堆栈
什么是堆栈
- CPU内部有ALU、寄存器和时钟,寄存器临时存储数据,为了实现更复杂的运算,需要更多空间,又不能加很多寄存器,此时CPU就需要一个助理,最关键的要求是读写速度要快——内存,于是应聘上岗

- 内存中划出一个专门的区域来临时存储数据——栈,也叫“堆栈”,还有另一个区域叫“堆”,和栈的特性很不一样

堆栈怎么运行?
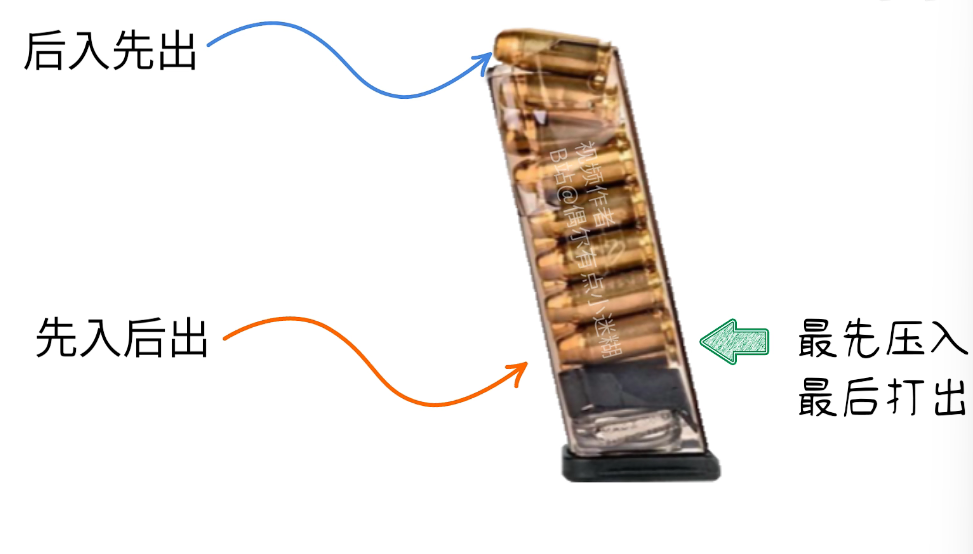
怎么运行呢?——先入后出,后入先出,和弹夹一样
堆栈有栈底和栈顶,栈底是固定不动的,栈顶是活动的,当堆栈无数据的时候,栈底和栈顶是重合的,当有数据进来的时候,栈顶就往上移动
 有以下两个操作
有以下两个操作
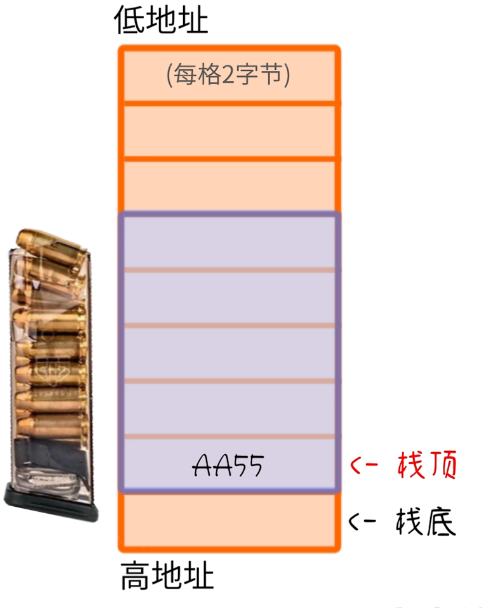
- 放入一个数据——这个动作加“压栈/入栈/Push”
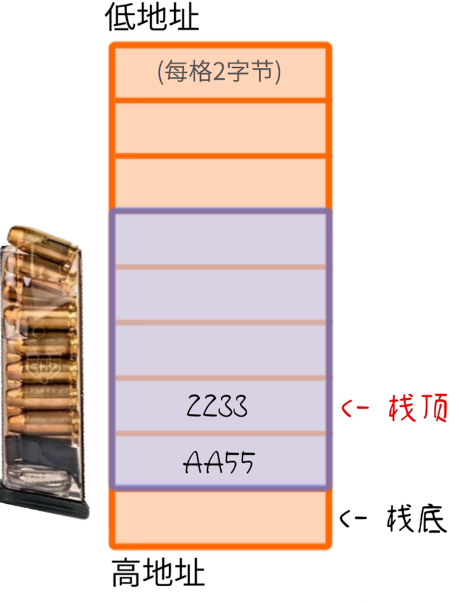
- 取出一个数据,把数据复制到CPU寄存器中——这个动作叫“弹栈/出栈/POP”(出栈后这个数据还放在堆栈里,但是已经被当作垃圾了)
