【数据结构与算法基础】代码仓库:https://github.com/jinrunheng/datastructure-and-algorithm
一:无向带权图的最小生成树
无向带权图的概念我们就不在这篇文章中介绍了,下图为一个无向带权图的示例:
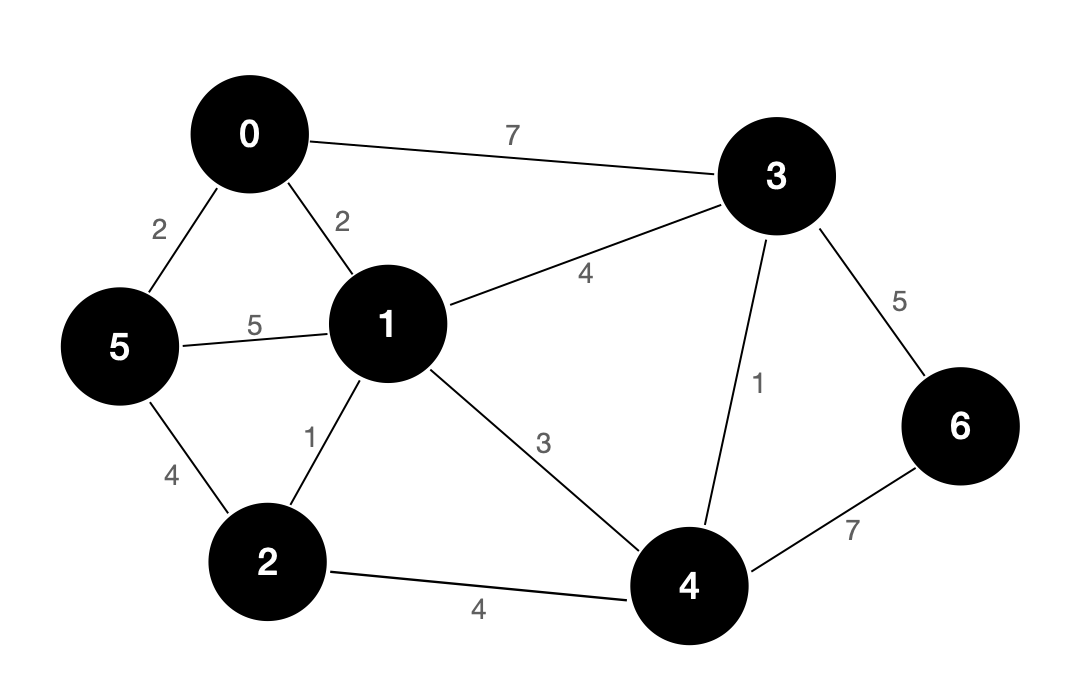
以邻接表的表示方式实现的无向带权图(WeightedGraph)这个类的代码请参考链接:代码链接
接下来我们着重介绍一下图的生成树与最小生成树的概念。
什么是图的生成树呢?
首先,只有一个联通图才有会有图的生成树,也就是说,给定的图的联通分量的个数必须是 1 。
然后,在一个联通图 $G$ 中,如果取它全部顶点和一部分边构成一个子图 $G’$,若子图$G’$的所有边能够使得全部的顶点联通且不形成任何的回路,则称子图$G’$为原图$G$的一棵生成树。
