户权限,对ID之类的字段做基础的校验,如id<=0的字段直接拦截;
2. 方法二
缓存空值。如果一个查询返回的数据为空(不管是数据不存在,还是系统故障)仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过5分钟。通过这个设置的默认值存放到缓存,这样第二次到缓存中获取就有值了,而不会继续访问数据库。
3. 方法三
采用布隆过滤器BloomFilter
优势:占用内存空间很小,位存储;性能特别高,使用key的hash判断key存不存在。
将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
布隆过滤器是一种比较特殊的数据结构,有点类似与HashMap,在业务中可能会通过使用HashMap来判断一个值是否存在,它可以在O(1)时间复杂度内返回结果,效率极高,但是受限于存储容量,如果可能需要去判断的值超过亿级别,那么HashMap所占的内存就很可观了。
而BloomFilter解决这个问题的方案很简单。首先用多个bit位去代替HashMap中的数组,这样的话储存空间就下来了,之后就是对 Key 进行多次哈希,将 Key 哈希后的值所对应的 bit 位置为1。
当判断一个元素是否存在时,就去判断这个值哈希出来的比特位是否都为1,如果都为1,那么可能存在,也可能不存在(如下图F)。但是如果有一个bit位不为1,那么这个Key就肯定不存在。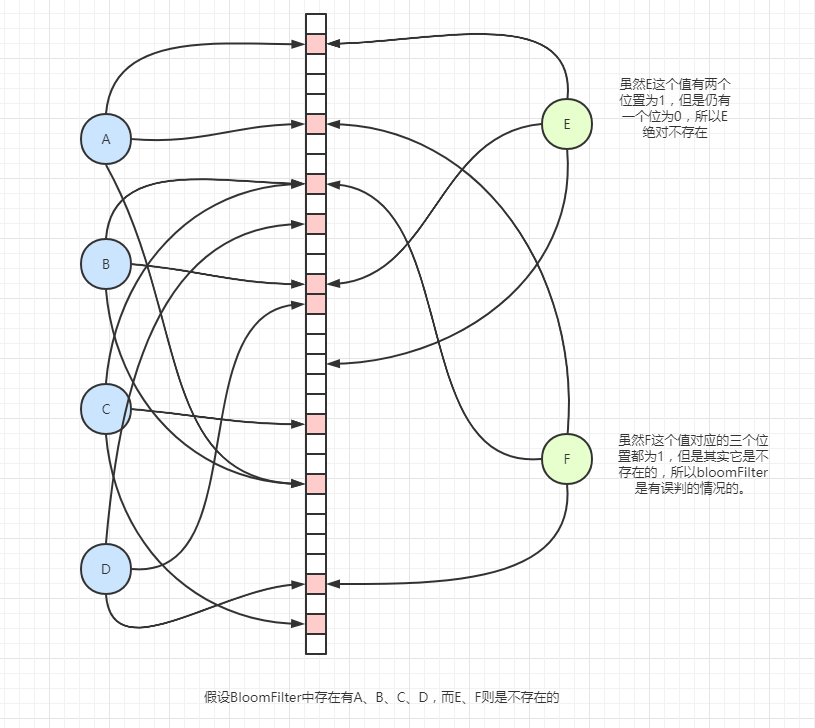
注意:BloomFilter并不支持删除操作,只支持添加操作。这一点很容易理解,因为如果要删除数据,就得将对应的bit位置为0,但是这个Key对应的bit位可能其他的Key也对应着。

若有收获,就点个赞吧
0 人点赞
