part 1 概要
| 基本概念 | 1. 函数的签名=? 2. 函数的组成、各个特点 3. 形参、返回值解析 4. 值传递与引用传递的区别是什么? |
| 函数类型 | 1. 如何运用函数类型? 2. 函数签名vs函数类型vs匿名函数 |
| 应用 | 1. 匿名函数, 1. 怎么用? 1. 可传递给变量、可做参数列表、可做返回值 2. 可即使使用 3. 可做闭包 2. 匿名函数vs普通函数??? 2. 函数递归 3. defer函数—延迟调用 4. 获取命令行参数 |
part 2 练习
- 对比
函数语法:func behavior(x,y int, s string)result int{...<函数内容>}
函数类型:func(int, int, string)int(去掉所有名字(函数名、形参名、返回值名)名即可,func保留)
匿名函数:func (x,y int, s string)result int{...<函数内容>}(除没有名字外,匿名函数和普通函数完全相同)
part 3 局部分析
函数组成、特点
func function_name( [parameter list] ) [return_types] {函数体return xxx}
| 是什么 | 解析/特点 | |
|---|---|---|
| func | 关键字 | 函数由 func 开始声明 |
| function_name | 函数名称 | 1. 函数签名= <font style="color:rgb(51, 51, 51);">function_name (parameter_list) return_types</font>2. 函数名可大写(包内外用),可小写(包内用) 3. 不支持重载(overload) 1. 什么叫重载? —同一个函数名用不同的函数内容去定义,那么如何区分呢?通过输入参数类型、个数和返回值类型的不同来实现 2. go语言如何考虑 —函数重载可能会导致代码难以阅读和理解,因为不同的函数定义之间的区别可能非常微小,此外,函数重载也可能导致函数名的混淆,因为同一个函数名可以代表多个不同的函数,这会给代码的维护和调试带来一定的困难。 —go语言不支持函数重载,但支持定义不同receiver的但可同名的方法 |
| parameter list | 参数列表 | 1. 参数列表(形参)规定了输入的实参的参数类型、顺序、及参数个数。 2. 可输入0或多个参数,但是括号必须有 3. 分为 1. 固定参数列表 (x,y int)2. 不定参数列表 <font style="color:#AD1A2B;">(x...int)</font>4. 不支持默认参数如 a int = 1 |
| return_types | 返回类型 | 1. 无返回值无return;有返回值的函数体内,必须有return,遇到return就回中止函数进程,进行返回 2. 应用 1. 可无返回值,整个省略 2. 一个返回值/多个返回值;带变量名/不带变量名 |
| 函数体 | 函数体 | 1. 不支持嵌套函数(函数内再定义一个函数),但支持嵌套匿名函数 |
形参、返回值解析
无参无返回值
保证语法格式即可
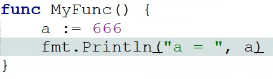
形参解析(值传递)
普通参数列表

- 形参语法
实际就是,变量声明删去关键字var x, y int ➡ (x,y int)var x int; var y string ➡ (x int, y string) - 实参的值,按序,不缺地,单方向传给形参,不能形参的值传给实参
- 作用域:仅限于函数体内
不定参数列表
和传入列表有什么差别?
