newproc 就是创建一个新的 Goroutine,在 Scheduler 中就是 g,每个 g 会运行一个函数 fn。在 Golang 中创建一个 goroutine 很简单,只需要一个 go 关键字就可以。
go func(message string) {fmt.Println(message)}()
在 newproc 中,首先获取函数 fn 的指针,获取调用方的 goroutine,获取调用方的 PC 寄存器,然后再系统堆栈上运行 newproc1,L24 是将新创建好的 goroutine 放到 P 的运行队列中,并且尝试唤醒一个 P。这里的 newproc1 , runqput,wakep 会在后面一一介绍。
func newproc(siz int32, fn *funcval) {argp := add(unsafe.Pointer(&fn), sys.PtrSize)gp := getg()pc := getcallerpc()systemstack(func() {newg := newproc1(fn, argp, siz, gp, pc)_p_ := getg().m.p.ptr()runqput(_p_, newg, true)if mainStarted {wakep()}})}
L1 ~ L6 检查一下 fn 是不是有效,如果 fn 为 nil,就直接抛出错误。接下来处理传递进来的参数大小,根据这个大小分配初始的栈。与 C 不同,Golang 函数调用的参数传递和返回值都是通过栈进行的,所以函数的参数数量没有限制,返回值的数量也可以是多个。
接下来并不直接生成一个新的 goroutine,而是先尝试从 gfree 队列中获取,获取不到的时候才会调用 malg() 生成一个新的 g。
_g_ := getg()if fn == nil {_g_.m.throwing = -1 // do not dump full stacksthrow("go of nil func value")}acquirem() // disable preemption because it can be holding p in a local varsiz := nargsiz = (siz + 7) &^ 7// ..._p_ := _g_.m.p.ptr()newg := gfget(_p_)if newg == nil {newg = malg(_StackMin)casgstatus(newg, _Gidle, _Gdead)allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.}
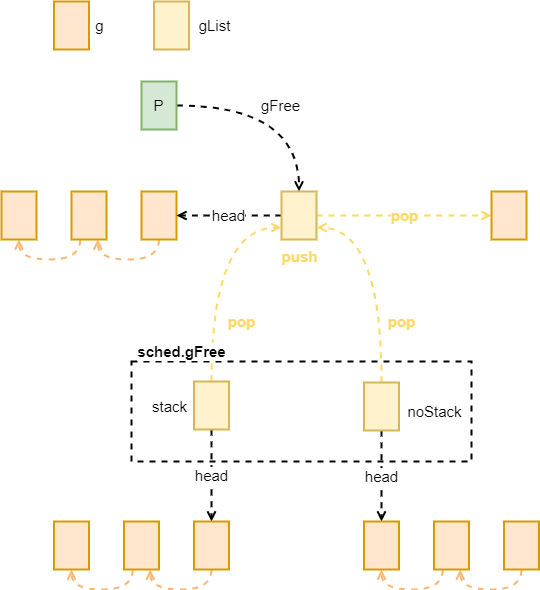
Get Free Goroutine
这里有两个 gFree 队列,一个是当前的 P 中的,另一个是全局变量 sched 中的,通常不会从全局的 sched 中获取空闲的 Goroutine,除非当前 P 里没有空闲的 Goroutine 了。获取到空心的 Goroutine 之后还会查看是否这个 Goroutine 持有栈,如果没有的化会分配新的栈空间。
// Get from gfree list.// If local list is empty, grab a batch from global list.func gfget(_p_ *p) *g {retry:if _p_.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {lock(&sched.gFree.lock)// Move a batch of free Gs to the P.for _p_.gFree.n < 32 {// Prefer Gs with stacks.gp := sched.gFree.stack.pop()if gp == nil {gp = sched.gFree.noStack.pop()if gp == nil {break}}sched.gFree.n--_p_.gFree.push(gp)_p_.gFree.n++}unlock(&sched.gFree.lock)goto retry}gp := _p_.gFree.pop()if gp == nil {return nil}_p_.gFree.n--if gp.stack.lo == 0 {// Stack was deallocated in gfput. Allocate a new one.systemstack(func() {gp.stack = stackalloc(_FixedStack)})gp.stackguard0 = gp.stack.lo + _StackGuard} else {if raceenabled {racemalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)}if msanenabled {msanmalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo)}}return gp}
Init Goroutine
接下来的部分就是为新生成的 g 进行初始化。首先是参数的拷贝,需要注意的是每个 goroutine 刚生成时,分配的栈的大小都是 2K,如果我们的参数大小超过了这个限制,运行时并不会分配更大的栈,因为 Go 语言的开发人员认为这种情况大多数都是因为错误导致的,毕竟函数传递中传递 2K 数据并不多见,如果有较大的数据结构,应该直接传递其指针的。