- 堆栈里的数据必须先入后出,不可绕过调用
堆栈和函数的调用
- 程序临时调用另一个函数叫——函数跳转和返回
- 程序临时调用另一个函数,返回完后,需要记下,接下来执行什么?那么就要记下这个执行命令的地址,堆栈就需要把这个地址在调用的时候,压栈;程序返回之后,弹栈;为啥非要用堆栈,而不是随便一块内存地址呢?
——实际的程序中,函数调用都是嵌套的,函数的跳转和返回都符合先入后出的顺序,这正好和堆栈运行方式契合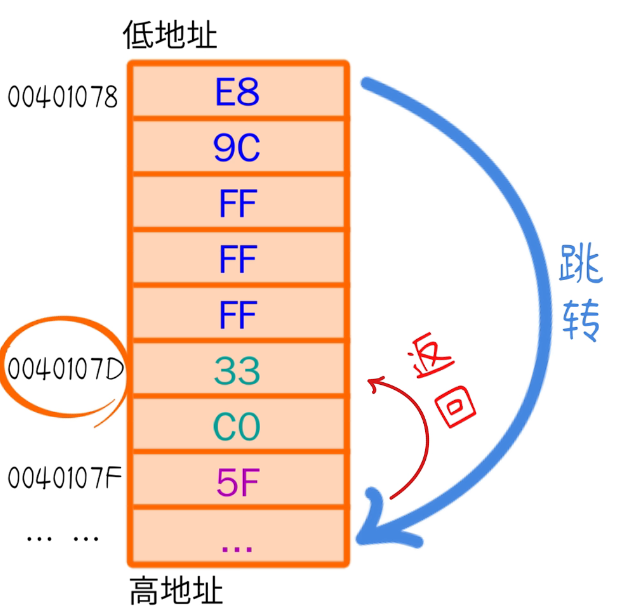
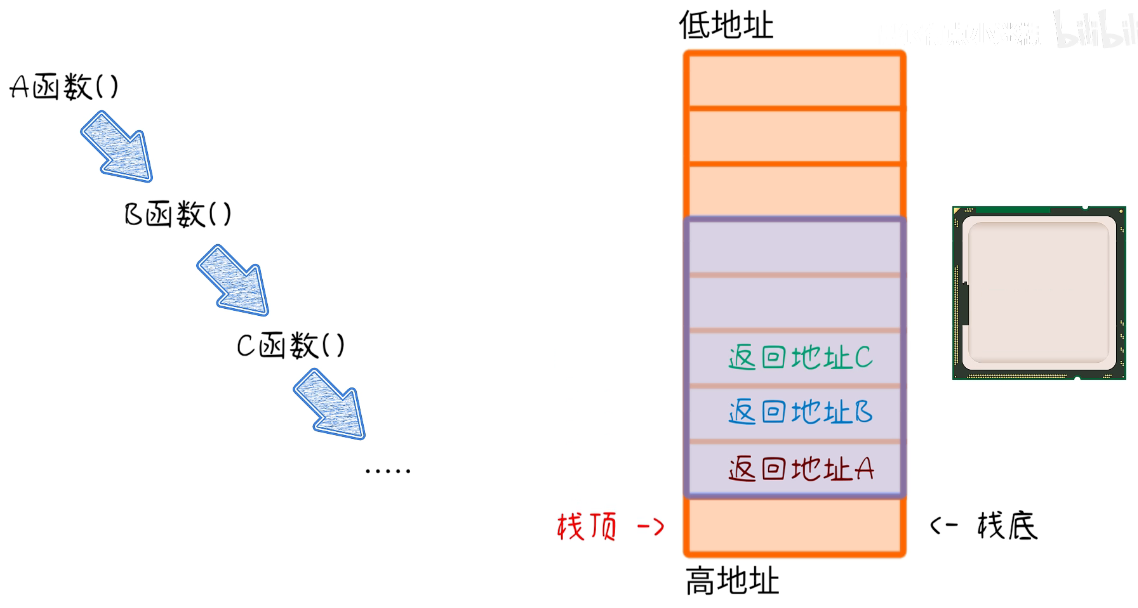
NOTE:假如函数无限调用,不返回,那会咋样?——堆栈马上就爆了,这就叫堆栈溢出,常见于函数递归调用的错误
递归
- 递归就是自己调用自己
- 只递不归会导致程序崩溃,所以需要终止条件
上面地堆栈讲过,不停地调用,只压栈不弹栈,就会堆栈溢出,操作系统就会让它强行终止,报错 - 实例(python)
这个例子很简单,但可以注意到,其实f(x)的实体并未给出,给的是f(x)和返回f(x),确实很数学里的等差数列/等比数列非常地像