func myfunc(args...int){x, y, z := argsfmt.Println(args)fmt.Println("++++++++++++++++++++++++")for k,v := range args{fmt.Println("%d个参数是%d", k, v)}}
- 语法
- 什么叫不定参数列表?——传递地实参可以是0或多个(并没有定义容量)
- 形参语法
(args...type) - 接受什么?——0或多个同类型的参数
返回什么?——若要想返回args,那么返回的是切片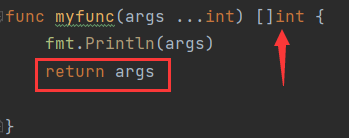
- 要求
- 固定参数一定要传参,但不定参数根据需求传递参数,可以是0或多个
实例:如a一定要赋值,但arg不一定 **
** - 不定参数可以和固定参数混搭,但一定放在参数最后,且不定参数只能有一个
- 固定参数一定要传参,但不定参数根据需求传递参数,可以是0或多个
- 本质:args就是一个slice
- 类型上,要求必须是同类型的参数;若需要不同类型,则定义
args...interface{}(用interface{}传递任意类型数据是Go语言的惯例用法,而且interface{}是类型安全的。) - args在函数中如何使用?→切片怎么用args就怎么用
- 类型上,要求必须是同类型的参数;若需要不同类型,则定义
返回值解析
- 变量名
| 不带变量名的 | 带变量名的 | |
|---|---|---|
| 一个返回值 | 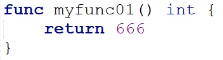 可省略括号 可省略括号 |
 |
| 多个返回值 |  |
 ➡同样可以采取省略写法 ➡同样可以采取省略写法  |
| 优缺点 | 可以返回不同变量的值,只是不够直观 | 只能返回开头声明的变量的值,有约束性,但直观 |
最终在main函数体内调用的时候a, b := MyFunc(1,2)
- 编程习惯
- Go中经常会使用一个返回值作为函数是否执行成功、是否有错误信息的判断,比如,
return value, exists、return value,ok、return value, err - 返回值过多,如超过四个的时候,应收集到相应容器中,同类型放slice、不同类型放map
- 用
_来丢弃返回值
- Go中经常会使用一个返回值作为函数是否执行成功、是否有错误信息的判断,比如,
与c语言的区别
- 语法上
- go中参数和返回值类型都不是必须的,c语言中你不需要至少要写个void为返回值类型
- 格式不同,go需要关键字func声明


- 返回值
go语言返回值可返回多个(注意,要在开头声明出来),且返回值可以有变量名,而c语言无法在开头就告知返回值变量名,只能在函数体定义 - go无函数声明,只要是包内,都可以调用,也就是对自定义函数的位置,不关心
!!函数参数(值传递/引用传递)
调用函数,可以通过两种方式来传递参数: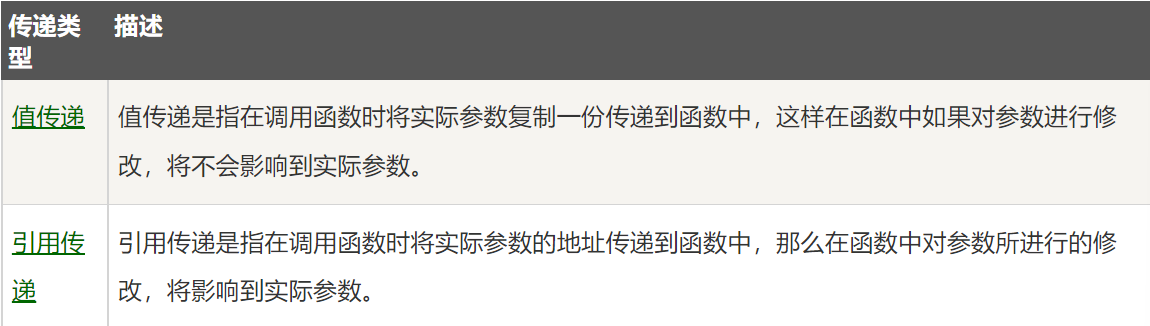 1. 值传递
1. 默认情况值传递
2. 形参的作用域和c语言一样,调用实参过程中不会影响到实际参数。
3. 具体解析见上文
2. 引用传递
1. 形参是带指针
2. map、slice、chan、指针、interface默认以引用的方式传递,或者含有这些引用类型的符合数据类型,比如结构体指针
3. 无论是值传递,还是引用传递,传递给函数的都是变量的副本**,**不过,值传递是值的拷贝。引用传递是地址的拷贝,一般来说,地址拷贝更为高效。而值拷贝取决于拷贝的对象大小,对象越大,则性能越低。
## 函数是一种类型
函数也是一种数据类型,和int,float一样,可以通过type给一个函数类型起别名,之所以提出函数类型,是为了让函数和基本变量一样,可以进行传递
### 函数变量的声明与调用
> 其流程与结构体一致
>
1. 什么是函数类型?
