对于一个简单的 KV 数据库,最基本的实现几个简单的接口,能够完成 KV 之间的存储和对应就足够了,但是如果面对复杂的业务场景和更高的性能要求,仅仅使用字符串作为 Value 的类型是不够的。
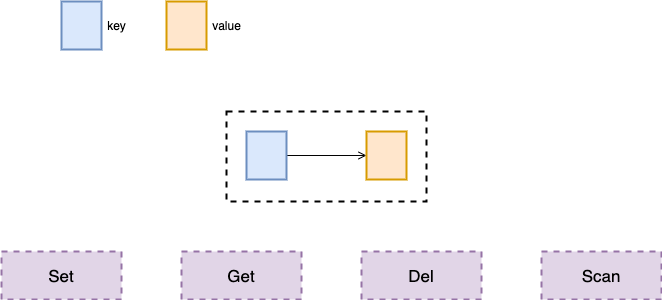
图一:Simple KV Database
Redis 中有 5 种数据类型,它们分别是 String, List, Hash, Sorted Set, Set,每种都有与其对应的特定方法。Redis 能够在实际业务场景中得到广泛的应用,就是得益于支持多样化类型的 value。不同 value 类型的实现,不仅可以支撑不同业务的数据需求,而且也隐含着不同数据结构在性能、空间效率等方面的差异,从而导致不同的 value 操作之间存在着差异。
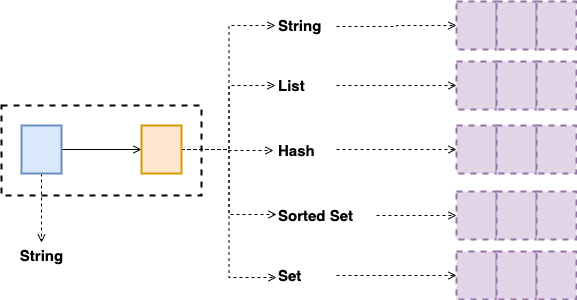
图二:Data Struct And Method
在实现里有一个全局变量 redisCommandTable 存储这全部的 redis 命令和其对应的处理函数,它会在 redis 初始化的时候全部注册到 server 的 commands 中,这是一个字典结构,客户端的请求到来的时候会在里面着对应的命令并且执行。具体的内容会在介绍 Server 的接收流程时介绍。
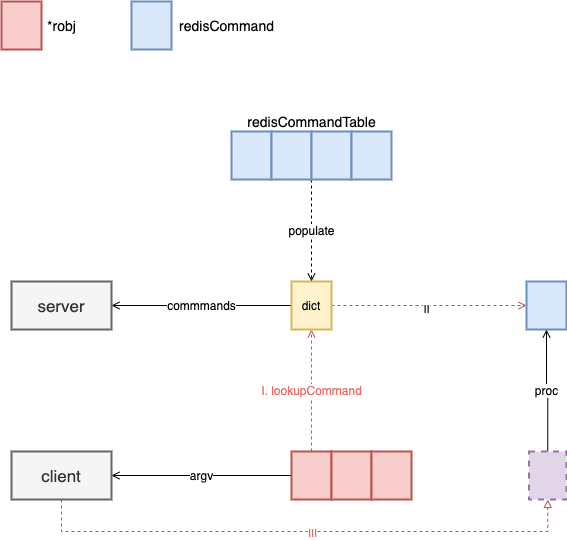
图三:Find Command
数据类型是暴露给用户的,它们还对应这底层的数据结构,根据使用情况的不同,同一数据类型的底层可能有不同的数据结构实现。
SDS
SDS 的意思是简单动态字符串,它和 C 语言中的字符串最重要的区别就是保存了长度和已分配内存大小的信息,所以可以迅速得到字符串长度,并且快速进行扩容(只要不超过已经分配的大小就可以)。
创建一个新的 SDS,首先通过需要使用的 initlen 决定 SDS 的类型,由于每个类型存储长度的字段长度不同,最大能够存储的长度也就有了限制,那么一个 SDS 的类型从初始化之后就不变了吗,如果 SDS 持续增长,类型也应该需要改变。SDS 通过长度去分配不同类型的头部长度,最大限度的减少了内存的浪费。
static inline char sdsReqType(size_t string_size) {if (string_size < 1<<5)return SDS_TYPE_5;if (string_size < 1<<8)return SDS_TYPE_8;if (string_size < 1<<16)return SDS_TYPE_16;#if (LONG_MAX == LLONG_MAX)if (string_size < 1ll<<32)return SDS_TYPE_32;return SDS_TYPE_64;#elsereturn SDS_TYPE_32;#endif}
虽然初始化时也可以提前分配更多的内存,但是 SDS 在初始化的时候,完全按照需要使用的大小进行分配,而没有多余的数据。其实这是更合理的,因为无法确定这个 SDS 是需要频繁更改的,还是基本就作为常量不变了,多分配出去的内存很难回收,等待第一次增长的时候再分配空余空间消耗并不大。
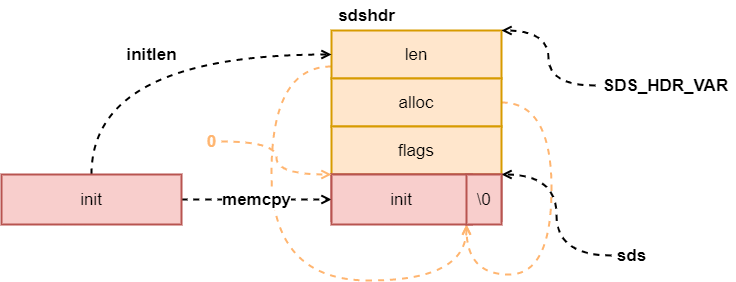
图四:sds new
最后在复制好的字符串后面增加一个 \0 是为了适配 C 语言中的字符串,因为 C 中的字符串就是以 \0 作为结束标志,sds 的指针是指向 buf 数组的,所以 SDS 和 C 标准库中的全部函数都是兼容的。