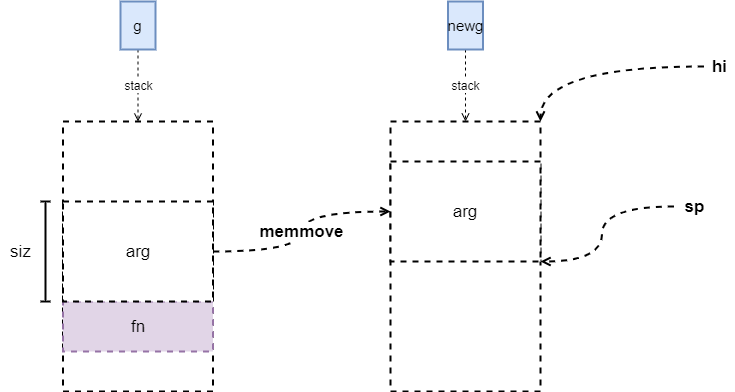
图 2:init args
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // extra space in case of reads slightly beyond frametotalSize += -totalSize & (sys.SpAlign - 1) // align to spAlignsp := newg.stack.hi - totalSizespArg := spif usesLR {// caller's LR*(*uintptr)(unsafe.Pointer(sp)) = 0prepGoExitFrame(sp)spArg += sys.MinFrameSize}if narg > 0 {memmove(unsafe.Pointer(spArg), argp, uintptr(narg))// This is a stack-to-stack copy. If write barriers// are enabled and the source stack is grey (the// destination is always black), then perform a// barrier copy. We do this *after* the memmove// because the destination stack may have garbage on// it.if writeBarrier.needed && !_g_.m.curg.gcscandone {f := findfunc(fn.fn)stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps))if stkmap.nbit > 0 {// We're in the prologue, so it's always stack map index 0.bv := stackmapdata(stkmap, 0)bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata)}}}memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))newg.sched.sp = spnewg.stktopsp = spnewg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same functionnewg.sched.g = guintptr(unsafe.Pointer(newg))gostartcallfn(&newg.sched, fn)newg.gopc = callerpcnewg.ancestors = saveAncestors(callergp)newg.startpc = fn.fnif _g_.m.curg != nil {newg.labels = _g_.m.curg.labels}if isSystemGoroutine(newg, false) {atomic.Xadd(&sched.ngsys, +1)}casgstatus(newg, _Gdead, _Grunnable)if _p_.goidcache == _p_.goidcacheend {// Sched.goidgen is the last allocated id,// this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch].// At startup sched.goidgen=0, so main goroutine receives goid=1._p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)_p_.goidcache -= _GoidCacheBatch - 1_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch}newg.goid = int64(_p_.goidcache)_p_.goidcache++if raceenabled {newg.racectx = racegostart(callerpc)}if trace.enabled {traceGoCreate(newg, newg.startpc)}releasem(_g_.m)return newg}
Running Queue
接着回到函数 newproc 中,生成好的 g 会被放入当前 p 的运行队列中,并将 next 标记为 true。如果当前的调度模式是 random,新创建的 goroutine 并不一定需要下一个执行,生成一个随机数,如果这个随机数不是 2 的倍数,也就是有二分之一的概率,我们并不在下一个执行它。
首先处理 next == true 的情况,将新来的 g 与 runnext 交换,直到交换成功为止,查看是不是以前也有 next,将这个 next 进行下一步处理,如果原来的 next 就是空的,直接返回就可以了。接下来是将 g 放入到 runq 的末尾,这里的 g 可能是新创建的 groutine,也可能是以前的 runnext 中的 goroutine。
