并行查询,第一次听到以为就是多个事务同时执行,其实这里的并行查询是指一个查询中,使用多个线程并行进行查询,从而获得更高的查询性能。
Parallel Scan
Sequential Scan
EXPLAIN ANALYSE SELECT * FROM test_big1 WHERE name='1_test';-- Gather (cost=1000.00..628080.77 rows=1 width=25) (actual time=63.351..1092.629 rows=1 loops=1)-- Workers Planned: 2-- Workers Launched: 2-- -> Parallel Seq Scan on test_big (cost=0.00..627080.67 rows=1 width=25) (actual time=724.787..1065.790 rows=0 loops=3)-- Filter: ((name)::text = '1_test'::text)-- Rows Removed by Filter: 16666666-- Planning Time: 0.309 ms-- JIT:-- Functions: 6-- Options: Inlining true, Optimization true, Expressions true, Deforming true-- Timing: Generation 0.832 ms, Inlining 131.329 ms, Optimization 37.092 ms, Emission 20.006 ms, Total 189.259 ms-- Execution Time: 1151.737 msSET max_parallel_workers_per_gather = 0;EXPLAIN ANALYSE SELECT * FROM test_big1 WHERE name='1_test';-- Seq Scan on test_big (cost=0.00..991664.00 rows=1 width=25) (actual time=60.364..2980.227 rows=1 loops=1)-- Filter: ((name)::text = '1_test'::text)-- Rows Removed by Filter: 49999999-- Planning Time: 0.074 ms-- JIT:-- Functions: 2-- Options: Inlining true, Optimization true, Expressions true, Deforming true-- Timing: Generation 0.253 ms, Inlining 40.945 ms, Optimization 12.837 ms, Emission 6.468 ms, Total 60.504 ms-- Execution Time: 3022.296 ms
正常情况下,顺序查询只需要一个 Seq Scan 节点就可以了,如果是开启了并行查询,就是允许打开多个 Seq Scan,然后最后通过一个 Gather 节点,将所有的结果结合起来。
max_parallel_workers_per_gather 指每次 gather 最多是用到的后台工作线程的数量,这里将这个参数设置为 0, 就是不允许并行查询了。这里的 test_big 表有 50,000,000 条数据,并行查询的速度几乎是原来的三分之一。通过 Benchmark 测试,所得到的结果相差不大。
go test -bench='^(Benchmark*)' ./parallel/parallel_test.go -benchtime=60sgoos: linuxgoarch: amd64cpu: Intel(R) Core(TM) i3-9100F CPU @ 3.60GHzBenchmarkParallelQuery-4 60 1111487091 ns/opBenchmarkNoParallelQuery-4 22 2892573886 ns/opPASSok command-line-arguments 134.604s
:::warning
为什么并行查询只使用了两个后台线程,时间却变成原本的三分之一?
当前进程的主线程也会负责一部分数据查询。
:::
是否使用并行查询是优化器进行决定的,并不是所有查询并行之后都有优化,只有那些需要搜索的数目特别多,但是需要返回条目的并不多的才需要使用并行查询。有关于并行查询的代价常量有下面这些:
parallel_tuple_cost = 0.1parallel_setup_cost = 1000.0min_parallel_table_scan_size = 8MBmin_parallel_index_scan_size = 512kB
并行主要提升的是运算效率,而不是 IO 速率,如果每一条数据都需要进行读取,优化器也不会选择进行并行查询