SDS 既然是动态字符串,也就是说它支持内存的动态增长,_sdsMakeRoomFor 就是给 SDS 增加 addlen 长度,这个函数有两种模式,通过参数 greedy 进行控制,如果 greedy 为 1,则会多分配一些空间,如果 greedy 为 0,仅分配请求的内存,其中 greedy = 1 的情况内部还分为两类,如果最小能够分配的 newlen < SDS_MAX_PREALLOC,会直接将 newlen 扩大两倍,否则多分配 SDS_MAX_PREALLOC 的空间,其实就相当于控制了预分配的上限为 SDS_MAX_PREALLOC,现在这个值是 1M。
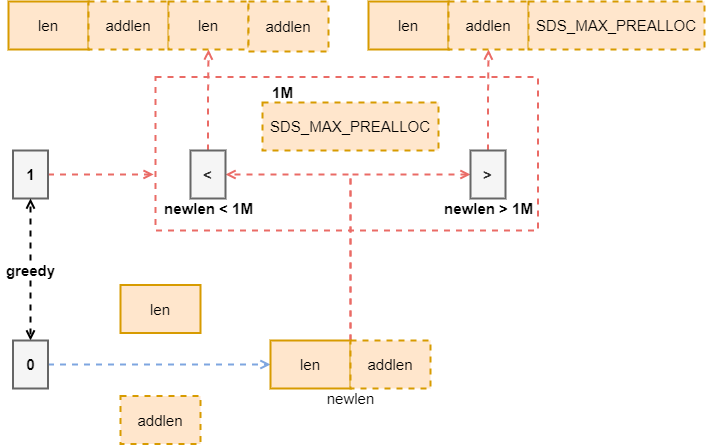
图五:sds newlen
另外如果需要分配的内存超过了原先类型的限制,会将 realloc 变为 malloc,请求新的内存,然后重新初始化 sdshdr 的内容。
if (oldtype==type) {newsh = s_realloc_usable(sh, hdrlen+newlen+1, &usable);if (newsh == NULL) return NULL;s = (char*)newsh+hdrlen;} else {/* Since the header size changes, need to move the string forward,* and can't use realloc */newsh = s_malloc_usable(hdrlen+newlen+1, &usable);if (newsh == NULL) return NULL;memcpy((char*)newsh+hdrlen, s, len+1);s_free(sh);s = (char*)newsh+hdrlen;s[-1] = type;sdssetlen(s, len);}
Adlist
adlist 实际上就是双向链表,结构体定义如下,在这里 list 中除了保存头节点和尾节点之外,还包含了三个函数,分别是 dup 复制,free 释放还有 match 匹配,而且 listnode 中的 value 类型是 void *,所以 value 可以变换成任意类型,只需要通过更改这三个函数就可以存储各种类型。
这其实也是为了保证代码可扩展性的方法,通过这三个方法实现了 listNode 的多态,在其他语言中通常有更加通用的方法,比如 Golang 的接口,rust 提供的泛型都是为了解决这一类问题。
typedef struct listNode {struct listNode *prev;struct listNode *next;void *value;} listNode;typedef struct list {listNode *head;listNode *tail;void *(*dup)(void *ptr);void (*free)(void *ptr);int (*match)(void *ptr, void *key);unsigned long len;} list;
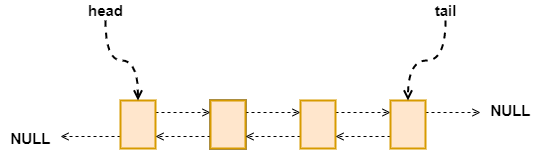
图六:adlist overview
遍历 adlist 有单独的遍历器,通过 listRewind 和 listRewindTail 可以生成两个方向的遍历器,分别是从 head -> tail 和从 tail -> head。
typedef struct listIter {listNode *next;int direction;} listIter;
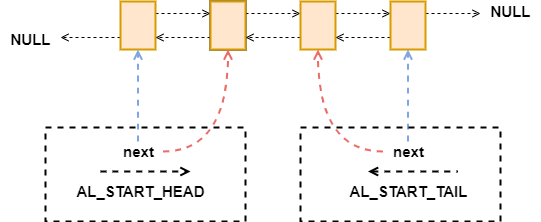
