- Go提供了一种称为通道的机制,用于在goroutine之间共享数据。当您作为goroutine执行并发活动时,需要在goroutine之间共享资源或数据,通道充当goroutine之间的管道(管道)并提供一种机制来保证同步交换。
- 需要在声明通道时指定数据类型。我们可以共享内置、命名、结构和引|用类型的值和指针。数据在通道上传递:在任何给定时间只有一个goroutine可以访问数据项:因此按照设计不会发生数据竞争。
- 根据数据交换的行为,有两种类型的通道:无缓冲通道和缓冲通道。无缓冲通道用于执行goroutine之间的同步通信,而缓冲通道用于执行异步通信。无缓冲通道保证在发送和接收发生的瞬间执行两个goroutine之间的交换。缓冲通道没有这样的保证。
基础知识
基本语法
| 详情 | |
|---|---|
| 基本语法 | |
| 创建channel | 1. var 变量名 chan 数据类型(chan像个副词加在类型前面)  2. 直接初始化: ch1 := make(chan int, 77) |
| 初始化 | 1. make函数: **<font style="color:rgb(51, 51, 51);">ch1 = make</font>**(**<font style="color:rgb(51, 51, 51);">chan</font>** 元素类型, [缓冲大小])2. NOTE: 当 capacity= 0 时,channel 是无缓冲阻塞读写的,当 capacity> 0 时,channel 有缓冲、是非阻塞的,直到写满 capacity 个元素才阻塞写入。 |
| 本质—比喻 | 比喻——水管 数据是水,channel是水管, 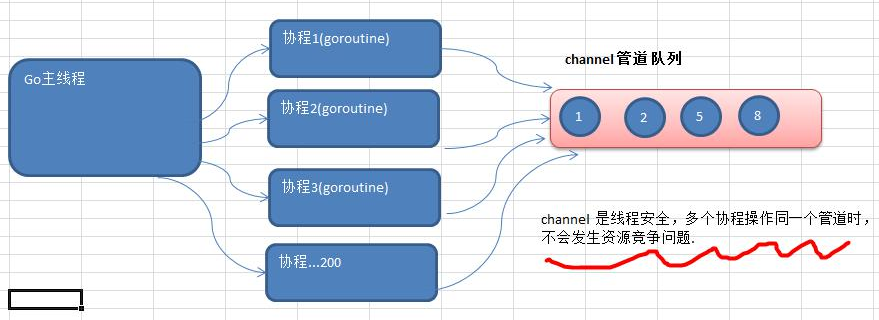 |
