原理
Postgres 因为 MVCC 机制的原因,在更新或者删除数据的时候,不会直接删除旧数据,而是建立一条新数据,然后将旧数据标记为删除,以便其他事务进行读取,这样可能会在表中产生很多的死行,浪费大量的磁盘空间。
只有对表做 VACUUM 操作时,才会清除这些四行。Postgres 也提供了配置 autovacuum 定期自动启动一个进行去执行 VACUUM。
就算是空间被 VACUUM回收,表的体积也不会下降,因为大多数情况下,被清除的记录只是文件中的一小部分,而操作系统是无法单独回收一块数据中的一小部分空间的。只有像下图一样清理的是文件末尾的整个数据块的时候,才能通过 Truncate 真正回收空间。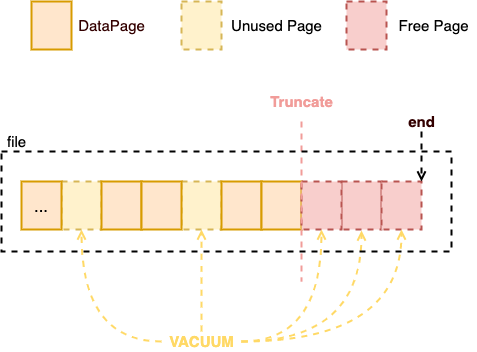
图 1:Truncate
另外一种方法是直接调用 VACUUM FULL 将整个表都重新整理一遍,但是,调用这个指令会给表加上 Access Exclusive 级别的锁,这个级别的锁会与所有操作互斥。
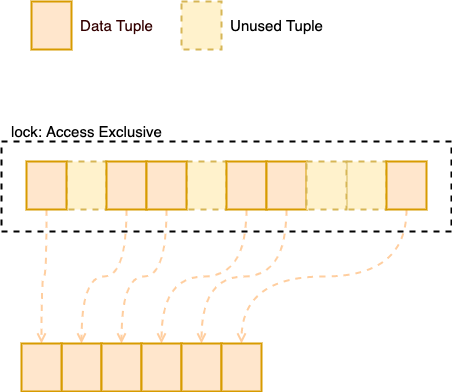
图 2:VACUUM FULL
对此 PostgreSQL 提供了手动垃圾回收 VACCUM 命令,也有自动垃圾回收 autovaccum 参数,按理说表膨胀的程度应该被控制在一定范围内,并不会应该正常的使用,但是仍然会产生垃圾回收不及时的情况。
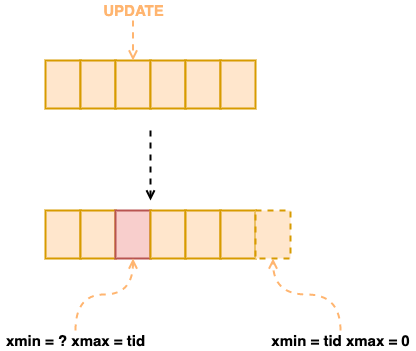
图 3:MVCC 表膨胀
由于表膨胀的底层原因是 MVCC,如果遇到更新删除操作就会将 tuple 版本标记为不可用,所以表膨胀通常发生在更新或删除操作特别频繁的场景。
长事务
在这种情况下最可能的原因是有超长的未结束事务,它们占据了很早的事务号,所以 VACCUM 也不能清除这些 dead tuple。
如果最老的事务没有被提交,这条事务能够看到的所有数据,都无法被回收,所以对于消耗时间很长的事务,就会让空间被持久的占用。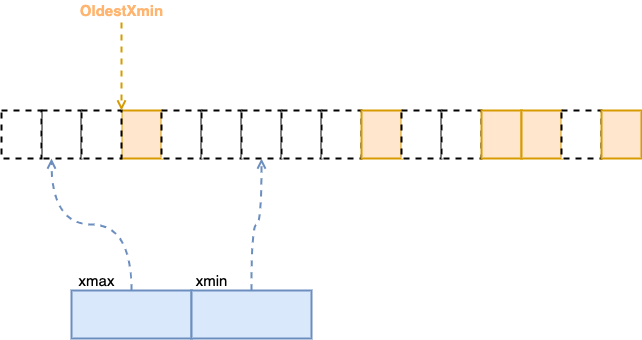
图 4:OldestXmin
autovaccum_work_mem 过小
