基本语法
声明
基本语法:
声明:**<font style="color:rgb(51, 51, 51);">var</font>** a [len]**<font style="color:rgb(51, 51, 51);">type</font>**
初始化
初始化:左边——全局<font style="color:rgb(51, 51, 51);">var a =</font>/ 局部<font style="color:rgb(51, 51, 51);">a :=</font> + 右边——数值<font style="color:rgb(51, 51, 51);">[len]type{...,...}</font>
实例
全局:var arr0 = [5]int{1, 2, 3}var arr1 = [5]int{1, 2, 3, 4, 5}var arr2 = [...]int{1, 2, 3, 4, 5, 6}var str = [5]string{3: "hello world", 4: "tom"}局部:a := [3]int{1, 2} // 未初始化元素值为 0。b := [...]int{1, 2, 3, 4} // 通过初始化值确定数组长度。//注意省略也是要。。。c := [5]int{2: 100, 4: 200} // 使用索引号初始化元素。//类型为结构,这是一维度数组d := [...]struct {name stringage uint8}{{"user1", 10}, // 可省略元素类型。{"user2", 20}, // 别忘了最后一行的逗号!!!}

总结
- 全局
var a/ 局部a:= - 由于数组是值类型,声明与初始化为零值作用相同
- 声明
**<font style="color:rgb(51, 51, 51);">var</font>** a [len]**<font style="color:rgb(51, 51, 51);">type</font>** - 初始化为零值:
**<font style="color:rgb(51, 51, 51);">var a = [5]type{}</font>**/a := [len]type{..., ...}
如果是多维数组,则 类型改成[len_1][len_2]type{{...}, {...}}
