实验目的
1.理解一元线性回归原理
2.掌握Statsmodels 分析模块相应的方法
实验原理
《一、线性回归》
线性回归也被称为最小二乘法回归(Linear Regression, also called Ordinary Least-Squares (OLS) Regression)。 它的数学模型是这样的:
y = a+ b x+e其中,a被称为常数项或截距、b被称为模型的回归系数或斜率、e为误差项。
a和b是模型的参数,当然,模型的参数只能从样本数据中估计出来:y’= a’ + b’ x,我们的目标是选择合适的参数,让这一线性模型最好地拟合观测值 ,拟合程度越高,模型越好, 我们如何判断拟合的质量呢?这一线性模型可以用二维平面上的一条直线来表示,被称为回归线,模型的拟合程度越高,也即意味着样本点围绕回归线越紧密
如何计算样本点与回归线之间的紧密程度呢?
高斯和勒让德找到的方法是:被选择的参数,应该使算出来的回归线与观测值之差的平方和最小。 用函数表示为:
这被称为最小二乘法,其原理为:当预测值和实际值距离的平方和最小时,就选定模型中的两个参数(a和b) 这一模型并不一定反映解释变量和反应变量真实的关系。 但它的计算成本低,相比复杂模型更容易解释
模型估计出来后,我们要回答的问题是:
- 我们的模型拟合程度如何?或者说,这个模型对因变量的解释力如何?(R2)
- 整个模型是否能显著预测因变量的变化?(F检验)
-
《二、Statsmodels 》
Statsmodels 是 Python 中一个强大的统计分析包,包含了回归分析、时间序列分析、假设检验等等的功能。可以与 Python 的其他的任务(如 NumPy、Pandas)有效结合,提高工作效率。在本文中,我们重点介绍回归分析中最常用的 OLS(ordinary least square)功能。当你需要在 Python 中进行回归分析时,import statsmodels.api as sm 后,就可以使用其中的方法了。
实验内容
利用statsmodels进行最小二乘回归,分析女性身高与体重之间的关系并作出线性回归预测,评估模型。
实验环境
Linux Ubuntu 16.04
Python 3.6.1
Jupyter实验步骤
1.首先打开终端模拟器,输入下面命令:jupyter notebook —ip=’127.0.0.1’,
cd /jupyter notebook --ip='127.0.0.1'

如上图所示,该终端不要关闭,在浏览器中会打开下面界面,
如果是第一次打开,浏览器界面会要求输入密码,密码为zhangyu2.切换到/data目录下,点击New,在其下拉框中选择folder

选中刚才创建的文件夹,点击页面左上角的【Rename】
重命名为linear_regression
3.切换到linear_regression 目录下,新建一个ipynb文件,用于编写并执行代码。点击页面右上角的New,选中【Python3】
4.线性回归分析
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。
本次“线性回归分析女性身高和体重之间关系”,我们将通过以下9个步骤开始进行:
1.业务理解
2.读取数据
3.数据理解
4.数据准备
5.模型类型的选择与超级参数的设置
6.训练具体模型及查看其统计量
7.模型预测
8.模型评价
9.模型优化与重新选择(1)业务理解
分析女性身高与体重之间的关系:分析数据women,来自The World Almanac and Book of Facts
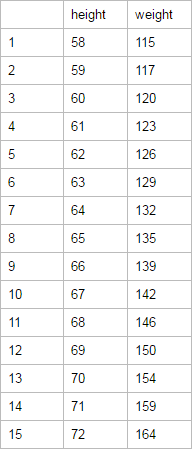
(2)获取数据并读取数据
2.1.打开linux终端,下载所需资源
cd /data/linear_regressionwget http://192.168.1.100:60000/allfiles/sklearn/line/women.csv

2.2. 在刚才新建的ipynb文件中,读取数据#导入pandas库和numpy库import pandas as pdimport numpy as np#读取women.csvdf_women = pd.read_csv('women.csv',index_col=0)#读取前五行数据,如果是最后五行,用df_women.tail()print(df_women.head())
(3)数据理解
3.1.查看数据结构

说明:women.csv表中共有15行,两列数据
3.2.查看列名称
说明:women.csv中总共两列数据,名称为height和weight
3.3.查看关于women数据的描述统计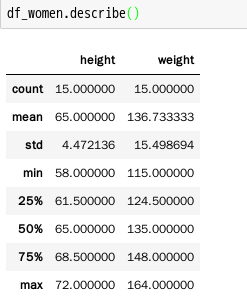
3.4.将women.csv中的数据绘制成图表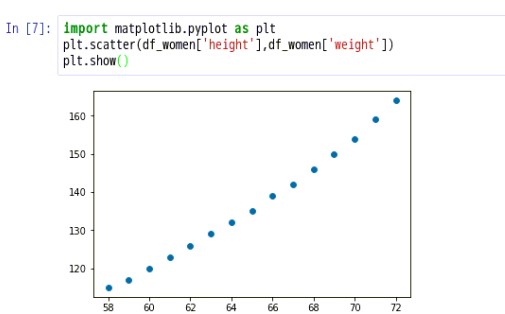
(4)数据准备
分别获得height和weight这两列数据,做模型预测使用

