Logical Backup
pg_dump
pg_dump -h 192.168.0.251 -p 5432 -U root -W -d postgres -t person > postgres.sql
默认情况下会生成一个 SQL 文件, 这个文件会通过 Stdout 的方式输出出来, 当然也可以通过 -f 参数来指定输出文件
pg_dump -h 192.168.0.251 -p 5432 -U root -W -d postgres -t person -f postgres.sql
使用 pg_dump 进行备份的时候, 是不需要担心数据对与新备份的影响的, pg_dump 最后的结果是 pg_dump 开始运行时刻数据库的快照, pg_dump 是不会阻塞其他对于数据库的操作的, 同样运行时产生的更新也是不会被保存的.
sql
下面是生成的 postgres.sql 的一部分内容, 可以看到这个文件中不但有数据, 而且也有建表语句, 索引创建语句, 权限语句等.
---- PostgreSQL database dump---- Dumped from database version 13.3 (Debian 13.3-1.pgdg100+1)-- Dumped by pg_dump version 13.3SET statement_timeout = 0;SET lock_timeout = 0;SET idle_in_transaction_session_timeout = 0;SET client_encoding = 'UTF8';SET standard_conforming_strings = on;SELECT pg_catalog.set_config('search_path', '', false);SET check_function_bodies = false;SET xmloption = content;SET client_min_messages = warning;SET row_security = off;SET default_tablespace = '';SET default_table_access_method = heap;---- Name: person; Type: TABLE; Schema: public; Owner: root--CREATE TABLE public.person (id integer NOT NULL,first_name character varying NOT NULL,last_name character varying NOT NULL,sex character varying NOT NULL,birth_date date NOT NULL,weight integer NOT NULL,height integer NOT NULL,update_time timestamp with time zone NOT NULL);ALTER TABLE public.person OWNER TO root;---- Name: person_id_seq; Type: SEQUENCE; Schema: public; Owner: root--CREATE SEQUENCE public.person_id_seqAS integerSTART WITH 1INCREMENT BY 1NO MINVALUENO MAXVALUECACHE 1;ALTER TABLE public.person_id_seq OWNER TO root;---- Name: person_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: root--ALTER SEQUENCE public.person_id_seq OWNED BY public.person.id;---- Name: person id; Type: DEFAULT; Schema: public; Owner: root--ALTER TABLE ONLY public.person ALTER COLUMN id SET DEFAULT nextval('public.person_id_seq'::regclass);---- Data for Name: person; Type: TABLE DATA; Schema: public; Owner: root--COPY public.person (id, first_name, last_name, sex, birth_date, weight, height, update_time) FROM stdin;1 Hunter Halvorson male 2004-06-13 66 61 2006-05-24 11:32:33+002 Sigrid Kub male 2002-06-09 10 70 2010-11-18 08:50:07+003 Alta Luettgen male 2006-07-31 336 73 1986-07-16 12:10:13+004 Nestor Schulist female 1999-03-12 171 24 2004-04-08 21:09:24+005 Carolyn Yundt female 2003-06-18 275 72 2013-05-25 08:31:50+00-- data9999 Tod Metz female 2011-04-20 70 72 2007-06-11 01:49:57+0010000 Keyon Larson female 1999-01-28 99 21 1987-11-05 01:46:57+00\.---- Name: person_id_seq; Type: SEQUENCE SET; Schema: public; Owner: root--SELECT pg_catalog.setval('public.person_id_seq', 10000, true);---- Name: person person_pkey; Type: CONSTRAINT; Schema: public; Owner: root--ALTER TABLE ONLY public.personADD CONSTRAINT person_pkey PRIMARY KEY (id);---- PostgreSQL database dump complete--
这里使用的数据复制语句并不是用的 INSERT 而是 COPY, 这也是 Postgres 自己提供的特性, 所以这个 SQL 文件只能给 PostgreSQL 使用, 其他数据库要用的话需要可以添加上 —inserts.当然前面的那些设置配置参数的, 还有建表语句同样不能用.
