Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片(“动态数组”),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
基本语法
- nil?初始化为零值?
- 为什么引用类型非得初始化,底层?
- 如何把握关键点,不长篇大论的说
- len与cap的作用:len到cap之间元素,就是,处于不可读取,但是可通过赋值进行添加的状态
- len和cap怎么确定?
- 通过定义获得的切片:
make ([]type, len, cap)—定义的时候,定义的多少就多少,没定义cap,就默认len=cap- 直接定义内容
[]type {...., ....},len=cap
- 通过截取获得的切片:
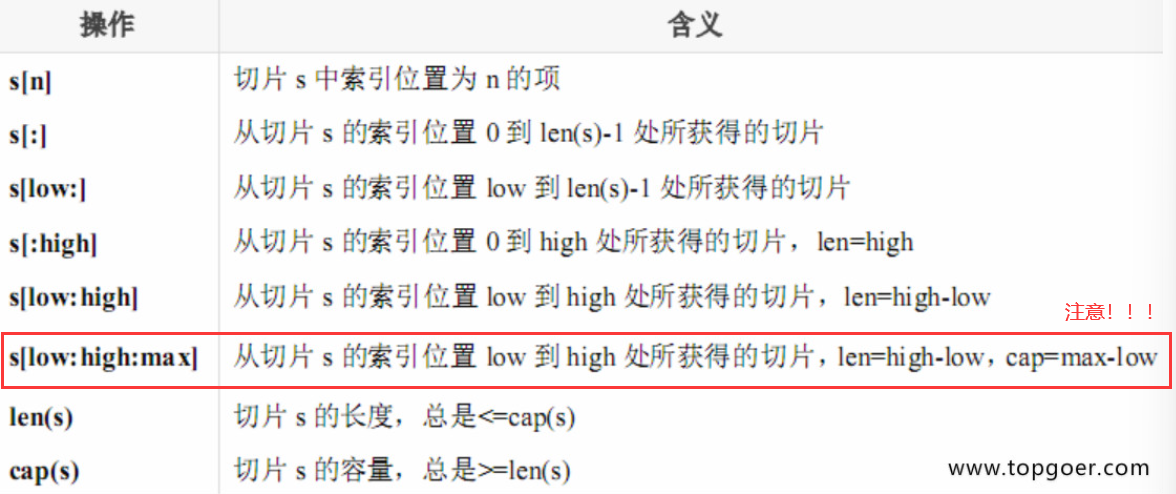
- cap的计算(原理)
- 实例分析:
**最难的——没有设置max的情况,,我们实例分析一下**data := []int{0,1,2,3,4,5,6,7,8,9}则<font style="color:rgb(36, 41, 46);">slice:= data[6:8]</font>,从第6位到第8位(返回6, 7),长度len为2, 最大可扩充长度cap为4(6-9)
- 通过定义获得的切片:
| 单个变量 | 多个变量 | ||
|---|---|---|---|
var |
只声明 | <font style="color:rgb(0, 0, 136);">var</font><font style="color:rgb(0, 0, 0);"> s_1 []type</font> |
1. 不同变量同一类型: <font style="color:rgb(0, 0, 136);">var</font><font style="color:rgb(0, 0, 0);"> s_1,s_2 []type </font>2. 不同变量不同类型(一般用于函数外):  |
| Note: 1. 并不推荐 **var** str []**string**,因为切片是引用类型,仅仅只是声明无初始化为零值,系统并未分配底层数组2. 仅声明,之后可以整体赋值,但是不可单独赋值 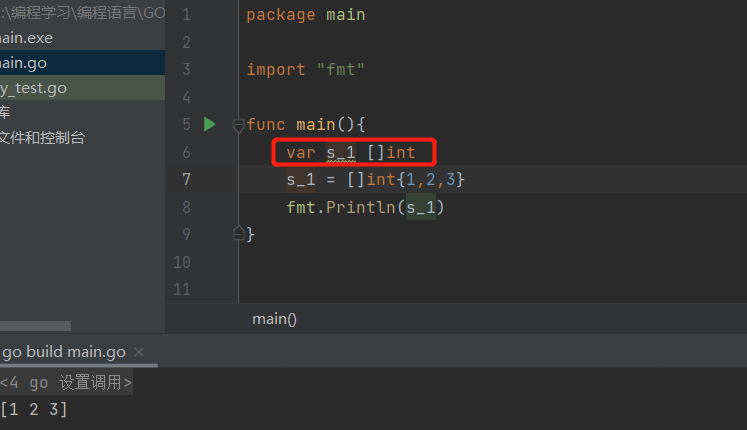 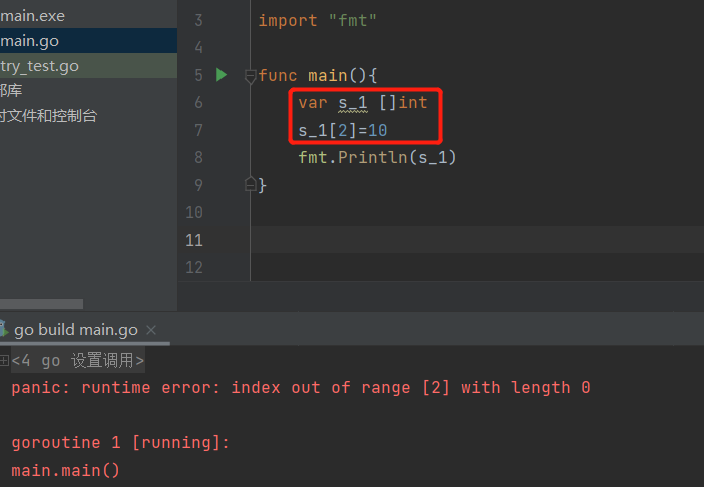 |
|||
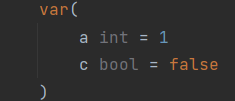