- 声明
- 初始化
- {}怎么塞?
- 一维数组
- 不完全赋值
[5]int{1, 2, 3}/[5]string{3: "hello world", 4: "tom"} - 完全赋值
[5]int{1, 2, 3, 4, 5}/[...]int{1, 2, 3, 4, 5, 6}
- 不完全赋值
- 多维数组
[2][3]int{{1, 2, 3}, {7, 8, 9}}- 可省略第一个
[...][3]int{{1, 2, 3}, {7, 8, 9}}
- 一维数组
- 用下标,挨个赋值
arr [i] =
- {}怎么塞?
- 组合
**类型——注意一下struct类型
**
性质
数组:是同一种数据类型的固定长度的序列。
- 不可变性
数组长度必须是常量,且是类型的组成部分。一旦定义,长度不能变。 - 访问
- 数组可以通过下标进行访问,下标是从0开始,
arr[i],最后一个元素下标是:len-1 - 访问越界,如果下标在数组合法范围之外,则触发访问越界,会panic
- 数组可以通过下标进行访问,下标是从0开始,
- 类型
- 数组是值类型
- 赋值和传参会复制整个数组,而不是指针。因此改变副本的值,不会改变本身的值。
- 支持 “==”、“!=” 操作符,一方面因为是值,可比较,另一方面因为内存总是被初始化过的。
- 长度
长度是数组类型的一部分,因此,**<font style="color:rgb(51, 51, 51);">var</font>** a[<font style="color:rgb(0, 128, 128);">5</font>] **<font style="color:rgb(51, 51, 51);">int</font>**和**<font style="color:rgb(51, 51, 51);">var</font>** a[<font style="color:rgb(0, 128, 128);">10</font>]**<font style="color:rgb(51, 51, 51);">int</font>**是不同的类型。 - 类型选择
类型不仅可以是int/foalt,还可以是struct类型 - 类型格式:
指针数组[n]*T,数组指针*[n]T。
- 数组是值类型
- 内置函数 len 和 cap 都返回数组长度 (元素数量)。

基本应用
数组的截取
:::info
:::

注意
a[2:len(a)] 等价于 a[2:]- 不支持负数索引 如
a[-1:] - 数组截取之后一定是切片
多维数组
:::info 声明/初始化
:::
- 编写原则和一维数组相同,就是注意数值是
[len_1][len_2]type{{...}, {...}}
全局var arr0 [5][3]intvar arr1 [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}var arr1 = [...][3]int{{1, 2, 3}, {7, 8, 9}}局部:a := [2][3]int{{1, 2, 3}, {4, 5, 6}}b := [...][2]int{{1, 1}, {2, 2}, {3, 3}} // 第 2 纬度不能用 "..."。//方便不数数//可直接打印fmt.Println(a, b)
- 更直观的写法

注意:以上代码中倒数第二行的 } 必须要有逗号,因为最后一行的 } 不能单独一行,也可以写成这样:
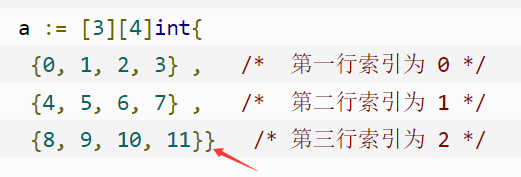
:::info 创建一个各维度数不一样的多维数组
:::
没有初始化的数组元素值为0(数值0会显示,字符零值为""不显示)

结果

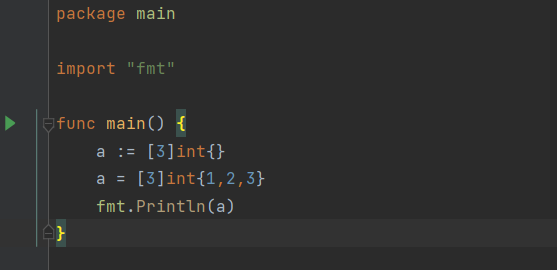
空数组
- 声明一个空数组,后面可以给其赋值
- 不可用append函数