INSERT INTO public.person VALUES (1, 'Hunter', 'Halvorson', 'male', '2004-06-13', 66, 61, '2006-05-24 11:32:33+00');INSERT INTO public.person VALUES (2, 'Sigrid', 'Kub', 'male', '2002-06-09', 10, 70, '2010-11-18 08:50:07+00');INSERT INTO public.person VALUES (3, 'Alta', 'Luettgen', 'male', '2006-07-31', 336, 73, '1986-07-16 12:10:13+00');INSERT INTO public.person VALUES (4, 'Nestor', 'Schulist', 'female', '1999-03-12', 171, 24, '2004-04-08 21:09:24+00');INSERT INTO public.person VALUES (5, 'Carolyn', 'Yundt', 'female', '2003-06-18', 275, 72, '2013-05-25 08:31:50+00');INSERT INTO public.person VALUES (6, 'Ethyl', 'Stiedemann', 'male', '2005-04-16', 143, 72, '1988-01-11 17:00:25+00');INSERT INTO public.person VALUES (7, 'Enrico', 'Kiehn', 'female', '2001-12-07', 28, 22, '2005-07-19 10:55:44+00');INSERT INTO public.person VALUES (8, 'Vincenza', 'Moen', 'female', '1990-12-09', 143, 28, '1994-11-16 13:30:25+00');INSERT INTO public.person VALUES (9, 'Gideon', 'Wisozk', 'male', '1988-05-19', 84, 66, '1985-08-17 13:47:22+00');INSERT INTO public.person VALUES (10, 'Stacey', 'Hyatt', 'male', '2013-12-08', 115, 48, '2012-07-07 19:32:00+00');INSERT INTO public.person VALUES (11, 'Jade', 'Trantow', 'male', '2009-05-03', 32, 68, '2007-11-02 17:22:24+00');INSERT INTO public.person VALUES (12, 'Lurline', 'Bahringer', 'female', '1992-06-30', 31, 23, '1983-09-21 15:45:38+00');INSERT INTO public.person VALUES (13, 'Bryana', 'Lubowitz', 'female', '2003-03-05', 115, 49, '2002-11-19 11:13:51+00');INSERT INTO public.person VALUES (14, 'Jaida', 'Turner', 'female', '1989-07-18', 184, 58, '1993-05-07 14:00:56+00');
custom
除了 sql 的文件各式, pg_dump 还支持将数据导出为它自定义的各式, 这需要通过 -Fc 进行指定
pg_dump -h 192.168.0.251 -p 5432 -U root -W -d postgres -t person -Fc > postgres.dump
生成的特定各式的文件比 sql 的文件各式更加紧凑, 对于这个 10000 行的表, 只占用了五分之一的体积.
-rw-r--r-- 1 dovics dovics 248K 8月 11 14:06 postgres.dump-rw-r--r-- 1 dovics dovics 1.2M 8月 11 13:54 postgres.sql-rw-r--r-- 1 dovics dovics 656K 8月 11 14:08 postgres.tar
这是因为在使用自定义格式的时候, 会使用 zlib 压缩库对其进行压缩, 和使用 gzip 的压缩效率是差不多的, 但是它相比于 gzip 压缩有一个明显的优势, 可以选择性的恢复里面的数据表.
directory
pg_dump -h 192.168.0.251 -p 5432 -U root -W -d postgres -t person -Fd -f postgres
文件夹中的数据如下所示, 其中 3013.dat.gz 中就是表中的数据
-rw-r--r-- 1 dovics dovics 245K 8月 11 14:53 3013.dat.gz-rw-r--r-- 1 dovics dovics 3.0K 8月 11 14:53 toc.dat
1 Hunter Halvorson male 2004-06-13 66 61 2006-05-24 11:32:33+002 Sigrid Kub male 2002-06-09 10 70 2010-11-18 08:50:07+003 Alta Luettgen male 2006-07-31 336 73 1986-07-16 12:10:13+004 Nestor Schulist female 1999-03-12 171 24 2004-04-08 21:09:24+005 Carolyn Yundt female 2003-06-18 275 72 2013-05-25 08:31:50+006 Ethyl Stiedemann male 2005-04-16 143 72 1988-01-11 17:00:25+007 Enrico Kiehn female 2001-12-07 28 22 2005-07-19 10:55:44+008 Vincenza Moen female 1990-12-09 143 28 1994-11-16 13:30:25+009 Gideon Wisozk male 1988-05-19 84 66 1985-08-17 13:47:22+00
为了转储一个大型数据库, 可以使用 pg_dump 的并行模式, 这也就是 pg_dump 支持将数据导出到文件夹的原因, 对于一个文件我们是很难采用并行模式进行写入的
pg_dump -h 192.168.0.251 -p 5432 -U root -W -d postgres -t person -Fd -f postgres -j 4
pg_dumpall
使用 pg_dump 时, 必须通过 -d 来指定需要进行备份的数据库, 而且不会存储 user 和 role 的任何信息, 这是因为 Postgres 的 User 是存储在 Database Cluster 级别的, 只是备份到数据库级别是没法备份用户信息的.
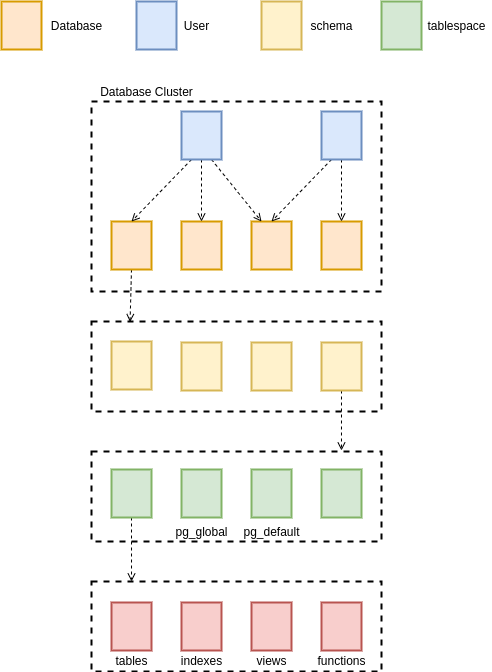
图二: Database Cluster
pg_dumpall 就是为了备份整个数据库的, 它生成的 sql 文件中, 会包含创建用户和权限所有命令. pg_dumpall 和 pg_dump 的参数基本上是一样的, 也可以连接远程数据库, 也可以生成多种类型的备份文件.
