Kafka 2.8.0之后也可以配置不采用ZK
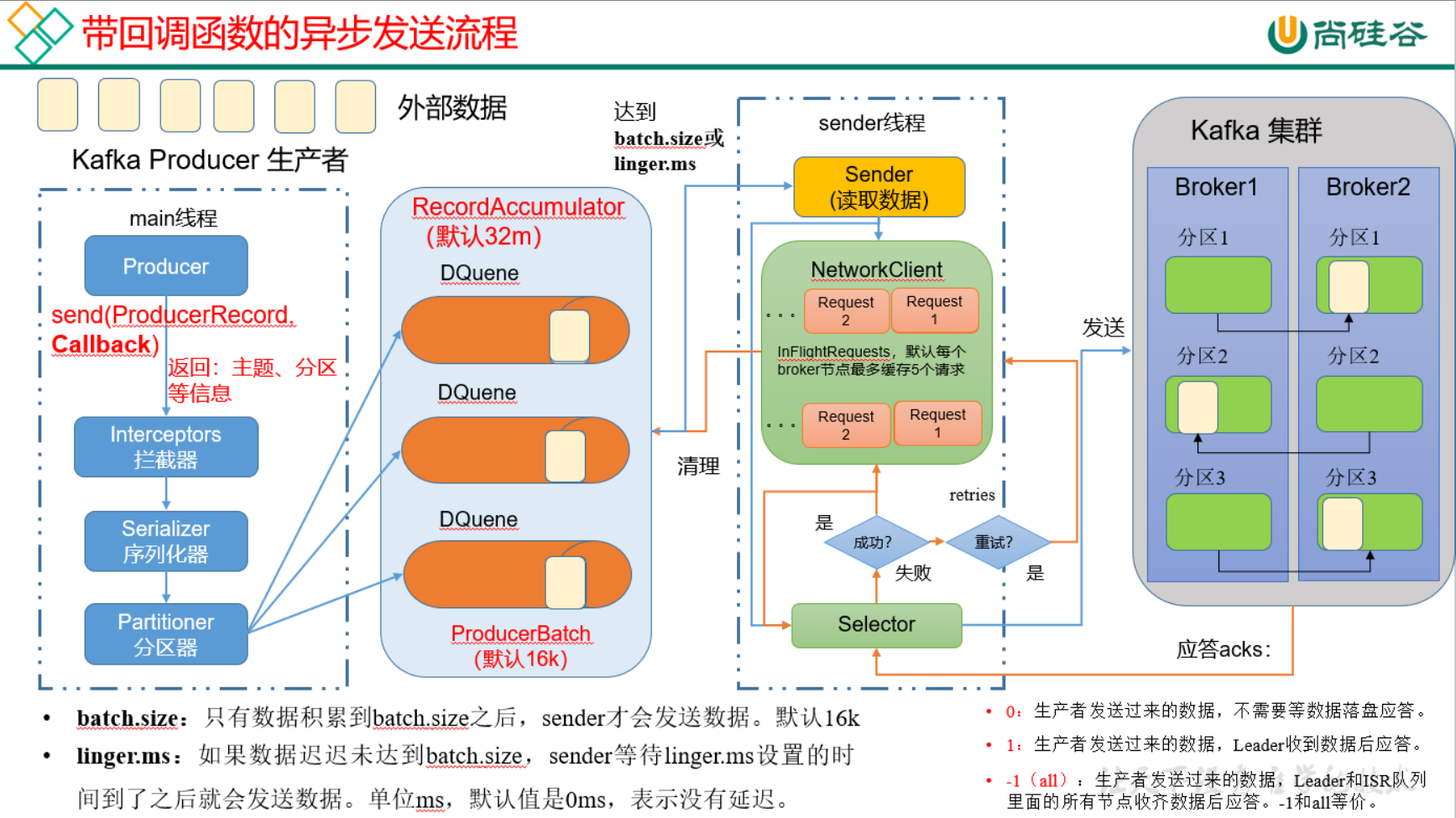
生产者如何提高吞吐量?
- batch.size:批次大小,默认16k
- linger.ms:等待时间,修改为5-100ms
- compression.type:消息压缩,snappy
RecordAccumulator:缓冲区大小,修改为64m
数据的可靠性
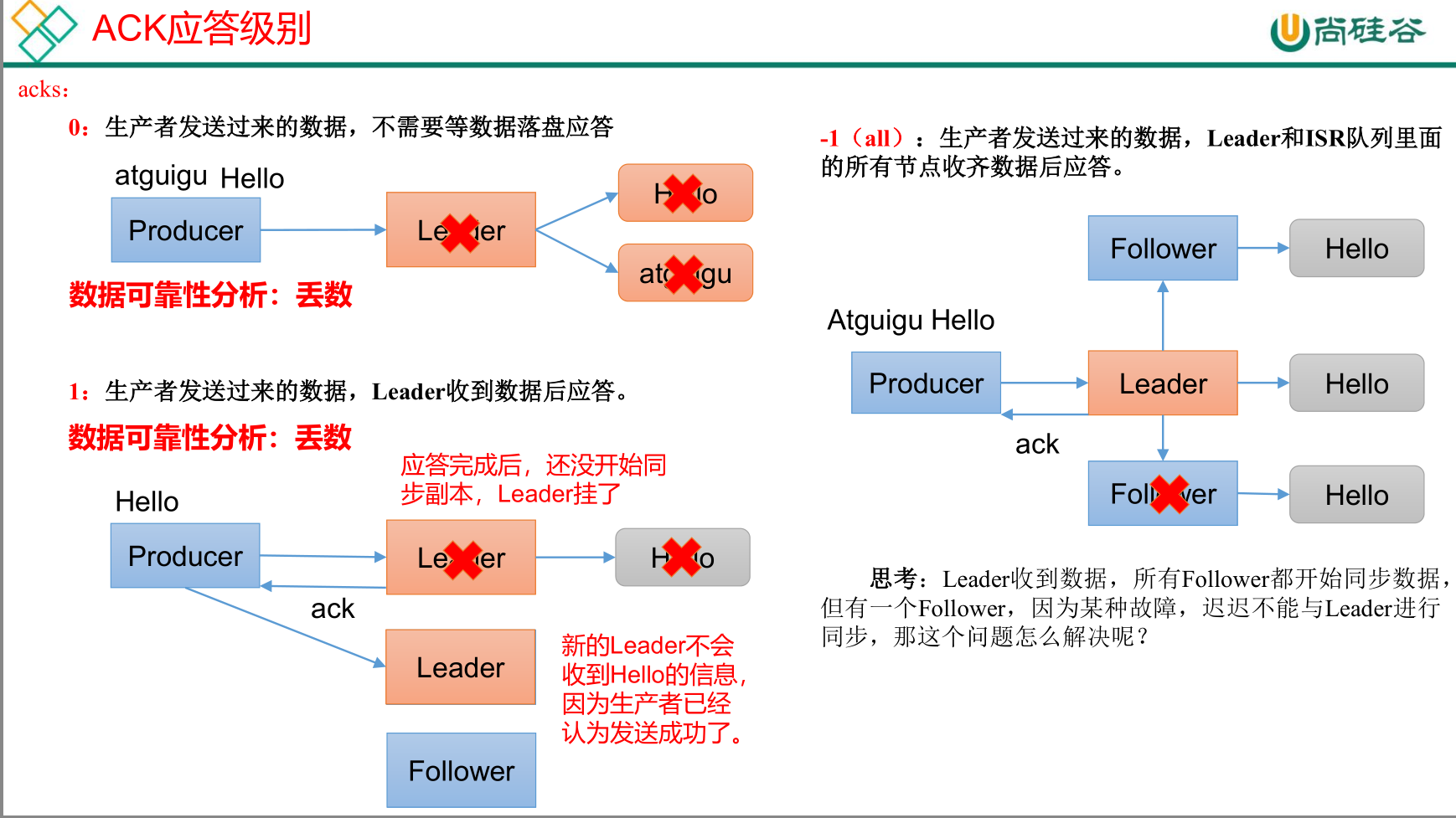
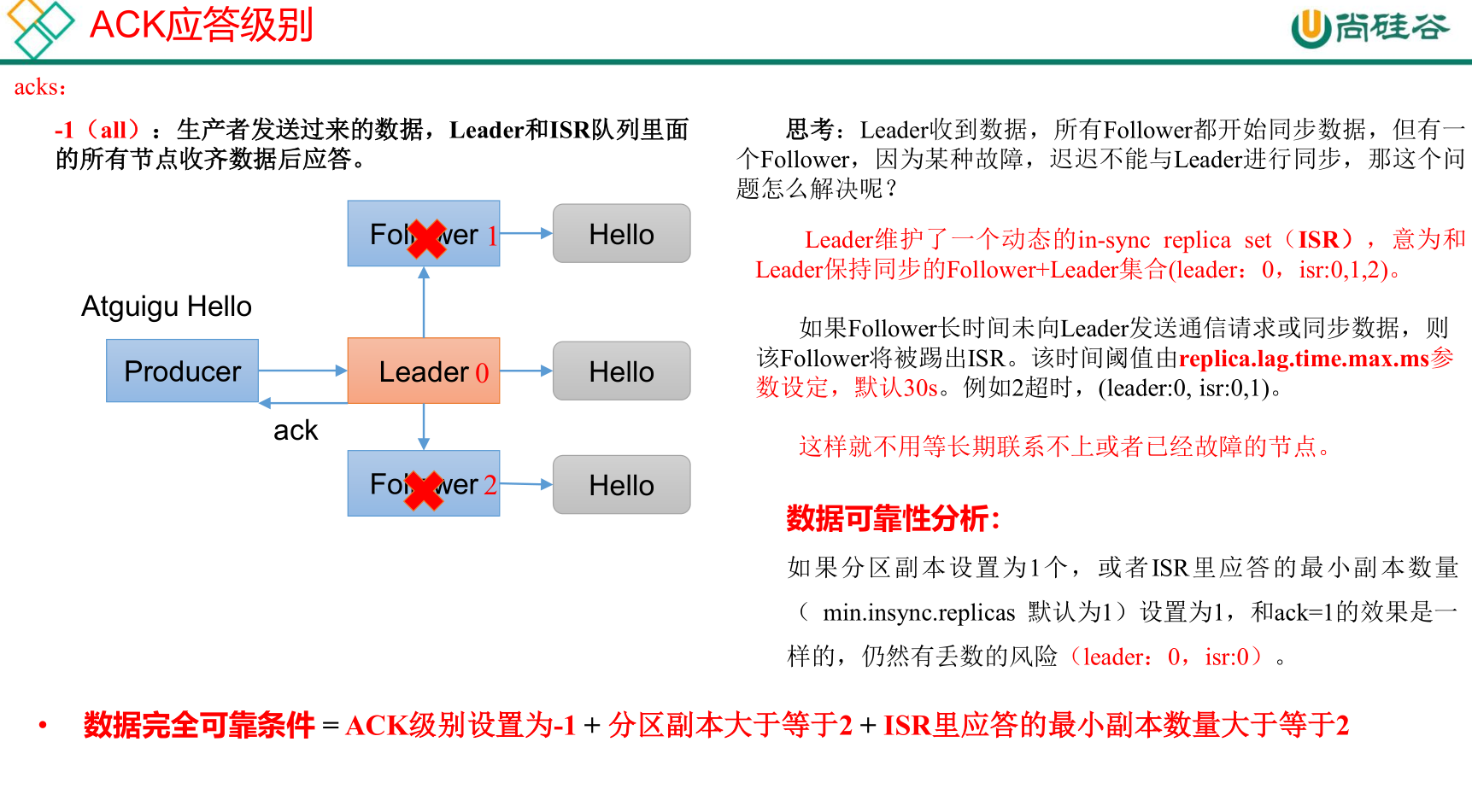
分区副本包括Leader

幂等性
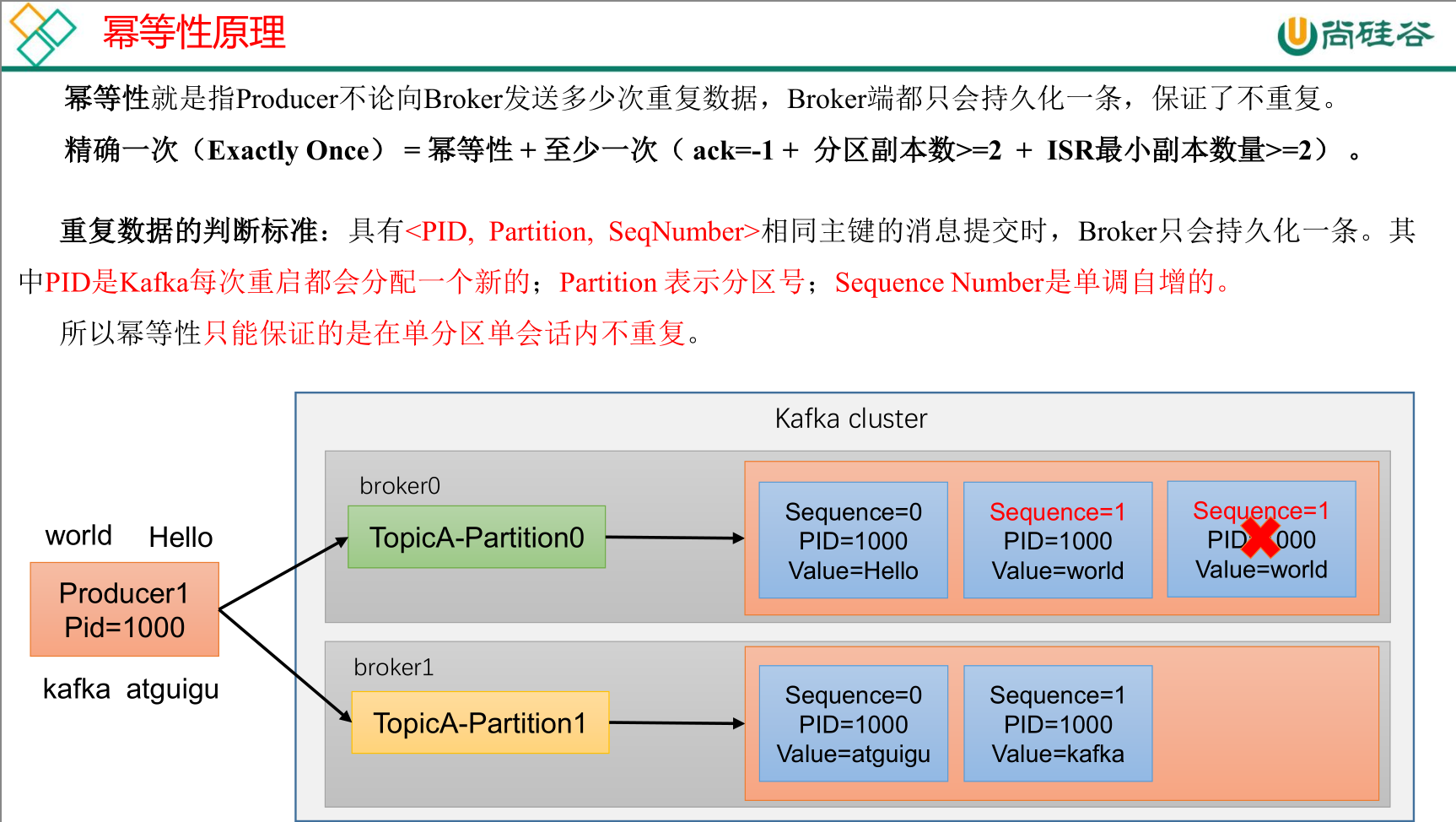
幂等性默认开启,参数 enable.idempotence 默认为 true,false关闭。
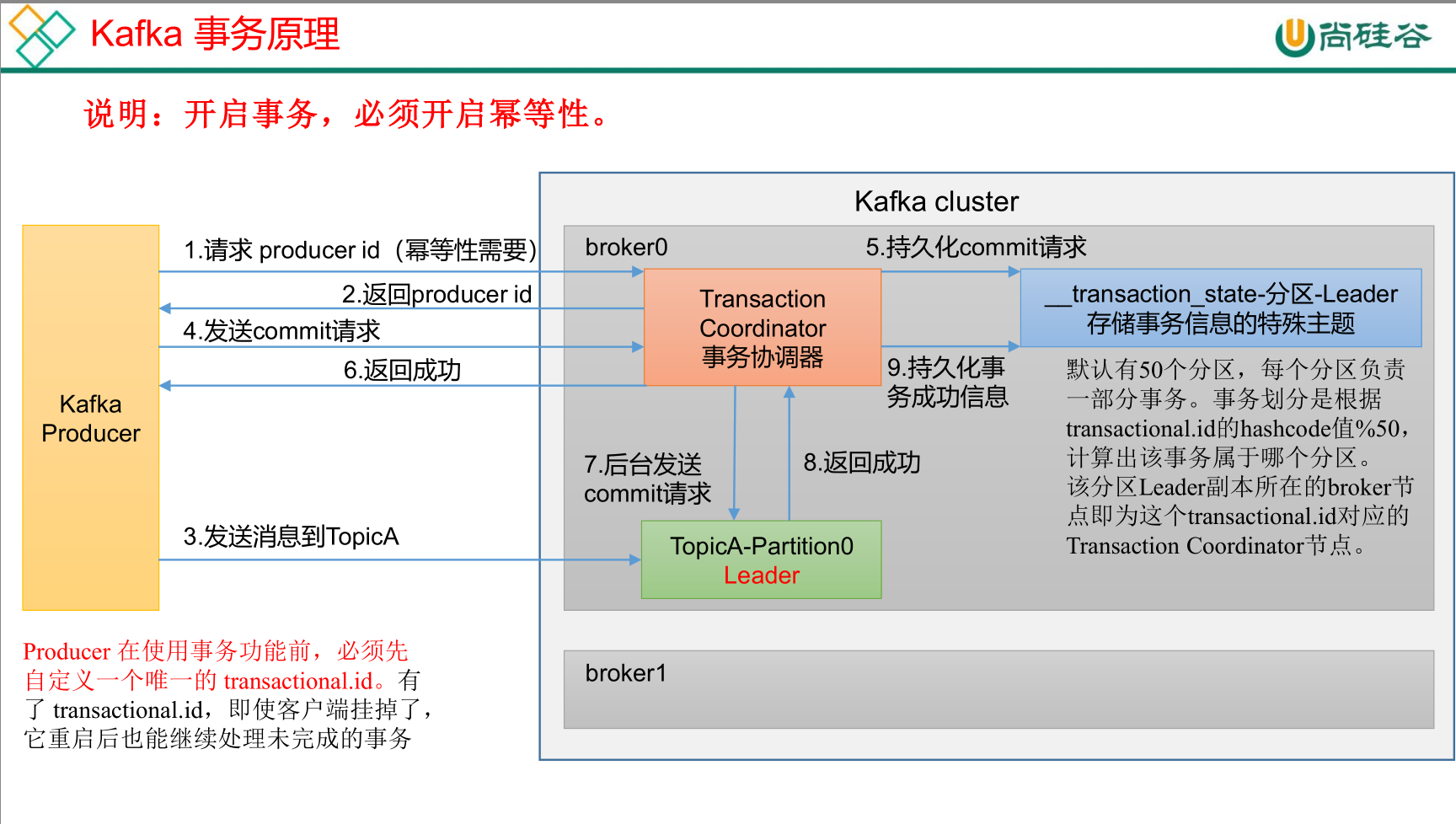
事务
数据有序性