1. 值传递
1. 默认情况值传递
2. 形参的作用域和c语言一样,调用实参过程中不会影响到实际参数。
3. 具体解析见上文
2. 引用传递
1. 形参是带指针
2. map、slice、chan、指针、interface默认以引用的方式传递,或者含有这些引用类型的符合数据类型,比如结构体指针
3. 无论是值传递,还是引用传递,传递给函数的都是变量的副本**,**不过,值传递是值的拷贝。引用传递是地址的拷贝,一般来说,地址拷贝更为高效。而值拷贝取决于拷贝的对象大小,对象越大,则性能越低。
## 函数是一种类型
函数也是一种数据类型,和int,float一样,可以通过type给一个函数类型起别名,之所以提出函数类型,是为了让函数和基本变量一样,可以进行传递
### 函数变量的声明与调用
> 其流程与结构体一致
>
1. 什么是函数类型?func Myfunc (a, b int)int➡<font style="color:#AD1A2B;">func (int, int)int</font>(去掉所有名字(函数名、形参名、返回值名)名即可,func保留)
2. 如何使用?
1. 用type关键字,给函数类型其个别名type 类型别名 函数类型比如 type Func_type func(a, b int)
2. 声明一个函数变量var Mytest Func_type
3. 赋值给一个函数变量赋什么值?当然是函数啦
Mytest = Swap(Swap是某个已定义的函数)
4. 调用Mytest(1,2)与基本函数调用完全一致
3. 作用:可以创建一个变量,赋予该变量同一类型但不同内容的函数,实现<font style="color:#AD1A2B;">多态</font>的理念
### 函数作为参数/返回值
1. key:如何获得函数类型?func Myfunc (a, b int)int➡<font style="color:#AD1A2B;">func (int, int)int</font>(去掉函数名和形参名即可,func保留)
2. 应用—实现封装与多态实例:
go
package main
import "fmt"
//函数作为形参
func sayHello(name string){
fmt.Printf("Hello,%s\n", name)
}
func test(name string, f func(string2 string)){
f(name)
}
//函数作为返回值
func add(a int, b int)int {
return a+b
}
func sub(a int, b int)int {
return a-b
}