| 类型 | 类型——chan是引用类型,故 1. 必须初始化才可使用,一般使用make 2. channel 有类型的 int的channel只能写入整数int;一个string的channel只能存放string类型数据 |
| 值 | 由于channel是一个引用类型,它的值和地址和指针类似 1. 值是一个地址,指向真正的数据 2. cahnnel的地址,存放其值 |
| 特点/性质 | 1. 不同于切片,不可增长 2. 线程安全,多goroutine访问时,不需要加锁,就是说channel本身就是线程安全的,这就是go最牛逼的地方 |
| len与cap | len(ch) ,cap(ch) len表示缓冲区剩余数据个数,cap表示缓冲区大小 |
| 操作(视角是我,我向管道发送值,我从管道接受值,我把管道关闭) | |
| 发送 | 管道变量<-数据 ,如ch1 <- "我是傻逼" |
| 接受 | x <- ch1/ x := <-ch1(创建并赋值x)/<-ch1(接受数据并将其丢弃) |
| 关闭 | **<font style="color:rgb(51, 51, 51);">close</font>**(ch1) 详情见下方 |
创建channel
:::info 要点
:::
- 如果输入数据比较复杂,如集合、结构体等等,先定义好再传输
- 输入什么类型,输出就什么类型
- 尤其注意空接口类型,若channel类型是空接口,传输了各种类型变量,则取出时变量类型本质仍为空接口,若是结构体则需要类型断言之后才可以使用
:::info 实例
:::
- intChan好像并非只能传int
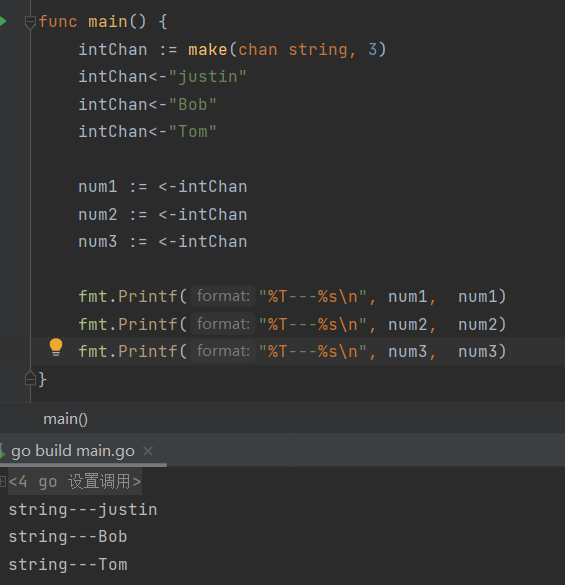
- 如果输入数据比较复杂,如集合、结构体等等,先定义好再传输

- 空接口类型
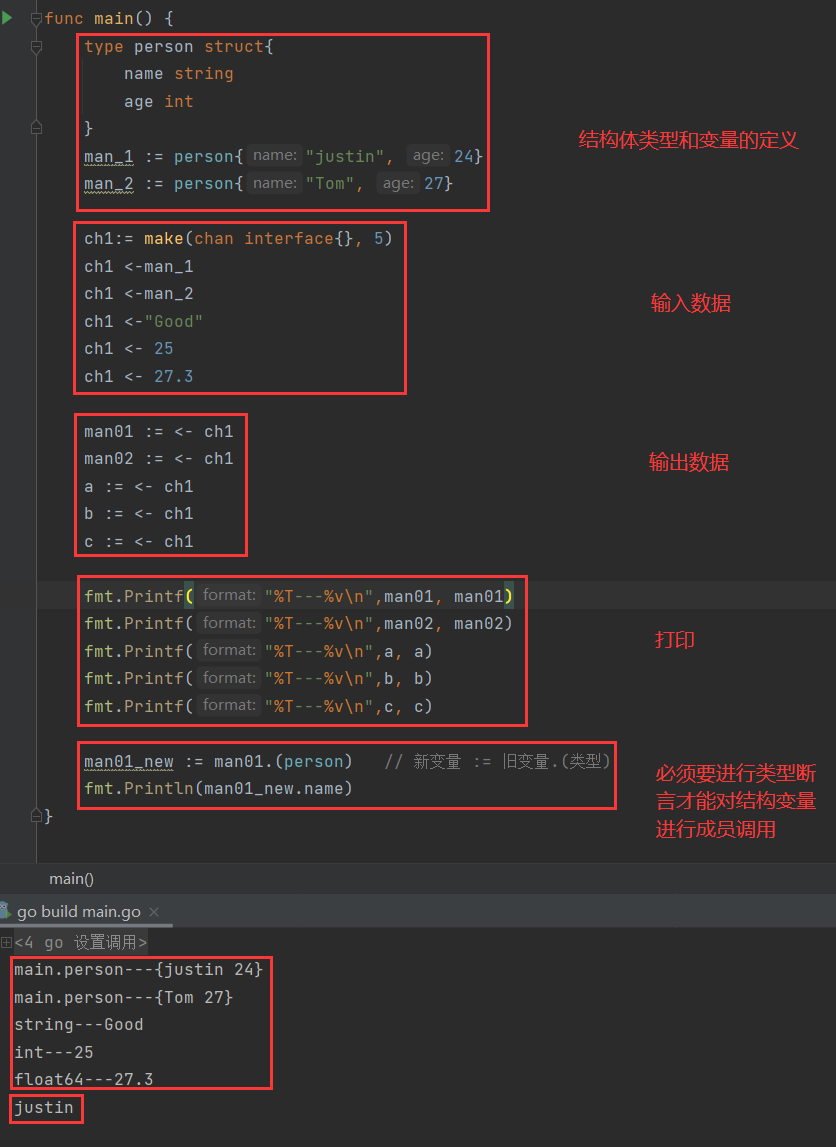
无缓冲的channel
- 是什么?