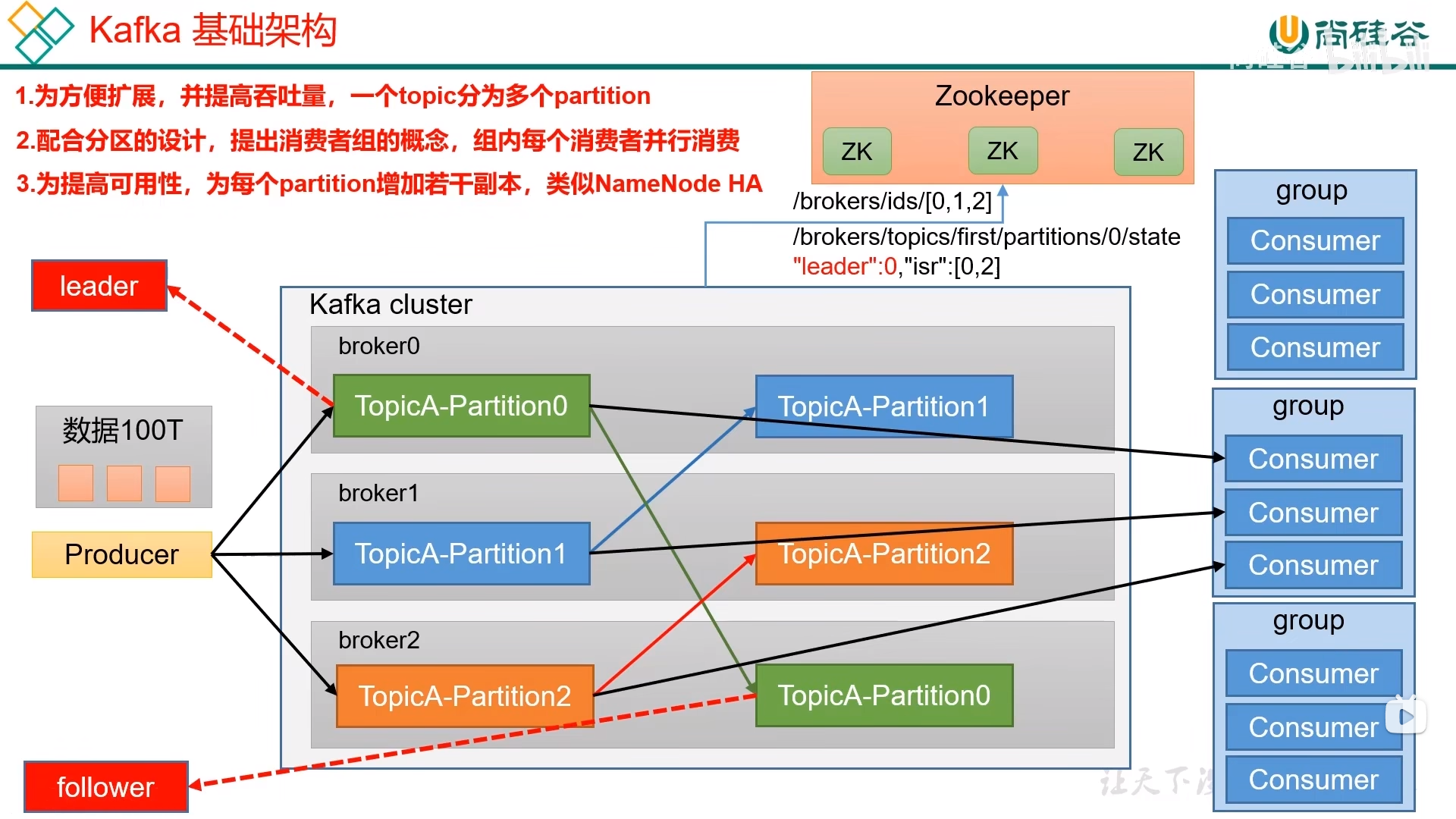
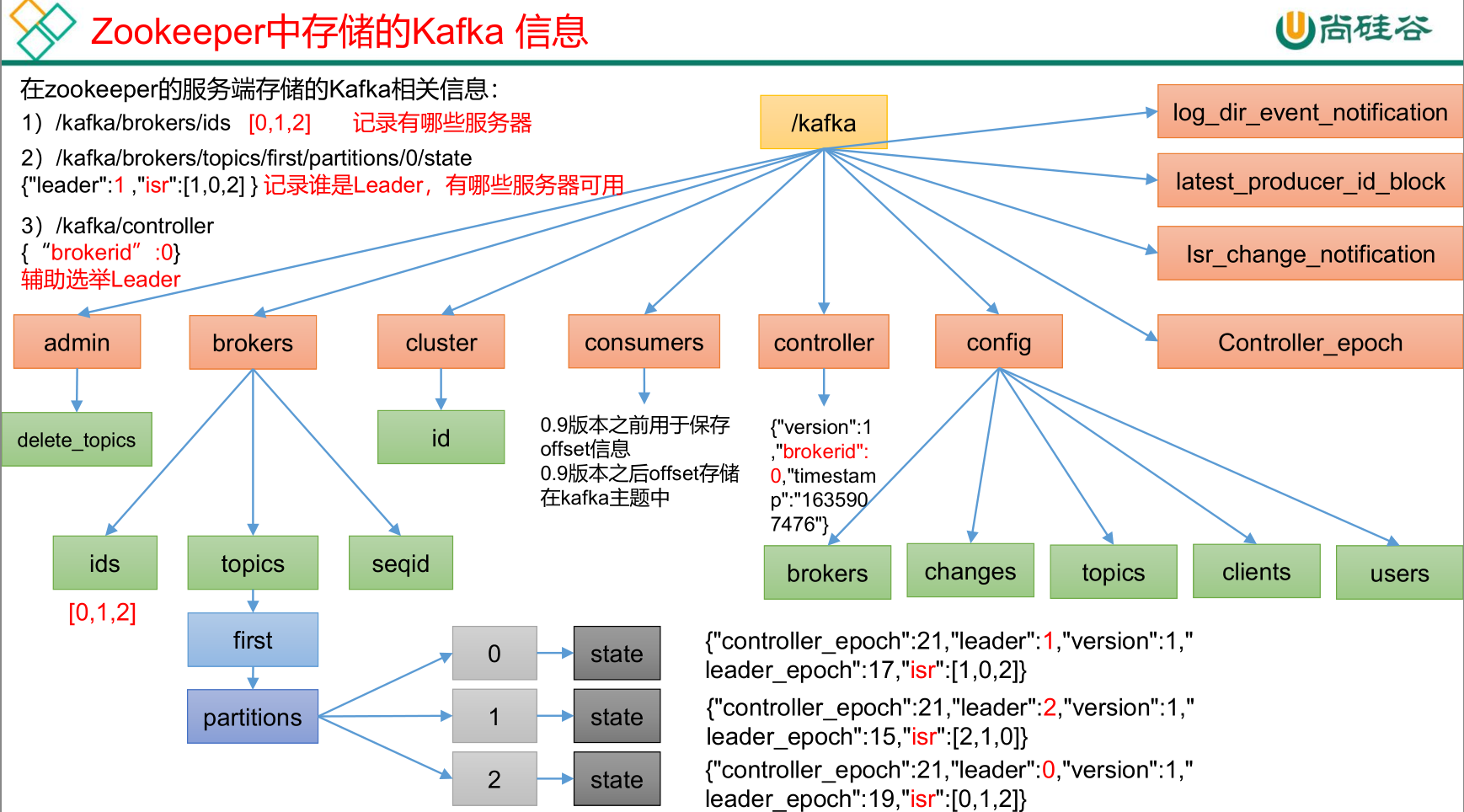
ZK中存储的Kafka信息
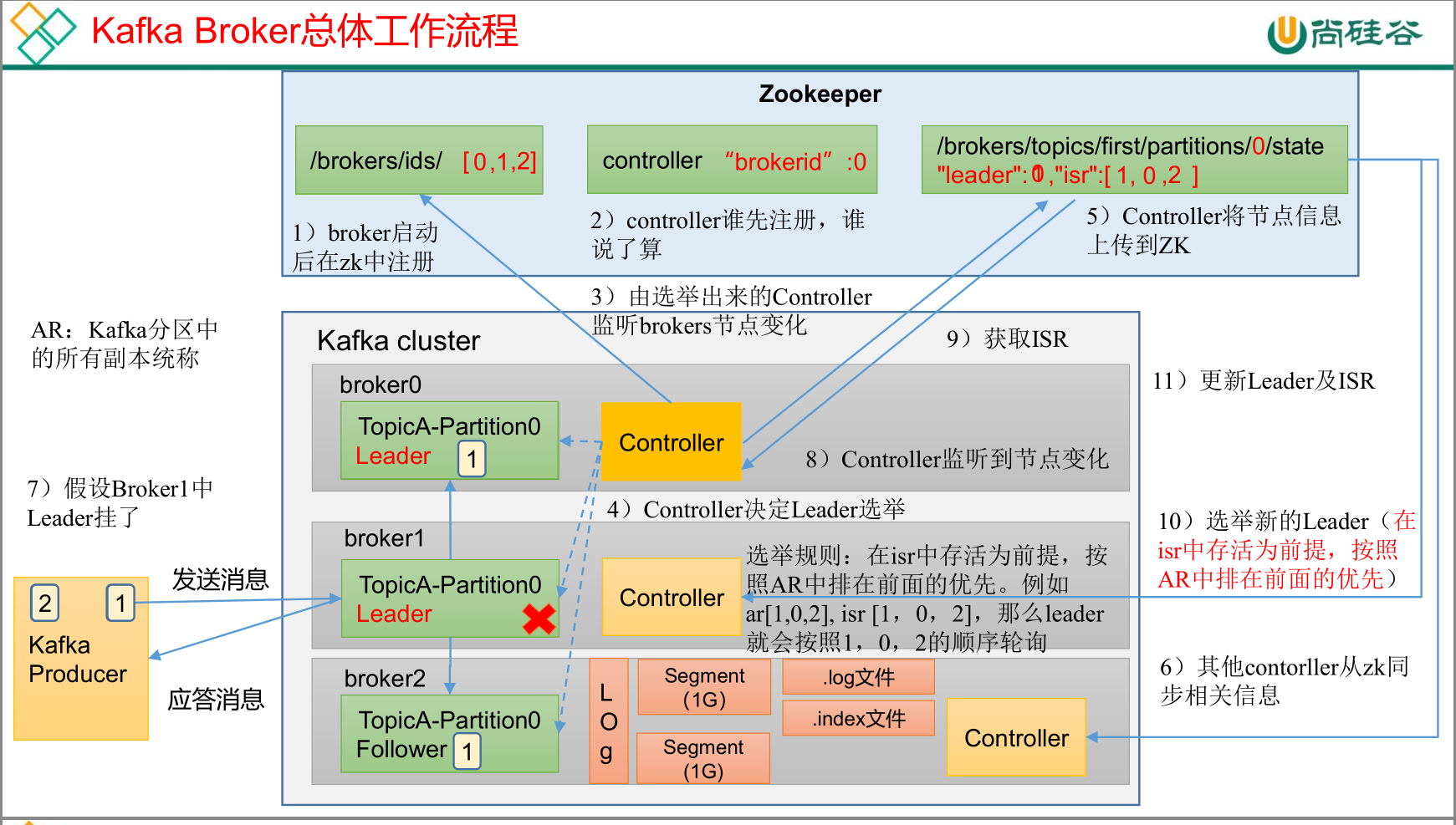
kafka Broker总体工作流程
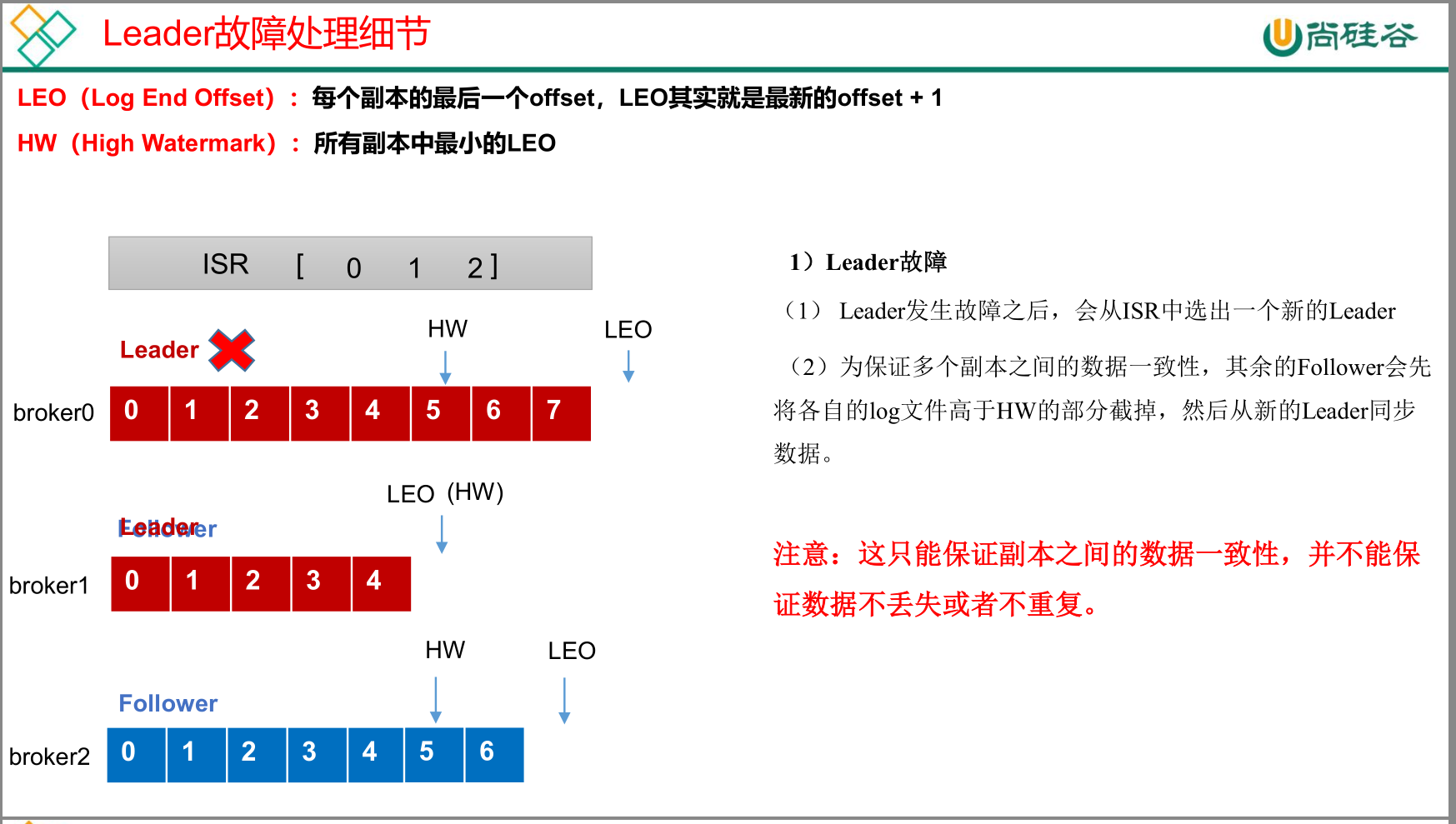
kafka副本


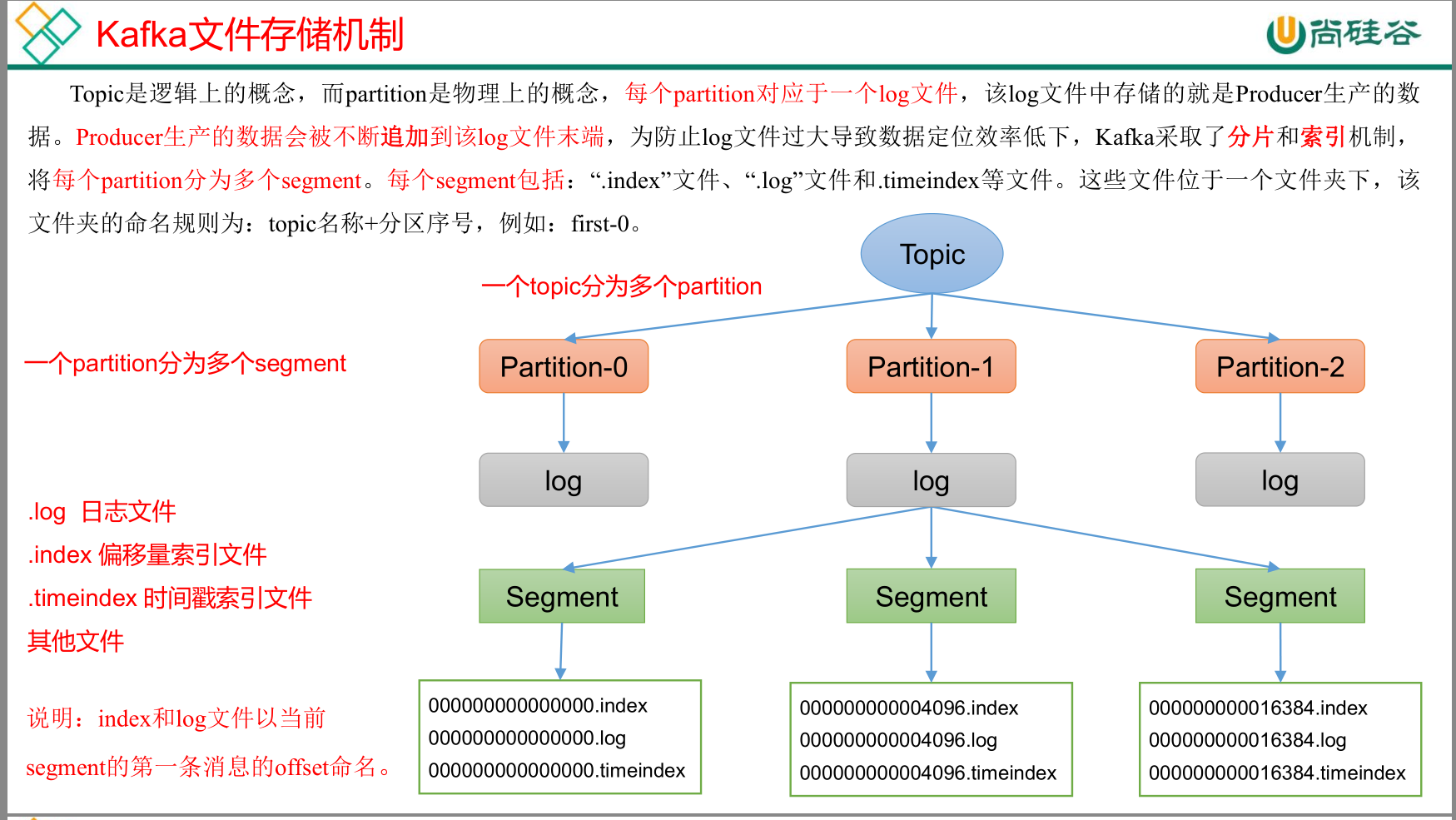
kafka文件存储机制
kafka高效读写数据

4)页缓存+零拷贝
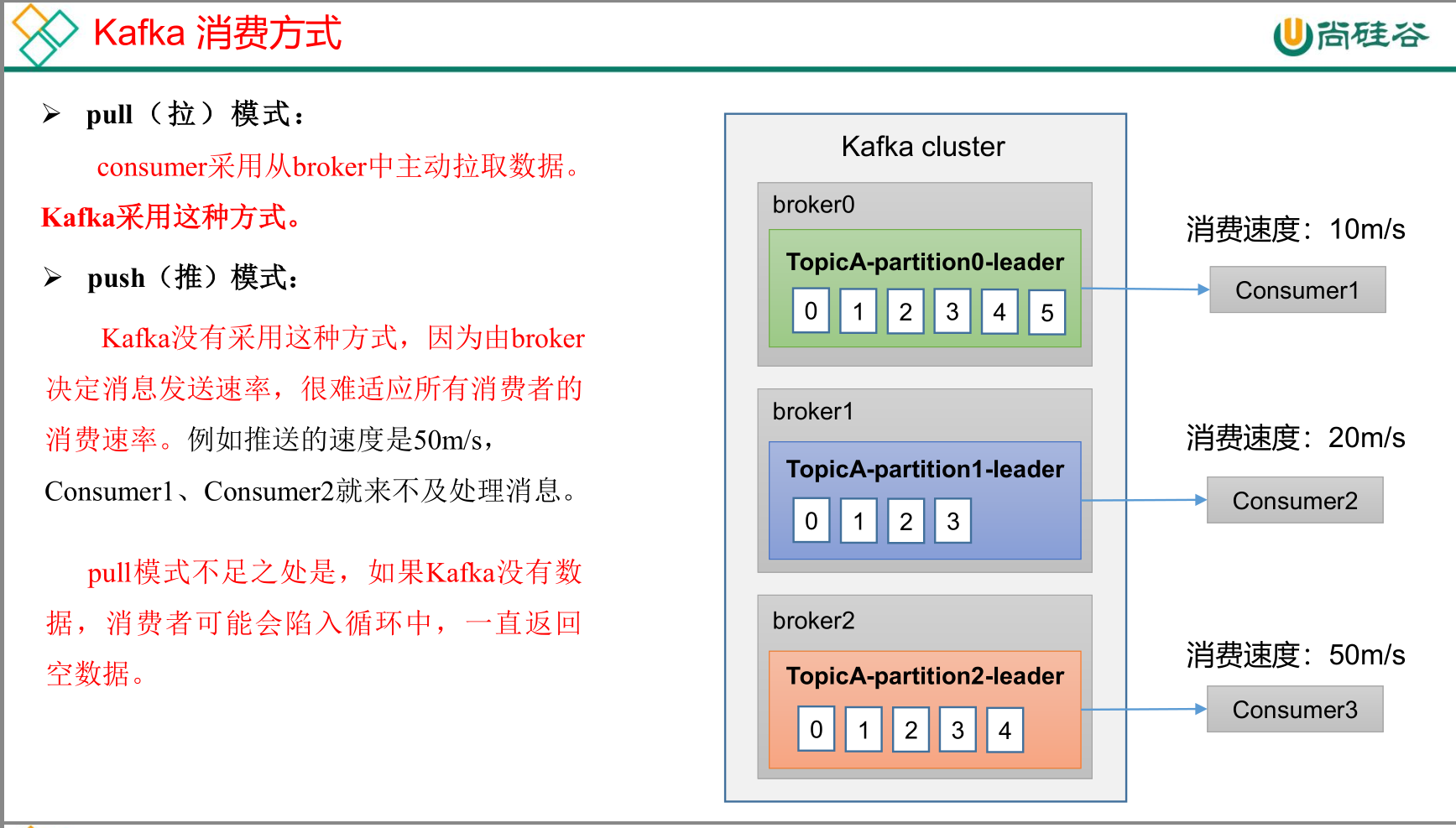
kafka消费方式

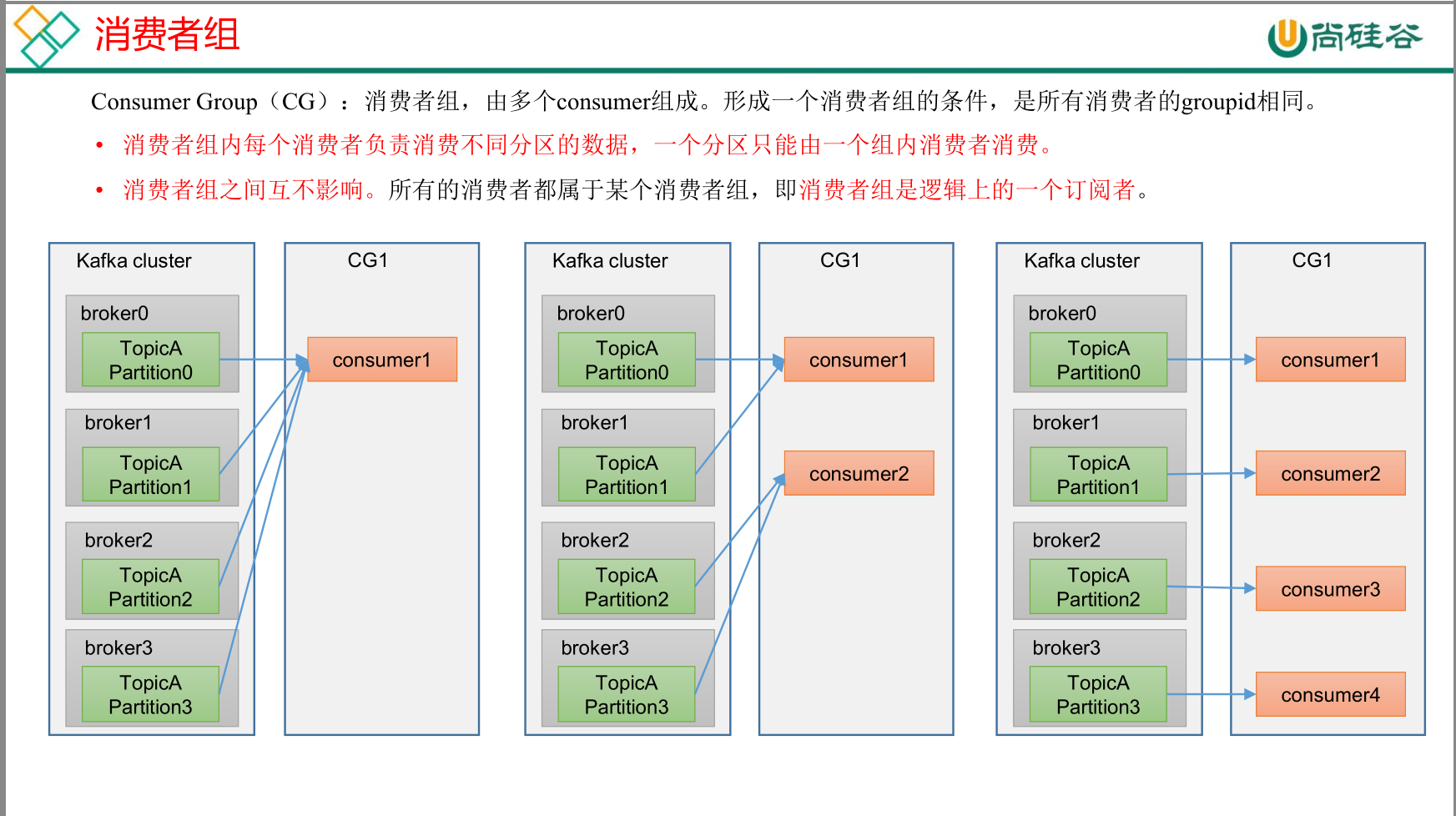
消费者组
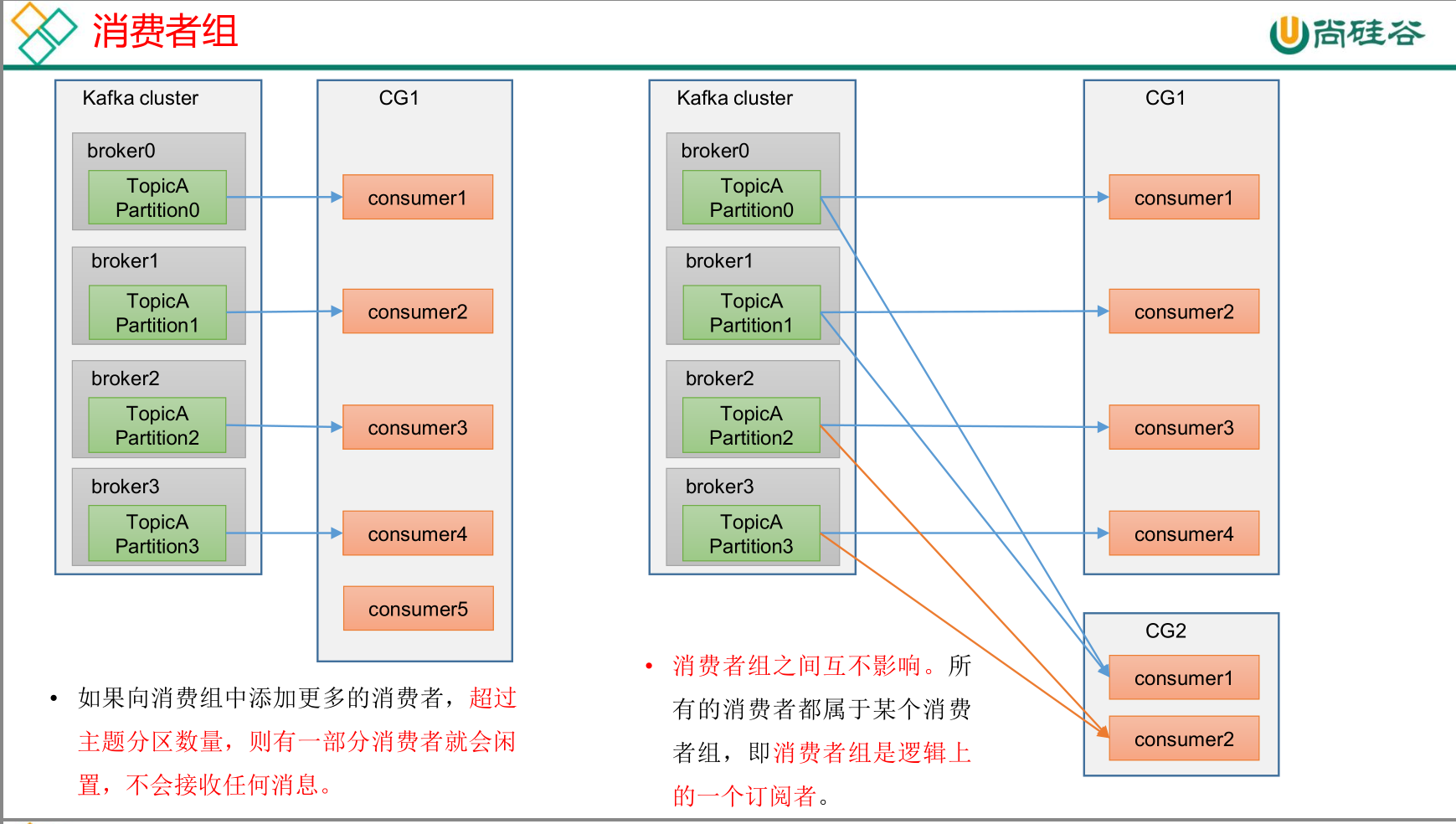