func cal(operator string) func(int, int)int {
switch operator {
case "+":
return add
case "-":
return sub
default:
return nil
}
}
func main() {
//函数作为形参
test("ray", sayHello)
//函数作为返回值
f1 := cal("+")
r1:= f1(1,2)
fmt.Println(r1)
f2 := cal("-")
r2 := f2(3,5)
fmt.Println(r2)
}
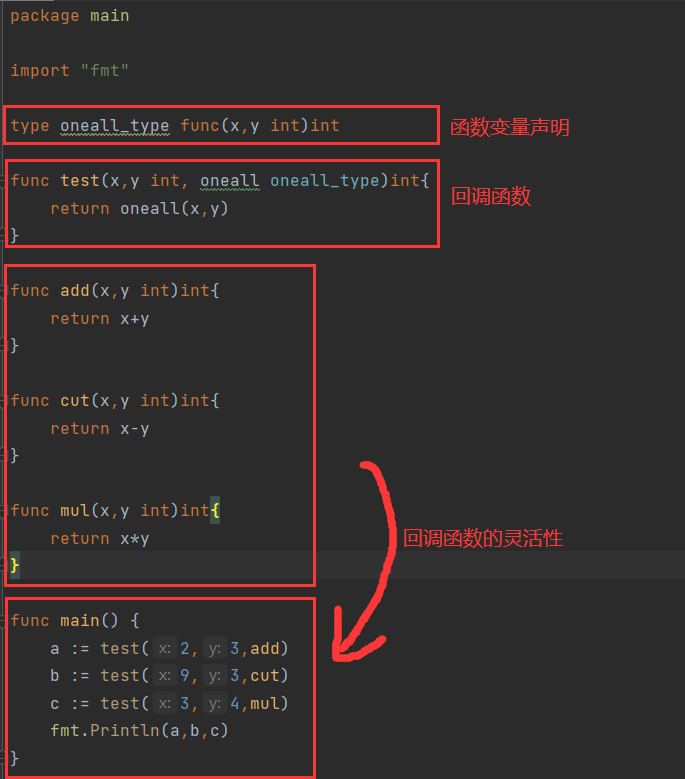
go
package main
import "fmt"
type oneall_type func(x,y int)int
func test(x,y int, oneall oneall_type)int{
return oneall(x,y)
}
func add(x,y int)int{
return x+y
}
func cut(x,y int)int{
return x-y
}
func mul(x,y int)int{
return x*y
}
func main() {
a := test(2,3,add)
b := test(9,3,cut)
c := test(3,4,mul)
fmt.Println(a,b,c)
}
 结果:
结果: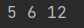 ## 应用
###
### 匿名函数
由于,在Go里面,函数可以像普通变量一样被传递或使用,故,产生了匿名函数
## 应用
###
### 匿名函数
由于,在Go里面,函数可以像普通变量一样被传递或使用,故,产生了匿名函数
- 语法:
func(参数列表)返回值{...(除没有名字外,匿名函数和普通函数完全相同) - 优点 在于可以直接使用函数内的变量,不必申明。
- 应用
- 可赋值给变量
 =
=
- 可作为参数
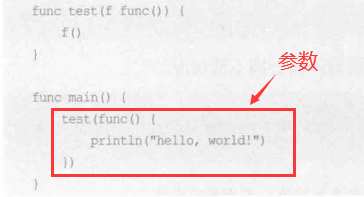
- 可作为返回值
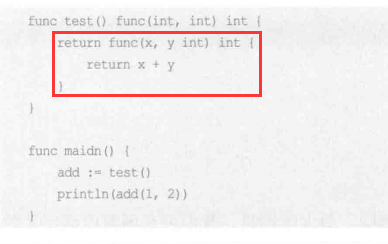
- 即时调用 (定义完后立即运行)

若有返回值,返回给变量(和第一个不一样,x和y得到的是max和min的值)
- 普通函数和匿名函数都可作为结构体的元素类型,或经通道传递(函数类型把形参的标识符也去了)


- 除闭包因素外,匿名函数也是一种常见重构手段。可将大函数分解成多个相对独立的匿名函数块,然后用相对简洁的调用完成逻辑流程,以实现框架和细节分离。
