正则表达式是一种进行模式匹配和文本操纵的复杂而又强大的工具。虽然正则表达式比纯粹的文本匹配效率低,但是它却更灵活。按照它的语法规则,随需构造出的匹配模式就能够从 原始文本中筛选出几乎任何你想要得到的字符组合。
Go 语言通过 regexp 标准包为正则表达式提供了官方支持,如果你已经使用过其他编程语言提供的正则相关功能,那么你应该对 Go 语言版本的不会太陌生,但是它们之间也有一些小的差 异 ,因为 Go 实 现的是 RE2 标 准 , 除 了 \C , 详细的语法描述参考 : http://code.google.com/p/re2/wiki/Syntax 与strings包的对比:其实字符串处理我们可以使用 strings 包来进行搜索(Contains、Index)、替换(Replace)和解析(Split、Join)等操作,但是这些都是简单的字符串操作,他们的搜索都是大小写敏感,而且固定的字符串,如果我们需要匹配可变的那种就没办法实现了,当然如果 strings 包能解决你的问题,那么就尽量使用它来解决。因为他们足够简单、而且性能和可读性都会比正则好。 ### 使用步骤 | | 步骤 | 实例: 在某string中找符合样式为a.b的字符串(点号表示任意字符) | | —- | —- | —- | | 1 | 引入包 |
 |
| 2 | 1. 解释规则
|
| 2 | 1. 解释规则 变量reg1 := 包.方法/函数(正则表达式) (最好用反引号...表示原生字符串 )2. 作用: 它会解析正则表达式,如果成功返回解释器,失败返回nil | 定义字符串变量
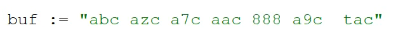
解释规则
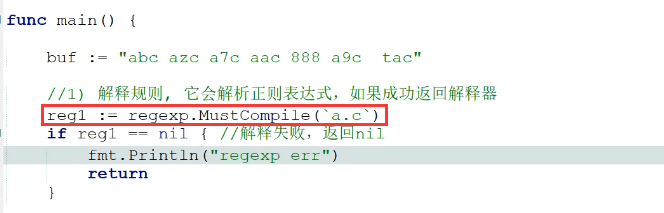
可查询返回的解释器,compile表示汇编,函数名叫必须汇编?reg是个啥(虽然我现在根本不懂)
 |
| 3 | 根据规则提取关键字信息