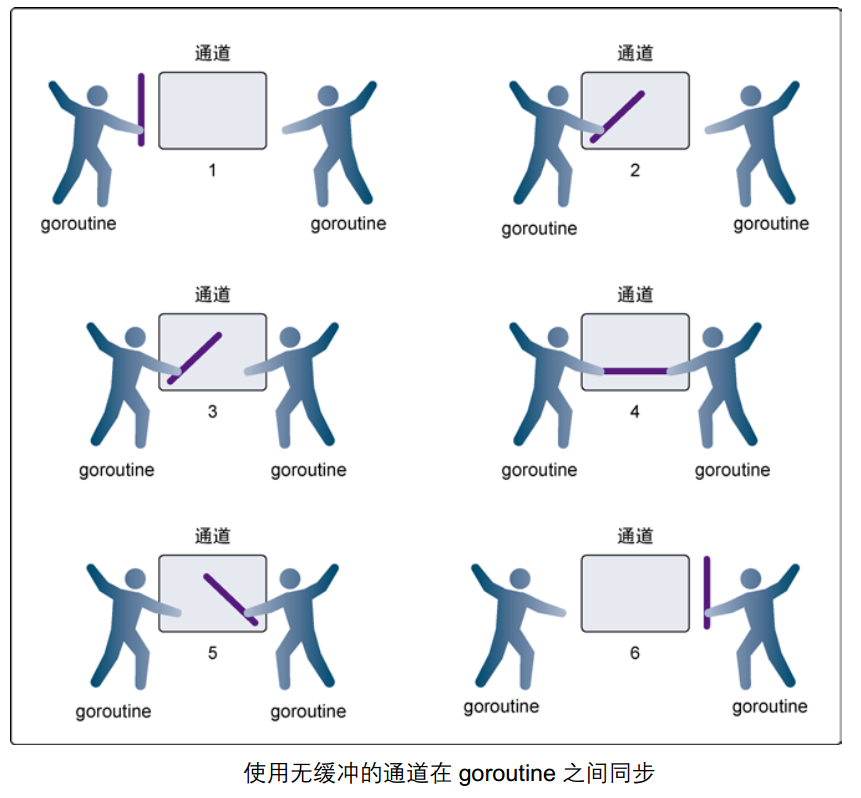
——无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。无缓冲的通道又称为阻塞的通道。 - 创建方式:
<font style="color:rgb(0,0,0);">ch := make(chan int)</font>or<font style="color:rgb(0,0,0);">ch := make(chan int, 0)</font> - 特点
- 任何时候,len(ch) = cap(ch) = 0
- 无缓冲的通道只有在有人接收值的时候才能发送值
**= 执行过程:一个发,紧接着另一个收 + 程序中channel的命令个数必然成对**
- 目的是什么呢?
使用无缓冲通道进行通信将导致发送和接收的goroutine同步化。因此,无缓冲通道也被称为同步通道。
:::info
特点解析:::
- 无缓冲的通道又称为阻塞的通道。我们来看一下下面的代码:

上面这段代码能够通过编译,但是执行的时候会出现以下错误:
- 为什么会出现deadlock错误呢?
因为我们使用<font style="color:rgb(36, 41, 46);">ch := make(chan int)</font>创建的是无缓冲的通道,无缓冲的通道只有在有人接收值的时候才能发送值。就像你住的小区没有快递柜和代收点,快递员给你打电话必须要把这个物品送到你的手中,简单来说就是无缓冲的通道必须有接收才能发送。 - 如何解决?