图七:adlist list_iter
Ziplist
zip 是一种压缩方法,ziplist 也正是将 list 进行压缩,从而获得更高的内存利用率。ziplist 对外就是一段字符数组,下面是一个刚创建好的 ziplist,
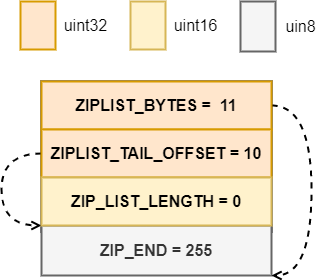
图八:ziplist new
一个完整的 ziplist 如下图所示,使出实际存储在 entry 中,每个 entry 会保存前一个 entry 的长度。
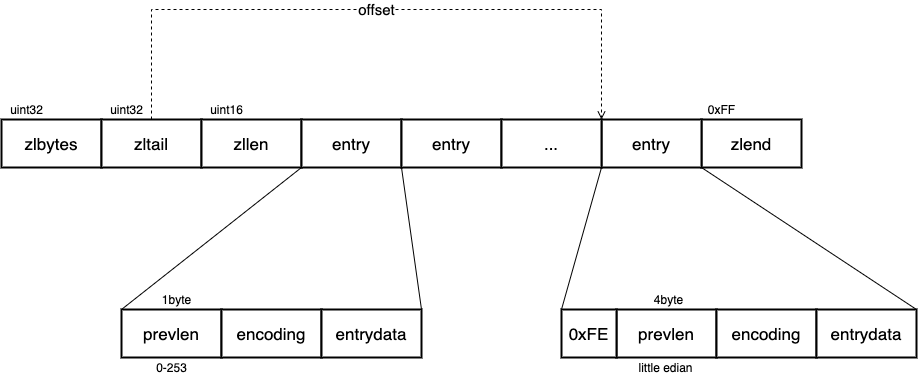
图九:ziplist struct
这里有两个方法插入一个新的 entry,其实也可以说是三种,ziplistPush 通过参数 where 可以选择是插入到头部还是尾部,他们底层调用的都是 __ziplistInsert 函数,可以看到它的参数与 ziplistInsert 完全一样,它会接收一个指针,代表着新插入的 entry 的位置。
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {unsigned char *p;p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);return __ziplistInsert(zl,p,s,slen);}/* Insert an entry at "p". */unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {return __ziplistInsert(zl,p,s,slen);}
另外这里需要注意 ZIPLIST_ENTRY_END 和 ZIPLIST_ENTRY_TAIL 的区别,前者是直接指向最后一个字节也就是 255 的,而后者才是指向最后一个 entry 的。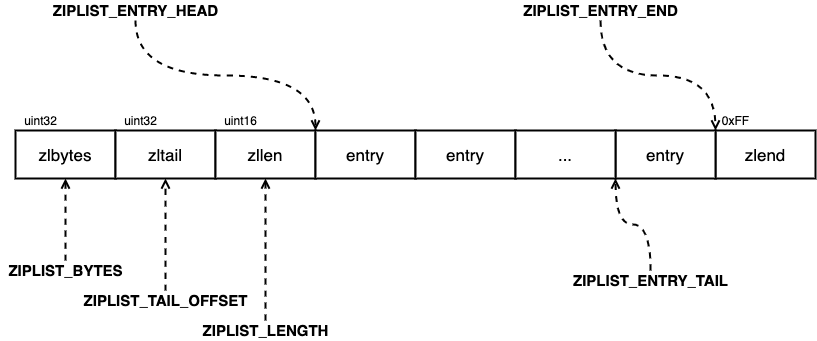
图十:ziplist macro
首先初始化这个函数需要使用的变量。可以看到,这里已经将变量进行初始化了,原因是为了避免编译器 warning,也是使用一个值方便判断 bug 是不是由于未初始化产生的。
然后获取前一个 entry 的长度,作为这个 entry 的 prevlen 的值,这里有两种情况,首先是正常的 p 指向一个 entry,这时候直接通过宏 ZIP_DECODE_PREVLEN 获取 prevlen 的值就行,这里是一个宏调用,宏其实就是直接将当前位置替换为宏中定义的代码,所以这里是不需要传指针的,宏里面每次使用,都是直接使用这个变量。另一种是 p 指向 ZIP_END,这时候需要将前面的 entry 解析出来,然后计算长度。
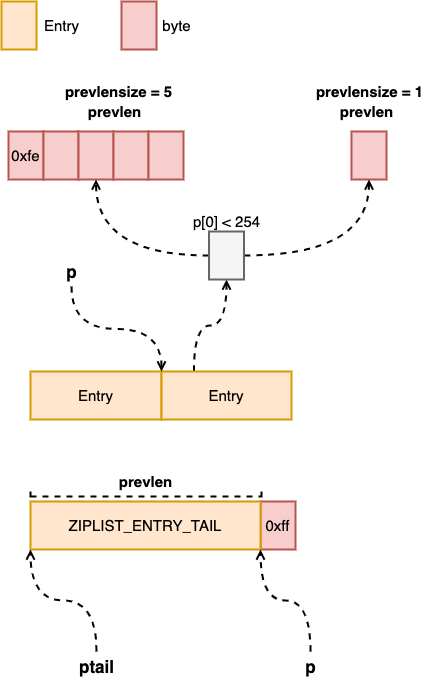
图二:prevlen
每个 entry 中 prev 是第一个字段,这里有两种格式,一种是这个值能够用一个字节来表示,那就只使用一个字节,如果长度过大,就使用五个字节,第一个字节设置为 0xfe,后面四个字节才表示 prevlen 的值,所以这里才会有 prevlensize 这个变量。
zipEntry
判断一个 entry 的长度,需要使用到 zlentry 这个结构体,这个结构体并不是一个 entry 数据真正存储的格式,只是使用它来接收一个 entry 中存储的信息。可以看到这里首先通过 zipEntrySafe 函数将 entry 的信息解析出来,然后将头部的长度和长度加起来就行了。
