Redis 的单线程模型一直被人津津乐道,结果到了前段时间的 6.0 版本发布,大家开始说 Redis 变为多线程了,但是还是有人说 Redis 仍然是单线程的,为什么会产生这两种分歧呢?
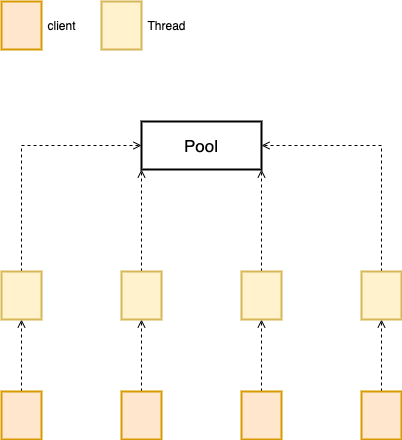
Redis 仍然是 Client-Server 的架构,所有的操作都需要根据客户端的请求去执行,一般情况下,网络编程中的多线程就是每一个请求,都创建一个线程去处理,可能这里会有线程池来进行复用。
图一:multiple thread
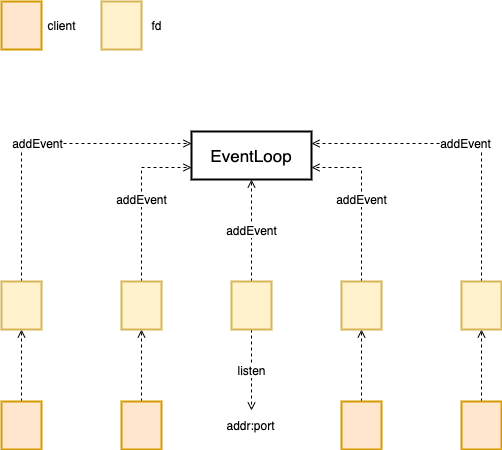
这样的一个模型可以很好的利用网络,对于每一个请求都可以及时的去处理,这也带来了一些新的问题,就是内存的并发访问,不能让多个线程同时操作同一块内存,解决这个问题的方法有很多,但是降低运行效率是不可避免的,而且还会给系统带来很高的复杂度,所以最开始的 Redis 选择了单线程 + IO 多路复用的模式。
图二:multiplexing
Epoll
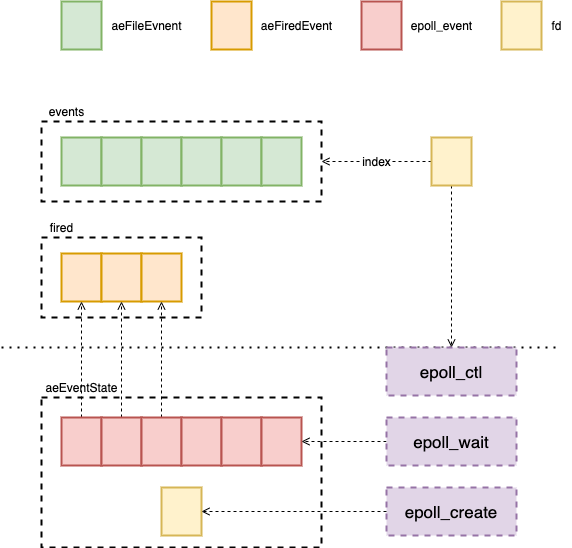
对于 Linux 来说这里的 IO 多路复用机制就是 epoll 了,每个平台有不同的多路复用机制,windows 的叫做 kqueue,redis 为了屏蔽他们底层的不同抽象出了 EventLoop,将各自实现的不同的数据存储到 aeEventState 字段里,这里最重要的是两个数组,一个是 events 存储着所有的 fd,另一个是fired,这里是所有被触发的 fd,表示里面有数据需要读取或者写入。
图三:epoll overview
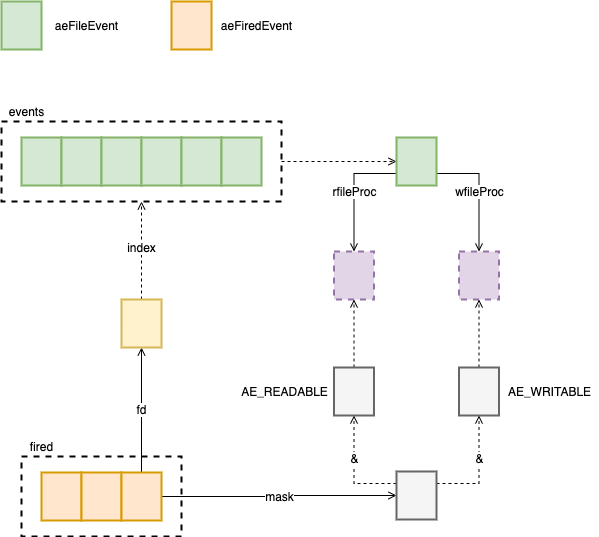
对于每一个 fired 中的数据,通过 fd 找到其对应的 aeFileEvent,然后调用其对应的处理函数。处理完所有的 firedEvent 之后,就可以再次监听新的事件。这样 redis 就实现了单线程服务多个客户端了。
图四:proc