一种方法是启用一个goroutine去接收值,例如: →结果
→结果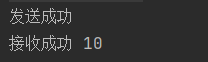
:::info 黑马
:::
package mainimport ("fmt""time")var ch1 chan intfunc main() {ch1 = make(chan int, 0)go func() {for i:=0; i<3; i++{fmt.Printf("这里是子协程,i = %d\n", i)ch1 <- ifmt.Printf("这里是子协程结尾,i = %d, 给管道发送完毕\n", i)fmt.Println()}}()time.Sleep(2*time.Second)for i:=0; i<3; i++{fmt.Println("这是主协程开头")num := <-ch1fmt.Printf("这是主协程结尾,num = %d 从管道接受完毕\n", num)fmt.Println()}}
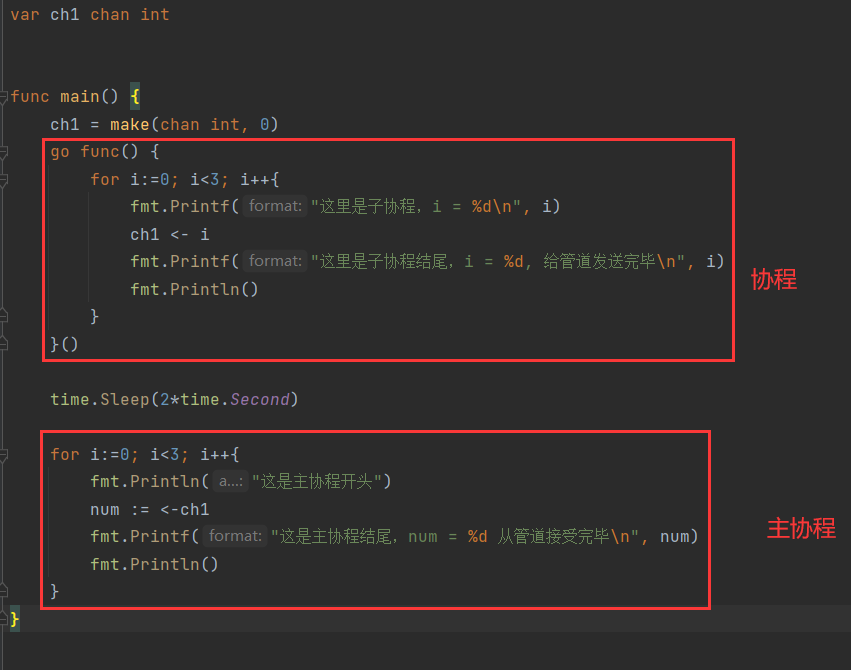
结果:
有缓冲的channel
只要通道的容量大于零,那么该通道就是有缓冲的通道,通道的容量表示通道中能存放元素的数量。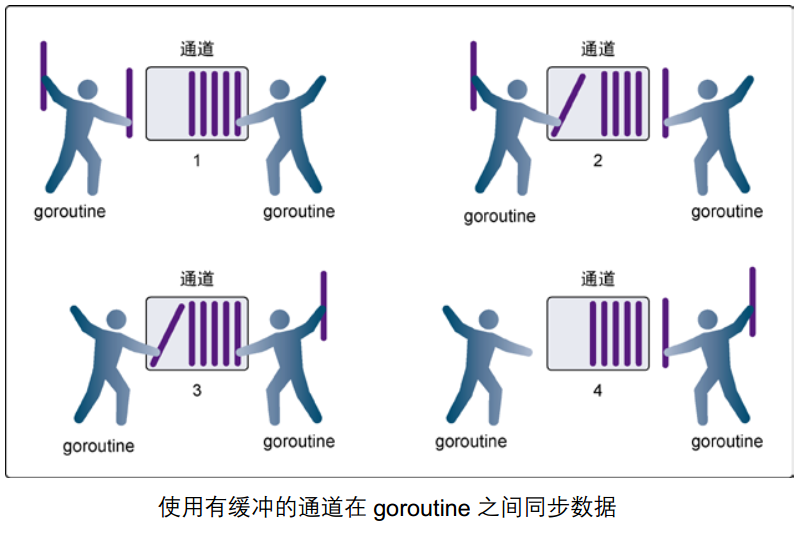
- 设置方法:例如设容量为3
<font style="color:rgb(0,0,0);">ch1 := make(chan int, 3)</font> - 解释:
1. 顺序:
1. 先进先出
2. 但不一定所有一起进,再所有一起出,即,如果给定了一个缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
2. 若满了
就像你小区的快递柜只有那么个多格子,格子满了就装不下了,就阻塞了,等到别人取走一个快递员就能往里面放一个。 3. 我们可以使用内置的len函数获取通道内元素的数量,使用cap函数获取通道的容量,虽然我们很少会这么做。
