什么是循环依赖
Spring 的循环依赖就是多个 Bean 互相引用对方,形成引用链上的闭环。
循环依赖发生在createBeanInstance和populateBean方法中,createBeanInstance是实例化(属性尚未填充)阶段,这一阶段会调用 Bean 的构造函数实例化 Bean;populateBean即填充属性期间,这一步主要是对 Bean 的依赖属性进行填充。
什么情况下循环依赖可以被处理
Spring 循环依赖表现为多个 Bean 互相引用对方,那 Spring 里类与类之前相互引用可以通过什么方式实现的?出现循环依赖的Bean必须要是单例(singleton),主要是通过构造器注入、属性注入、setter注入。
Spring解决循环依赖是有前置条件的:
- 出现循环依赖的 Bean 必须要是单例(singleton),如果依赖 prototype 作用域的 Bean,Spring容器不进行缓存,因此无法提前暴露一个创建中的 Bean。
- Spring 只能解决field属性注入、setter注入的循环依赖问题,通过构造器注入造成的循环依赖依然不能解决。
如果使用构造器注入,在 Spring 项目启动的时候,就会抛出:BeanCurrentlyInCreationException:Requested bean is currently in creation: Is there an unresolvable circular reference?从而提醒你避免循环依赖,如果是属性注入的话,启动的时候不会报错,在使用那个 Bean 的时候才会报错。
Spring如何解决循环依赖环依赖
Spring解决循环依赖引入的三级缓存
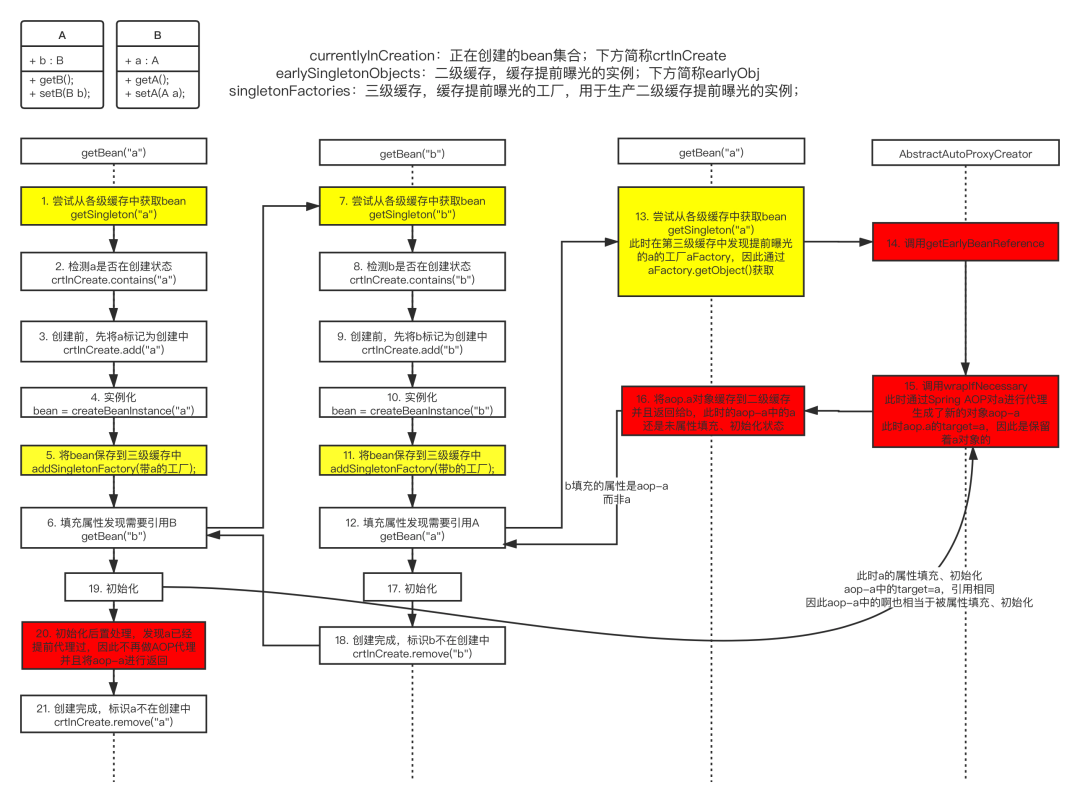
Spring 针对属性注入的循环依赖,设计了三级缓存(map)来解决,三级缓存对应的源码中的类是:DefaultSingletonBeanRegistry,三级缓存对应的 map 如下:
/** Cache of singleton objects: bean name to bean instance. */// 一级缓存private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);/** Cache of singleton factories: bean name to ObjectFactory. */// 二级缓存private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);/** Cache of early singleton objects: bean name to bean instance. */// 三级缓存private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
说明:
singletonObjects:一级缓存,用于存放完全初始化好的 Bean,从一级缓存找那个取出的 Bean 可以直接使用,存储的映射关系是:Bean 名称 -> 可以直接使用的单例 Bean;earlySingletonObjects:二级缓存,存放提前曝光的单例对象,即仅完成了实例化还没有进行属性填充的bean,存储的映射关系是:Bean 名称 -> 未进行属性填充的Bean;singletonFactories:三级缓存,提前暴露的一个单例工厂,存储的映射关系是:Bean 名称 -> ObjectFactory 实现类。
此外,还有两个Set集合,也是辅助三级缓存帮助解决循环依赖的,如下:
/** Names of beans that are currently in creation. */// 表示bean创建过程中,还未被完全初始化时都会在这个集合中待着,它在Bean开始创建时放值,创建完成时会将其移出private final Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(new ConcurrentHashMap<>(16));/** Names of beans that have already been created at least once. */// 当这个Bean被创建完成后会被放在这个集合中private final Set<String> alreadyCreated = Collections.newSetFromMap(new ConcurrentHashMap<>(256));
源码解析