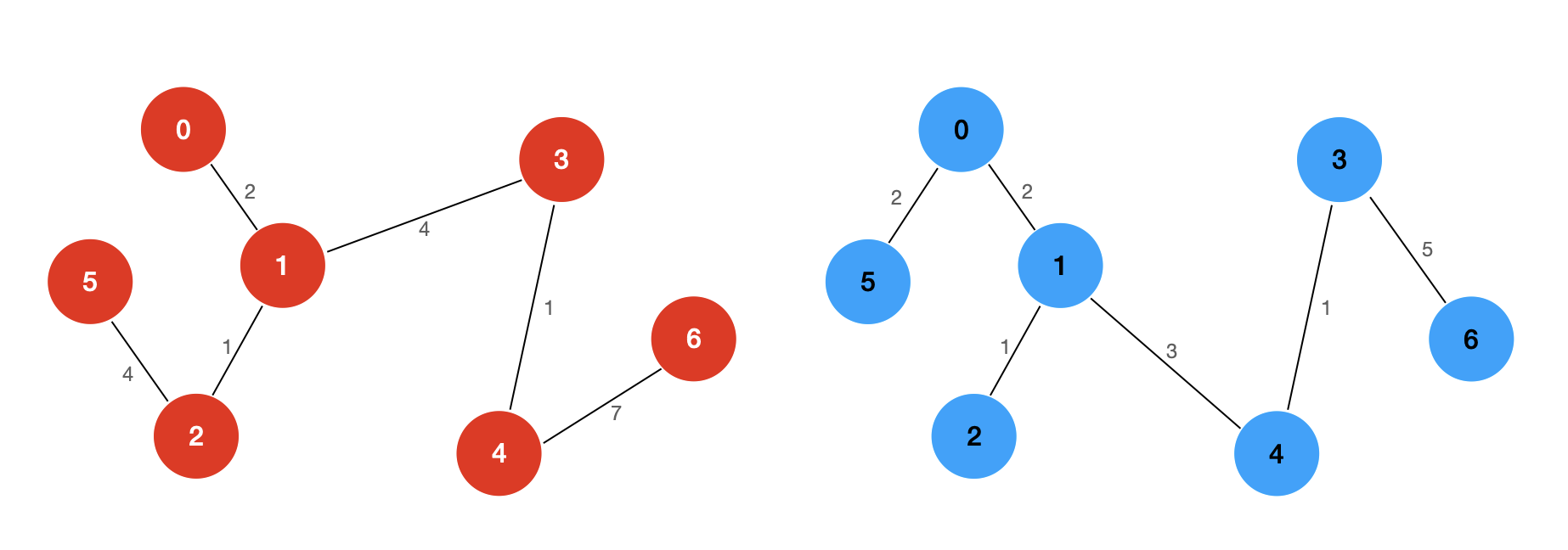
上面的两个图都是示例给定图的生成树。我们看到,一个图可能存在多个生成树,生成树不同,每棵树的权(即树中所有边上的权值总和)也可能不同。譬如左边的生成树的权为 19,右边的生成树的权为 14。
所谓的最小生成树(Minimum Spanning Tree)指的就是,带权图的生成树中,权最小的生成树。
右边的生成树(用蓝色节点标注)实际上就是我们给定的示例图的最小生成树。
求解带权图的最小生成树有什么意义呢?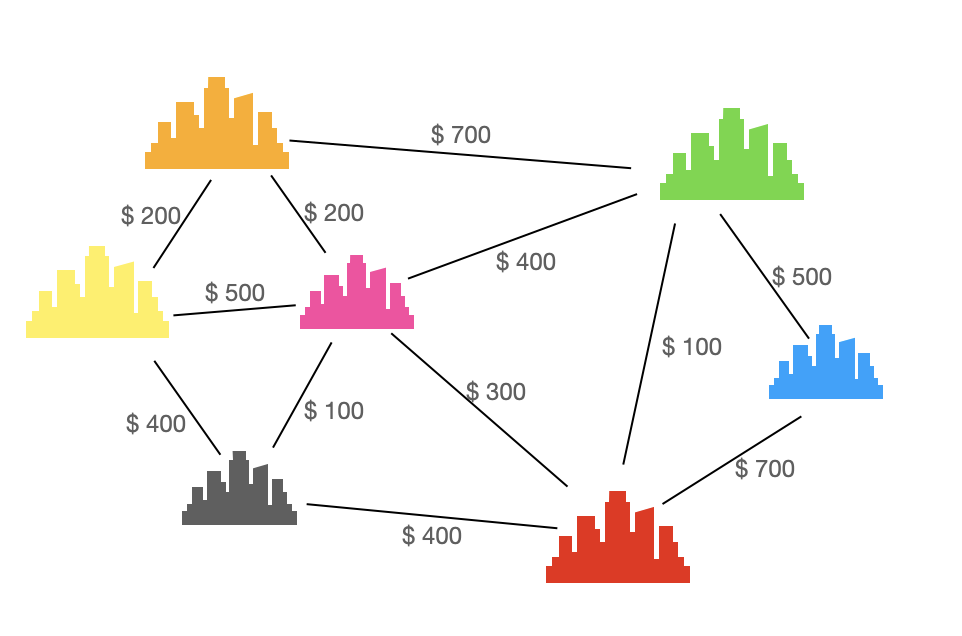