EXPLAIN ANALYSE SELECT * FROM test_big;-- Seq Scan on test_big (cost=0.00..866664.00 rows=50000000 width=25) (actual time=0.018..15297.111 rows=50000000 loops=1)-- Planning Time: 0.043 ms-- Execution Time: 16607.608 ms
Index Scan
EXPLAIN ANALYZE SELECT COUNT(name) FROM test_big WHERE id < 10000000;-- Finalize Aggregate (cost=308461.81..308461.82 rows=1 width=8) (actual time=814.356..821.219 rows=1 loops=1)-- -> Gather (cost=308461.59..308461.80 rows=2 width=8) (actual time=814.240..821.211 rows=3 loops=1)-- Workers Planned: 2-- Workers Launched: 2-- -> Partial Aggregate (cost=307461.59..307461.60 rows=1 width=8) (actual time=773.128..773.129 rows=1 loops=3)-- -> Parallel Index Scan using idx_test_big_id on test_big (cost=0.56..297133.64 rows=4131181 width=13) (actual time=0.029..546.479 rows=3333333 loops=3)-- Index Cond: (id < 10000000)-- Planning Time: 0.075 ms-- JIT:-- Functions: 17-- Options: Inlining false, Optimization false, Expressions true, Deforming true-- Timing: Generation 2.606 ms, Inlining 0.000 ms, Optimization 0.747 ms, Emission 11.907 ms, Total 15.260 ms-- Execution Time: 822.556 ms
EXPLAIN ANALYZE SELECT COUNT(name) FROM test_big WHERE id < 10000000;-- Aggregate (cost=379757.27..379757.28 rows=1 width=8) (actual time=2223.418..2223.419 rows=1 loops=1)-- -> Index Scan using idx_test_big_id on test_big (cost=0.56..354970.18 rows=9914835 width=13) (actual time=0.037..1574.698 rows=9999999 loops=1)-- Index Cond: (id < 10000000)-- Planning Time: 4.493 ms-- JIT:-- Functions: 5-- Options: Inlining false, Optimization false, Expressions true, Deforming true-- Timing: Generation 0.438 ms, Inlining 0.000 ms, Optimization 0.254 ms, Emission 3.202 ms, Total 3.894 ms-- Execution Time: 2287.465 ms
可以看到这里也是只消耗了三分之一的时间。而且这里还用到了并行聚集函数,将 COUNT 操作划分开,最后再聚合在一起。
在正常情况下,进行并行索引扫描是比较困难的,因为必须要求索引足够大才行,所以这里使用并行聚合间接导致了并行索引扫描,对这个表单纯的进行索引扫描并不会使用并行查询
EXPLAIN ANALYZE SELECT * FROM test_big WHERE id = 1;-- Index Scan using idx_test_big_id on test_big (cost=0.56..8.58 rows=1 width=25) (actual time=0.030..0.031 rows=1 loops=1)-- Index Cond: (id = 1)-- Planning Time: 0.399 ms-- Execution Time: 0.093 ms
Index Only Scan
Index 是指只是用到了索引的扫描,因为这里只需要索引中的数据,不需要进行回表,所以速度会更快。