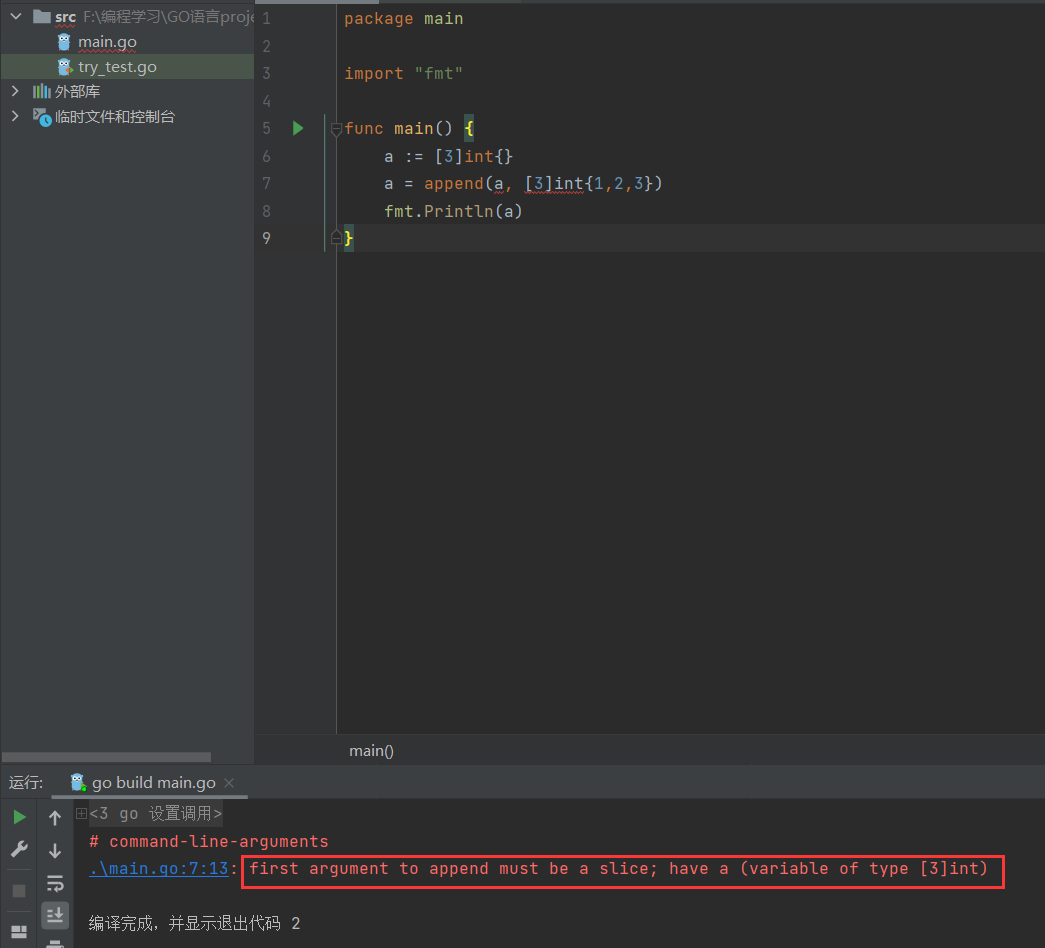
函数参数
:::info 数组做参数
:::
数组由于是值类型,给函数传递参数,本质是值传递,即实参的值复制给形参,副本怎么修改不改变原本数组的值
:::info 数组指针做参数
:::
那上面情况怎么改变呢?——数组指针
package mainimport "fmt"func main(){a := [5]int{1,2,3,4,5}modify(&a)fmt.Println(a)}func modify(p *[5]int){(*p)[2] = 100//*p就等价与数组a了}
这里注意
p = &a那么*p就等同于数组a,(*p)[3]就是数组的第三号元素
(之前有个特别不好的,就是*p = &a[2],由于go指针不支持和整数的算术运算,所以只能指向该元素,不可改变)
与c语言的差别
| c语言 | go语言 | |
|---|---|---|
| 语法 | type name [维数] 如int a[10] |
**<font style="color:rgb(51, 51, 51);">var</font>** a [len]**<font style="color:rgb(51, 51, 51);">int</font>**,比如:**<font style="color:rgb(51, 51, 51);">var</font>** a [<font style="color:rgb(0, 128, 128);">5</font>]**<font style="color:rgb(51, 51, 51);">int</font>** |
| 类型 | arr会自动转换成地址/指针 | go的数组是值类型,可以进行数值比较 要得到指针只有&arr[i] |
遍历/访问
for…range
关于for …range 是 go 自身的语法,可以用来遍历数据结构,有如下数据结构可以遍历
- 切片 slice
- 数组 array
- map 集合
- channel 通道
