实验目的
实验原理
k-近邻(kNN,k-Nearest Neighbors)算法是一种基于实例的分类方法。该方法就是找出与未知样本x距离最近的k个训练样本,看这k个样本中多数属于哪一类,就把x归为那一类。k-近邻方法是一种懒惰学习方法,它存放样本,直到需要分类时才进行分类,如果样本集比较复杂,可能会导致很大的计算开销,因此无法应用到实时性很强的场合。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成反比
例如,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1.计算已知类别数据集中的点与当前点之间的距离;
2.按照距离递增次序排列;
3.选取与当前点距离最小的 K 个点;
4.确定前 K 个点所在类别的出现频率;
5.返回前 K 个点出现频率最高的类别作为当前点的预测分类
实验环境
- Linux Ubuntu 16.04
- Python 3.6
- Anaconda 4
- IPython Notebook
实验内容
学习KNN算法,了解模型创建、使用模型及模型评价等操作实验步骤
1.打开终端模拟器,切换到/data目录下,使用wget命令下载实验数据
cd /datawget http://192.168.1.100:60000/allfiles/sklearn/bc_data.csv
2.开启jupyter notebook
jupyter notebook --ip='127.0.0.1'
3.创建一个 .ipynb文件
数据读入
4.导入os模块,返回当前工作路径

5.导入pandas和numpy包,并改变工作目录为/data

6.读取/data/目录下的bc_data.csv文件,并返回文件内容
其中header参数用来指定数据开始读取行数。设置为0表示从第一行开始读取,设置为1,表示从第二行开始读取bc_data = pd.read_csv('/data/bc_data.csv', header=0)bc_data.head()#查看read_csv的用法pd.read_csv?
数据理解
7.shape函数是numpy.core.fromnumeric中的函数,直接用.shape可以快速读取矩阵的形状,使用shape[0]读取矩阵第一维度的长度