EXPLAIN ANALYZE SELECT COUNT(*) FROM test_big WHERE id < 10000000;-- Finalize Aggregate (cost=25147.94..25147.95 rows=1 width=8) (actual time=69.908..72.459 rows=1 loops=1)-- -> Gather (cost=25147.72..25147.93 rows=2 width=8) (actual time=69.869..72.454 rows=3 loops=1)-- Workers Planned: 2-- Workers Launched: 2-- -> Partial Aggregate (cost=24147.72..24147.73 rows=1 width=8) (actual time=65.425..65.426 rows=1 loops=3)-- -> Parallel Index Only Scan using idx_test_big_id on test_big (cost=0.56..23085.50 rows=424890 width=0) (actual time=0.059..46.002 rows=333333 loops=3)-- Index Cond: (id < 1000000)-- Heap Fetches: 0-- Planning Time: 0.582 ms-- Execution Time: 72.541 ms
Parallel Join
Nested Loop
Nested Loop 的中文翻译叫做嵌套翻译,也就是循环中还包含其他循环。首先从较小的表中,将数据取出来,然后对这些数据进行遍历,从稍大的表中获取到对应的数据。对于嵌套连接使用并行的的过程如下图所示
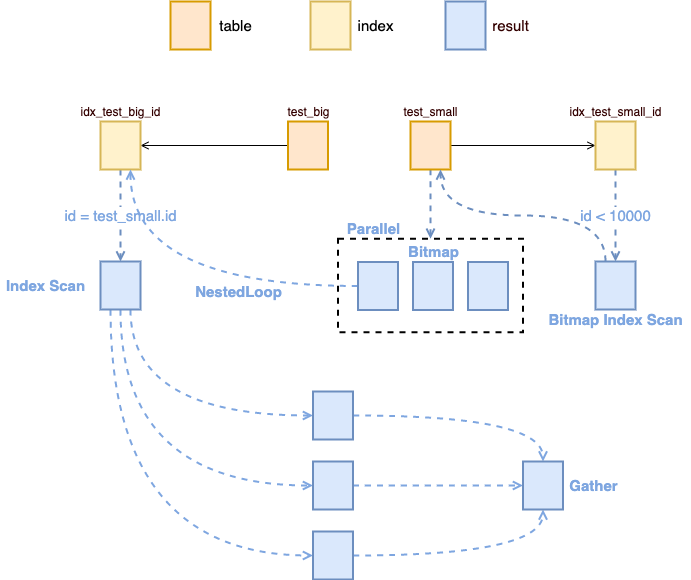
图1:Nested Loop
下面这个例子中使用了嵌套查询
EXPLAIN ANALYZESELECT test_big.nameFROM test_big, test_smallWHERE test_big.id = test_small.idAND test_small.id < 10000;-- Gather (cost=1189.67..61534.50 rows=9893 width=13) (actual time=214.445..1197.429 rows=9999 loops=1)-- Workers Planned: 2-- Workers Launched: 2-- -> Nested Loop (cost=189.67..59545.20 rows=4122 width=13) (actual time=71.271..164.950 rows=3333 loops=3)-- -> Parallel Bitmap Heap Scan on test_small (cost=189.10..24918.56 rows=4122 width=4) (actual time=71.264..77.680 rows=3333 loops=3)-- Recheck Cond: (id < 10000)-- Heap Blocks: exact=55-- -> Bitmap Index Scan on idx_test_small_id (cost=0.00..186.63 rows=9893 width=0) (actual time=110.349..110.350 rows=9999 loops=1)-- Index Cond: (id < 10000)-- -> Index Scan using idx_test_big_id on test_big (cost=0.56..8.39 rows=1 width=17) (actual time=0.026..0.026 rows=1 loops=9999)-- Index Cond: (id = test_small.id)-- Planning Time: 491.008 ms-- Execution Time: 1197.945 ms
Merge Join
Merge Join 的过程是从多个表中分别选出对应的数据,然后分别进行判断。 Nested Loop 和 Merge Join 相比 Nested Join 需要让其中一个表比较小,这样遍历小表的代价就比较低,这个时候才能拿小表的结果从大表中获取值。并发如下所示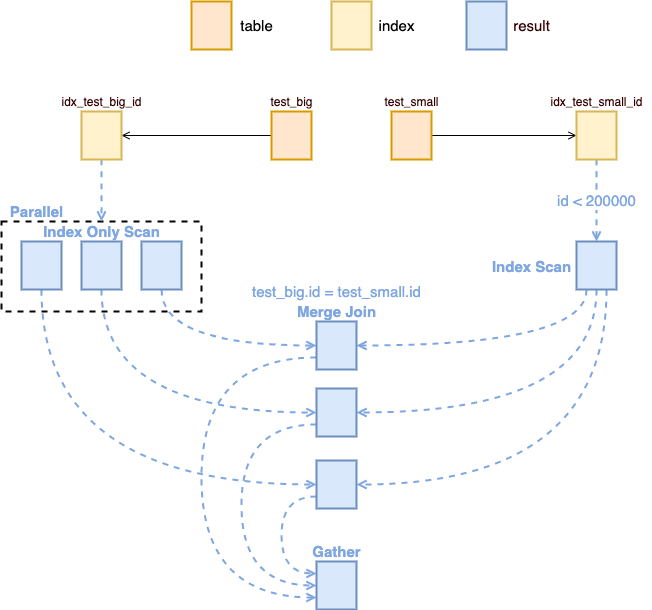
图2:Merge Join
将上面的 Nested Join 的例子中的 id 限制调大,就可以变为 Merge Join 了