举个例子:假设上图表示 n 个城市之间的通信网线路(其中顶点表示城市,边表示两个城市之间的通信线路,边上的权值表示线路的具体造价)。
我们可以通过求该图的最小生成树达到求解通信线路造价费用最小的方案。
二:Kruskal 算法
Kruskal 算法是求解无向带权图的最小生成树的经典算法之一。
Kruskal 算法的思想是每次都选择图中的一个权值最小的边添加到结果集中,期间要保证结果集不会产生环,当结果集满足生成树的条件时,那么其必然是一棵最小生成树。
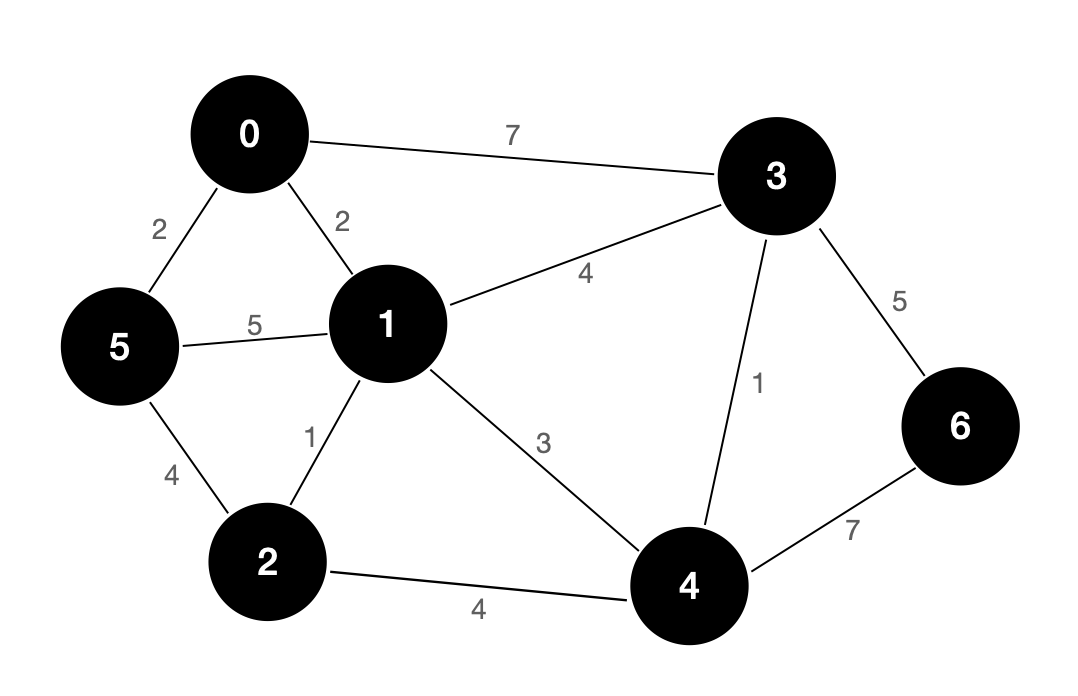
我们使用该示例图作为演示,看一下 Kruskal 算法的具体执行流程:
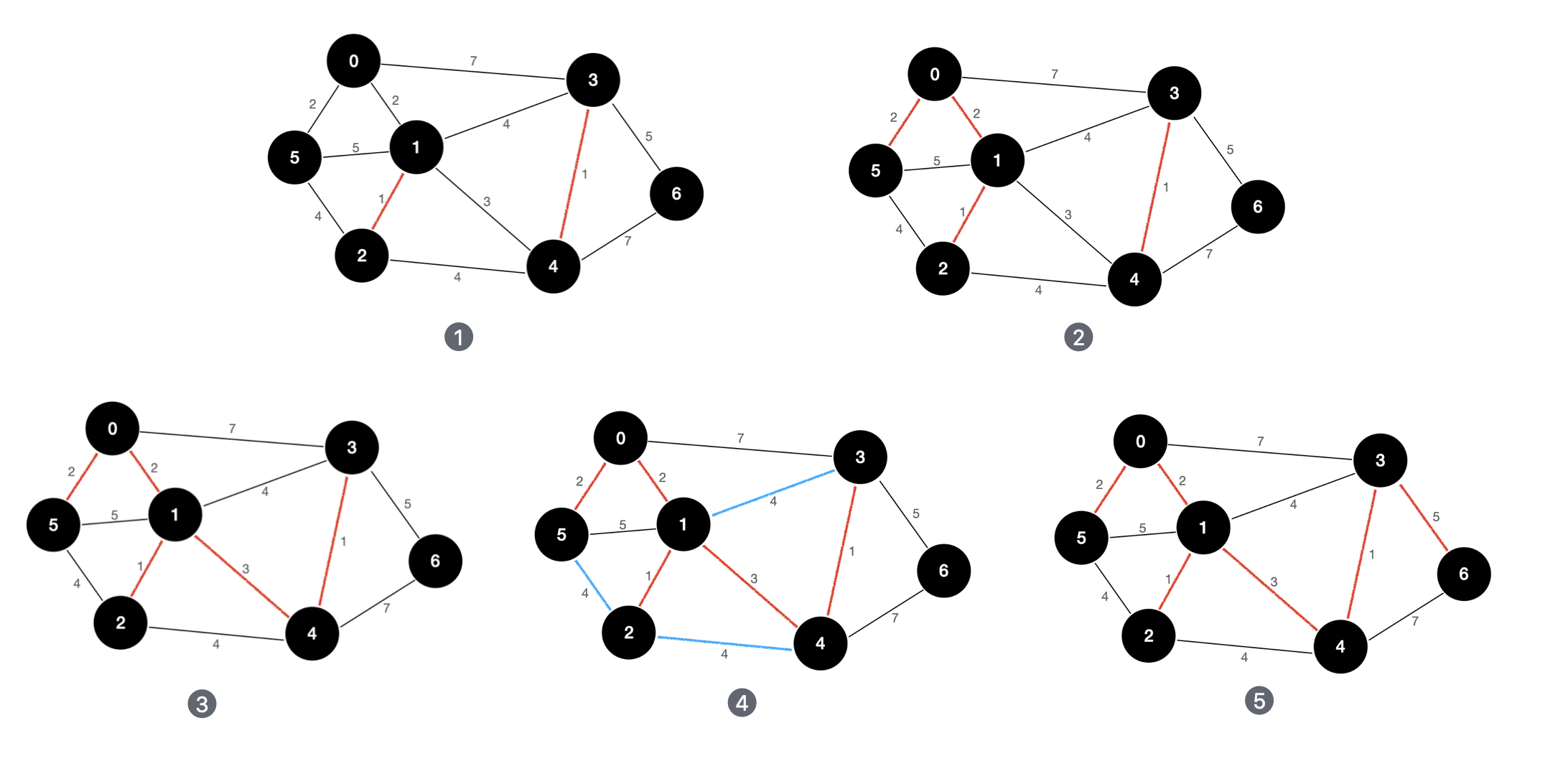