| ?初始化为零值 | <font style="color:rgb(0, 0, 136);">var</font><font style="color:rgb(0, 0, 0);"> v_name </font><font style="color:rgb(102, 102, 0);">=</font><font style="color:rgb(0, 0, 0);"> value</font> |
 |
|
:= |
?初始化 | <font style="color:rgb(51, 51, 51);">a := 50 </font> |
<font style="color:rgb(0, 0, 0);">a</font><font style="color:rgb(102, 102, 0);">,</font><font style="color:rgb(0, 0, 0);"> b</font><font style="color:rgb(102, 102, 0);">,</font><font style="color:rgb(0, 0, 0);"> c </font><font style="color:rgb(102, 102, 0);">:=</font><font style="color:rgb(0, 0, 0);"> </font><font style="color:rgb(0, 102, 102);">5</font><font style="color:rgb(102, 102, 0);">,</font><font style="color:rgb(0, 0, 0);"> </font><font style="color:rgb(0, 102, 102);">7</font><font style="color:rgb(102, 102, 0);">,</font><font style="color:rgb(0, 0, 0);"> </font><font style="color:rgb(0, 136, 0);">"abc"</font>(c语言是不可这样的) |
声明
基本语法:**var** 变量名 []类型
初始化
- 全局
var s_1 =/ 局部s := - 等式右边
- 初始化为零值
- 设定len和cap:
make ([]type, len, cap) - 不设定 :
[]type{}
- 设定len和cap:
- 初始化
- 直接定义内容
[]type {...., ....} - 截取别的数组
other_s [a:b:c](a,b,c皆可省略)
- 直接定义内容
- 初始化为零值
- 如果是二位数组,目前不知道make怎么弄,其他依葫芦画瓢
data := [][]int{{1,2,3},{4,5,6}}
:::info 空切片
:::
- 一个切片在未初始化之前,系统默认初始化为 nil,长度为 0,若打印,则为