|
| 3 | 根据规则提取关键字信息返回 := reg1.方法(被搜索字符串, 范围) | 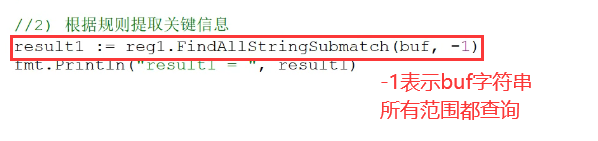
这个方法名还挺接地气,
findallstringmatch,-1表示所有范围是所有,1表示从左往右搜到一个就行了,返回的是符合样式的一个个字符串组成的切片 |
上面例子里,如果改变正则表达式,还可以
1. 样式为
|
上面例子里,如果改变正则表达式,还可以
1. 样式为a[0-9]c,意思是a和c中间是0-9的数字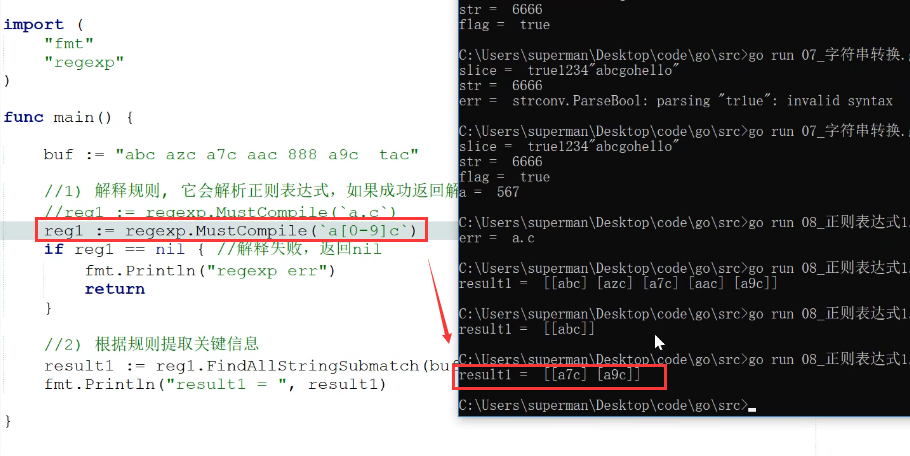 2. 样式为
2. 样式为a\dc,意思是a和c中间是整数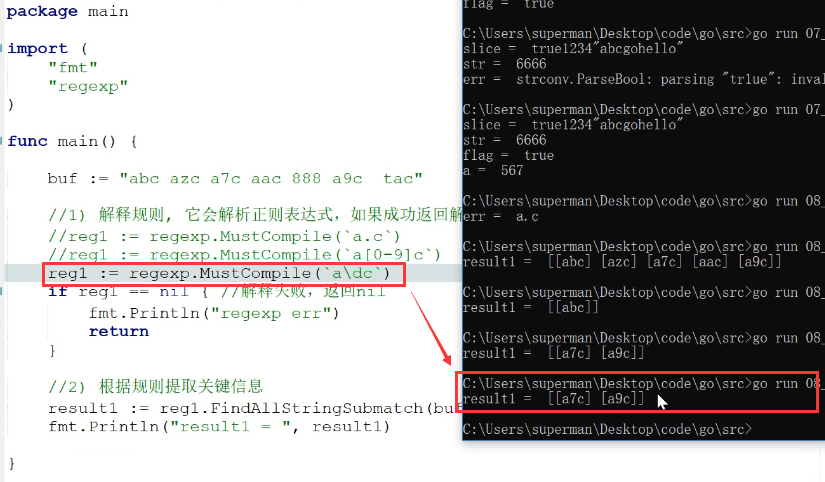 ### 正则表达式规则
不用特殊记,用到再查
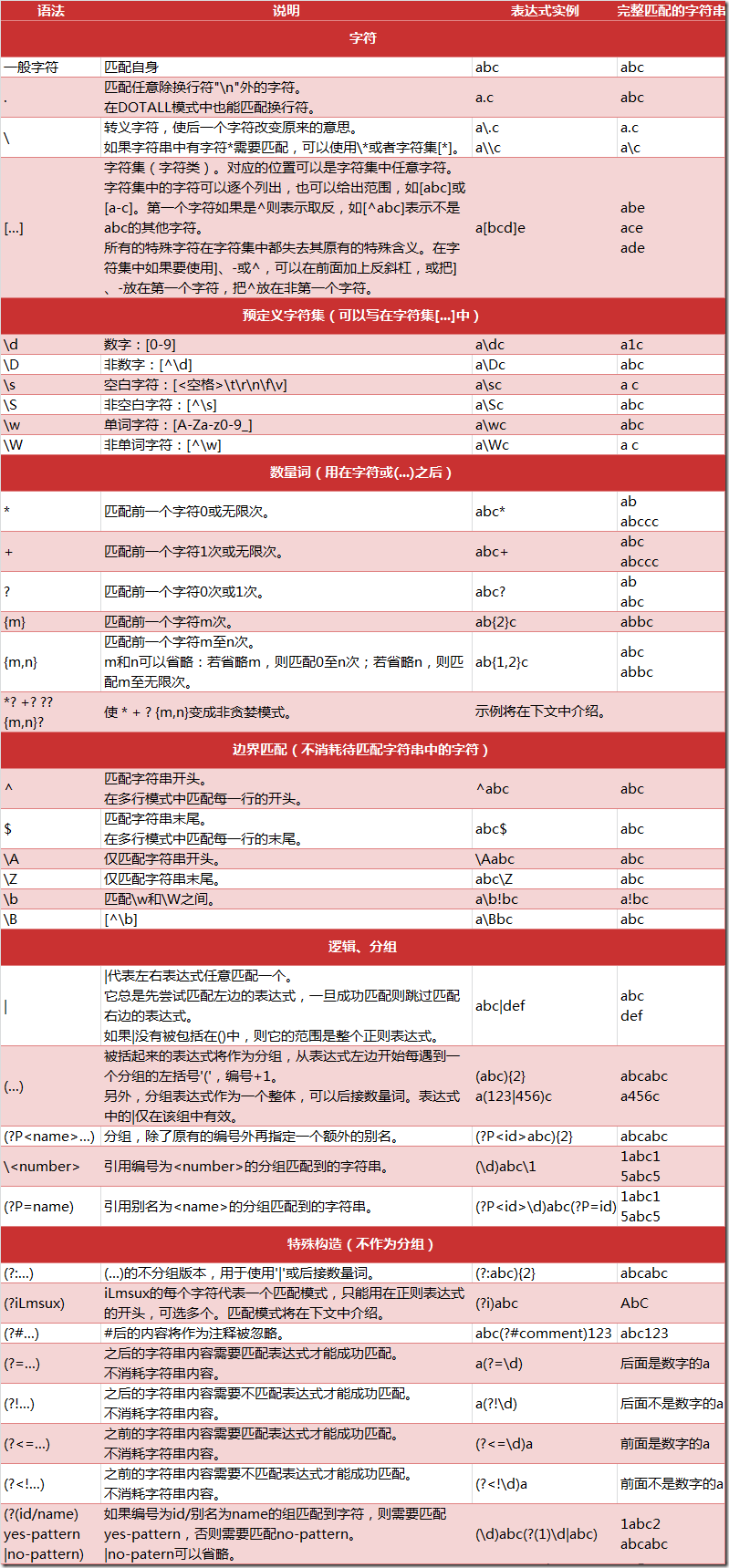
### 正则表达式规则
不用特殊记,用到再查
 ### 更多实例
正则表达式,虽然强大,但内容过于复杂,所有积累经验非常重要
### 更多实例
正则表达式,虽然强大,但内容过于复杂,所有积累经验非常重要
go
package main
//1.引入包,虽然会自动引入
import (
"fmt"
"regexp"
)
func main() {
//第二步:定义待搜索字符串,解析正则表达式,记得写reg为nil返回error
buf := "34.23 3424 feafs 324.432 34.44 213.ss sf23.23"
reg := regexp.MustCompile(`\d+\.\d+`) //\d表示整数,\d+的+表示一个或者无限个,\.表示点号
if reg == nil{
fmt.Println("error")
}
//第三步:提取关键信息,打印出来