相关代码在DefaultSingletonBeanRegistry类的getSingleton方法,关键步骤已写注释,如下:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {// 先尝试从一级缓存中获取beanObject singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {// 如果从一级缓存中获取bean失败,再尝试从二级缓存中获取singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null && allowEarlyReference) {/** 这里加synchronized同步机制是为了保证仅执行一次从三级缓存获取bean放到二级缓存,并从三级缓存中移除对应的bean的操作。* 其实现和单例模式中为什么要加synchronized同步机制并做两次判断是一个道理* */synchronized (this.singletonObjects) {// Consistent creation of early reference within full singleton locksingletonObject = this.singletonObjects.get(beanName);if (singletonObject == null) {singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null) {// 获取三级缓存的bean工厂,注意三级缓存存储的映射关系是:beanName -> bean工厂ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {// 从三级缓存中获取beansingletonObject = singletonFactory.getObject();// 将从三级缓存中获取的bean放置到二级缓存中,即添加二级缓存中维护的映射关系this.earlySingletonObjects.put(beanName, singletonObject);// 将对应的beanName从三级缓存的bean工厂移除this.singletonFactories.remove(beanName);}}}}}}return singletonObject;}public boolean isSingletonCurrentlyInCreation(String beanName) {// 实质是判断beanName在singletonsCurrentlyInCreation这个set集合中是否还存在return this.singletonsCurrentlyInCreation.contains(beanName);}
先说明一下getSingleton方法中两个判断条件:
isSingletonCurrentlyInCreation():判断当前单例 Bean 是否正在创建中,即通过 beanName 在Set集合singletonsCurrentlyInCreation中查找 beanName 是否存在。比如A的构造器依赖了B对象所以要先去创建B对象,此时A的 Bean 就是在创建中; 或者在A的populateBean(属性注入)过程中依赖了B对象,得先去创建B对象,此时A的 Bean 就是在创建中。allowEarlyReference:是否允许从singletonFactories中通过getObject方法拿到对象。
这里注意在从三级缓存中获取bean时,有一个同步机制synchronized代码块和重复判断一级缓存和二级缓存中是否存在bean的过程,这是为了保证多个线程同时获取同一个beanName的bean时,三级缓存中的操作仅执行一次,参考单例模式中为什么要加锁和双重检查。
面试
- Spring 通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象(earlySingletonObjects),三级缓存为早期曝光对象工厂(singletonFactories)。
- 当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,添加到三级缓存中。(如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象)
- 当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用 getBean(A) 来获取需要的依赖,此时的 getBean(A) 会从缓存中获取:
- 先获取到三级缓存中的工厂;
- 调用对象工工厂的 getObject() 方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。
- 当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束。
问题1:Spring为什么仅能解决属性注入的循环依赖,不能解决构造函数的循环依赖问题?
答:属性注入的循环依赖解决方案的关键是从三级缓存singletonFactories中获取提前暴露 Bean,而将 Bean 存入三级缓存的前提是执行了构造函数(源码中是先执行构造函数,再将“不完整的bean”放入三级缓存),因此构造器的循环依赖没法解决,Spring 是直接抛异常的。
问题2:为什么需要三级缓存,只要一级、二级缓存不可以吗?