哈希函数
- 哈希是hash英译,意思是”把东西弄糟弄乱“,所以哈希函数又称为散列函数,杂凑函数
- 功能:输入数据,生成整数
- 特点
- 不同参数->不同整数
- 同样参数->同样整数(强调时间上的不变性)
- 速度极快
- 应用
借助哈希函数,就可以实现数据到存储位置的一对一对应,从而把数据(西瓜…商品)的属性(价格)放进一张表里,就叫哈希表/散列表(python的字典用的哈希表) - 哈希函数的内部实现
- 实际哈希函数其实只是具有以上两种特点的一类函数,并不只是一个算法,比较经典的有SHA-256,MD5
- 听起来高深,但,技术是要为现实服务的,抛开希求谈技术方案都是耍流氓,我们还可以自己设计一个简易的哈希算法——平方取中法
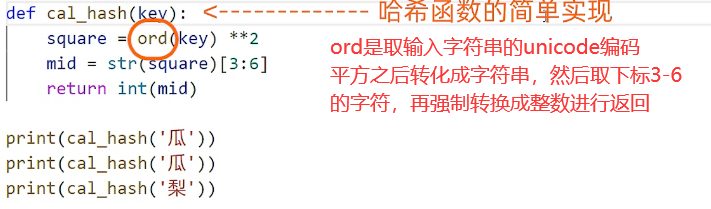
结果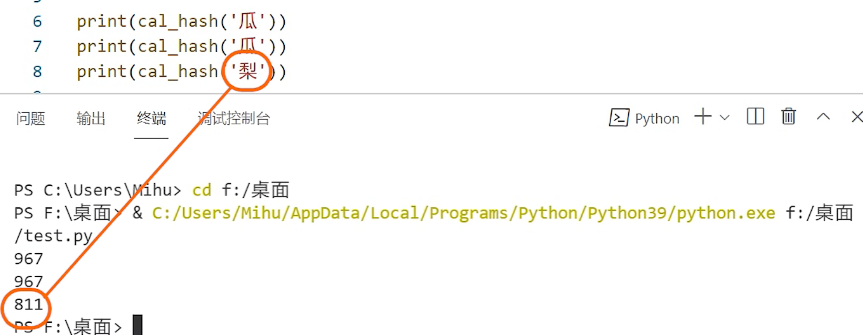
- 冲突
- 参数不同,结果相同的现象叫冲突
- 任何算法都不能保证100%的不冲突,只有好与坏的差别,能设计这个的都是精英
- 实例2——如何验证客户端在服务器下载的文件与服务器的文件相同?
- 已经服务器网站,提供MD5 Sum
- 打开命令提示符(这里是powerShell)
- 输入
certuil-hashfile ...生成的文件 MD5- certuil

- -hashfile 标明要生成文件的哈希值
- 后面那一串,是把下载的文件拖曳到这,就自动生成了一段代码

- MD5
指定使用MD5算法
- certuil
- 结果
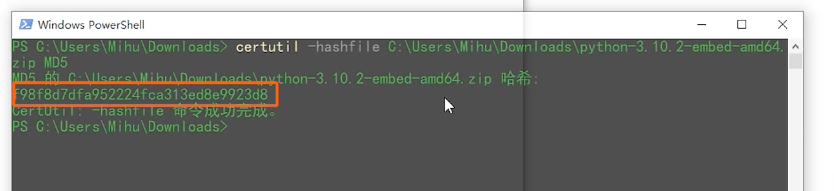
- 与服务器提供的值进行比较
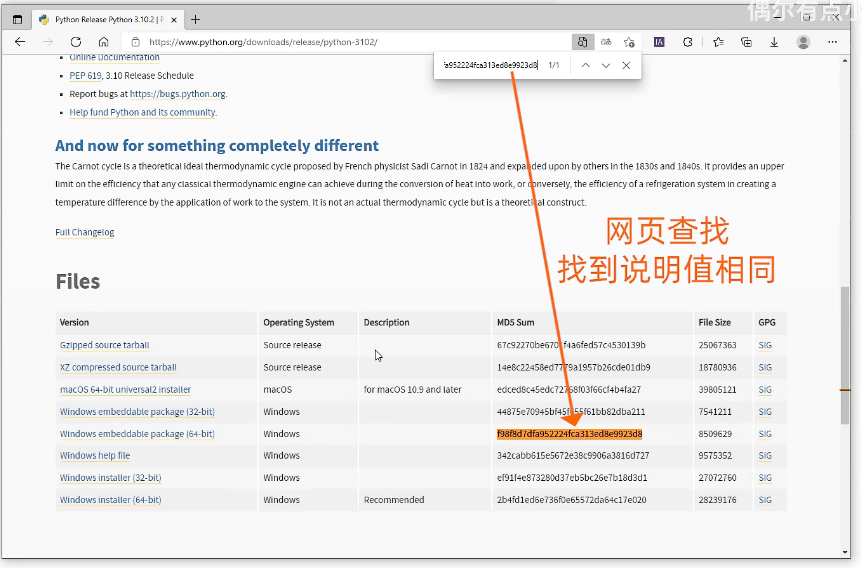
若结果相同,那么下载的文件就是服务器文件相同

若有收获,就点个赞吧
0 人点赞