<font style="color:rgb(51, 51, 51);">[]</font>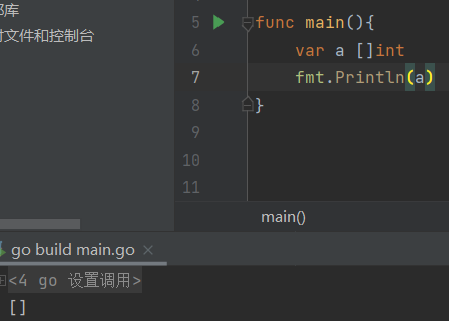
- 若初始化为对应类型的零值后,打印,则元素全为零值
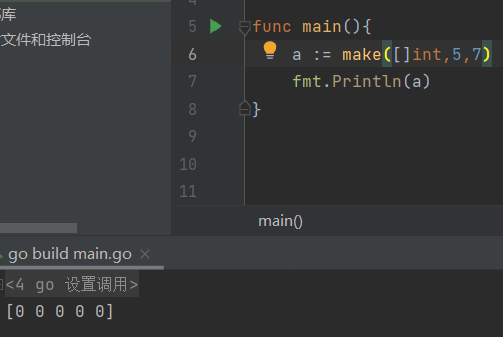
:::info 和数组的比较
:::
- 能否扩容
- 值能否比较
- 引用类型,与底层数组联系
数组/切片的截取
- cap的计算
- 索引过去自己看
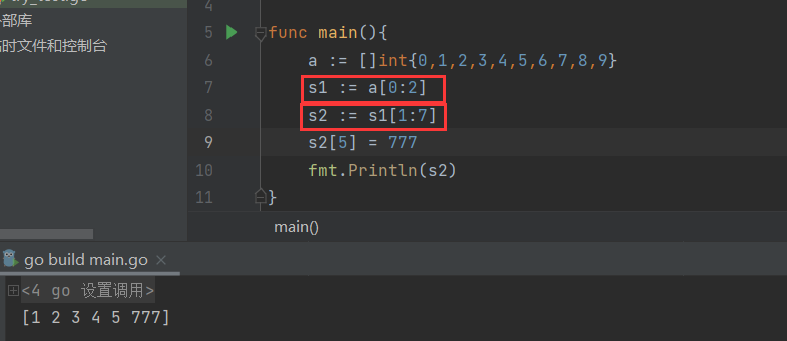
- 实例分析:
**最难的——没有设置max的情况,,我们实例分析一下**data := []int{0,1,2,3,4,5,6,7,8,9}则<font style="color:rgb(36, 41, 46);">slice:= data[6:8]</font>,从第6位到第8位(返回6, 7),长度len为2, 最大可扩充长度cap为4(6-9)
- 切片之间的截取可“超范围”,始终联系的是一个底层数组
通过make来声明切片
- 全局变量——
var slice_1 = make([]type, len, cap) - 局部变量——
slice_1 := make([]type, len,cap) - len与cap
- len(slice)是数组的长度,cap(slice)是数组的容量,
- len(slice) <= cap(slice) = max{len(slice)} = len( arr )(若引用数组来创建切片)
- 其中 capacity 为可选参数。若省略 cap,相当于 cap = len。
- 优点:
系统自动分配底层数组,且可自主设定len和cap,且初始化对应类型的为零值
:::info 实例
:::
package mainimport "fmt"func main() {s1 := []int{0, 1, 2, 3, 8: 100} // 通过初始化表达式构造,可使用索引号。fmt.Println(s1, len(s1), cap(s1))s2 := make([]int, 6, 8) // 使用 make 创建,指定 len 和 cap 值。fmt.Println(s2, len(s2), cap(s2))s3 := make([]int, 6) // 省略 cap,相当于 cap = len。fmt.Println(s3, len(s3), cap(s3))}

赋值
- 注意不像python用方括号和花括号区分不同组合类型,而通过开头区别,开头是数组/切片的一部分,
- 数组
[...]int {1,2,3,4,5} - 切片
[]int{1,2,3,4,5}
- 另一方面,
[]就是那的一个符号,是空的,切片不需要说明长度数组和切片在格式上,差别就在这,数组的[]可以塞数字or...