pg_dump -h 192.168.0.251 -p 5432 -U root -W -d postgres -t person -Fd -f postgres
为什么 pg_dump 和 pg_dumpall 默认都采用了将数据输出到标准输出的方法?
pg_restore
对于使用 postgres 生成的特定的文件, 只能采用 pg_restore 进行恢复
pg_restore -h 192.168.0.251 -p 5432 -U root -W -d postgres postgres.dump
同样 pg_restore 也支持使用并行模式进行恢复, 但是这不单可以用于文件夹, 也可以用在自定义各式中.
pg_restore -h 192.168.0.251 -p 5432 -U root -W -d postgres postgres.dump -j 4
不过 pg_restore 不支持通过 sql 文件进行恢复, 想要使用 sql 文件,还是需要 psql
psql -f postgres.sql
Physical Backup
对于物理备份最朴素的想法就是将整个数据库在文件系统中的文件进行打包复制, PostgreSQL 将所有的配置文件和数据文件都放在目录 $PGDATA 中.
tar -cf backup.tar /usr/local/pgsql/data
但是这样的备份方法必须将数据库停止, 因为在外部调用 tar 无法保证数据库状态不变, 即使屏蔽了所有的外部连接也不行, 数据库再空闲时也会有很多后台进程在运行, 保存下来的快照可能是不一致的, 这无法用户恢复数据库, 同理恢复数据库之前也需要关闭服务器.
另外这样复制的灵活性并不高, 无法单独的恢复一个数据库或者是一个表.
如果想要使用物理复制的方法,还需要依赖数据库的支持,Postgres 提供了外部工具 pg_basebackup 和 内部函数 pg_start_back_up 和 pg_stop_backup 来支持,非阻塞的复制
pg_basebackup
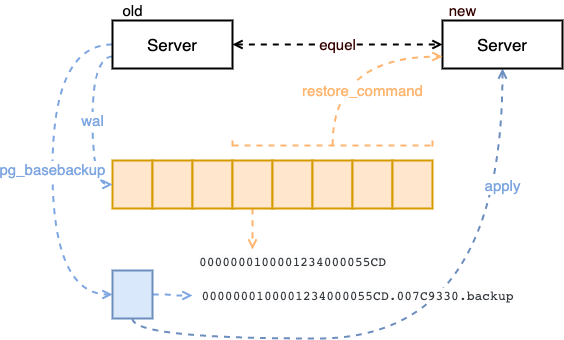
图三:pg_basebackup
使用 pg_basebackup 生成备份文件非常简单,基本只需要指定备份保存的文件目录。pg_basebackup 也是一个 postgresql 客户端,所以在进行复制的时候也可以从远程主机上开始,另外需要注意一点生成的归档文件的名字,与恢复时需要复制的 wal 日志的第一个 segment 的名字是一样的。
pg_basebackup -D ./pg_data -Fp -Xs -v -P -h 192.168.0.251 -U root -W
另外,pg_basebackup 不会阻塞数据库其他操作,也就是可以在数据库运行期间进行备份,这段时间产生的变化,都会记录在新产生的 wal 日志中。
Exclusive Low-level Backup
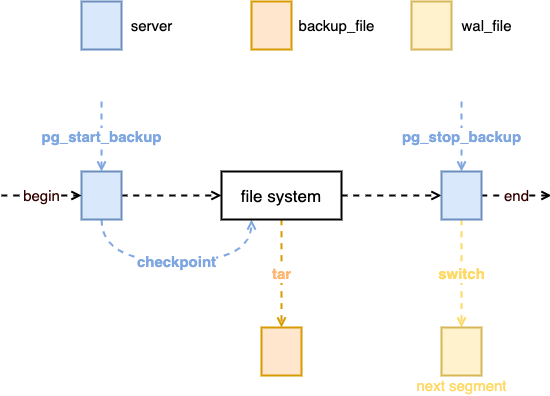
图四:exclusive_low_level_backup
这里的 Exclusive 翻译为中文就是非排他的,也就是在执行这个操作的时候同样不会阻塞其他的操作。
整个备份过程分为三部分,首先进行 pg_start_backup, 执行这条命令时,数据库会产生一个 checkpoint,将所有的脏页都刷新回磁盘中,然后用户使用任意一个归档命令,比如 tar,将数据库文件打包,打包完成后调用 pg_stop_backup, 结束这次备份。

若有收获,就点个赞吧
0 人点赞