上图为 Kruskal 算法的执行流程。我们每次都选择权值最小的边来构建图的生成树。在第四步,由于三条权值为 4 的边都会使得生成树产生环,即这三条边不符合生成树的定义,所以并没有添加到结果集当中。
不难发现,Kruskal 算法的本质就是贪心策略。接下来,我们就去证明一下 Kruskal 算法为什么可以得到无向带权图的最小生成树?这个贪心策略为什么是正确的?
三:Kruskal 算法的正确性证明
切分定理(Cut property)
首先,我们要了解两个概念:切分(Cut)与横切边(Crossing Edge)。
将图中的顶点分为两部分,就称为一个切分。如果一个边的两个端点,属于切分不同的两边,则这个边称为横切边。
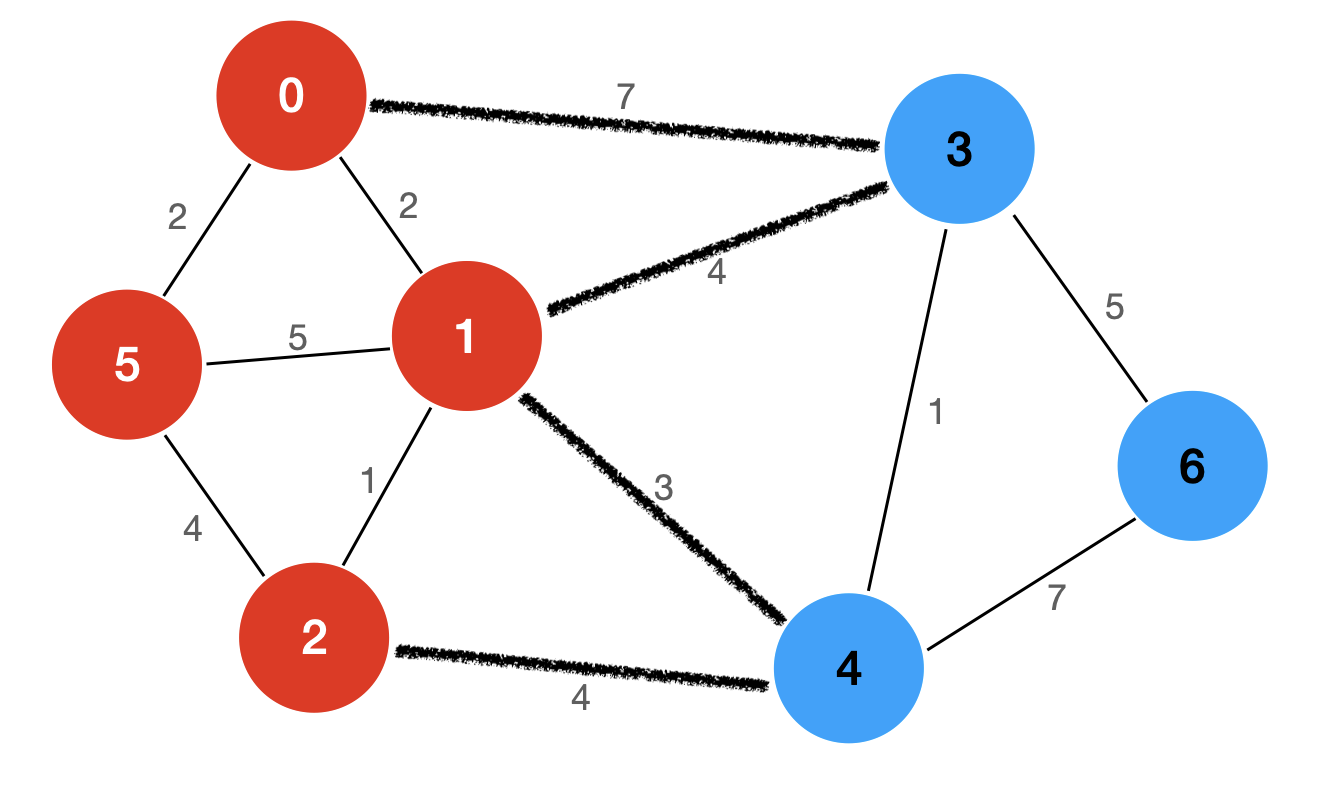