:::info
错误点::::
a = {1,2,3,4}
二维切片
切片类型——<font style="color:rgb(36, 41, 46);">[][]T</font>,是指元素类型为 <font style="color:rgb(36, 41, 46);">[]T </font>。
package mainimport ("fmt")func main() {data := [][]int{{1,2,3},{4,5,6}}data_1 := [][]int{{1, 2, 3},{100, 200},{11, 22, 33, 44},}fmt.Println(data)fmt.Println(data_1)}

看,多维切片还可以不同维度,有不同维数
内建函数
!append函数(已更新)
与其说是增添函数,不如说是切片拼接函数
:::info 可以加上什么?在哪加?
:::
- 末端添加
- 可以加什么?
- 不定参数列表
append(slice_1, elems_1...)比如切片之类的,注意后面三个点号,不可缺 - 单个元素
append(slice, elem_1, elem_2) []Type
- 不定参数列表
- 本质是:拼接切片a和b
如 c := append(a, b...)//加切片,实质是拼接切片a和b
package mainimport ("fmt")func main() {var a = []int{1, 2, 3}fmt.Printf("slice a : %v\n", a)var b = []int{4, 5, 6}fmt.Printf("slice b : %v\n", b)//加切片,实质是拼接切片a和b,注意后面三个点不可缺!!!c := append(a, b...)fmt.Printf("slice c : %v\n", c)//加元素d := append(c, 7)fmt.Printf("slice d : %v\n", d)//加多个元素e := append(d, 8, 9, 10)fmt.Printf("slice e : %v\n", e)}

:::info NOTE
:::
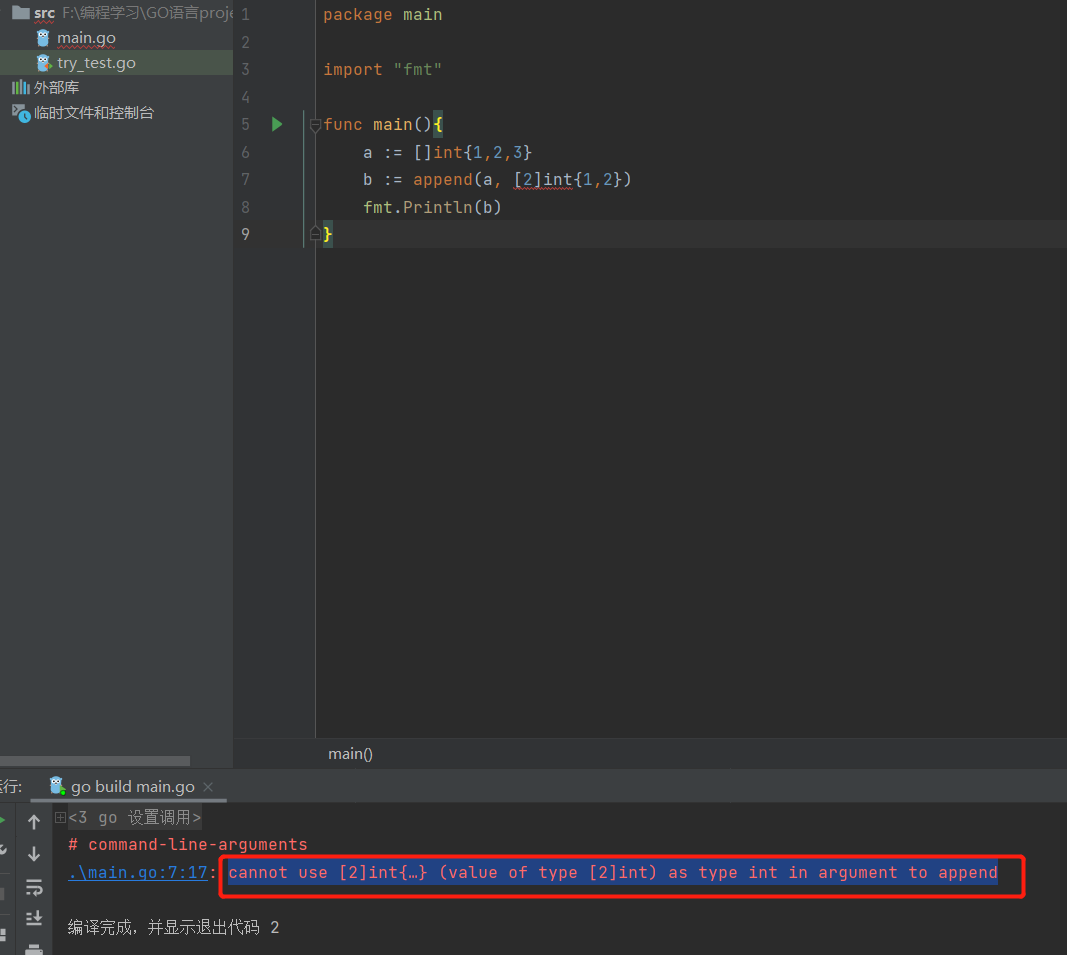
- 不可加数组
- 是否创建新切片
- 假如是
x = append(x []Type, elems ...Type) []Type超过容量会创建新切片,但&x是不变的
- 假如是