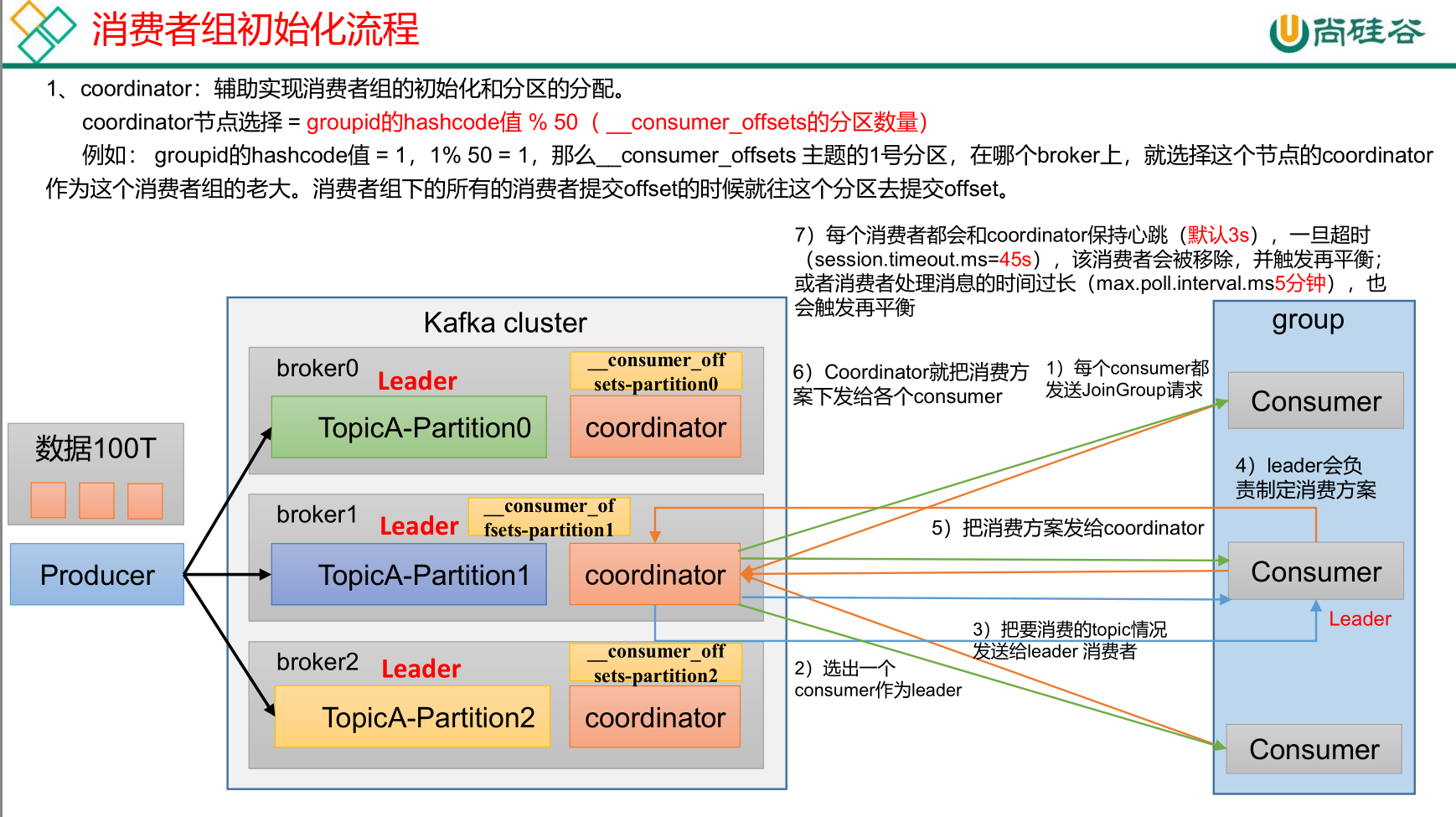
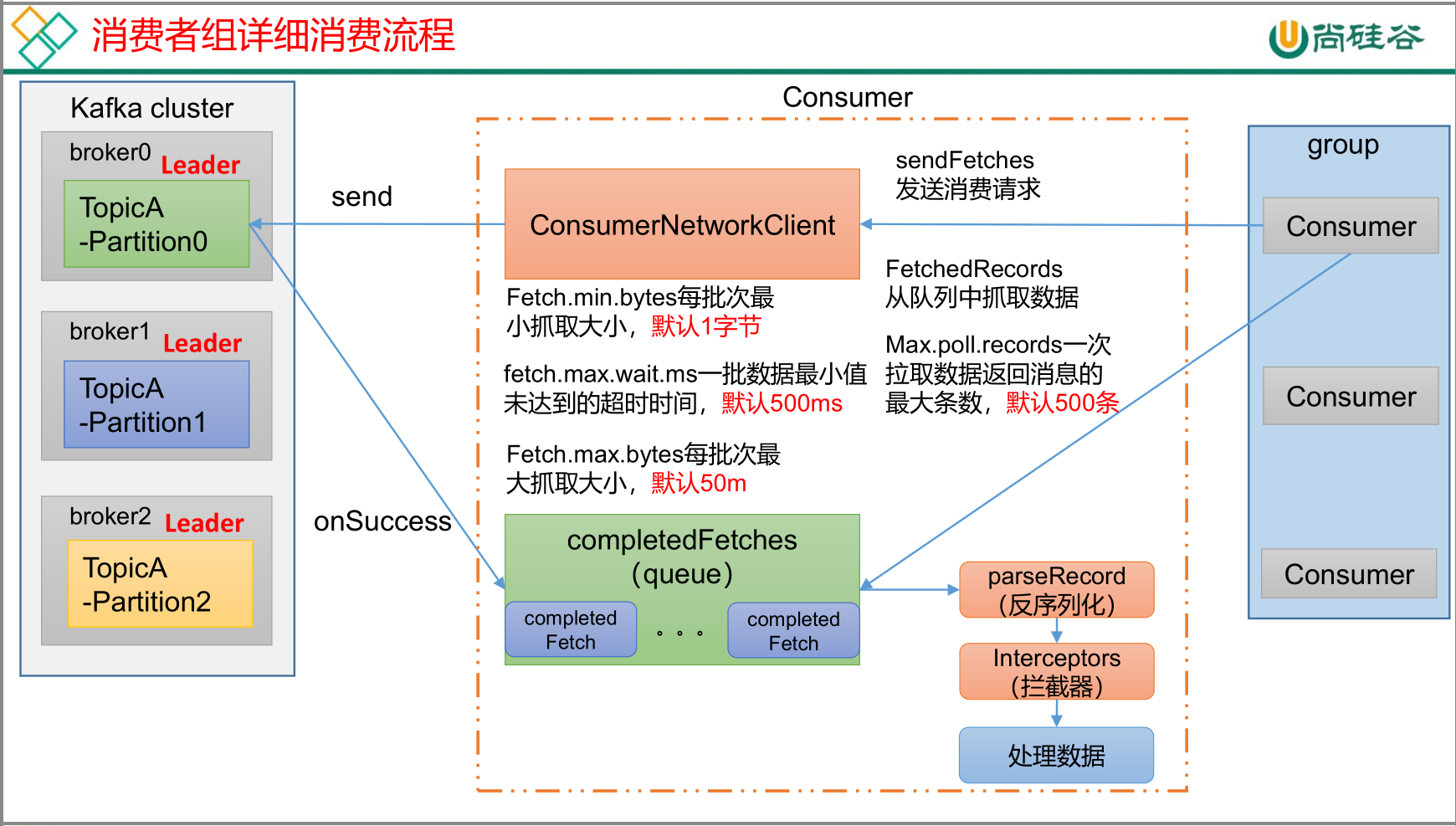
消费者组消费流程
消费分区的分配以及再平衡
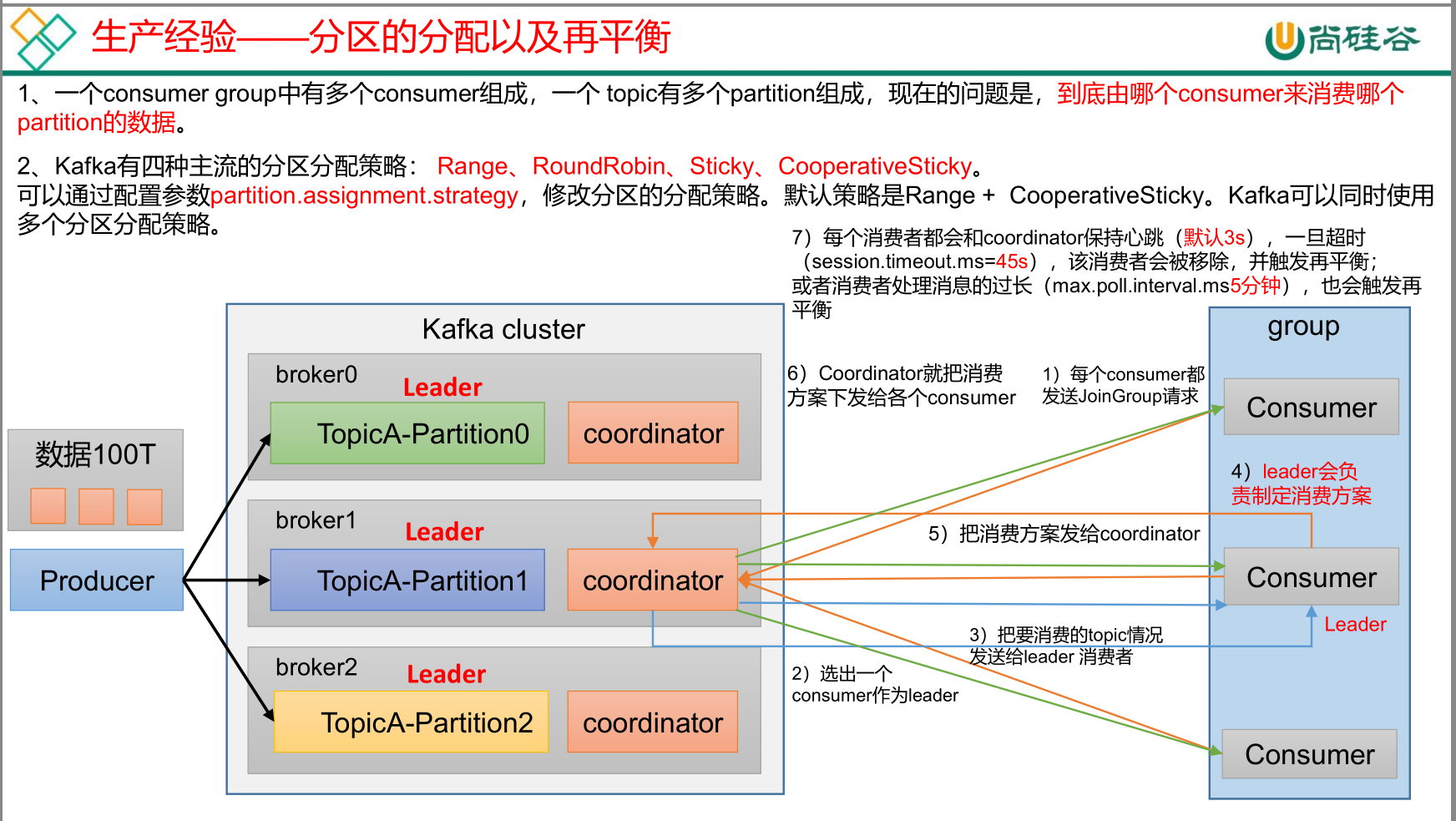
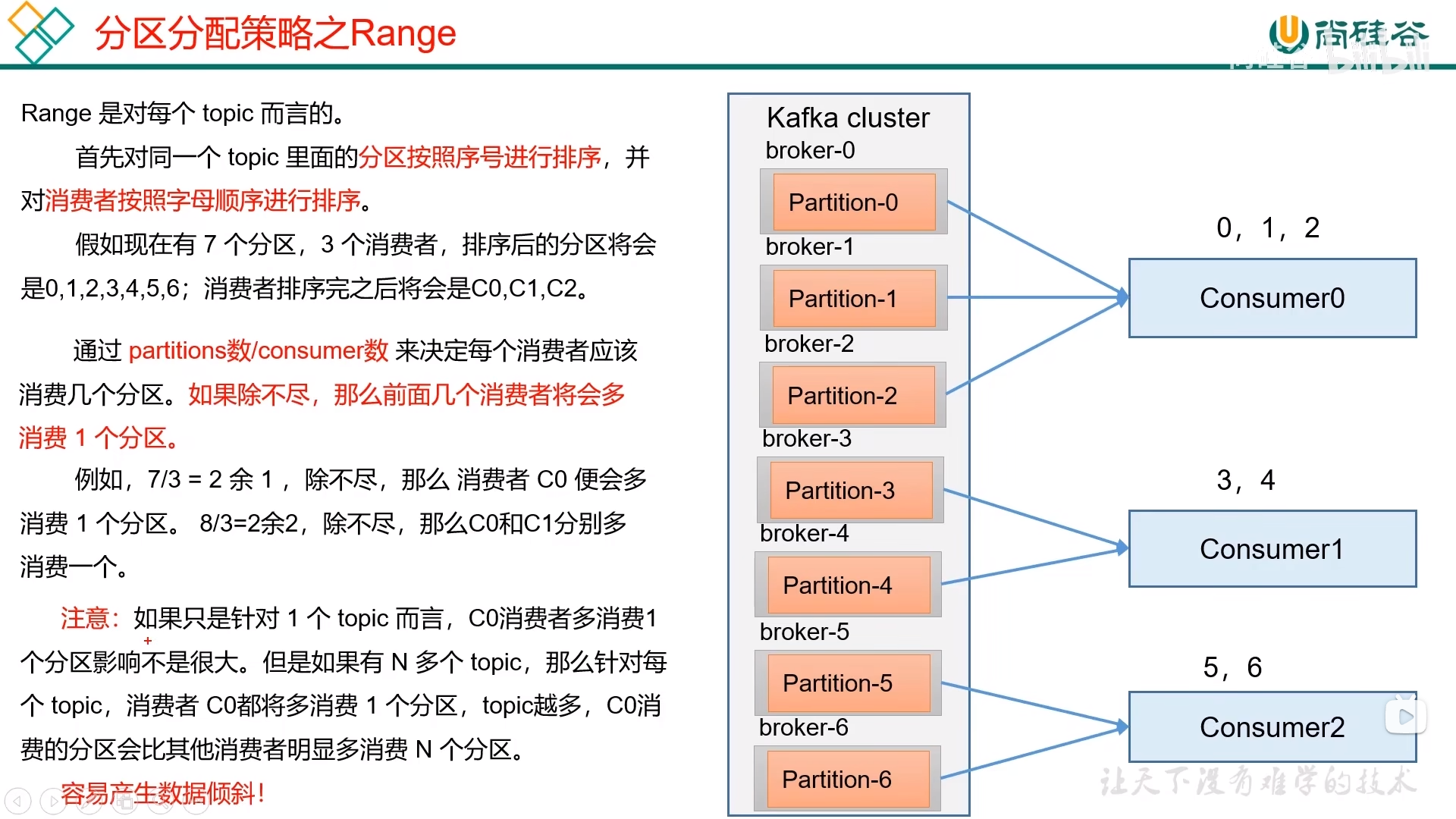
Range
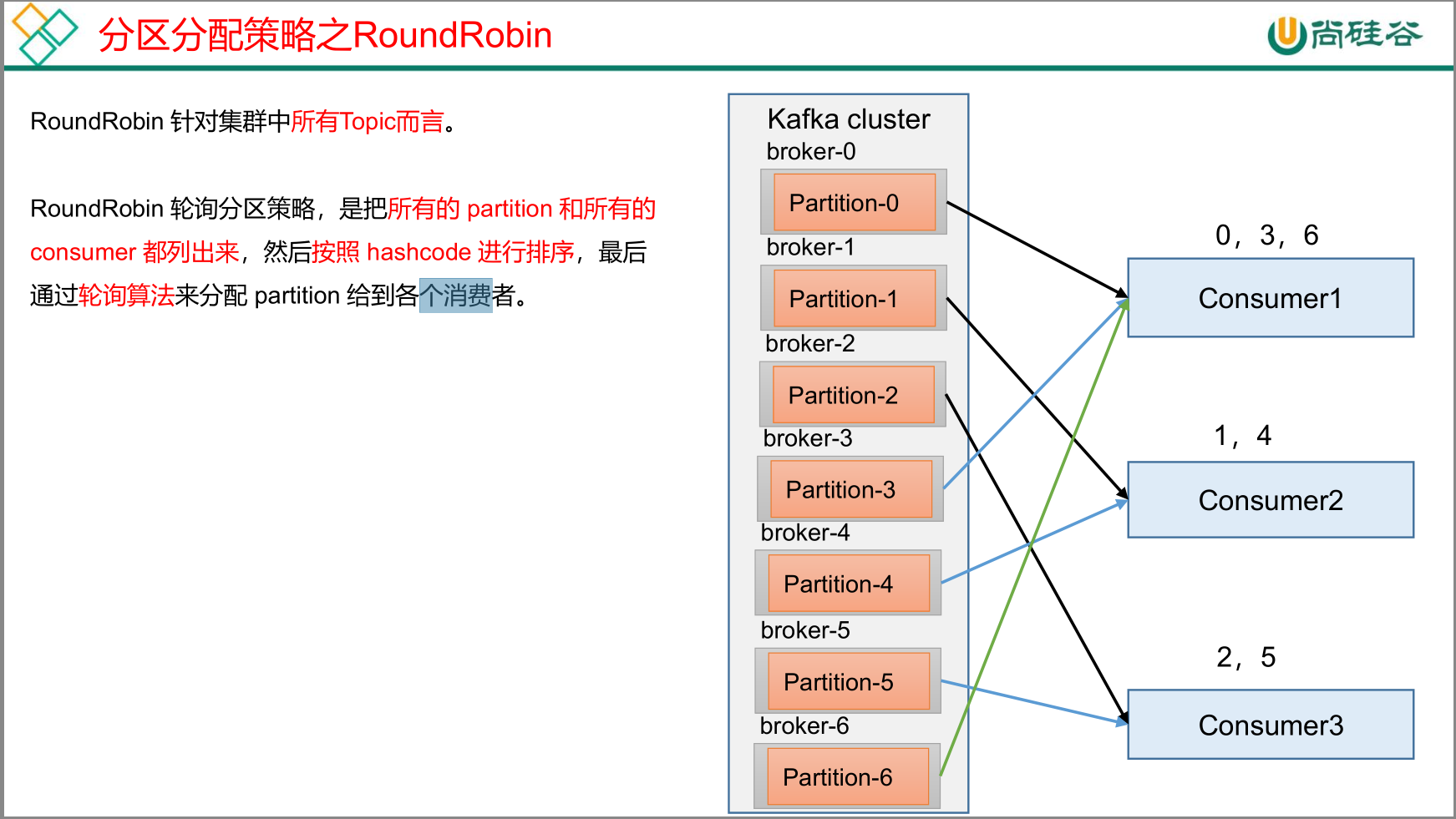
RoundRobin
Sticky

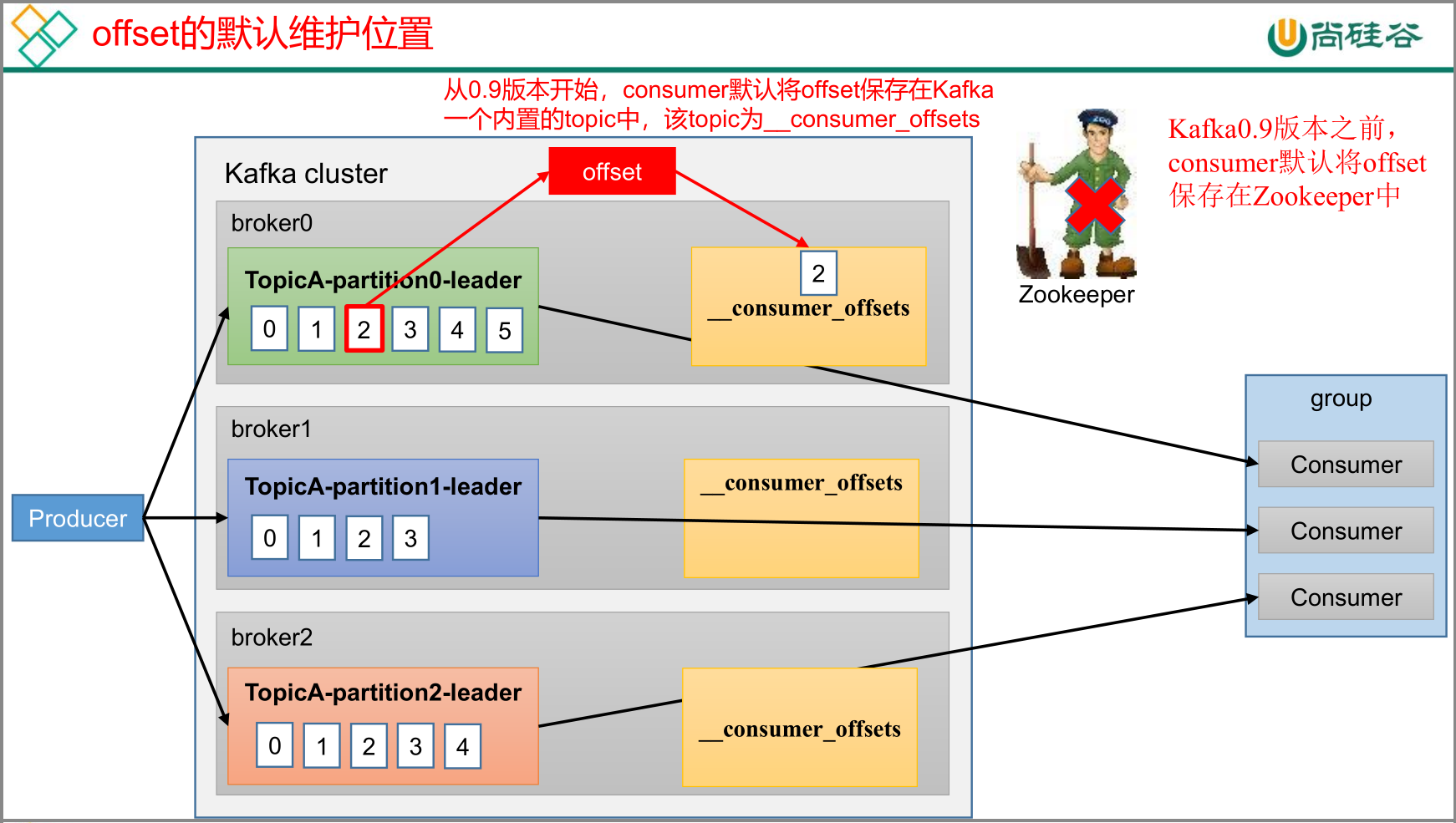
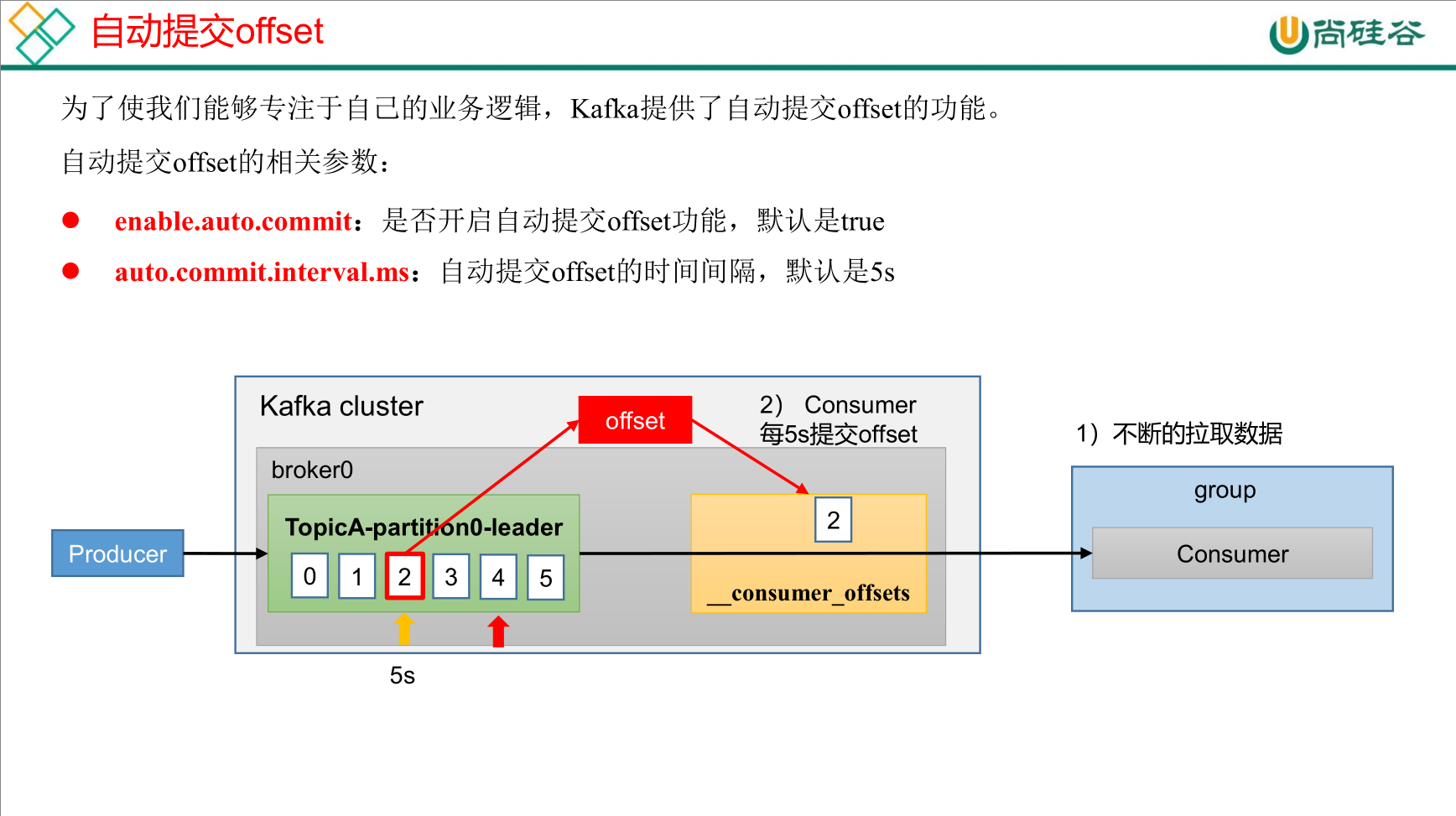
offset


public class CustomConsumerSeek {public static void main(String[] args) {// 0 配置信息Properties properties = new