/* We use this function to receive information about a ziplist entry.* Note that this is not how the data is actually encoded, is just what we* get filled by a function in order to operate more easily. */typedef struct zlentry {unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/unsigned int prevrawlen; /* Previous entry len. */unsigned int lensize; /* Bytes used to encode this entry type/len.For example strings have a 1, 2 or 5 bytesheader. Integers always use a single byte.*/unsigned int len; /* Bytes used to represent the actual entry.For strings this is just the string lengthwhile for integers it is 1, 2, 3, 4, 8 or0 (for 4 bit immediate) depending on thenumber range. */unsigned int headersize; /* prevrawlensize + lensize. */unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending onthe entry encoding. However for 4 bitsimmediate integers this can assume a rangeof values and must be range-checked. */unsigned char *p; /* Pointer to the very start of the entry, thatis, this points to prev-entry-len field. */} zlentry;/* Return the total number of bytes used by the entry pointed to by 'p'. */static inline unsigned int zipRawEntryLengthSafe(unsigned char* zl, size_t zlbytes, unsigned char *p) {zlentry e;assert(zipEntrySafe(zl, zlbytes, p, &e, 0));return e.headersize + e.len;}
在看 zipEntrySafe 之前,先来看一下 unsafe 的做法是什么样的。unsafe 与 safe 的区别就是,unsafe 会按照 ziplist entry 的样式解析这一段内存,这里假设这段内存是正确的。虽然这里说是不会验证这段内存的正确定,但是在 L11 还是检查了一下 lensize 的大小。