8.查看bc_data的列名

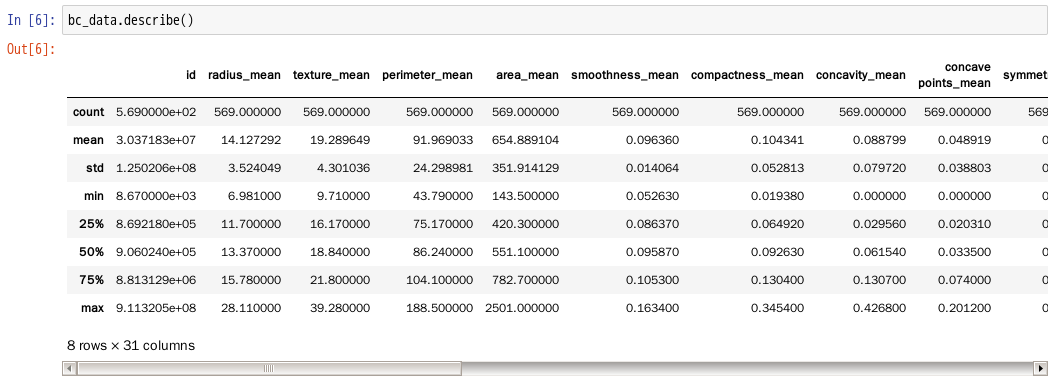
9.查看bc_data的描述性统计
数据准备
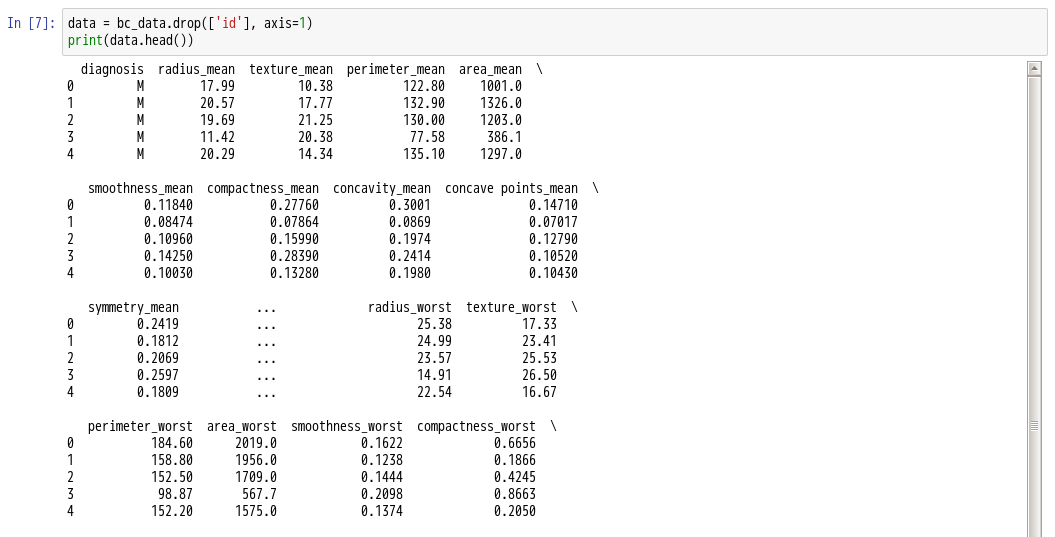
10.删除bc_data中的id列,其中axis使用0值表示沿着每一列或行标签\索引值向下执行方法,使用1值表示沿着每一行或者列标签模向执行对应的方法
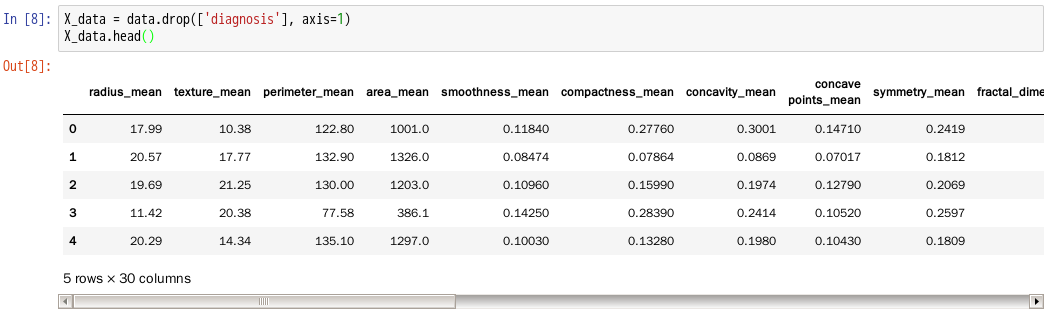
11.删除data文件中的diagnosis列并查看X_data内容
12.使用numpy中的ravel()方法将data中的多维数据降为一维,并使用切片查询y_data
这里需要注意的是np.ravel()返回的是视图,修改时会影响原始矩阵
13.导入sklearn库中的train_test_split函数,划分训练集和测试集
from sklearn.model_selection import train_test_splitX_trainingSet, X_testSet, y_trainingSet, y_testSet = train_test_split(X_data, y_data, random_state=1)

参数解释如下:
14.使用shape函数查看训练集矩阵形状

15.使用shape函数查看测试集矩阵形状

算法选择及其超级参数的设置
16.导入sklearn模块中的KNeighborsClassifier函数,并使用kd_tree算法
from sklearn.neighbors import KNeighborsClassifiermyModel = KNeighborsClassifier(algorithm='kd_tree')
具体模型的训练
17.使用.fit方法对训练数据进行模型拟合

用模型进行预测
18.使用.predict方法,用训练好的模型进行预测
y_predictSet = myModel.predict(X_testSet)
19.打印输出y_predictSet预测结果
20.打印输出y_testSet

模型评价
21.导入sklearn模块中的accuracy_score,对模型进行评价

说明:模型的正确率为0.937062937063
至此,实验结束!


















若有收获,就点个赞吧
0 人点赞