我们分别来看看可以如何使用他们,for…range 相当于一个迭代器,可以遍历数据结构的键/索引 和值
:::info 数组array
:::
for index, v := range arr_1 {}
获得的 index和v分别是数组arr_1的索引和值,index从 0 到 len(arr_1) - 1
一维数组遍历
for i := 0; i < len(a); i++ {}for index, v := range a {}
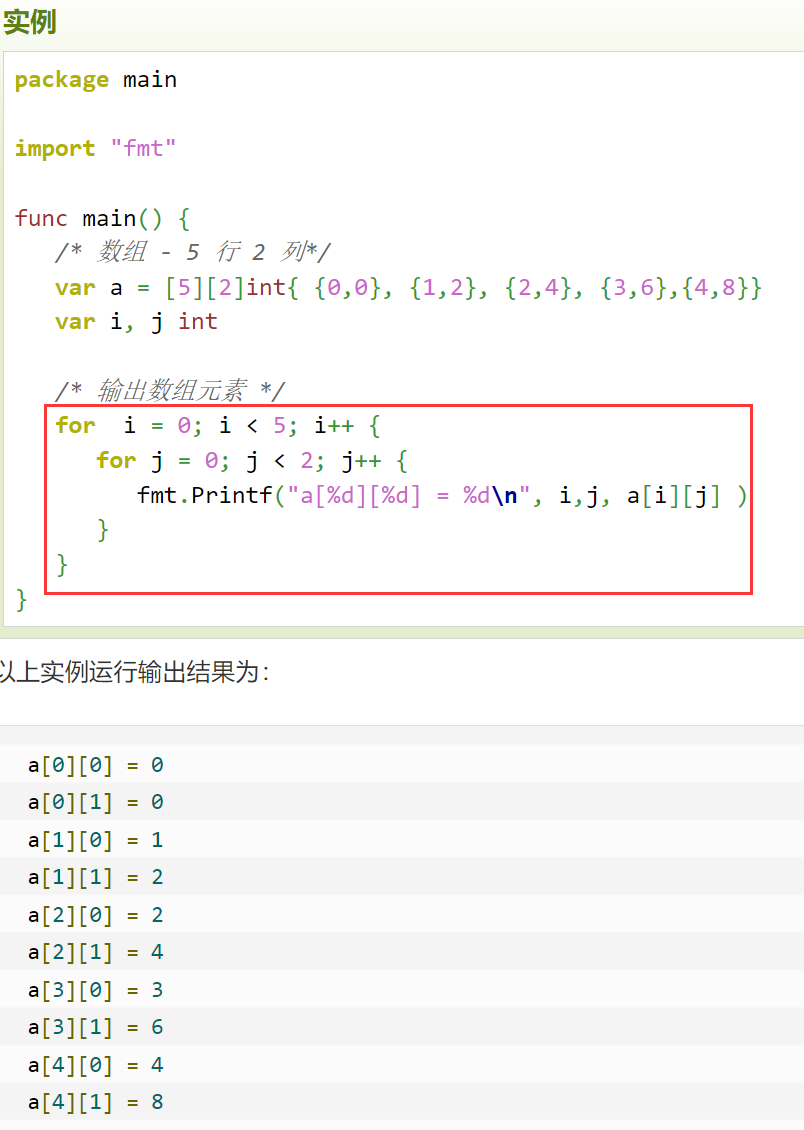
多维数组的遍历
传统方式:
常用方式——for..range:
package mainimport ("fmt")func main() {var f [2][3]int = [...][3]int{{1, 2, 3}, {7, 8, 9}}for k1, v1 := range f {for k2, v2 := range v1 {fmt.Printf("(%d,%d)=%d ", k1, k2, v2)}fmt.Println()}}

注意:Printf 与 Println区别
修改
通过指针修改
package mainimport "fmt"func main() {s := []int{0, 1, 2, 3}p := &s[2] // *int, 获取底层数组元素指针。*p += 100fmt.Println(s)}
通过下标
arr[i] = 10
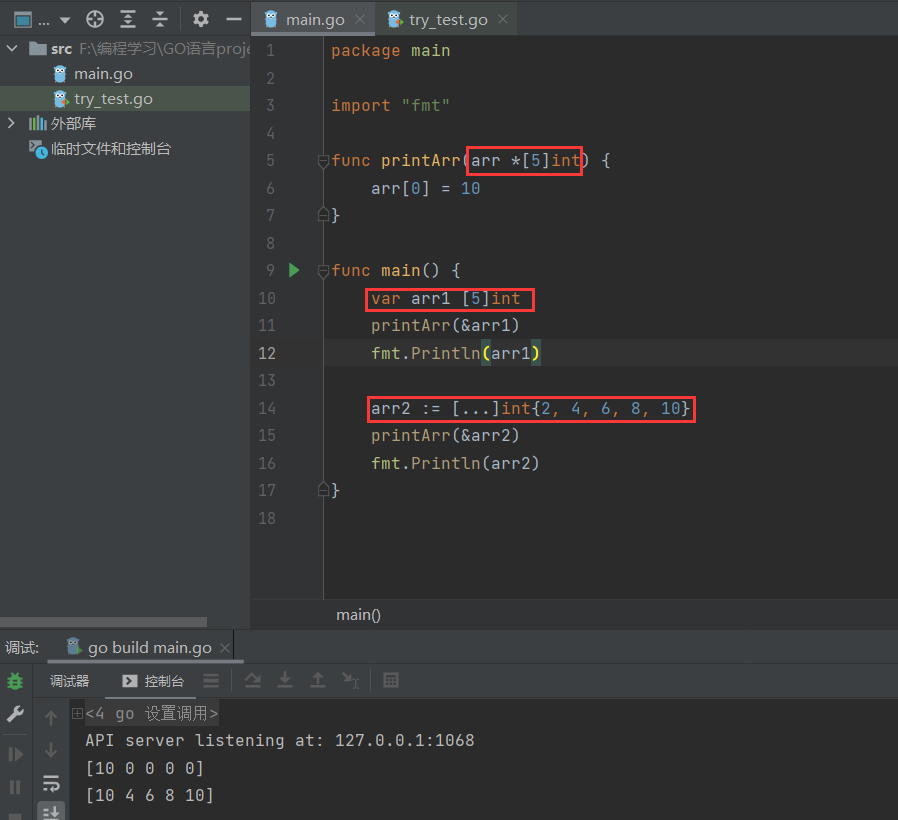
数组的拷贝和传参
涉及到指针
传参
- 值拷贝行为会造成性能问题,通常会建议使用 slice,或数组指针。

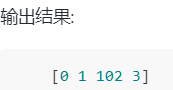
如果用切片会怎么样呢?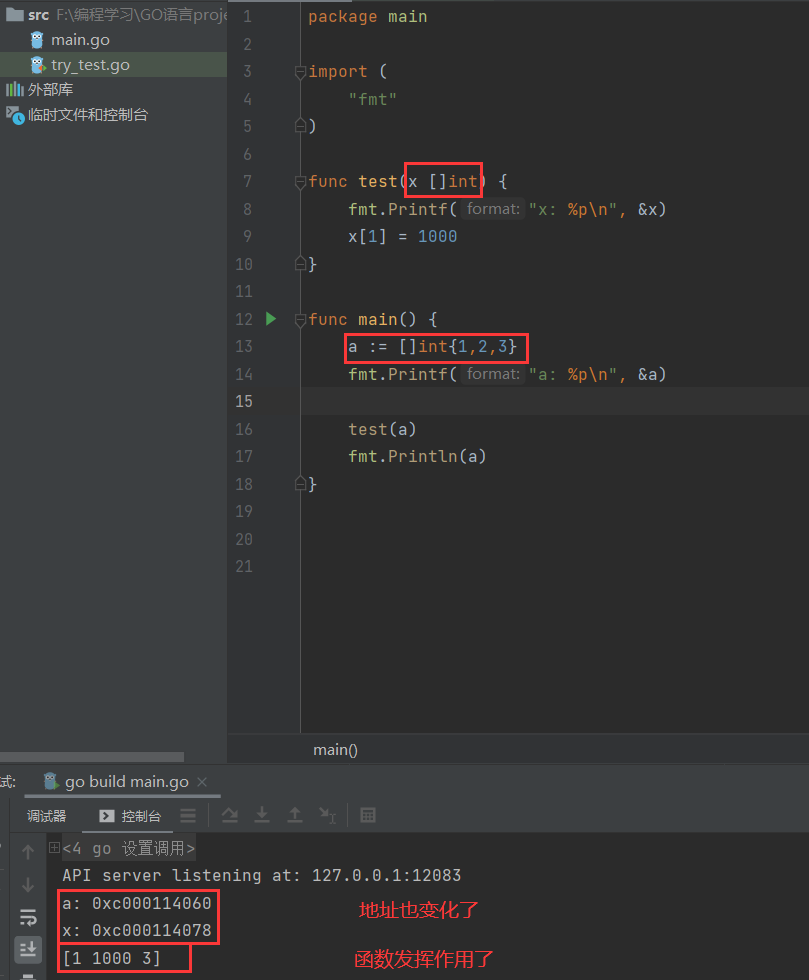
- 若想通过自定义修改数组,那就需要指针
拷贝
拷贝问题见切片,会有具体的对比
练习
随机数
:::info 如何产生随机数?——三步