想一个问题:如果A的原始对象注入给B的属性之后,A的原始对象进行了AOP产生了一个代理对象,此时就会出现,对于A而言,它的Bean对象其实应该是AOP之后的代理对象,而B的A属性对应的并不是AOP之后的代理对象,这就产生了冲突。
B依赖的A和最终的A不是同一个对象。
这个问题可以说没有办法解决。因为在一个 Bean 的生命周期最后,Spring 提供了BeanPostProcessor接口可以去对 Bean 进行加工,这个加工不仅仅只是能修改 Bean 的属性值,也可以替换掉当前 Bean。
举个例子:
@Componentpublic class User {}
@Componentpublic class LubanBeanPostProcessor implements BeanPostProcessor {@Overridepublic Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {// 注意这里,生成了一个新的User对象if (beanName.equals("user")) {System.out.println(bean);User user = new User();return user;}return bean;}}
@Configuration@ComponentScans(value = {@ComponentScan("com.mws.demo.循环依赖")})public class AppConfig {}
public class Test {public static void main(String[] args) {AnnotationConfigApplicationContext context =new AnnotationConfigApplicationContext(AppConfig.class);User user = context.getBean("user", User.class);System.out.println(user);}}
com.luban.service.User@5e025e70com.luban.service.User@1b0375b3
所以在BeanPostProcessor中可以完全替换掉某个 beanName 对应的 Bean 对象。
而BeanPostProcessor的执行在 Bean 的生命周期中是处于属性注入之后的,循环依赖是发生在属性注入过程中的,所以很有可能导致,注入给B对象的A对象和经历过完整生命周期之后的A对象,不是一个对象。
所以在这种情况下的循环依赖,如果没有三级缓存,Spring是解决不了的,因为在属性注入时,Spring也不知道A对象后续会经过哪些BeanPostProcessor以及会对A对象做什么处理。
虽然上面的情况可能发生,但是肯定发生得很少,我们通常在开发过程中,不会这样去做,但是,某个 beanName 对应的最终对象和原始对象不是一个对象却会经常出现,这就是AOP。
AOP就是通过一个BeanPostProcessor来实现的,这个BeanPostProcessor就是**AnnotationAwareAspectJAutoProxyCreator**,它的父类是AbstractAutoProxyCreator,而在 Spring 中AOP利用的要么是 JDK 动态代理,要么 CGLib 的动态代理,所以如果给一个类中的某个方法设置了切面,那么这个类最终就需要生成一个代理对象。
一般过程就是:A类—->生成一个普通对象—>属性注入—>基于切面生成一个代理对象—>把代理对象放入singletonObjects单例池中。
而AOP可以说是 Spring 中除开IOC的另外一大功能,而循环依赖又是属于IOC范畴的,所以这两大功能想要并存,Spring需要特殊处理。
如何处理的,就是利用了第三级缓存singletonFactories。
首先,singletonFactories中存的是某个 beanName 对应的 ObjectFactory,在 Bean 的生命周期中,生成完原始对象之后,就会构造一个 ObjectFactory 存入singletonFactories中。这个 ObjectFactory 是一个函数式接口,所以支持 Lambda 表达式:() -> getEarlyBeanReference(beanName, mbd, bean)
上面的 Lambda 表达式就是一个 ObjectFactory,执行该 Lambda 表达式就会去执行getEarlyBeanReference方法,而该方法如下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {Object exposedObject = bean;if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {for (SmartInstantiationAwareBeanPostProcessor bp : getBeanPostProcessorCache().smartInstantiationAware) {exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);}}return exposedObject;}
该方法会去执行SmartInstantiationAwareBeanPostProcessor中的getEarlyBeanReference方法,而这个接口下的实现类中只有两个类实现了这个方法,一个是AbstractAutoProxyCreator,一个是InstantiationAwareBeanPostProcessorAdapter,它的实现如下:
// InstantiationAwareBeanPostProcessorAdapter@Overridepublic Object getEarlyBeanReference(Object bean, String beanName) throws BeansException {return bean;}
// AbstractAutoProxyCreator@Overridepublic Object getEarlyBeanReference(Object bean, String beanName) {Object cacheKey = getCacheKey(bean.getClass(), beanName);this.earlyProxyReferences.put(cacheKey, bean);return wrapIfNecessary(bean, beanName, cacheKey);}
所以很明显,在整个 Spring 中,默认就只有AbstractAutoProxyCreator真正意义上实现了getEarlyBeanReference方法,而该类就是用来进行AOP的。上文提到的AnnotationAwareAspectJAutoProxyCreator的父类就是AbstractAutoProxyCreator。
那么getEarlyBeanReference方法到底在干什么?