- 可赋值给变量
:::info 注意点
:::
- 将匿名函数赋值给变量,与为普通函数提供名字标识符有着根本的区别。(**???不知道?)**当然,编译器会为匿名函数生成一个“随机”符号名。
- 未被使用的匿名函数会被编译器当成错误
- 闭包与匿名函数的差别???
相比语句块,匿名函数的作用域被隔离( 不使用闭包),不会引发外部污染,更加灵活。没有定义顺序限制,必要时可抽离,便于实现干净、清晰的代码层次。
?闭包
什么是闭包?
—闭包 = 嵌套函数(闭包是一般通过匿名函数来实现的,但也有在函数内调用其他函数实现的) + 引用环境
特点
闭包捕获的变量,具有记忆性,可迭代,那么什么叫记忆性?
—闭包不关心这些捕获了的变量或者常量是否超出了作用域,所以只有闭包还在使用它,这些变量就还会存在(即,闭包内,变量的生命周期不由它的作用域决定)
条件
—外部函数A,包含着函数B,函数B;函数B引用了外部的(外部函数A内或者全局)变量C,且不会被垃圾回收机制回收。以下是理解:
- 如何理解外部的?
- C是在外部函数A外定义的,从作用域是全局理解即可
- C是在外部函数A内定义的,看下方原理分析
- 如何保证不会被垃圾机制回收?
前言:闭包捕获的变量C的作用域=闭包的声明周期
→闭包生命周期的结束取决于闭包本身是否还被其它代码引用。具体:- 执行了包含闭包的函数并返回了闭包,但是没有将闭包赋值给任何变量或者将闭包从变量中移除了,从而使闭包无法再被访问。
- 将包含闭包的变量从内存中删除或销毁,例如通过垃圾回收器清除了不再被使用的变量。
需要注意的是,在闭包中引用的外部变量如果是指针类型的话,需要注意内存泄漏的问题。如果闭包中引用的外部变量是一个指针,并且在闭包的生命周期中没有被正确释放,那么就可能会导致内存泄漏,从而影响程序的性能和稳定性。因此,在使用闭包时需要注意避免这种情况的发生。
- 函数B作为输入参数或者返回值
- 输入参数实例,实例如下
- 返回值实例
- 函数B通常是匿名函数,但也可以是引用的普通函数,实例如下
原理分析
闭包引用的变量具有记忆性,因为它们的生命周期不仅仅是由外部函数的生命周期所决定,而是由闭包本身的生命周期所决定。
当一个函数返回一个闭包时,该闭包会捕获其所引用的外部变量,并将它们保存在一个内部的数据结构中。这些外部变量可以是局部变量、函数参数或者全局变量。当闭包被调用时,它可以访问这些外部变量,并且可以修改它们的值。闭包的记忆性是因为闭包本身保存了对外部变量的引用,并且在闭包的生命周期中,这些外部变量的值可以随着闭包的调用而改变。这意味着,闭包可以“记住”它们在上一次调用时所引用的变量值,并且可以在下一次调用时使用这些值。这种记忆性可以使闭包在特定场景下非常有用,例如实现缓存、迭代器和状态机等。