另外一个原因可能是 autovaccum_work_mem 设置的太小了,导致索引被扫描很多次。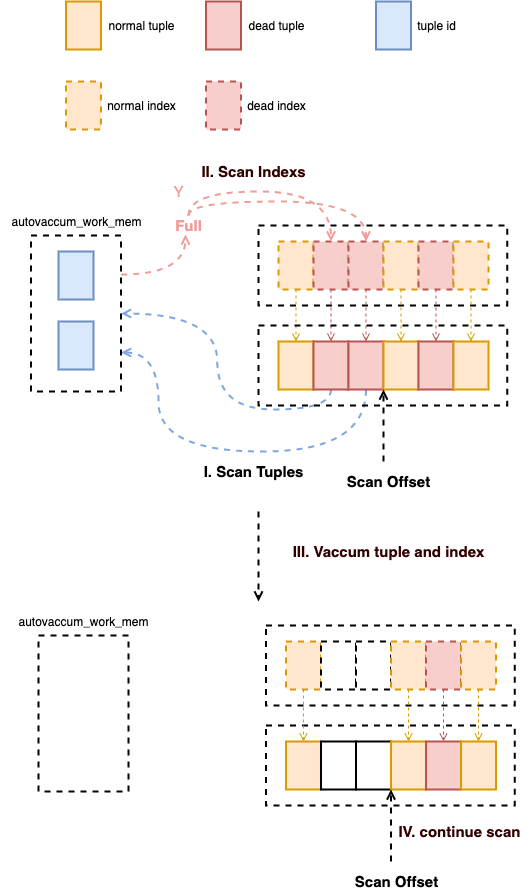
图 5:autoaccum_work_mem
因为数据库中的索引是用来查询对应的 tuple 的,所以给定索引可以很方便的找到对应的 tuple,但是给定 tuple 找到它的索引却并不容易,这需要对索引进行完整的扫描。而 xmin 和 xmax 事务信息是存储在 tuple 中的,所以在 VACCUM 的时候第一步要先扫描所有的 tuple,并且将 dead tuple id 存储在 autovaccum_work_mem 大小的分配内存中,这一块内存满了之后,就扫描整个 index,将对应的索引和元组删除,然后从上次的位置继续开始扫描。如果 autovaccum_work_mem 设置的太小,可能会导致索引被全部扫描多次。
Undo 存储引擎
对于PostgreSQL的MVCC来说,膨胀是必然的事情,如果想要从根本上解决这个问题,可以选择使用 UNDO 的存储引擎,比如 zheap 和 zedstore 等。下面以 zheap 为例,介绍一下这类引擎是怎么工作的。
ZHEAP
zheap 是 postgres 新的存储引擎,其目标就是避免表膨胀的问题,这是一种与正常的 PostgreSQL 完全不同的存储引擎,也就意味着它们之间的页结构是无法兼容的,zheap 在每个 tuple 中去除了所有事务相关的字段,将他们都移动到页级别。
INSERT
对于 INSERT,zheap 申请一个 transaction slot 并且发出一个 undo 记录来处理 error 相关的问题。INSERT中的 TID 是 undo 所需的最重要的信息。如果 INSERT 被回滚空间可以马上被再次利用,这也是 zheap 和PostgreSQL 标准存储最主要的不同。
UPDATEUPDATE 要复杂的多,主要有两种类型:
- 新的记录能被写入之前的存储空间
- 新的记录无法写入之前的存储空间

图 6:Update
DELETE
处理行的删除,zheap会发出一个undo记录来旧的的行,如果ROLLBACK则写回去。在DELETE中,zheap会删除掉该行。

若有收获,就点个赞吧
0 人点赞
