// 获取hashCode "abc".hashCode();public int hashCode() {int h = hash;if (h == 0 && value.length > 0) {char val[] = value;for (int i = 0; i < value.length; i++) {h = 31 * h + val[i];}hash = h;}return h;}
- 31 是一个奇质数,如果选择偶数会导致乘积运算时数据溢出。
- 另外在二进制中,2个5次方是32,那么也就是 31 * i == (i << 5) - i。这主要是说乘积运算可以使用位移提升性能,同时目前的JVM虚拟机也会自动支持此类的优化。
1.Hash碰撞概率计算
想计算碰撞很简单,也就是计算那些出现相同哈希值的数量,计算出碰撞总量即可。这里的实现方式有很多,可以使用set、map也可以使用java8的stream流统计distinct。
private static RateInfo hashCollisionRate(Integer multiplier, List<Integer> hashCodeList) {int maxHash = hashCodeList.stream().max(Integer::compareTo).get();int minHash = hashCodeList.stream().min(Integer::compareTo).get();int collisionCount = (int) (hashCodeList.size() - hashCodeList.stream().distinct().count());double collisionRate = (collisionCount * 1.0) / hashCodeList.size();return new RateInfo(maxHash, minHash, multiplier, collisionCount, collisionRate);}
- 这里记录了最大hash和最小hash值,以及最终返回碰撞数量的统计结果。
2.单元测试
@Beforepublic void before() {"abc".hashCode();// 读取文件,103976个英语单词库.txtwords = FileUtil.readWordList("D:/test/103976个英语单词库.txt");}@Testpublic void test_collisionRate() {List<RateInfo> rateInfoList = HashCode.collisionRateList(words, 2, 3, 5, 7, 17, 31, 32, 33, 39, 41, 199);for (RateInfo rate : rateInfoList) {System.out.println(String.format("乘数 = %4d, 最小Hash = %11d, 最大Hash = %10d, 碰撞数量 =%6d, 碰撞概率 = %.4f%%", rate.getMultiplier(), rate.getMinHash(), rate.getMaxHash(), rate.getCollisionCount(), rate.getCollisionRate() * 100));}}
- 以上先设定读取英文单词表中的10个单词,之后做hash计算。
- 在hash计算中把单词表传递进去,同时还有乘积数;2, 3, 5, 7, 17, 31, 32, 33, 39, 41, 199,最终返回一个list结果并输出。
- 这里主要验证同一批单词,对于不同乘积数会有怎么样的hash碰撞结果。
测试结果
单词数量:103976乘数 = 2, 最小Hash = 97, 最大Hash = 1842581979, 碰撞数量 = 60382, 碰撞概率 = 58.0730%乘数 = 3, 最小Hash = -2147308825, 最大Hash = 2146995420, 碰撞数量 = 24300, 碰撞概率 = 23.3708%乘数 = 5, 最小Hash = -2147091606, 最大Hash = 2147227581, 碰撞数量 = 7994, 碰撞概率 = 7.6883%乘数 = 7, 最小Hash = -2147431389, 最大Hash = 2147226363, 碰撞数量 = 3826, 碰撞概率 = 3.6797%乘数 = 17, 最小Hash = -2147238638, 最大Hash = 2147101452, 碰撞数量 = 576, 碰撞概率 = 0.5540%乘数 = 31, 最小Hash = -2147461248, 最大Hash = 2147444544, 碰撞数量 = 2, 碰撞概率 = 0.0019%乘数 = 32, 最小Hash = -2007883634, 最大Hash = 2074238226, 碰撞数量 = 34947, 碰撞概率 = 33.6106%乘数 = 33, 最小Hash = -2147469046, 最大Hash = 2147378587, 碰撞数量 = 1, 碰撞概率 = 0.0010%乘数 = 39, 最小Hash = -2147463635, 最大Hash = 2147443239, 碰撞数量 = 0, 碰撞概率 = 0.0000%乘数 = 41, 最小Hash = -2147423916, 最大Hash = 2147441721, 碰撞数量 = 1, 碰撞概率 = 0.0010%乘数 = 199, 最小Hash = -2147459902, 最大Hash = 2147480320, 碰撞数量 = 0, 碰撞概率 = 0.0000%Process finished with exit code 0
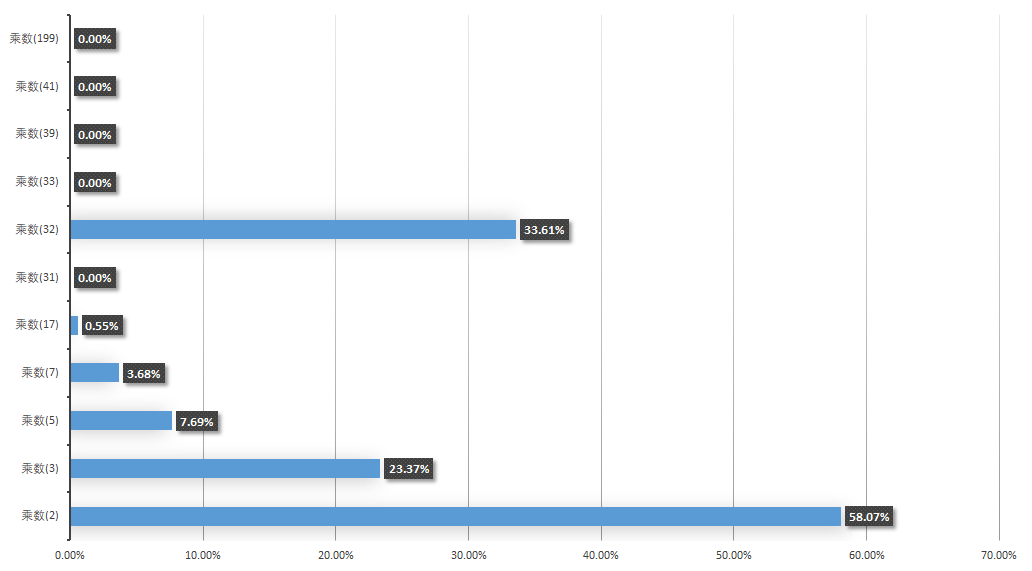
以上就是不同的乘数下的hash碰撞结果图标展示,从这里可以看出如下信息;
- 乘数是2时,hash的取值范围比较小,基本是堆积到一个范围内了,后面内容会看到这块的展示。
- 乘数是3、5、7、17等,都有较大的碰撞概率
- 乘数是31的时候,碰撞的概率已经很小了,基本稳定。
- 顺着往下看,你会发现199的碰撞概率更小,这就相当于一排奇数的茅坑量多,自然会减少碰撞。但这个范围值已经远超过int的取值范围了,如果用此数作为乘数,又返回int值,就会丢失数据信息。

若有收获,就点个赞吧
0 人点赞