package mainimport "fmt"func main(){var a = []int{1, 2, 3}fmt.Printf("slice a : %v\n", a)var b = make([]int,3,7)b = []int{4, 5, 6}fmt.Printf("slice b : %v\n", b)fmt.Printf("slice b : %p\n", &b)fmt.Println("没超容量")b = append(b,a...)fmt.Printf("slice b : %v\n", b)fmt.Printf("slice b : %p\n", &b)fmt.Println("超过容量")b = append(b,a...)fmt.Printf("slice b : %v\n", b)fmt.Printf("slice b : %p\n", &b)}
结果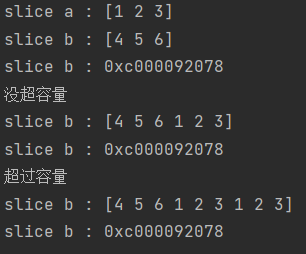
2. 假如是`y = append(x []Type, elems ...Type) []Type`&x与&y绝对不相同,且如果x后续没用到,会被垃圾回收

!copy函数
虽然是叫copy函数,但不产生新的切片,只是用一个切片去覆盖另一个切片
- 功能:copy(s1, s2) 本质是覆盖,用s2来覆盖s1,能覆盖多少是多少(=复制长度以len小的为准)
- 作用对象:切片
- 函数签名:
func copy(dst, src []byte) int,返回的是复制的长度(但很多时候不去接受返回值)
package mainimport "fmt"func main() {src := []byte("hello, world")dst := make([]byte, len(src))n := copy(dst, src)fmt.Printf("Copied %d bytes: %s\n", n, dst)//结果:Copied 12 bytes: hello, world}
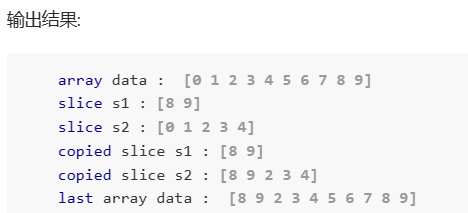
package mainimport ("fmt")func main() {data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}fmt.Println("array data : ", data)s1 := data[8:]s2 := data[:5]fmt.Printf("slice s1 : %v\n", s1)fmt.Printf("slice s2 : %v\n", s2)copy(s2, s1)fmt.Printf("copied slice s1 : %v\n", s1)fmt.Printf("copied slice s2 : %v\n", s2)fmt.Println("last array data : ", data)}