EXPLAIN ANALYZESELECT test_small.nameFROM test_big, test_smallWHERE test_big.id = test_small.idAND test_small.id < 200000;-- Gather (cost=1003.91..198417.04 rows=199472 width=13) (actual time=7.942..112.188 rows=199999 loops=1)-- Workers Planned: 2-- Workers Launched: 2-- -> Merge Join (cost=3.91..177469.84 rows=83113 width=13) (actual time=11.463..71.879 rows=66666 loops=3)-- Merge Cond: (test_big.id = test_small.id)-- -> Parallel Index Only Scan using idx_test_big_id on test_big (cost=0.56..1006729.35 rows=20833308 width=4) (actual time=0.033..6.408 rows=66667 loops=3)-- Heap Fetches: 0-- -> Index Scan using idx_test_small_id on test_small (cost=0.43..6951.19 rows=199472 width=17) (actual time=0.035..32.868 rows=199999 loops=3)-- Index Cond: (id < 200000)-- Planning Time: 0.415 ms-- JIT:-- Functions: 21-- Options: Inlining false, Optimization false, Expressions true, Deforming true-- Timing: Generation 2.076 ms, Inlining 0.000 ms, Optimization 0.993 ms, Emission 13.567 ms, Total 16.636 ms-- Execution Time: 166.989 ms
Parallel Hash Join
Hash Join 一般用于没有索引的表,这时候先对较小的表中每一条数据进行 Hash,然后与大表中的值一一对比,这样对于小表来说,只需要遍历一遍,对于大表来说也只需要遍历一遍,剩余的只是需要比较 Hash 值。
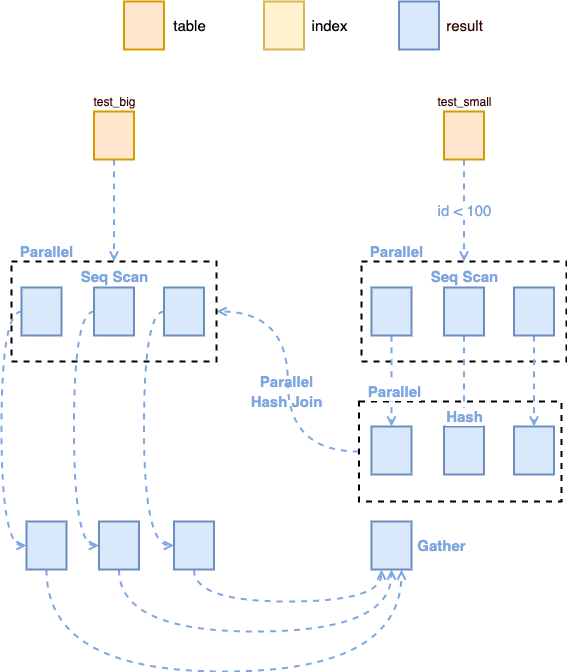
图3:Parallel Hash Join
哈希连接因为是在没有索引的情况下执行的,所以需要先将索引都删除,删除索引之后可以看到查询的效率降低了特别多。
DROP INDEX idx_test_big_id;DROP INDEX idx_test_small_id;EXPLAIN ANALYZESELECT test_small.nameFROM test_big JOIN test_smallON (test_big.id = test_small.id)AND test_small.id < 100;-- Gather (cost=93532.11..746735.48 rows=800 width=13) (actual time=598.101..149936.080 rows=99 loops=1)-- Workers Planned: 2-- Workers Launched: 2-- -> Parallel Hash Join (cost=92532.11..745655.48 rows=333 width=13) (actual time=100133.934..149912.037 rows=33 loops=3)-- Hash Cond: (test_big.id = test_small.id)-- -> Parallel Seq Scan on test_big (cost=0.00..574997.08 rows=20833308 width=4) (actual time=0.005..147858.039 rows=16666667 loops=3)-- -> Parallel Hash (cost=92527.94..92527.94 rows=333 width=17) (actual time=577.510..577.511 rows=33 loops=3)-- Buckets: 1024 Batches: 1 Memory Usage: 40kB-- -> Parallel Seq Scan on test_small (cost=0.00..92527.94 rows=333 width=17) (actual time=531.732..577.472 rows=33 loops=3)-- Filter: (id < 100)-- Rows Removed by Filter: 2666634-- Planning Time: 0.438 ms-- JIT:-- Functions: 36-- Options: Inlining true, Optimization true, Expressions true, Deforming true-- Timing: Generation 2.631 ms, Inlining 515.555 ms, Optimization 699.317 ms, Emission 110.611 ms, Total 1328.114 ms-- Execution Time: 149980.934 ms

若有收获,就点个赞吧
0 人点赞