/* Fills a struct with all information about an entry.* This function is the "unsafe" alternative to the one blow.* Generally, all function that return a pointer to an element in the ziplist* will assert that this element is valid, so it can be freely used.* Generally functions such ziplistGet assume the input pointer is already* validated (since it's the return value of another function). */static inline void zipEntry(unsigned char *p, zlentry *e) {ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);ZIP_ENTRY_ENCODING(p + e->prevrawlensize, e->encoding);ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);assert(e->lensize != 0); /* check that encoding was valid. */e->headersize = e->prevrawlensize + e->lensize;e->p = p;}
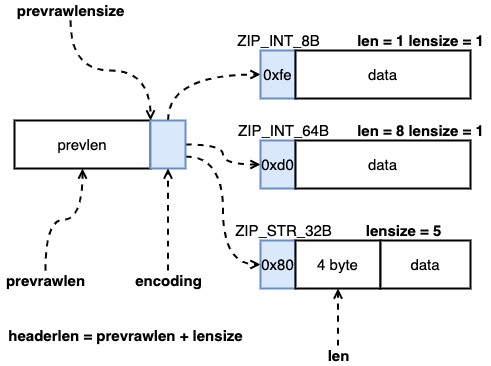
图三:zipEntry
使用一个 entry 所有的信息填满一个结构体,这个函数对于无法信任的指针式安全的,它会确保不会尝试获取 ziplist 负载之外的内存,如果这个 entry 是正确的返回 1,否则返回 0.
首先 L6 L7 先求出整个 ziplist 的第一个 entry 和最后一个 entry 的地址,在整个函数中,不能让访问的地址超出这个界限。然后在 L8 这里定义了一个宏,这个宏只在该函数中有效,在 L64 会取消掉。L12 是在尝试解析头部,如果头部在最大的情况下也不会超过限制,那直接解析就可以了,L13 ~ L17 与 zipEntry 函数一样,然后计算 p 加上当前 entry 的长度有没有超限,p 减去上一个 entry 的长度有没有超限就结束了。如果不能保证头部能完整解析,那就需要每次解析一部分都进行判断。
Dict
首先来看结构体的定义,dict 中最核心的部分就是 dt_table,这是两个 dictEntry 的数组,这里有两个是为了在 rehash 的时候一个存储旧的,另一个作为新的,这两个数组分别有两个值 ht_size_exp 和 ht_used 存储它们的大小和已使用的个数。
一个 dictEntry 就是一条数据,其中存储了 key 和 value,还有指向下一个 entry 的指针,这个指针是为了解决 hash 冲突,使用了拉链法来存储冲突了的 dictEntry。
dictType 包含了一系列函数,所有有关于 key 和 value 的处理都是通过这些函数进行的。将一组函数作为结构体,是 C 语言中实现多态的一个很常见的做法。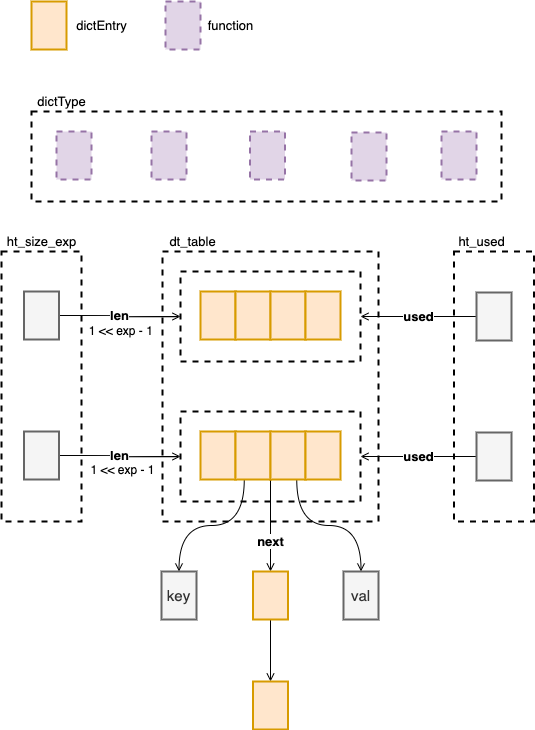
图一: struct