结果
!与赋值的差别
| a与b | 值类型 | 引用类型 |
|---|---|---|
a=b |
a与b不相关(只赋值值层面,不复制内存层面) | a与b共享一个底层数据 |
copy(a,b) |
无 copy函数只支持切片 |
a与b不相关(只赋值值层面,不复制内存层面) |
package mainimport "fmt"func main() {s1 := []int{1, 2, 3}s2 := []int{4, 5, 6}// s1和s2共享同一个底层数组s1 = s2s2[1] = 100fmt.Println(s1) // 输出 [4 100 6]fmt.Println(s2) // 输出 [4 100 6]// 将s2中的元素复制到s1中生成一个新的底层数组s1 = make([]int, len(s2))copy(s1, s2)s2[1] = 200fmt.Println(s1) // 输出 [4 100 6]fmt.Println(s2) // 输出 [4 200 6]fmt.Println("-------------------")a:=[5]int{1,2,3,4,5}b:= ab[2]= 8fmt.Println(a, b) //结果:[1 2 3 4 5] [1 2 8 4 5]}
- 现象
- 用
=:可以看出,对s2进行修改,也会影响s1的值- why?—对于引用类型变量,用赋值运算符
<font style="color:#AD1A2B;">=</font>,会复制原变量的地址
- why?—对于引用类型变量,用赋值运算符
- 用
copy:对s2修改,不会影响s1
- 用
原理
切片与底层数组(yyds)
切片的内存布局
:::info 切片的内存布局
:::
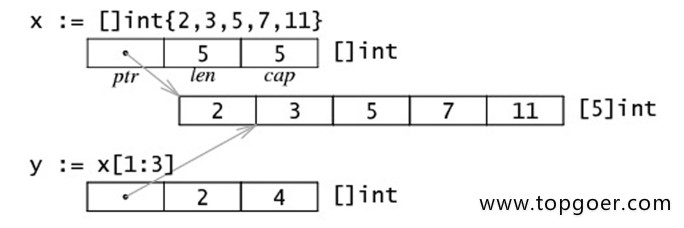
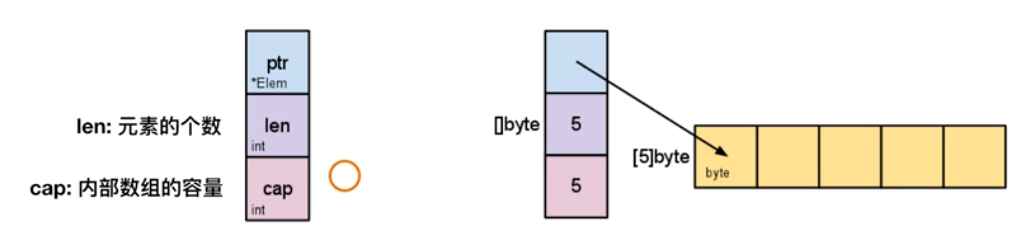
- 本质:
- 看起来是个可变长的数组,但本质是个结构体,包括三个基本元素:指向底层数组的指针*prt,len 和 cap,因此切片是引用类型。但自身是结构体,值拷贝传递。
- 所谓的底层数组,是切片的共享存储结构
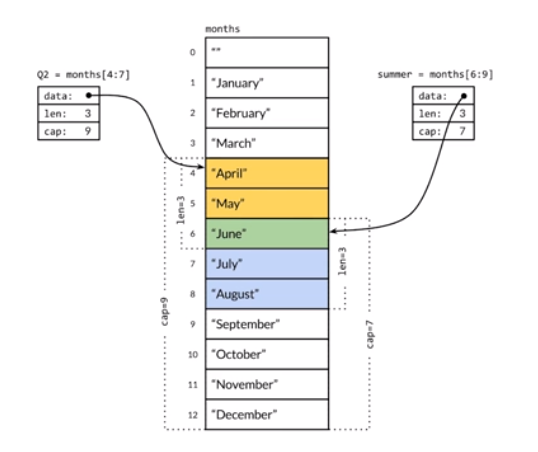
- 比喻:
- 底层数组是母鸡,切片是小鸡,小鸡是归母鸡管➡切片是对数组的引用
- 小鸡是是母鸡的孩子,潜力无限,能跑能跳
- 小鸡与母鸡一家亲,变化保持同步(切割的部分)
底层数组是怎么产生的?