result := reg.FindAllStringSubmatch(buf, -1) //FindAllStringSubmatch 比 FindAllString 就多在每一块再圈起来
fmt.Println("result = ", result)
}
### 简易网站爬虫
1. 提取网页源代码,复制
 2. 放进buf,记得两边反引号
2. 放进buf,记得两边反引号...框住
3. 代码基本与实例1相同,寻找样式为<div>...<div>的字符,此处我们只修改正则表达式
1. <font style="color:rgb(0,0,0);">exp2 := regexp.MustCompi</font>le((.?)
)`(.)
<font style="color:rgb(0,0,0);">表示要中间的内容,</font>(?s:(.))<font style="color:rgb(0,0,0);">表示跨行也可以</font>
2.(`(.)
)表示要中间的内容| content | 正则表达式 | 结果 | |
|---|---|---|---|
| 1 |  |
((.*) ) 表示要中间的内容 |
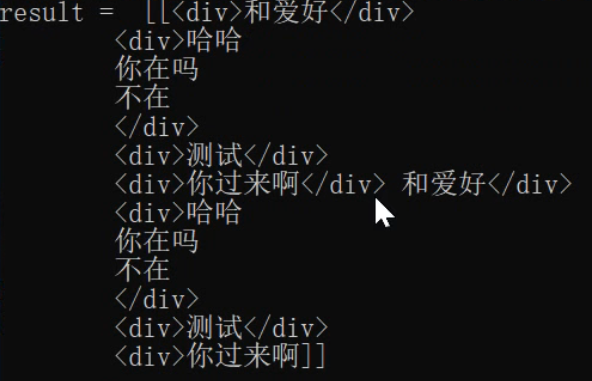
result=[[<div>和爱好</div>和爱好] [<div>哈哈</div> 哈哈] [<div>测试</div> 测试] [<div>你过来啊</div> 你过来啊]] |
| 2 |  |
((?s:(.*)) ) s表示跨行也可以 |
 |
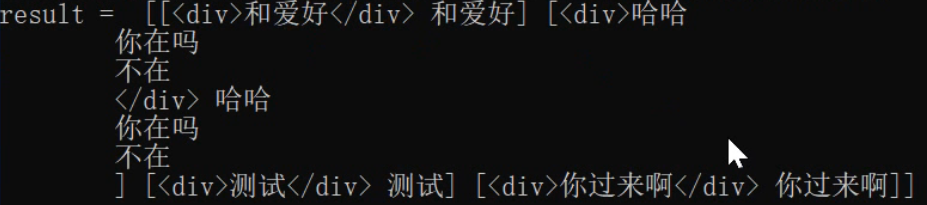
| 3 | 上同 | ((?s:(.?)) ) ?表示对前面字符进行匹配 |
 |
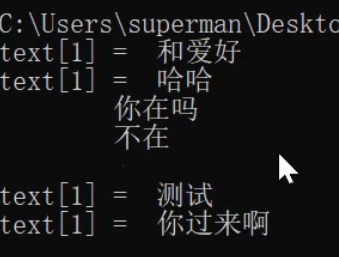
| 4 | 上同 | 过滤<> </> 继承上面的正则表达式,加上一个for循环  |
 |

若有收获,就点个赞吧
0 人点赞