:::
- 引入包
import "math/rand" - 设置种子
rand.Seed(参数),那么设置什么参数呢?- 参数性质:
如果种子的参数不变,那么每次程序go run/go build一次, 产生的随机数, 那都是一样的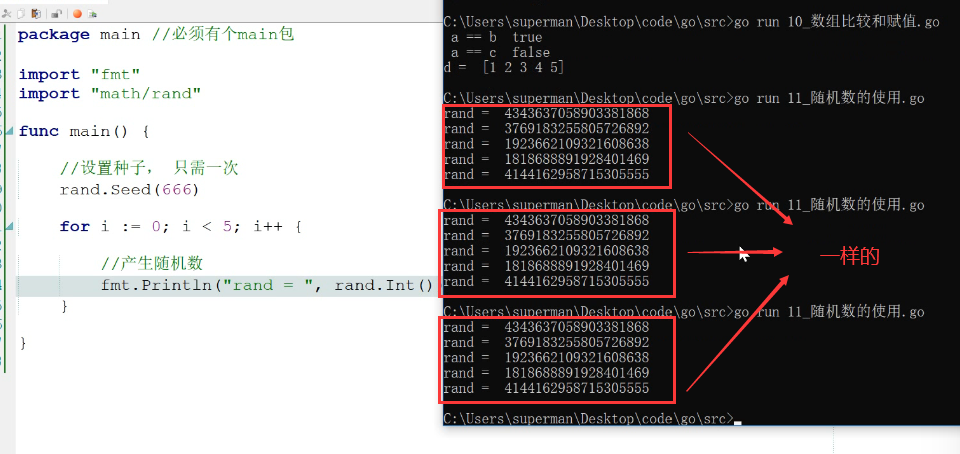
- 所以我们常常把当前时间当作种子参数,方法如下
- 引入包
import "time" rand.Seed(time.Now().UnixNano)
- 引入包
- 参数性质:
- 产生随机数
- 产生随机的数,通常数值很大,
rand.Int() - 在一定范围内产生随机数 ,比如在100以内
rand.Intn(100)
- 产生随机的数,通常数值很大,
package mainimport "fmt"import "math/rand"import "time"func main() {rand.Seed(time.Now().UnixNano)//时间作为参数for i :=100; i<5; i++{fmt.Println("rand = ", rand.Intn(100))//随机数范围在100以内}}
为什么上例我不显示结果,但下面的例子我显示了结果
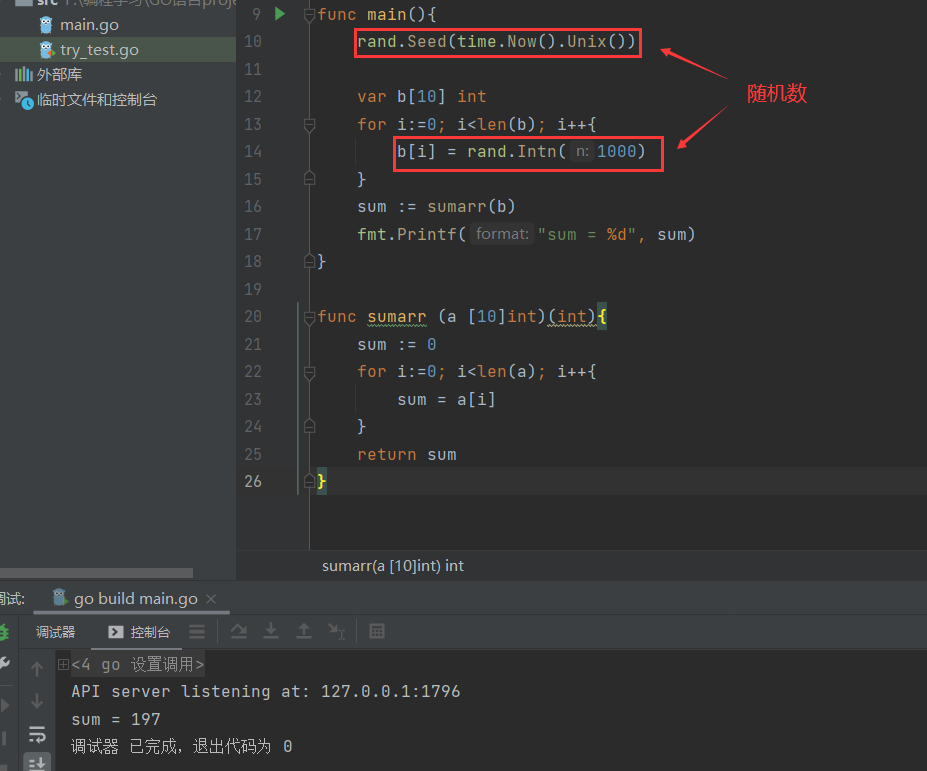
func main(){// 若想做一个真正的随机数,要种子// seed()种子默认是1//rand.Seed(1)rand.Seed(time.Now().Unix())var b[10] intfor i:=0; i<len(b); i++{b[i] = rand.Intn(1000)// 产生一个0到1000随机数}sum := sumarr(b)fmt.Printf("sum = %d", sum)}func sumarr (a [10]int)(int){sum := 0for i:=0; i<len(a); i++{sum = a[i]}return sum}
冒泡排序