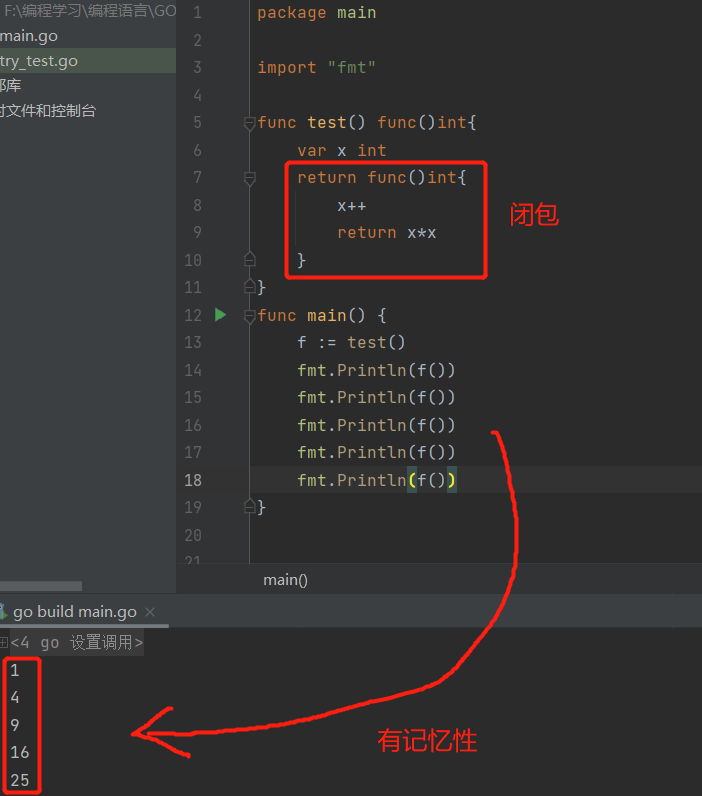
func fibonacci() func() int {a, b := 0, 1return func() int {result := aa, b = b, a+breturn result}}func main() {f := fibonacci()for i := 0; i < 10; i++ {fmt.Println(f())}}
实例分析
- 实例1——在add的生命周期内,变量base一直有效
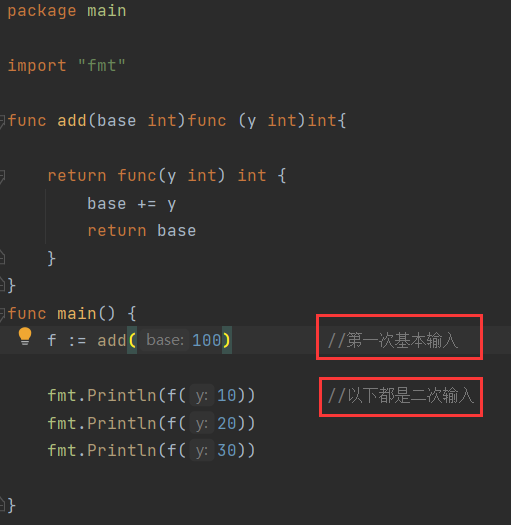
- 实例2
- 实例3
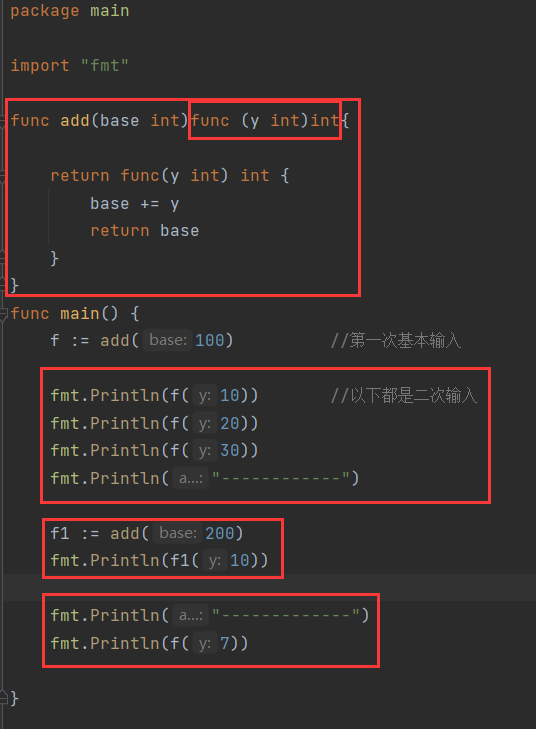
结果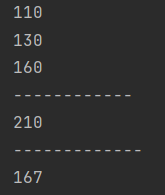
注意:- 当闭包重新赋予新的变量f1的时候,原闭包的生命周期依然存在,因为并未销毁f
闭包→初始函数
闭包+base=100→f1函数
闭包+base=200→f2函数 - 当我们谈论闭包生命周期的时候,指的是定义闭包的函数块内,定义的变量的生命周期
- 当闭包重新赋予新的变量f1的时候,原闭包的生命周期依然存在,因为并未销毁f
package mainimport "fmt"func add()func (y int)int{ //返回匿名函数也可以写func(int)intvar x int //x最终做返回值return func(y int) int {x += yreturn x}}func main() {var f = add()fmt.Println(f(10))fmt.Println(f(20))fmt.Println(f(30))fmt.Println("----------")f1 := add()fmt.Println(f1(40))fmt.Println(f1(50))}
- 实例4——返回两个闭包
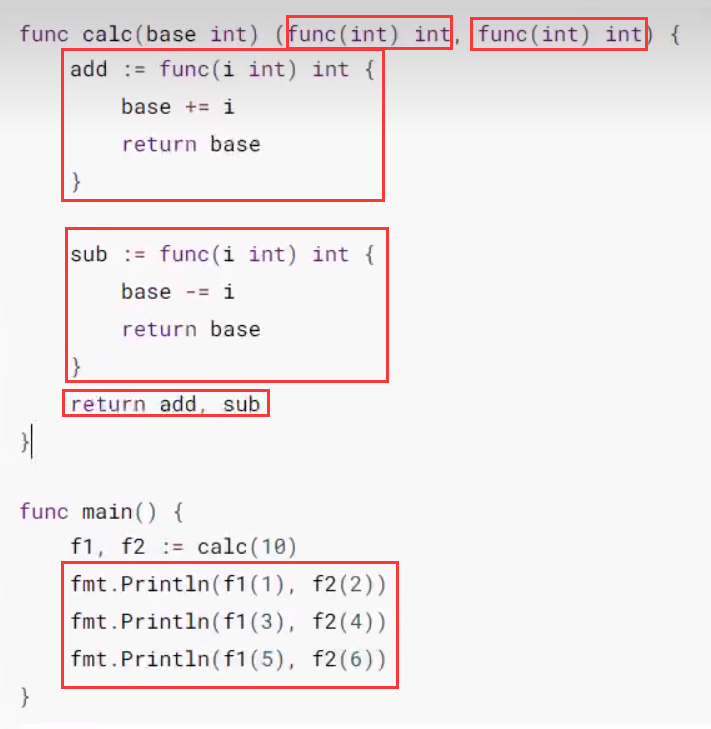

理解:f1与f2是相关的,从始至终都是一个base变量
函数递归
函数调用流程:先调用后返回,先进后,要deep到顶点之后,才从顶点返回
具体流程以前在c语言分析过,笔记作用不明显,要看往回看视频黑马go语言第49个视频去看,这里讲结果怎么用
:::info 原理
:::
递归 = 递推 + 回归
递推是往下挖掘,不计算;回归才是真正的计算,返回一个关系,
:::info 应用
:::
- 返回什么关系?