channel基本操作
发送
- 语法:
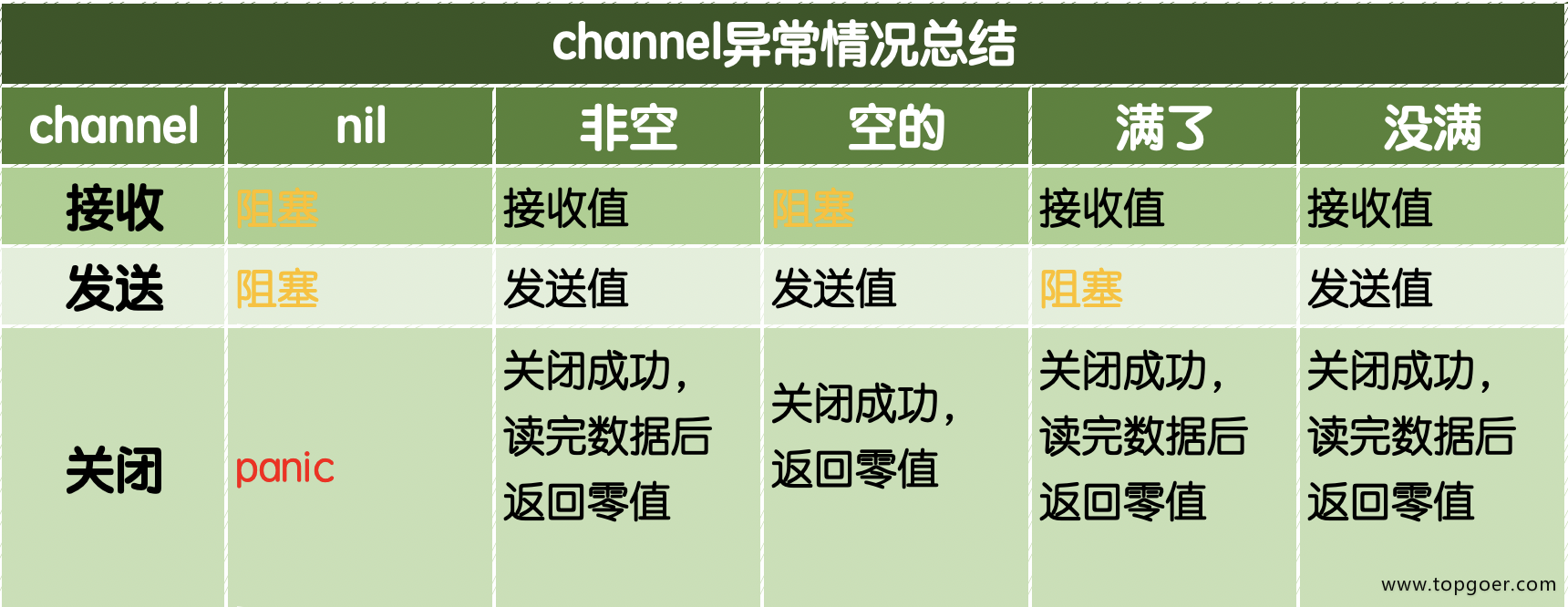
ch1 <- data - 当channel满了或者nil channel的时候,发送数据,会阻塞
接收
- 语法:
x <- ch1/x := <-ch1(创建并赋值x)/<-ch1(接受数据并将其丢弃) - 顺序:先进先出 在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报告deadlock(报错)
- 什么时候阻塞?
nil channel或者空的channel的时候
发送和接受的特性
- 对于同一个通道,发送操作之间是互斥的,接受操作之间也是互斥的
- 发送操作和接受操作中,对元素值得处理是不可分割的
- 发送操作在完全完成之前,会被阻塞,接受操作也是如此
关闭close与range、for
:::info close
:::
- 什么是关闭channel?
类似于在管道尾巴锁上了,加了个写入锁 - 什么时候需要关闭通道?
——如果发送者知道,没有更多的值需要发送到 channel 的话,那么让接收者也能及时知道没有多余的值可接收将是有用的,因为接收者可以停止不必要的接收等待。这可以通过内置的close 函数来关闭 channel 实现。 - 注意点
——只有在通知接收方goroutine所有的数据都发送完毕的时候才需要关闭通道。通道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭通道不是必须的。(???不咋理解) - 关闭channnel后:
- 无法再发送数据——会导致panic
- 可以继续接受数据——会正常持续接受,直到通道为空;
- 关闭——会导致panic
- 若对一个已经空了又关闭的通道去执行接受,会收到对应类型的零值(对于nil channel未初始化的管道,无论收发,都会阻塞)
- 怎么查channel关闭了没?