int aeProcessEvents(aeEventLoop *eventLoop, int flags){// ...numevents = aeApiPoll(eventLoop, tvp);// ...for (j = 0; j < numevents; j++) {aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];int mask = eventLoop->fired[j].mask;int fd = eventLoop->fired[j].fd;if (!invert && fe->mask & mask & AE_READABLE) {fe->rfileProc(eventLoop,fd,fe->clientData,mask);fired++;fe = &eventLoop->events[fd]; /* Refresh in case of resize. */}if (fe->mask & mask & AE_WRITABLE) {if (!fired || fe->wfileProc != fe->rfileProc) {fe->wfileProc(eventLoop,fd,fe->clientData,mask);fired++;}}// ...}// ...return processed;}
Multithreading
Redis 多线程也并不是说处理线程变成多线程了,Redis 现在遇到的问题并不是计算速度不够,而是网络 I/O 的速度不够。
那这些线程是每次读取的时候就启动一个,然后读取完成之后就销毁了吗?这样做肯定浪费了很多资源,征程情况下,我们应该有一个线程池进行线程的复用。Redis 在启动时会先创建多个线程,然后等待各自的信号,一旦接收到信号就去各自的队列中拿取 Client 进行处理。
这里的 io_threads_list, io_threads_list, io_threads 全部都是全局变量,专门用来存储多线程读取。Server 会先将需要读取的放到 client_pending_read 中,然后在需要读取的时候,将其分配到不同的队列中,等待不同的线程进行读取,对于第一个队列,是主线程负责读取的。读取完成后会持续查看其他的 io_threads_pending,等到它们全为 0 的时候,就是读取完成了。
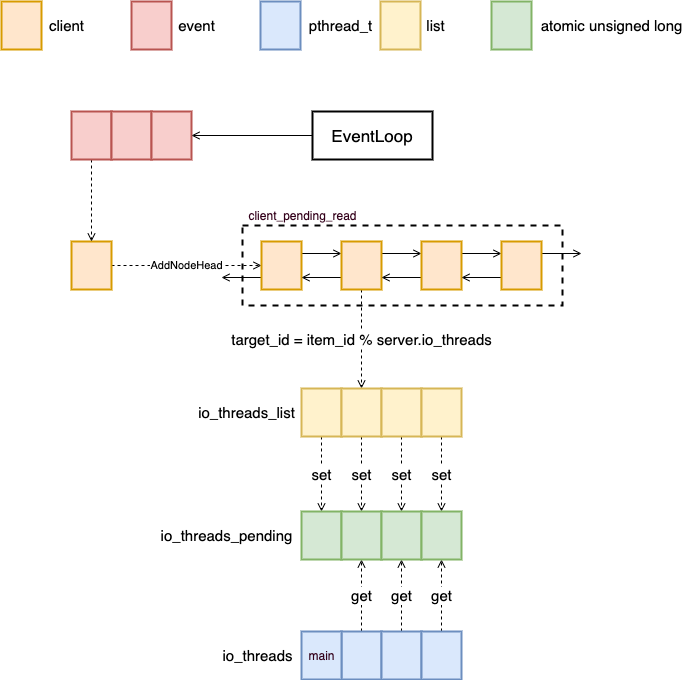
图五:multithreading overview