- 首先得到一个 cachekey,cachekey 就是 beanName。
然后把 beanName 和 Bean(这是原始对象)存入
earlyProxyReferences中。private final Map<Object, Object> earlyProxyReferences = new ConcurrentHashMap<>(16);
调用
wrapIfNecessary进行AOP,得到一个代理对象。/** 如有必要,包装给定的bean,即如果它有资格被代理* Wrap the given bean if necessary, i.e. if it is eligible for being proxied.* @param bean the raw bean instance* @param beanName the name of the bean* @param cacheKey the cache key for metadata access* @return a proxy wrapping the bean, or the raw bean instance as-is*/protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {return bean;}if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {return bean;}if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {this.advisedBeans.put(cacheKey, Boolean.FALSE);return bean;}// Create proxy if we have advice.Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);if (specificInterceptors != DO_NOT_PROXY) {this.advisedBeans.put(cacheKey, Boolean.TRUE);Object proxy = createProxy(bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));this.proxyTypes.put(cacheKey, proxy.getClass());return proxy;}this.advisedBeans.put(cacheKey, Boolean.FALSE);return bean;}
那么,什么时候会调用getEarlyBeanReference方法呢?回到循环依赖的场景中。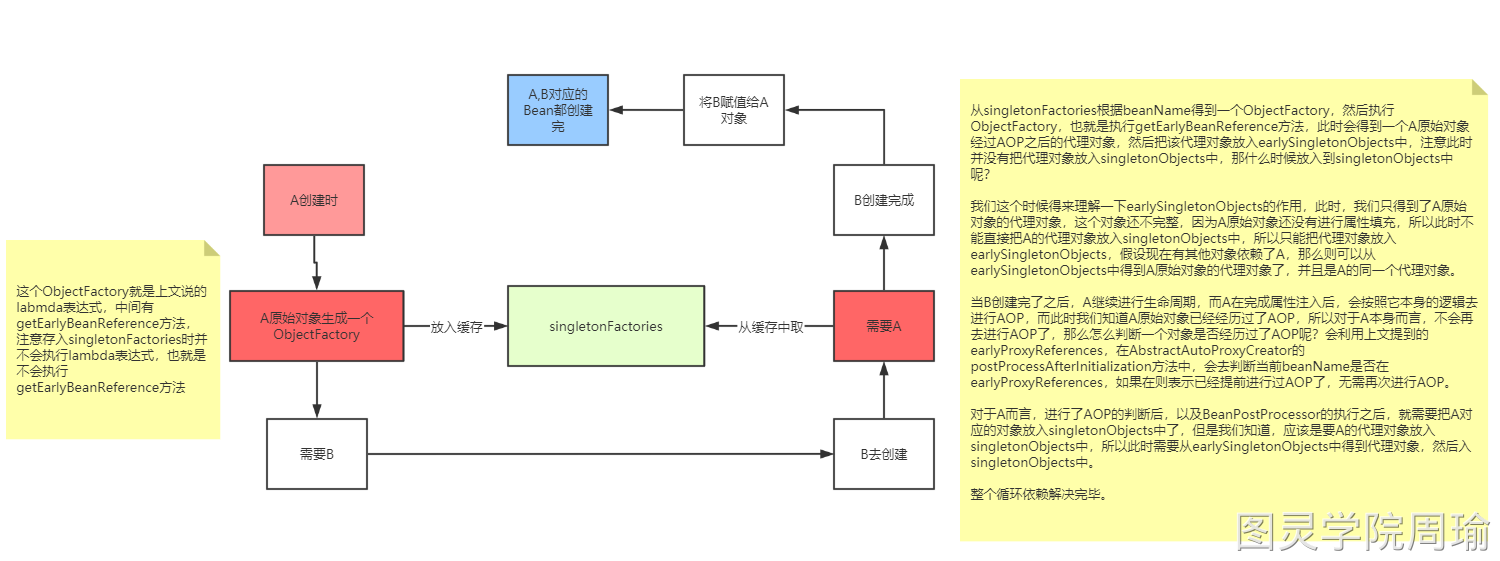
左边文字:
这个 ObjectFactory 就是上文说的 Lambda 表达式,中间有getEarlyBeanReference方法,注意存入singletonFactories时并不会执行 Lambda 表达式,也就是不会执行getEarlyBeanReference方法。
右边文字:
从singletonFactories根据 beanName 得到一个 ObjectFactory,然后执行 ObjectFactory,也就是执行getEarlyBeanReference方法,此时会得到一个A原始对象经过AOP之后的代理对象,然后把该代理对象放入earlySingletonObjects中,注意此时并没有把代理对象放入singletonObjects中,那什么时候放入到singletonObjects中呢?