——data, ok := <- ch1(channel关闭之后ok = false)
:::info close与range、for
:::
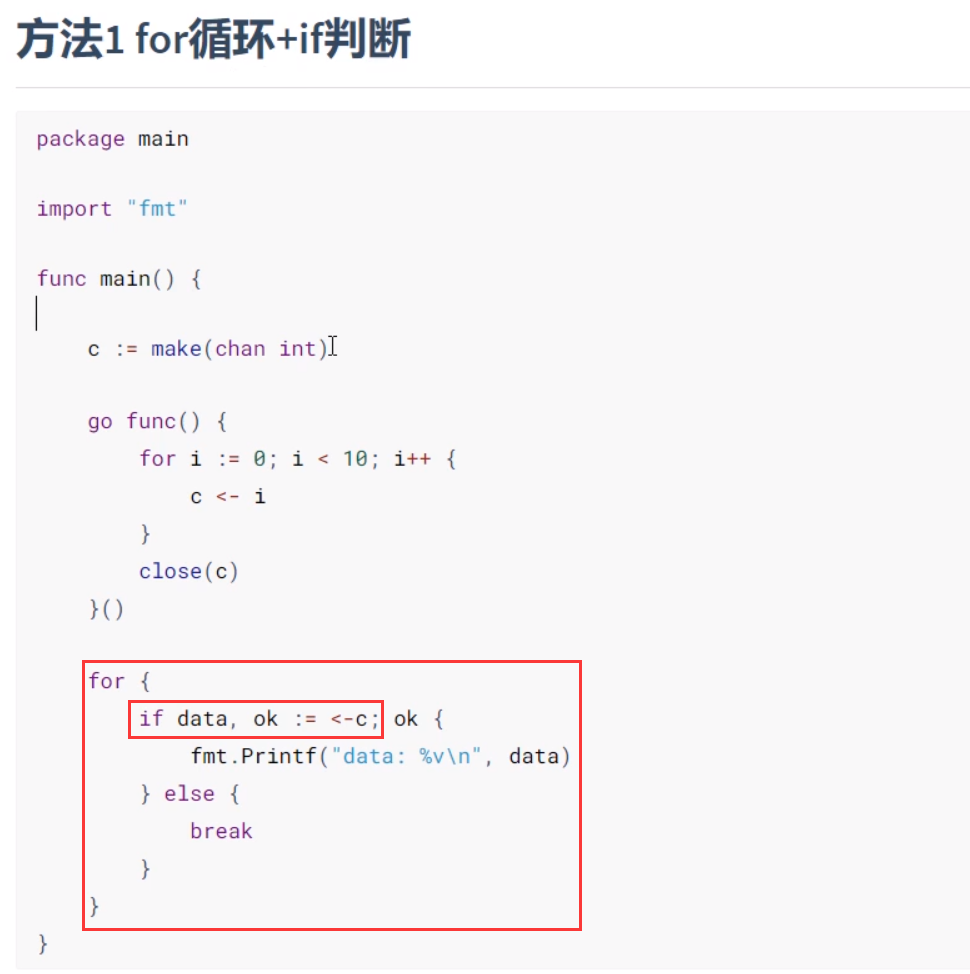
目的:如何优雅的从循环取值,一般情况下用range多
- range
- 语法
for data := range ch1{...} - 发送完成的时候,close了,接受的时候,用range,可不用管接受几个
- 语法
- for与range
- 记得写两个地方,一个获得ok,一个判断ok(if语句)
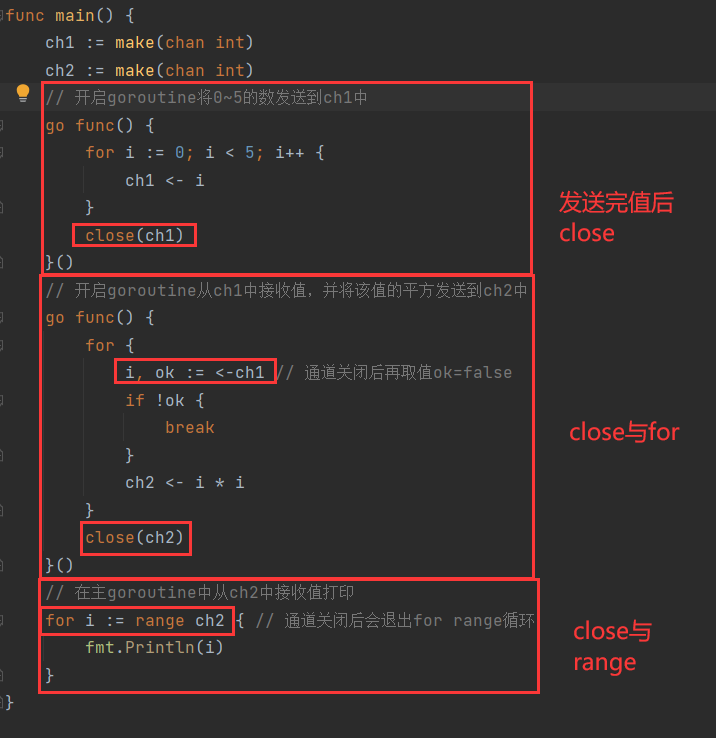 结果
结果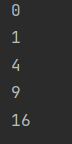
- 记得写两个地方,一个获得ok,一个判断ok(if语句)
遍历
两种方式
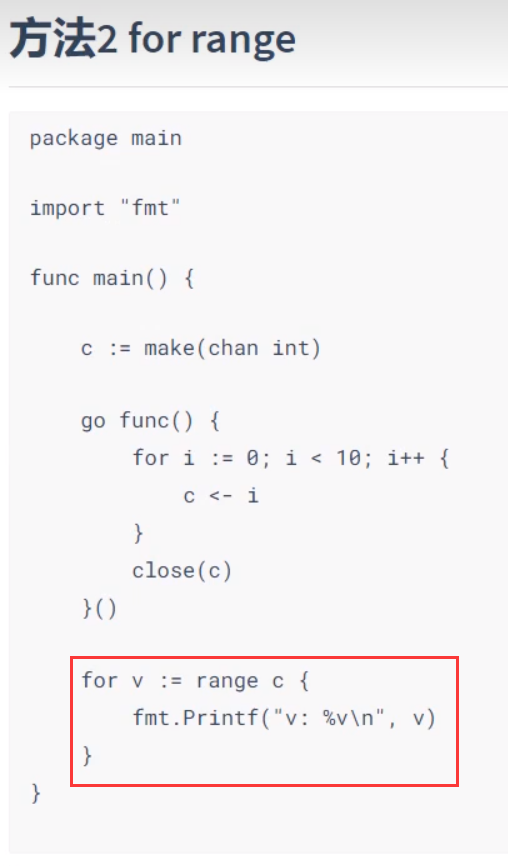
应用
单方向的channel
- 默认情况下,通道是双向的,也就是,既可以往里面发送数据也可以同里面接收数据。
- 使用场景
但是,我们经常见一个通道作为参数进行传递而值希望对方是单向使用的,要么只让它发送数据,要么只让它接收数据,这时候我们可以指定通道的方向。 - 创建

- 转化:
双向的channel可转化为单向的channel,反之不可行 - 应用
只可写入操作的,和输出的channel,都可以进行赋值,再由于通道是引用类型,则,建立一个双向ch0,分别赋值给单方向只写入的ch1,和单方向只读取的ch2,即可实现一边输入,一边再输出
package mainimport "fmt"func main() {ch1 := make(chan int) //无缓冲channelgo func(ch2 chan<- int) {for i:=0; i<5; i++{ch2 <- i}close(ch2)}(ch1)func(ch3 <-chan int) { //我一开始这里也是 go func(){....}但不行,不知道为什么for num := range ch3 {fmt.Println("num = ", num)}}(ch1)}