:::danger L25 和 L26 都是获取 p 中的值,为什么 runqhead 需要使用 atomic 进行获取呢?L29 最后的存储 runqtail 为什么也需要 actomic? :::
接下来看看 runq 满没满,通过 t - h 就可以判断,因为这里的 runq 的存取都是使用的 i%len(runq),我们可以将它看作是一个环形队列,h%len(runq) 的位置可能在 t%len(runq) 前面,但是 t 是肯定大于 h 的,只要两者差不大于 len(runq),那这个队列就没满。我们将这个 goroutine 放入到本地的 runq 中。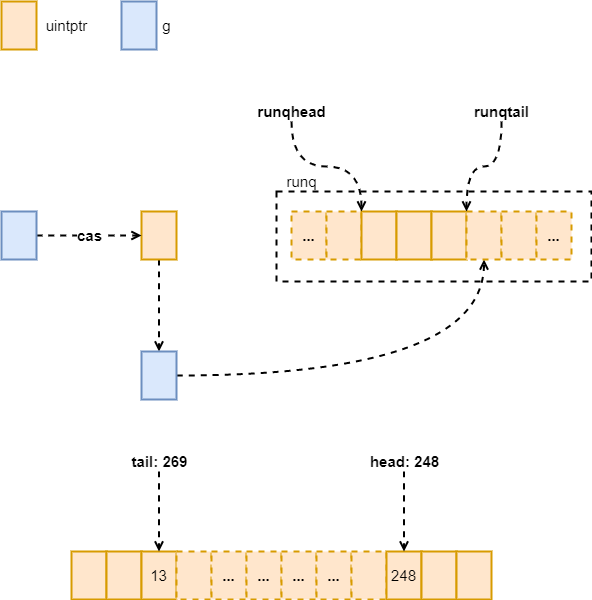
图 3:runq
// runqput tries to put g on the local runnable queue.// If next is false, runqput adds g to the tail of the runnable queue.// If next is true, runqput puts g in the _p_.runnext slot.// If the run queue is full, runnext puts g on the global queue.// Executed only by the owner P.func runqput(_p_ *p, gp *g, next bool) {if randomizeScheduler && next && fastrand()%2 == 0 {next = false}if next {retryNext:oldnext := _p_.runnextif !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {goto retryNext}if oldnext == 0 {return}// Kick the old runnext out to the regular run queue.gp = oldnext.ptr()}retry:h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumerst := _p_.runqtailif t-h < uint32(len(_p_.runq)) {_p_.runq[t%uint32(len(_p_.runq))].set(gp)atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumptionreturn}if runqputslow(_p_, gp, h, t) {return}// the queue is not full, now the put above must succeedgoto retry}
如果当前 p 的 runq 已经满了,就应该尝试将 P 中的 goroutine 清理一些放到全局队列中了,而这个 g 也应该放到全局队列里。关于 runqputslow 的过程见下图。可以看到在 p 中的 runq 是一个数组,而在 sche 中的 runq 变成了一个链表,这是一个单向链表,链表中的每个节点都是 g。
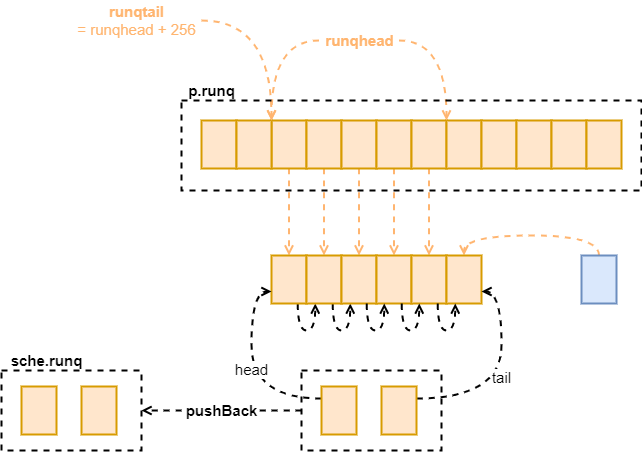
图 4:runqputslow
// Put g and a batch of work from local runnable queue on global queue.// Executed only by the owner P.func runqputslow(_p_ *p, gp *g, h, t uint32) bool {var batch [len(_p_.runq)/2 + 1]*g// First, grab a batch from local queue.n := t - hn = n / 2if n != uint32(len(_p_.runq)/2) {throw("runqputslow: queue is not full")}for i := uint32(0); i < n; i++ {batch[i] = _p_.runq[(h+i)%uint32(len(_p_.runq))].ptr()}if !atomic.CasRel(&_p_.runqhead, h, h+n) { // cas-release, commits consumereturn false}batch[n] = gpif randomizeScheduler {for i := uint32(1); i <= n; i++ {j := fastrandn(i + 1)batch[i], batch[j] = batch[j], batch[i]}}// Link the goroutines.for i := uint32(0); i < n; i++ {batch[i].schedlink.set(batch[i+1])}var q gQueueq.head.set(batch[0])q.tail.set(batch[n])// Now put the batch on global queue.lock(&sched.lock)globrunqputbatch(&q, int32(n+1))unlock(&sched.lock)return true}

若有收获,就点个赞吧
0 人点赞