Properties();// 连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key value 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test2");// 1 创建一个消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅一个主题ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);Set<TopicPartition> assignment= new HashSet<>();while (assignment.size() == 0) {kafkaConsumer.poll(Duration.ofSeconds(1));// 获取消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();}// 遍历所有分区,并指定 offset 从 1700 的位置开始消费for (TopicPartition tp: assignment) {kafkaConsumer.seek(tp, 1700);}// 3 消费该主题数据while (true) {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}}
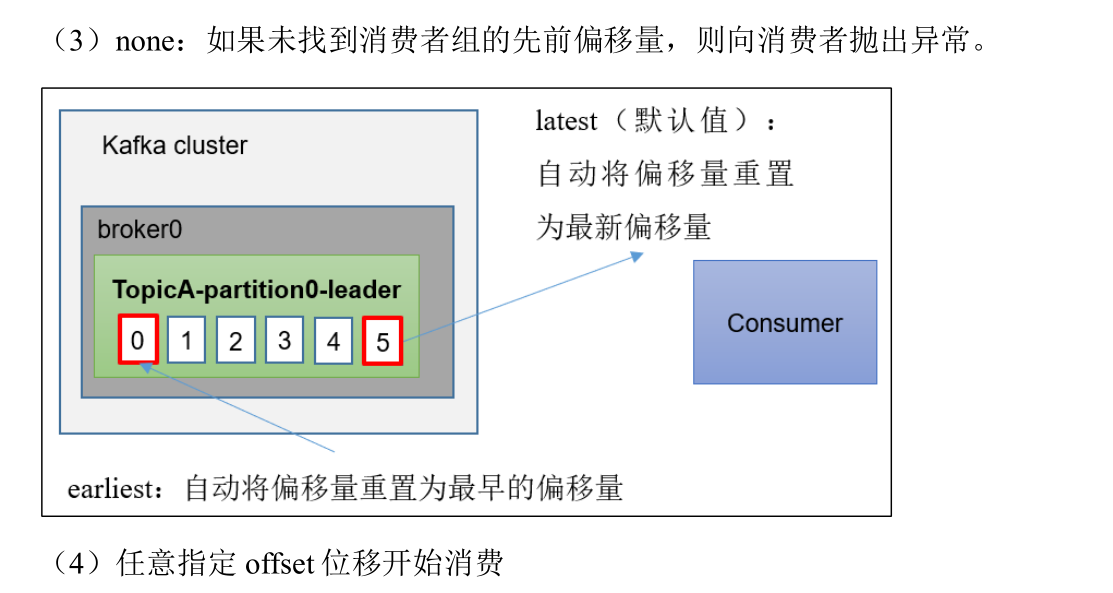
指定时间消费
public class CustomConsumerForTime {public static void main(String[] args) {// 0 配置信息Properties properties = new Properties();// 连接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key value 