package mainimport "fmt"// chan<- //只写func counter(out chan<- int) {defer close(out)for i := 0; i < 5; i++ {out <- i //如果对方不读 会阻塞}}// <-chan //只读func printer(in <-chan int) {for num := range in {fmt.Println(num)}}func main() {c := make(chan int) // chan //读写go counter(c) //生产者printer(c) //消费者fmt.Println("done")}
通道异常情况总结
直播学习
- 并发队列解决过什么问题?
- 线程池?
- 动态扩容?
- 卡夫卡什么?
- 生产者!消费者!
- 内容简要?
- 1:04分讲面试需要什么
- 根据场景,如何设计API?
- 什么是泛型?
- 注释化的快捷方式是什么?
- 要设计什么?
目标
提高你们的并发编程能力。p6 +,当你能够独立写出来这个并发队列的时候,就可以在简历加上精通 Go 并发编程。 代码在 live_round_2 分支上 课前准备 安装好 Go 开发环境,Go >=1.18
提前搜索队列的基本含义,包括普通队列,并发队列,并发阻塞队列,优先级队列,优先阻塞队列等
提前了解 ring buffer
(如果你还完全没接触过,课程中是有的)提前学习 context.Context, sync 包中的读写锁, sync.Cond, atomic 包(原子操作),semaphore.Weighted(golang.org/x/sync/semaphore 包)
4.9
讨论(提前思考)
如果要你设计一个并发队列,你会考虑一些什么场景,或者说考虑一些什么因素?
基于上面的场景,你怎么设计接口?