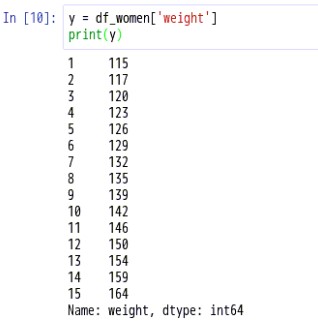
(5)模型类型的选择与参数的设置
5.1.导入构建模型需要的库,为模型增加常数项,即回归线在y轴上的截距
Statsmodels 是 Python 中一个强大的统计分析包,包含了回归分析、时间序列分析、假设检验等功能。
Statsmodels 在计量的简便性上是远远不及 Stata 等软件的,但它的优点在于可以与 Python 的其他的任务(如 NumPy、Pandas)有效结合,提高工作效率
结果如下所示: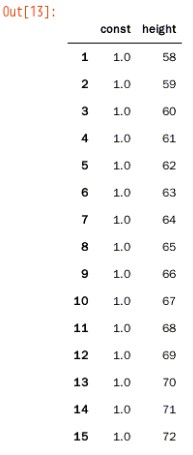
5.2.执行最小二乘回归
执行最小二乘回归,X可以是numpy array或pandas dataframe(行数为数据点个数,列数为预测变量个数),y可以是一维数组(numpy array)或pandas series
(6)训练具体模型及查看其统计量
6.1.使用OLS对象的fit()方法来进行模型拟合

6.2.查看模型拟合的结果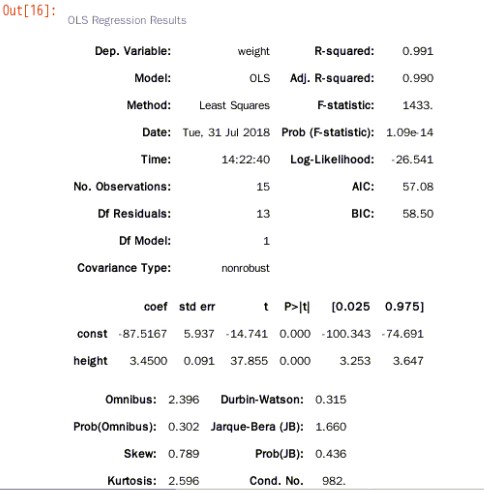
说明:初学者只关注 summary 结果中的判定系数,各自变量对应的系数值及 P 值即可。 R-squared 在统计学里叫判定系数,或决定系数,也称拟合优度,值在 0 到 1 之间,值越大,表示这个模型拟合的越好,这里 0.991 就拟合的很好
- coef:截距
- std err :是标准误差
- t 和 P:这是对每个系数做了个统计推断,统计推断的原假设是系数为 0,表示该系数在模型里不用存在,不用理解原理和具体过程,可以直接看 P 值,P 值如果很小,就推断原假设,即其实系数不为 0,该变量在模型中应该是存在的,如上面的 summary 结果,height的 P 值很小,说明这个自变量在模型里都是有意义的,都应该存在模型里。有些回归问题中,P 值比较大,那么对应的变量就可以扔掉






















6.3.查看最终模型的参数coef
6.4.查看判定系数
6.5.看对应的残差
残差表示真实值和模型拟合值的距离。
这里有 15个数据,也就有 15 个残差。
6.6.理论上残差应该服从正态分布,可以检验下
p 值很小,拒绝原假设,即残差不服从正态分布
6.7.查看残差的Durbin-Watson
德宾-沃森检验,简称D-W检验,是目前检验自相关性最常用的方法,但它只使用于检验一阶自相关性。因为自相关系数ρ的值介于-1和1之间,所以 0≤DW≤4。并且
DW=O=>ρ=1 即存在正自相关性
DW=4<=>ρ=-1 即存在负自相关性
DW=2<=>ρ=0 即不存在(一阶)自相关性
因此,当DW值显著的接近于O或4时,则存在自相关性,而接近于2时,则不存在(一阶)自相关性。这样只要知道DW统计量的概率分布,在给定的显著水平下,根据临界值的位置就可以对原假设H0进行检验。
结果=0.31538,所以残差序列存在自相关性
(7)模型预测

(8)模型评价


(9)模型优化与重新选择
numpy.column_stack(tup)[source]:Stack 1-D arrays as columns into a 2-D array.
numpy.power(x1, n):对数组x1的元素分别求n次方
9.1.模型优化与重新选择

9.2.对模型进行预测
9.3.查看参数
9.4.查看残差
9.5.查看残差的std
9.6.查看残差的Durbin-Watson统计量
结果=2.388205643,所以残差序列不存在自相关性
9.7.对优化后的模型作图

由此图得知,预测值和实际值更加接近。
至此,实验结束!

若有收获,就点个赞吧
0 人点赞