求最大小值,我遇到的,就是 for + if ,遇到最大/最小的,就留下
原理
- n个数,循环n-1次,设 i ∈[0, n-1]
- 第 i 次循环,比其的范围是[0, n-i-1],设 j ,j∈[0, n-i-1],每比一次,都可以把最大/最小的数,放到第i次比的范围的最右边,每比一次,范围缩小一个数( i + j = n-1)
代码实现
比如用随机数造一个元素个数为10的数组
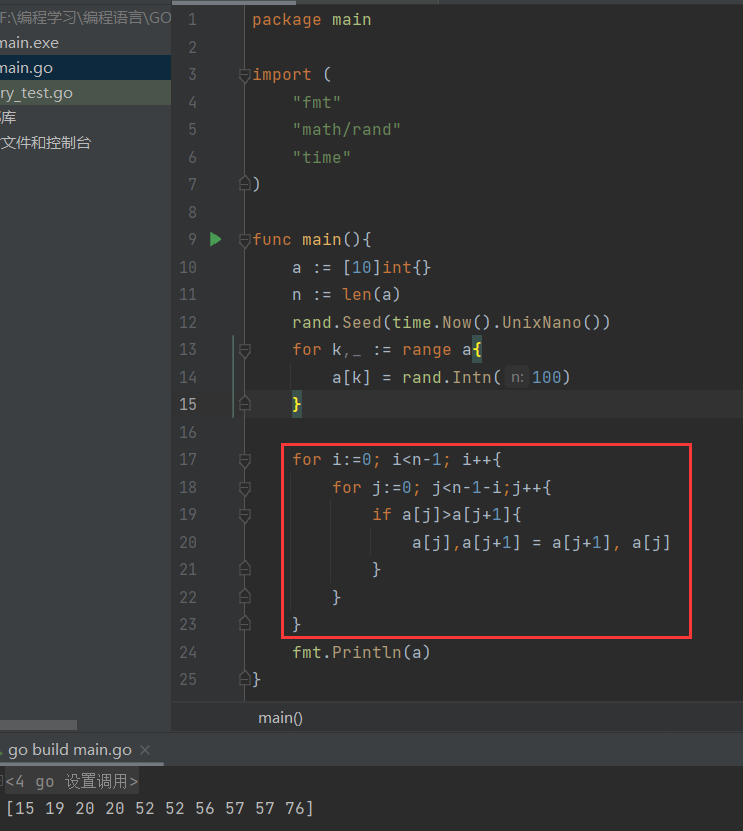
package mainimport ("fmt""math/rand""time")func main(){a := [10]int{}n := len(a)rand.Seed(time.Now().UnixNano())for k,_ := range a{a[k] = rand.Intn(100)}for i:=0; i<n-1; i++{for j:=0; j<n-1-i;j++{if a[j]>a[j+1]{//从小到达和从大到小,在这改变一下大小于号就行a[j],a[j+1] = a[j+1], a[j]}}}fmt.Println(a)}
给一数组a,给一常数b,要求在数组a中找两个元素之和 = b,算出下标
package mainimport "fmt"// 找出数组中和为给定值的两个元素的下标,例如数组[1,3,5,8,7],// 找出两个元素之和等于8的下标分别是(0,4)和(1,2)// 求元素和,是给定的值func myTest(a [5]int, target int) {// 遍历数组for i := 0; i < len(a); i++ {other := target - a[i]// 继续遍历for j := i + 1; j < len(a); j++ {if a[j] == other {fmt.Printf("(%d,%d)\n", i, j)}}}}func main() {b := [5]int{1, 3, 5, 8, 7}myTest(b, 8)}

若有收获,就点个赞吧
0 人点赞