类似于数列上的f(n) 与f(n-1)的关系,比如函数是Myfunc(x),那么就return g{Myfunc(x-1)}g(x)描述 Myfunc(x)和Myfunc(x-1)的关系,比如- 累加就是
return Myfunc(x-1) +x - 累乘就是
return Myfunc(x-1) *x - 如果是奇数项彼此相加,那就是
return Myfunc(x-2) *x(初始为奇数,末端为0)
- 累加就是
- 终止项
- 必须夹在函数开头与返回循环关系之间
- 一般是
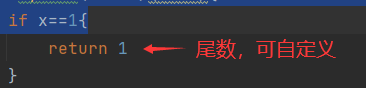
package mainimport "fmt"func main() {sum := Myfunc(100)fmt.Println(sum)}func Myfunc(x int)( int){if x==1{return 1}return Myfunc(x-1)+x}
defer延迟调用
我们要延迟执行一个命令,怎么办?——defer关键字
- 基本语法:
defer ...(语句/函数/方法)defer是一个关键字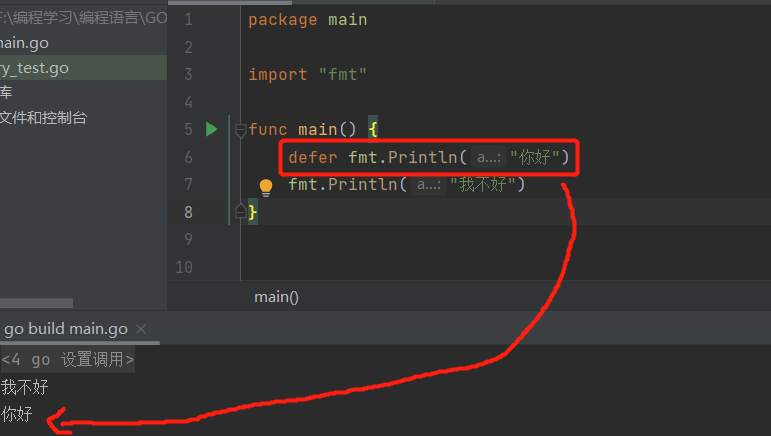
- 作用
延迟调用一个语句/函数/方法,延迟到什么时候呢?——函数结束的时候,常用于网络编译,比如关闭连接的这个命令要在客服选择挂机后才执行 - 要求