我们这个时候得来理解一下earlySingletonObjects的作用,此时,我们只得到了A原始对象的代理对象,这个对象还不完整,因为A原始对象还没有进行属性填充,所以此时不能直接把A的代理对象放入singletonObjects中,所以只能把代理对象放入earlySingletonObjects,假设现在有其他对象依赖了A,那么则可以从earlySingletonObjects中得到A原始对象的代理对象了,并且是A的同一个代理对象。
当B创建完了之后,A继续进行生命周期,而A在完成属性注入后,会按照它本身的逻辑去进行AOP,而此时我们知道A原始对象已经经历过了AOP,所以对于A本身而言,不会再去进行AOP了,那么怎么判断一个对象是否经历过了AOP呢?会利用上文提到的earlyProxyReferences,在AbstractAutoProxyCreator的postProcessAfterInitialization方法中,会去判断当前 beanName 是否在earlyProxyReferences,如果在则表示已经提前进行过AOP了,无需再次进行AOP。
/*如果子类将bean标识为代理bean,则使用配置的拦截器创建代理。Create a proxy with the configured interceptors if the bean is identified as one to proxy by the subclass.**/@Overridepublic Object postProcessAfterInitialization(@Nullable Object bean, String beanName) {if (bean != null) {Object cacheKey = getCacheKey(bean.getClass(), beanName);if (this.earlyProxyReferences.remove(cacheKey) != bean) {return wrapIfNecessary(bean, beanName, cacheKey);}}return bean;}/**如果有必要,例如,如果有资格被代理,就包装给定的bean。* Wrap the given bean if necessary, i.e. if it is eligible for being proxied.* @param bean the raw bean instance* @param beanName the name of the bean* @param cacheKey the cache key for metadata access* @return a proxy wrapping the bean, or the raw bean instance as-is*/protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) {return bean;}if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) {return bean;}if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {this.advisedBeans.put(cacheKey, Boolean.FALSE);return bean;}// Create proxy if we have advice.//返回给定的bean是否要被代理,以及其他什么建议(例如AOP联盟拦截器)和顾问应用。Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);if (specificInterceptors != DO_NOT_PROXY) {this.advisedBeans.put(cacheKey, Boolean.TRUE);Object proxy = createProxy(bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));this.proxyTypes.put(cacheKey, proxy.getClass());return proxy;}this.advisedBeans.put(cacheKey, Boolean.FALSE);return bean;}
对于A而言,进行了AOP的判断后,以及BeanPostProcessor的执行之后,就需要把A对应的对象放入singletonObjects中了,但是我们知道,应该是要A的代理对象放入singletonObjects中,所以此时需要从earlySingletonObjects中得到代理对象,然后入singletonObjects中。
整个循环依赖解决完毕。
总结
至此,总结一下三级缓存:
- singletonObjects:缓存某个beanName对应的经过了完整生命周期的 Bean。
- earlySingletonObjects:缓存提前拿原始对象进行了AOP之后得到的代理对象,原始对象还没有进行属性注入和后续的BeanPostProcessor等生命周期。
- singletonFactories:缓存的是一个ObjectFactory,主要用来去生成原始对象进行了AOP之后得到的代理对象,在每个Bean的生成过程中,都会提前暴露一个工厂,这个工厂可能用到,也可能用不到,如果没有出现循环依赖依赖本Bean,那么这个工厂无用,本Bean按照自己的生命周期执行,执行完后直接把本Bean放入singletonObjects中即可,如果出现了循环依赖依赖了本Bean,则另外那个Bean执行ObjectFactory提交得到一个AOP之后的代理对象(如果有AOP的话,如果无需AOP,则直接得到一个原始对象)。
- 其实还要一个缓存,就是earlyProxyReferences,它用来记录某个原始对象是否进行过AOP了。
参考文档

若有收获,就点个赞吧
0 人点赞
