Compare
继承是 Postgers 提供的很独特的特性,一般来说,继承是面向对象的编程语言才会有的概念,但是 Postgres 为了减少数据库与编程语言之间模型的差异性,也增加了继承,让应用模型与数据库模型更相似,减少了开始时思维的转换。
PostgreSQL 中的继承是指表的继承,就像下面所示,每个车都有他们公共的属性,比如颜色,名字,目前的位置等,但是每辆车也都有他们特别的属性,比如货车会有装载量,自行车会有车架的尺寸等。对于这些公共的部分,可以抽离出 Vehicles 表,而对于特殊的属性,可以单独创建一个特殊的 Bikes 表,只需要继承自 Vehicles,就拥有 Vehicles 的所有字段。
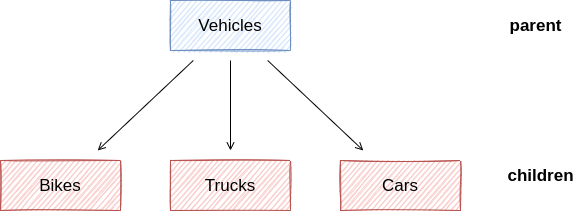
图 1: Verhicles
CREATE TABLE vehicles(name text PRIMARY KEY,color text,weight float,area text, -manufacturerid int);CREATE TABLE bikes(size float NOT NULL) INHERITS(vehicles);
正常的关系型数据库中,对于 Bikes, Trucks, Cars 三类车辆来说,只需要三张表就可以了,而这里需要四张表,一眼看上去这里的复杂性还提高了。
如果需要查询所有颜色为红色的车辆,对于没有继承的表来说,需要查询三张表,然后将结果结合起来
SELECT * FROM bikes WHERE color = 'red'UNIONSELECT * FROM trucks WHERE color = 'red'UNIONSELECT * FROM cars WHERE color = 'red';
而对于继承的表来说,Vehicles 中有这三个表共有的列,所以只需要
SELECT * FROM vehicles;
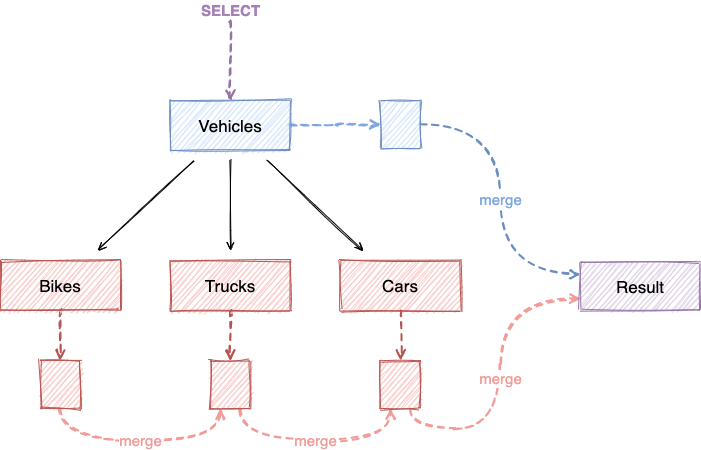
图 2: Select
其实如果单单针对这个问题,可以使用是视图,如果需要性能的话,物化视图也是一个选择,但是如果考虑系统的扩展性,需要再增加新的车辆类型的表,对于支持继承的数据库来说,直接从父表再创建新表就可以,但是如果基于视图的实现,需要重新修改视图,重写视图的 SQL 语句。
现在看上去继承确实很像一个自动更新的视图,父表也是一个表完整的表,也可以向它里面单独添加数据,甚至给它添加主键,约束等。
CRUD
SELECT
如果对父表使用 SELECT * FROM vehicles; 会将子表中的数据也返回出来,需要使用 ONLY 关键字仅查看父表中的数据。如果对子表使用 ONLY 是没有作用的。
SELECT * FROM ONLY vehicles;
查看二者的执行计划,如果没有加 ONLY 的话,需要将子表全部都扫描一遍,而且查看子表的字段的话,发现他自身是包含所有字段的。所以继承出来的子表就是包含所有字段的完整的表,而父表中是不会保存子表的数据的,查询是获取到全部数据的原始是将所有的表都扫描过。
EXPLAIN ANALYZE SELECT * FROM ONLY vehicles-- Seq Scan on vehicles (cost=0.00..1.60 rows=60 width=108) (actual time=0.005..0.005 rows=1 loops=1)-- Planning Time: 0.341 ms-- Execution Time: 0.020 msEXPLAIN ANALYZE SELECT * FROM vehicles-- Append (cost=0.00..57.10 rows=1740 width=108) (actual time=0.008..0.036 rows=14 loops=1)-- -> Seq Scan on vehicles vehicles_1 (cost=0.00..1.60 rows=60 width=108) (actual time=0.007..0.008 