typedef struct dictEntry {void *key;union {void *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next; /* Next entry in the same hash bucket. */void *metadata[]; /* An arbitrary number of bytes (starting at a* pointer-aligned address) of size as returned* by dictType's dictEntryMetadataBytes(). */} dictEntry;typedef struct dict dict;typedef struct dictType {uint64_t (*hashFunction)(const void *key);void *(*keyDup)(dict *d, const void *key);void *(*valDup)(dict *d, const void *obj);int (*keyCompare)(dict *d, const void *key1, const void *key2);void (*keyDestructor)(dict *d, void *key);void (*valDestructor)(dict *d, void *obj);int (*expandAllowed)(size_t moreMem, double usedRatio);/* Allow a dictEntry to carry extra caller-defined metadata. The* extra memory is initialized to 0 when a dictEntry is allocated. */size_t (*dictEntryMetadataBytes)(dict *d);} dictType;#define DICTHT_SIZE(exp) ((exp) == -1 ? 0 : (unsigned long)1<<(exp))#define DICTHT_SIZE_MASK(exp) ((exp) == -1 ? 0 : (DICTHT_SIZE(exp))-1)struct dict {dictType *type;dictEntry **ht_table[2];unsigned long ht_used[2];long rehashidx; /* rehashing not in progress if rehashidx == -1 *//* Keep small vars at end for optimal (minimal) struct padding */int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */signed char ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */};
dictKeyIndex
dictKeyIndex 是为了找到 key 对应的 index,查看应该将 key 插入到数组的那个位置。首先通过 dictType 中的 hashFunction 将 key 进行 hash 变成 uint64 类型,然后通过 exp 生成的 mask 获取到对应的 index,通过 index 找到 dt_table 中对应的 dictEntry。
这个函数应该是找到对应的 index,将 index 返回就可以了,但是当前 key 可能已经插入过了,还需要便利 dictEntry 查看有没有当前的 key,如果有的话,通过参数中的 existing 返回已经存在的 dictEntry。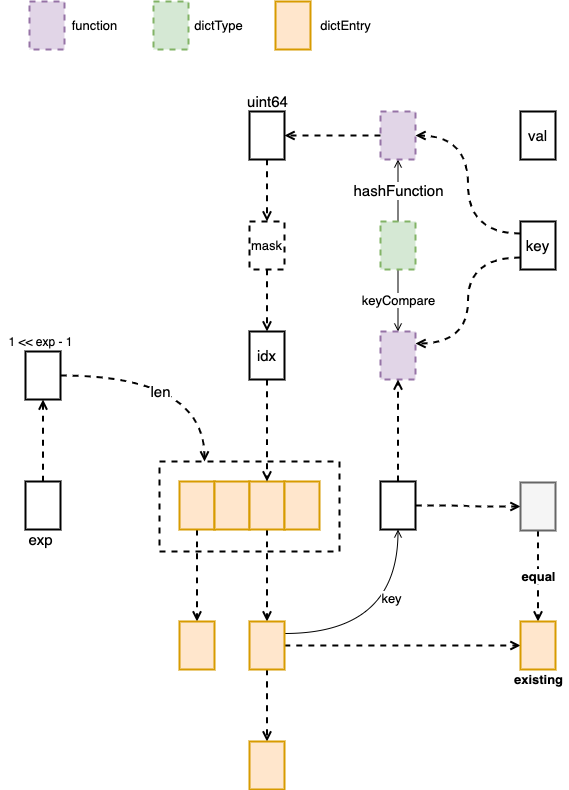
图一:dictKeyIndex

若有收获,就点个赞吧
0 人点赞