只能用于函数内部,即花括号内 - 多个执行语句怎么办?
后进先出(越后头,越先出来)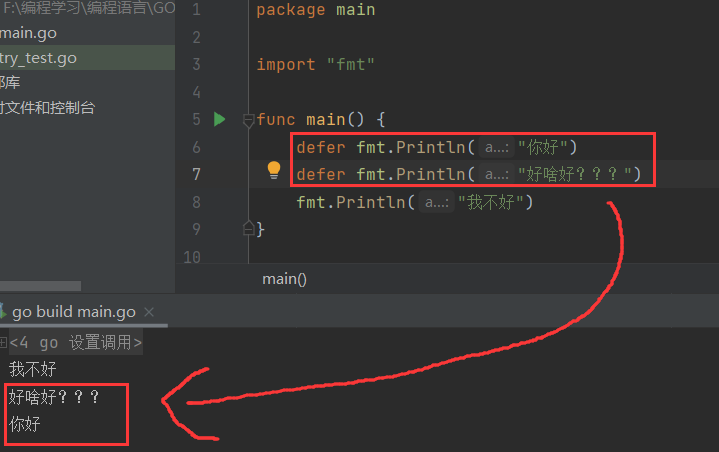
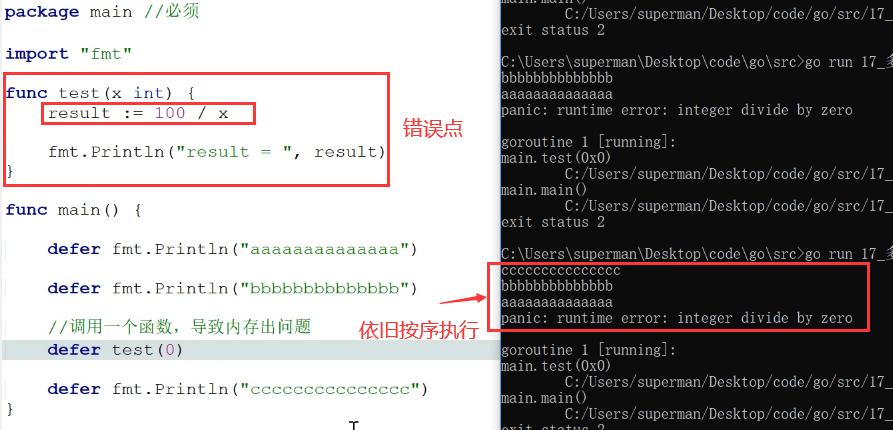
- defer语句中一旦出错了
- defer和匿名函数结合使用
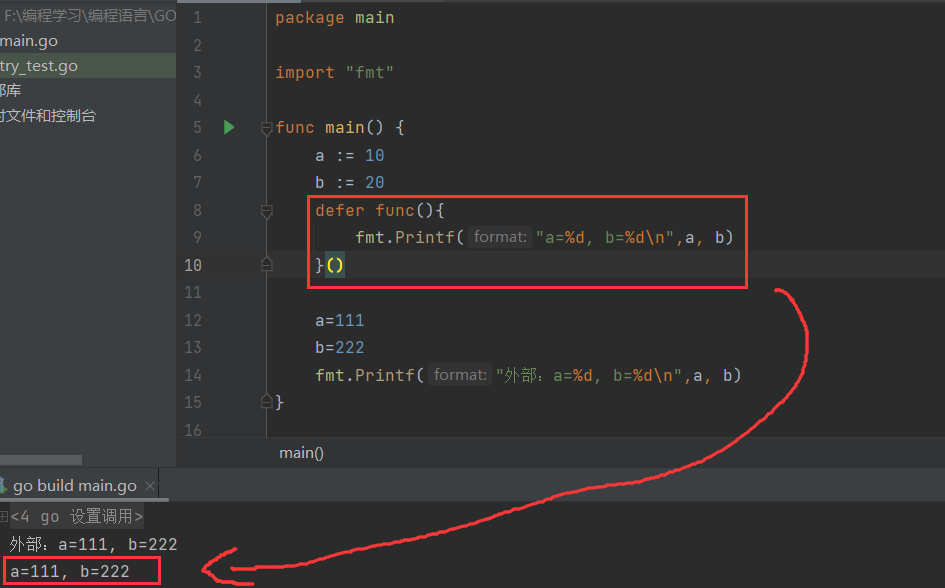
为什么刚刚强调先编译,再提取,最后按序执行呢?——我们来看两个例子- 实例1
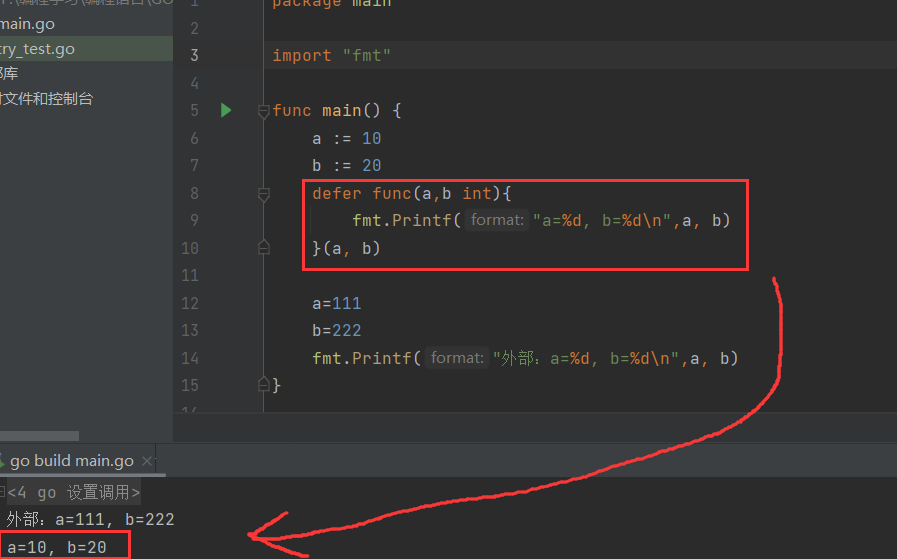
- 实例2
- 分析
观察两个例子,结果截然不同,差别就在于实例2是输入参数的,实例1不输入参数,这就表示,即使某段代码加入defer关键字,后面执行,那也是先进行了从例子中输入了参数,只是执行,放到了后面
- 实例1
:::info 核心步骤
:::
- 在多个含有defer的语句中,编译器会把含有defer的命令,先运行,该接收的参数接收它,没接收参数,需要调用的,再函数结束时再调用
- 在函数结束的时候,所有带defer的语法块提取出来,按后进先出的顺序,进行执行
- 若此时需要调用参数,则以函数结束时的参数的值为准
- 此时,即使其中有一个出错了,那其他也会按序,执行出来,不会终止

若有收获,就点个赞吧
0 人点赞