对于实现,你认为什么样的非功能特性是最比较重要的?
和 channel 作为对比,你认为 channel 和传统的并发队列比起来,优缺点有哪些?
(可选)平时你是怎么分析并发场景的?或者说,你是怎么分析一段代码有没有并发问题的?
知识点
● 你用并发队列解决过什么问题:
○ 生产者-消费者模型:
○ 线程池里面使用,用于存放任务,这个任务可以分优先级(使用优先级队列)
○ 延时队列:用于解决延时任务
● 扩展知识点:在 Kafka 里面怎么搞延时消息?
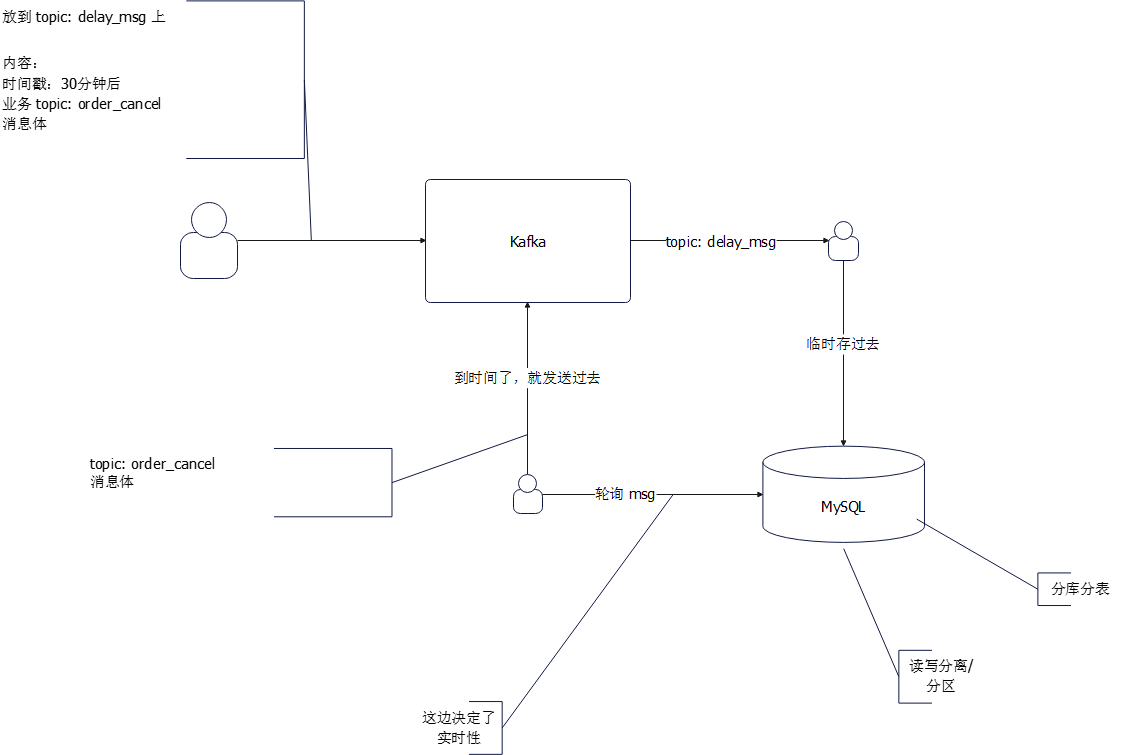
● 如果要你设计一个并发队列,你会考虑一些什么场景,或者说考虑一些什么因素?
○ 是否带缓冲
■ 不带缓冲:阻塞的情况更加严重,并没有达到生产者与消费者完全解耦的效果
■ 带缓冲,能否动态扩容/缩容
● 具备动态扩容:可以有比较小的初始化容量,后期按需扩容,节约资源
● 具备动态缩容:节约内存
○ 是否阻塞:看同步还是异步,看调用者需求
○ 阻塞是否有超时控制
■ 很多业务能接受阻塞一段时间,但是不能接受一直阻塞;
■ 带超时控制可以防止资源泄露:
○ 队列是否支持优先级
○ 高性能
○ 并发安全
○ 可靠性
● 分布式队列(or 消息队列)
○ 高可靠
○ 高可用
○ 高性能
● 让你来设计并发队列的接口,你会怎么设计?
○ 使用 context.Context 来做超时控制:
■ 灵活
■ 嵌进去了链路里面

若有收获,就点个赞吧
0 人点赞