:::info 先创建数组,再用切片截取,这个数组就是底层数组
:::
package mainimport ("fmt")func main() {d := [5]struct {x int}{}s := d[:]//s是切片,d是数组d[1].x = 10//修改数组s[2].x = 20//修改切片fmt.Println(d)fmt.Printf("%p, %p\n", &d, &d[0])}

结论
- 类型除了int/float/string,还可以是结构体
- 可以看出底层数组与切片同步变化
:::info
若直接创建 slice 对象,则自动分配底层数组。:::
两种方式:直接初始化 / 通过make函数
package mainimport "fmt"func main() {s1 := []int{0, 1, 2, 3, 8: 100} // 通过初始化表达式构造,可使用索引号。fmt.Println(s1, len(s1), cap(s1))s2 := make([]int, 6, 8) // 使用 make 创建,指定 len 和 cap 值。fmt.Println(s2, len(s2), cap(s2))s3 := make([]int, 6) // 省略 cap,相当于 cap = len。fmt.Println(s3, len(s3), cap(s3))}
什么时候切片会摆脱底层数组?
- 首先明确底层数组cap是多少
- 若超出cap,则按切片扩容策略进行扩容
cap的计算
| 语法 | cap | |
|---|---|---|
| 声明 | var关键字: **var** str []**string**/s2 := []**<font style="color:rgb(51, 51, 51);">int</font>**{} |
len = cap = 0,之后按切片扩容策略 |
make函数: var a []int = make([]int, len, cap)/ a := = make([]int, len, cap) |
1. 直接说明cap 2. 若省略cap,则len = cap |
|
| 初始化 | 直接初始化: 如s1 := []int{0, 1, 2, 3, 8: 100} |
系统自动分配底层数组, len = cap = 9 |
| 引用数组: 1. s := arr[:]2. s := arr[low:high]3. s := arr [low:]4. s := arr[:high]5. s := arr[low:high:max] |
max是容量,后面有一小节说明了 1. 说明了max 则len = high-low;cap = max-low 2. 没说max **则 len = high-low; cap = len(arr) - low (cap = 从截取点出发,包括头和尾,看到底层数组尾部,有几个元素) **换而言之,b对cap没有限制性 默认: 没说low,low = 0; 没说high, high = len(arr) — 1 |
|
| append函数 | new_sliver = append(s1, s2) | 切片扩容策略,见下方 |
| copy | copy(s1, s2)——把s2覆盖到s1 | copy函数不影响cap |
切片扩容策略
:::info 实例1——超出cap会发生什么?
:::
package mainimport ("fmt")func main() {data := [...]int{0, 1, 2, 3, 4, 10: 77}s := data[:2:3]//data是底层数组,s是切片,且规定了cap(s)=3<cap(data)=11s = append(s, 100, 200) // 一次 append 两个值,超出 s.cap 限制。fmt.Println(s, data) // 重新分配底层数组,与原数组无关。fmt.Println(&s[0], &data[0]) // 比对底层数组起始指针。}
- 结果:并未同步,且 起始指针/地址 也变了
 赋值超出slice.cap限制(例子为append方法,其他方法也一样),就会重新分配底层数组,即便原数组并未填满。
赋值超出slice.cap限制(例子为append方法,其他方法也一样),就会重新分配底层数组,即便原数组并未填满。 - 比喻:小鸡经历磨练,升级了,翅膀硬了,变成公鸡🐓了
- 经验:通常以 2 倍容量重新分配底层数组。在大批量添加数据时,建议一次性分配足够大的空间,以减少内存分配和数据复制开销。或初始化足够长的 len 属性,改用索引号进行操作。及时释放不再使用的 slice 对象,避免持有过期数组,造成 GC 无法回收。
:::info 实例2——切片扩容规律
:::
package mainimport ("fmt")func main() {s := make([]int, 0, 1)c := cap(s)for i := 0; i < 50; i++ {s = append(s, i)if n := cap(s); n > c {fmt.Printf("cap: %d -> %d\n", c, n)c = n}}}

解释:
- 切片扩容策略
| 若 | 则扩容的时候 | 实例 |
|---|---|---|
| cap<1024 | cap就会以2倍容量,进行扩容,len就是加多少是多少 | 看实例里,2,4,8,16,32 足以证明 |
| cap>1024 | cap就会以1.25倍,增加容量,len就是加多少是多少 |
- 为什么n和c不同?