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test2");// 1 创建一个消费者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅一个主题ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);Set<TopicPartition> assignment = new HashSet<>();while (assignment.size() == 0) {kafkaConsumer.poll(Duration.ofSeconds(1));// 获取消费者分区分配信息(有了分区分配信息才能开始消费)assignment = kafkaConsumer.assignment();}HashMap<TopicPartition, Long> timestampToSearch = new HashMap<>();// 封装集合存储,每个分区对应一天前的数据for (TopicPartition topicPartition : assignment) {timestampToSearch.put(topicPartition,System.currentTimeMillis() - 1 * 24 * 3600 * 1000);}// 获取从 1 天前开始消费的每个分区的 offsetMap<TopicPartition, OffsetAndTimestamp> offsets = kafkaConsumer.offsetsForTimes(timestampToSearch);// 遍历每个分区,对每个分区设置消费时间。for (TopicPartition topicPartition : assignment) {OffsetAndTimestamp offsetAndTimestamp = offsets.get(topicPartition);// 根据时间指定开始消费的位置if (offsetAndTimestamp != null){kafkaConsumer.seek(topicPartition,offsetAndTimestamp.offset());}}// 3 消费该主题数据while (true) {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}}
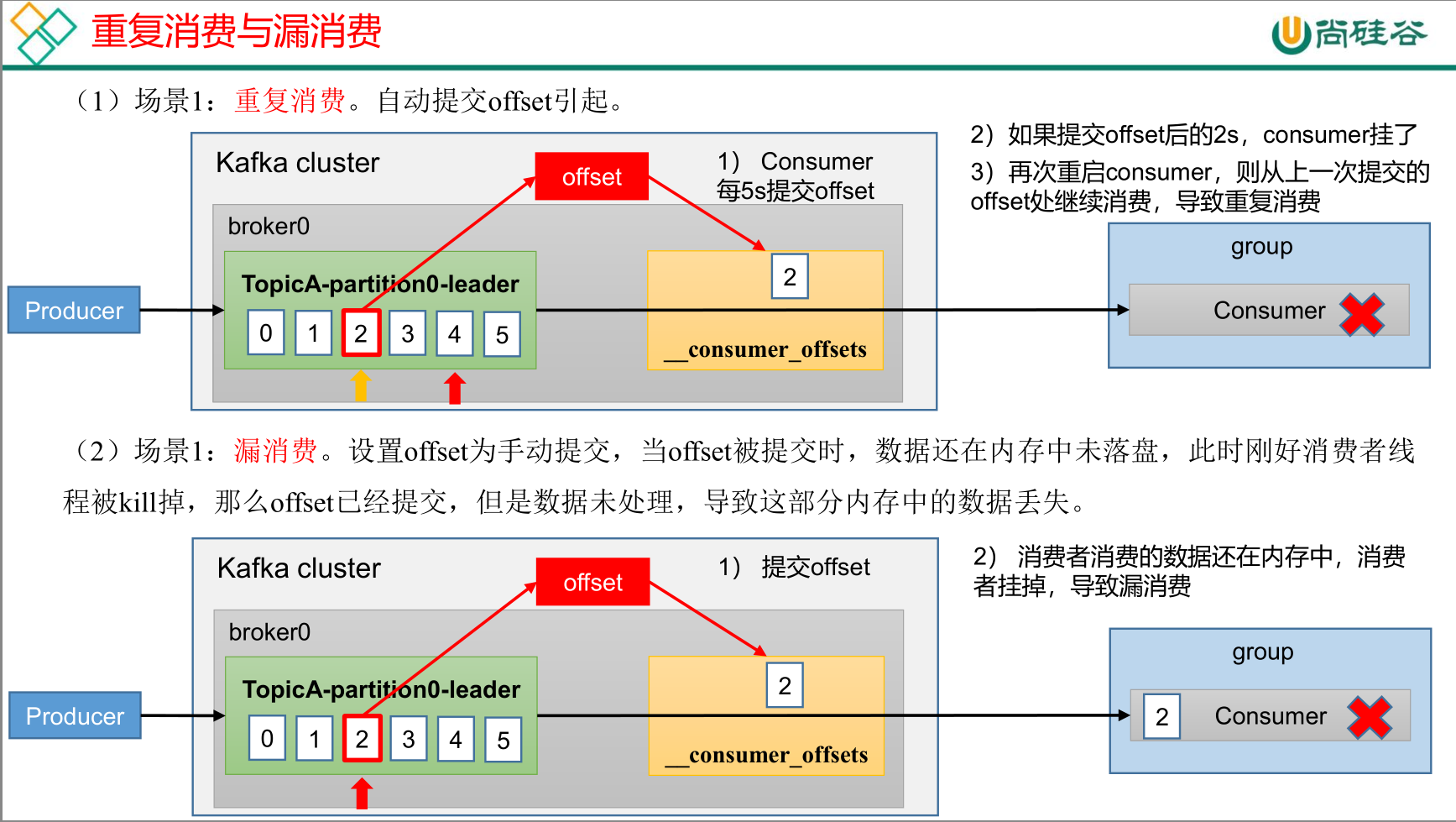
重复消费与漏消费
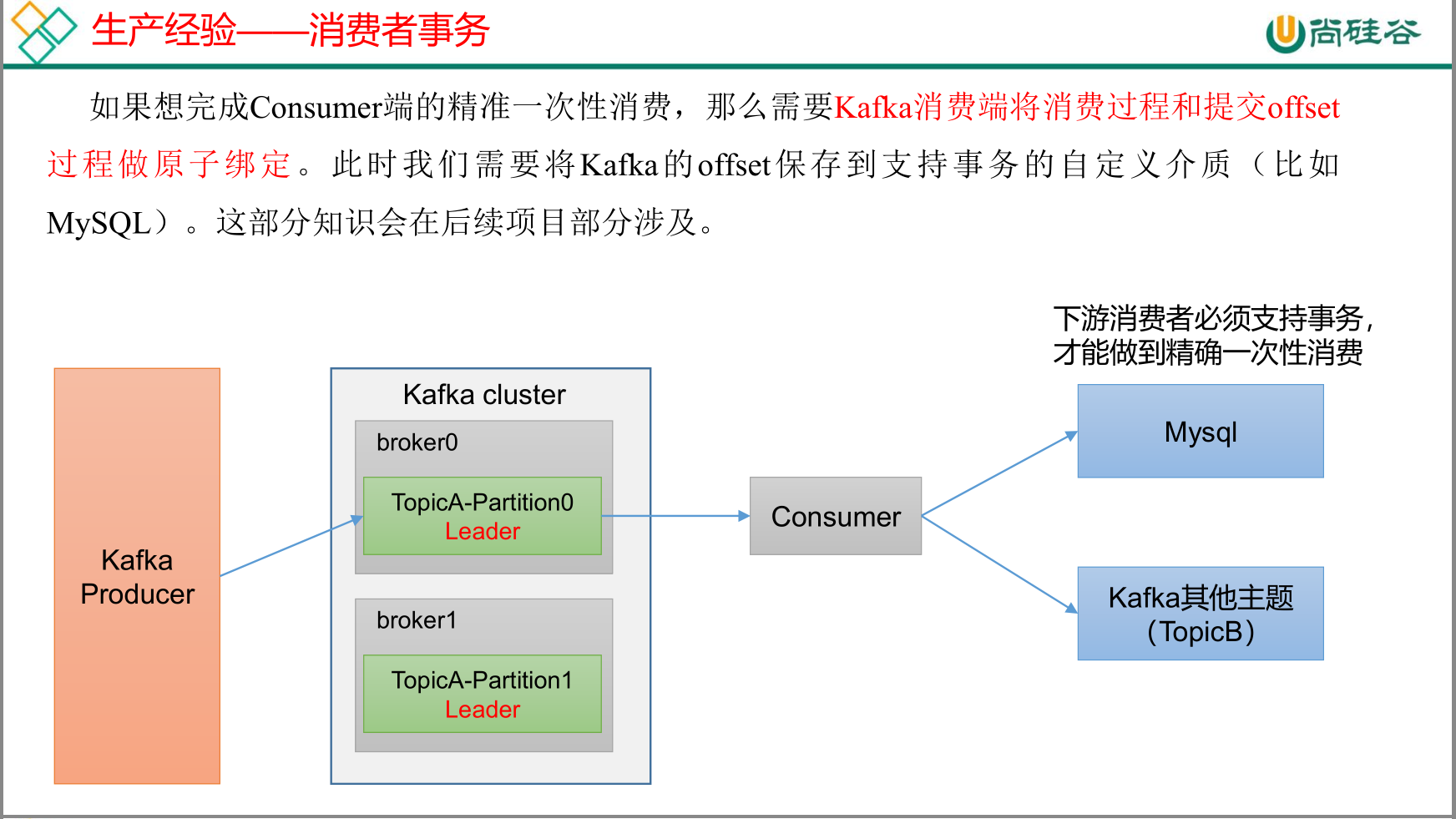
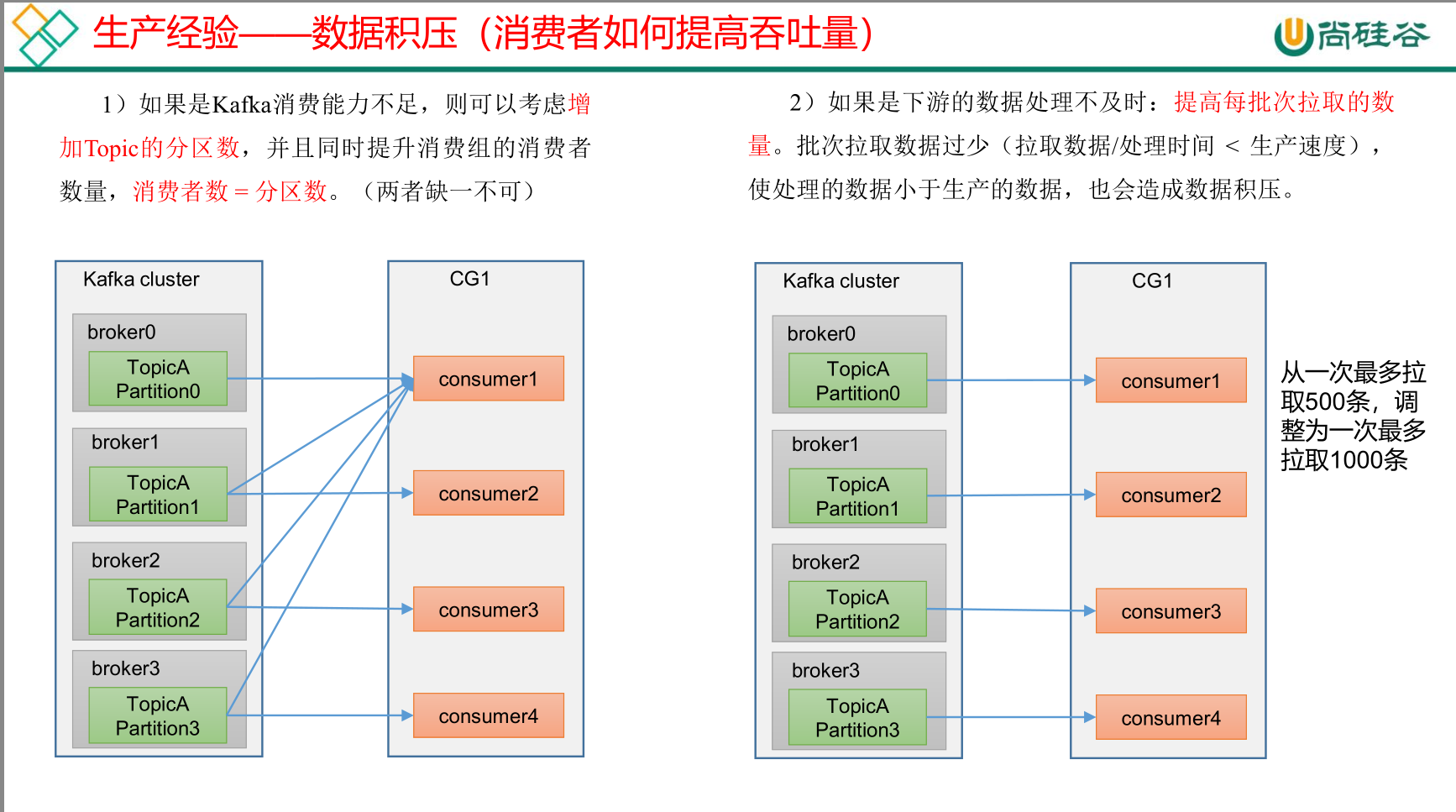
数据积压
参考资料
01_尚硅谷大数据技术之Kafka.pdf
03_尚硅谷大数据技术之Kafka(生产调优手册)V3.3.pdf
04_尚硅谷大数据技术之Kafka(源码解析)V3.3.pdf

若有收获,就点个赞吧
0 人点赞