rows=1 loops=1)-- -> Seq Scan on bikes vehicles_2 (cost=0.00..15.60 rows=560 width=108) (actual time=0.016..0.017 rows=4 loops=1)-- -> Seq Scan on cars vehicles_3 (cost=0.00..15.60 rows=560 width=108) (actual time=0.003..0.004 rows=6 loops=1)-- -> Seq Scan on trucks vehicles_4 (cost=0.00..15.60 rows=560 width=108) (actual time=0.002..0.003 rows=3 loops=1)-- Planning Time: 0.534 ms-- Planning Time: 0.534 ms
INSERT
有了上面的结论,其他的就都好理解了,父表和子表都支持单独插入数据,都不会产生其他副作用,只有当查询父表信息的时候,会将子表都扫描一遍,看上去就像是插入子表的时候,也在父表中插入了数据。
那么如果再父表中插入的时候,父表中没有这个列名,但是子表中有,会不会自动插入到子表中呢?
INSERT INTO vehicles(name, color, weight, area, manufacturerid, size)VALUES ('trucks004', 'RED', 1400, '上海', 1001, 20);-- column "size" of relation "vehicles" does not exist
UPDATE & DELETE
对于访问和修改子表中才有的字段,必须通过子表进行修改,访问公共的字段,或者通过公共字段进行删除,可以通过父表进行。也就是说下面这两个 SQL 语句效果上是一样的。
UPDATE vehicles SET color = 'YELLOW' WHERE name = 'bike001';UPDATE bikes SET color = 'YELLOW' WHERE name = 'bike001';
但是实际上,第一条语句会扫描 vehicles 表和其全部子表,这里的性能肯定是弱于下面的语句的。
Constrains
子表只会继承检查约束和非空约束,其他约束都不会被继承。也就是说在父表中定义的主键外键都不会生效。
按理说每一个表都需要主键,如果继承出来的子表能够包含父表中的主键其实也挺好的,但是根据继承的实现来看,每一个子表都是独立完整的表,而且一个表可以继承自多个表,如果多个表都有主键的话就不好处理了。而且主键约束,外键约束等可以看作是表级的约束,而继承只是继承了父表中的字段。但是当有任何一个子表存在时,父表不能被删除。当子表的列或者检查约束继承于父表时,它们也不能被删除或修改。
如果需要为子表添加主键或者其他约束条件,可以将这些添加在子表特有的字段中,或者在创建完子表之后再在上面添加约束。
:::success 可以将约束分为几类:
- 只和当前行有关的:非空约束,检查约束
- 和整个表有关的:唯一约束,排他约束,主键约束
- 和其他表有关的:外键约束,主键约束(可能)
其中,第一类可以被继承,因为在插入的时候不需要考虑其他列的情况,而第二种如果被继承,无法保证父表和子表中所有的都是唯一的。
第二类在插入数据的时候需要关心整个表中的数据,为了提高效率,这一类约束通常都会自带索引,唯一约束和主键约束会自动创建 B 树索引,排他约束会创建 Gist 索引,
第三类和其他表有关的,除了插入的时候有副作用,在级联删除的时候也会产生效果。 :::
Alter
使用 ALTER TABLE 命令既可以解除原有的表继承关系,又可以重新构建新的继承关系。
ALTER TABLE bikes NO INHERIT vehicles;ALTER TABLE bikes INHERIT vehicels;
:::warning 必须子表和父表的字段和约束相同才能建立继承关系。 :::

若有收获,就点个赞吧
0 人点赞