切片s经过append扩容之后,底层数组也扩容了,只是c := cap(s)只执行一次,后来通过if 语句结构体里有个c = n 衔接上了
:::info 举一反三
:::
为什么要对切片进行扩容的时候是s=append(s, 1,2,3)而不是append(s, 1,2,3)?
answer:
我们知道,切片的本质是结构体,扩容时,指针的指向的地址可能发生变化,如果超出cap,地址就会发生变化,没超出就不会,索性go语言要求append产生新的slice,创建新的空间,进行值拷贝
应用
遍历/访问
切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制。
切片做函数参数
func name (x []int)int{...}
唯一要注意的是,切片做参数,是引用传递,和数组不同,是可修改的
修改
- 修改什么?
- 元素,key——底层数组与切片同步变化(切割的部分)
- 长度,key——切片扩容策略
- 方式
- 下标 + 赋值
- 内建函数 append/copy
- 数组/切片截取
- 指针
package mainimport "fmt"func main() {s := []int{0, 1, 2, 3}p := &s[2] // *int, 获取底层数组元素指针。*p += 100fmt.Println(s)}

- 长度
- 方法:
主要通过append函数和截取来改变切片长度 - 切片扩容策略
- cap的计算
- 若超出底层数组cap,则会重新分配数组
- 方法:
字符串与切片
截取
string底层就是一个byte的数组,因此,也可以进行切片操作。
package mainimport ("fmt")func main() {str := "hello world"s1 := str[0:5]fmt.Println(s1)s2 := str[6:]fmt.Println(s2)}

修改字符串
string本身是不可变的,因此要改变string中字符,要进行强制类型转换,变成元素类型为byte的切片(纯英文),再换回string
package mainimport ("fmt")func main() {str := "Hello world"s := []byte(str) //中文字符需要用[]rune(str)s[6] = 'G's = s[:8]//截取s = append(s, '!')str = string(s)fmt.Println(str)}
:::info
含有中文字符串:则转换成<font style="color:rgb(36, 41, 46);">[]rune</font>
:::
package mainimport ("fmt")func main() {str := "你好,世界!hello world!"s := []rune(str)s[3] = '够's[4] = '浪's[12] = 'g's = s[:14]str = string(s)fmt.Println(str)}

练习
产生一个一定范围的随机数,并要求每个位的数值由大到小
- 产生一个一定范围的随机数
随机数我目前学的,只能定上限,下限不能设置,所以我采用——无限for循环 + if—break语句 - 要求随机数越高位,数值越大
看看例子的取值方法
package mainimport ("fmt""math/rand""time")func main(){num := sort()fmt.Println("num=",num)}func sort()(num int){rand.Seed(time.Now().UnixNano())for{num = rand.Intn(10000)if num>999 {n1 := num/1000n2 := (num-n1*1000)/100n3 := (num-n1*1000-n2*100)/10n4 := num-n1*1000-n2*100-n3*10if n1>n2&&n2>n3&&n3>n4 {break}}}return}

若有收获,就点个赞吧
0 人点赞
