一、为什么使用扰动函数
在HashMap存放元素时候有这样一段代码来处理哈希值,这是java 8的散列值扰动函数,用于优化散列效果;
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}
理论上来说字符串的hashCode是一个int类型值,那可以直接作为数组下标了,且不会出现碰撞。但是这个hashCode的取值范围是[-2147483648, 2147483647],有将近40亿的长度,谁也不能把数组初始化的这么大,内存也是放不下的。
我们默认初始化的Map大小是16个长度 DEFAULT_INITIAL_CAPACITY = 1 << 4,所以获取的Hash值并不能直接作为下标使用,需要与数组长度进行取模运算得到一个下标值,也就是我们上面做的散列列子。
那么,hashMap源码这里不只是直接获取哈希值,还进行了一次扰动计算,(h = key.hashCode()) ^ (h >>> 16)。把哈希值右移16位,也就正好是自己长度的一半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了随机性。计算方式如下图;
- 使用扰动函数就是为了增加随机性,让数据元素更加均衡的散列,减少碰撞。
二、初始化容量为什么必须是2的倍数
在HashMap的初始化中,有这样一段方法; ```java public HashMap(int initialCapacity, float loadFactor) { … this.loadFactor = loadFactor; this.threshold = tableSizeFor(initialCapacity); }
- 阈值threshold,通过方法tableSizeFor进行计算,是根据初始化来计算的。- 这个方法也就是要寻找比初始值大的,最小的那个2进制数值。比如传了17,我应该找到的是32。计算阈值大小的方法;```javastatic final int tableSizeFor(int cap) {int n = cap - 1;n |= n >>> 1;n |= n >>> 2;n |= n >>> 4;n |= n >>> 8;n |= n >>> 16;//MAXIMUM_CAPACITY = 1 << 30return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;}
- MAXIMUM_CAPACITY = 1 << 30,这个是临界范围,也就是最大的Map集合。
- 为什么位置都在向右移位1、2、4、8、16,这主要是为了把二进制的各个位置都填上1,当二进制的各个位置都是1以后,就是一个标准的2的倍数减1了,最后把结果加1再返回即可。
那这里我们把17这样一个初始化计算阈值的过程,用图展示出来,方便理解;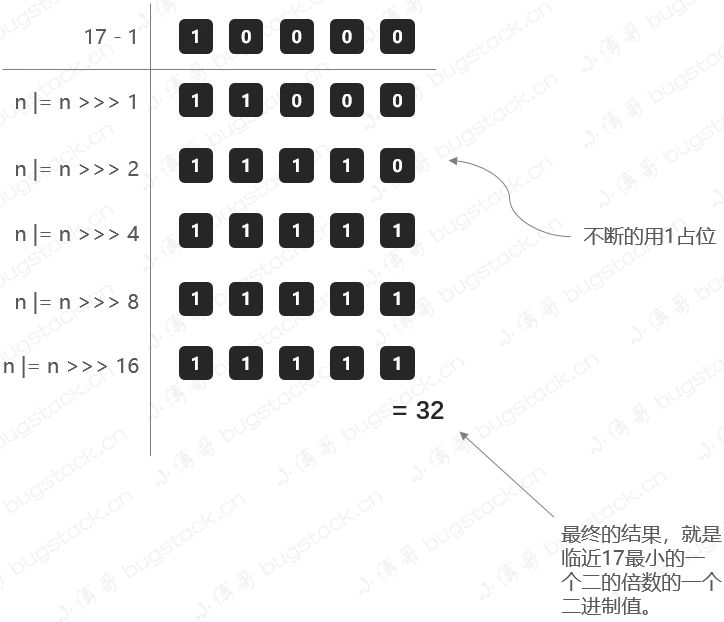
三、负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
负载因子是做什么的?
负载因子,可以理解成一辆车可承重重量超过某个阈值时,把货放到新的车上。
那么在HashMap中,负载因子决定了数据量多少了以后进行扩容。这里要提到上面做的HashMap例子,我们准备了7个元素,但是最后还有3个位置空余,2个位置存放了2个元素。 所以可能即使你数据比数组容量大时也是不一定能正正好好的把数组占满的,而是在某些小标位置出现了大量的碰撞,只能在同一个位置用链表存放,那么这样就失去了Map数组的性能。
所以,要选择一个合理的大小下进行扩容,默认值0.75就是说当阈值容量占了3/4时赶紧扩容,减少Hash碰撞。
同时0.75是一个默认构造值,在创建HashMap也可以调整,比如你希望用更多的空间换取时间,可以把负载因子调的更小一些,减少碰撞。

若有收获,就点个赞吧
0 人点赞