另外对于 IO 来说,是有两种情况的,读还有写,所以需要一个标志位来查看现在到底应该做什么,这个标志位就是 io_threads_op ,它是一个全局变量,每次执行是都会被检查。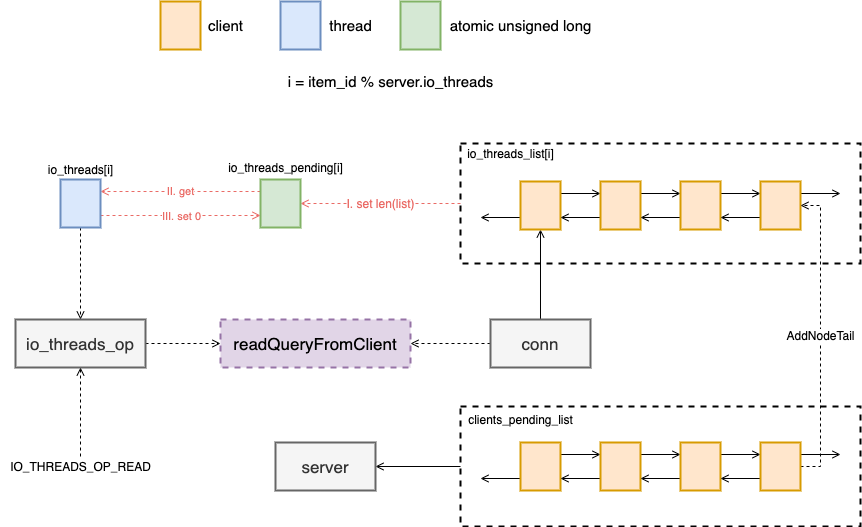
图六:multithreading read
对于每一个线程运行的都是下面的函数,就是一直查看自己的 io_threads_pending 有没有值,一旦有值就开始进行处理。
void *IOThreadMain(void *myid) {while(1) {for (int j = 0; j < 1000000; j++) {if (getIOPendingCount(id) != 0) break;}// ...listIter li;listNode *ln;listRewind(io_threads_list[id],&li);while((ln = listNext(&li))) {client *c = listNodeValue(ln);if (io_threads_op == IO_THREADS_OP_WRITE) {writeToClient(c,0);} else if (io_threads_op == IO_THREADS_OP_READ) {readQueryFromClient(c->conn);} else {serverPanic("io_threads_op value is unknown");}}listEmpty(io_threads_list[id]);setIOPendingCount(id, 0);}}
这里使用循环调用 getIOPendingCount() 是不是不太好?能不能使用信号量进行代替?
Open Multithreading
默认情况下 redis 并不会打开多线程 io,redis 打开多线程 io 必须在配置文件中修改 io_threads 。对于多线程读和多线程写还有一点区别,多线程读必须在配置里打开 io_threads_do_reads,而多线程写还需要 pending 的线程数大于 2 * io_threads。
io-threads 4io-threads-do-reads yes
redis 官方建议如果有 4 个内核,就将 io-threads 设置为 2 或 3,如果有 8 个内核就设置为 6,至少留下一个备用内核,大于 8 个内核的话,性能提升也不会特别多。

若有收获,就点个赞吧
0 人点赞