譬如上图中,我们将图中所有的顶点分成红色和蓝色两部分,这就是该图的一个切分。1-4、1-3、0-3 和 2-4 这四条边的两个端点属于切分不同的两边,所以,这四条边就是该切分的横切边。
拓展一下,在图论领域中,还有一个非常重要的概念叫二分图(Bipartite)。
二分图具有以下特性:
- 图中所有的顶点可以分成不相交的两个部分
- 所有的边的两个端点都隶属于不同的部分
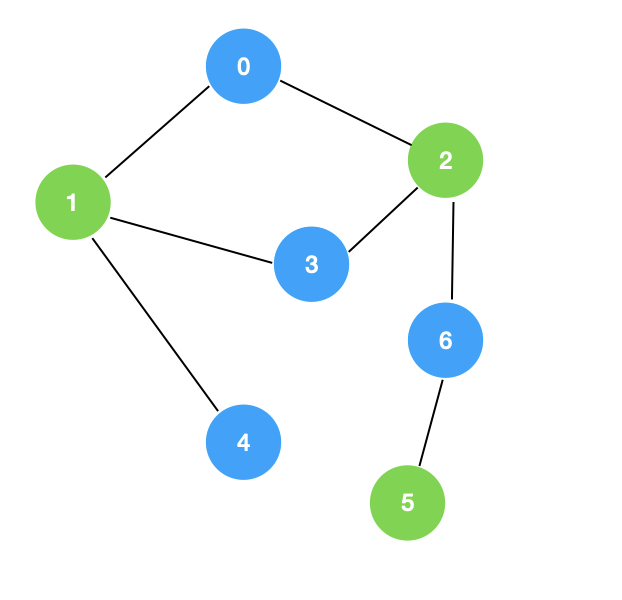
如上图所示,该图就是一个二分图。
在引入了切分这个概念之后,我们可以重新定义二分图的概念,二分图就是能在图中找到一个切分,使得图中的所有边都是横切边的图。
好,那么话说回来,什么是切分定理呢?
切分定理就是,任意一个切分的横切边中权值最小的那条边,一定是最小生成树的一条边。
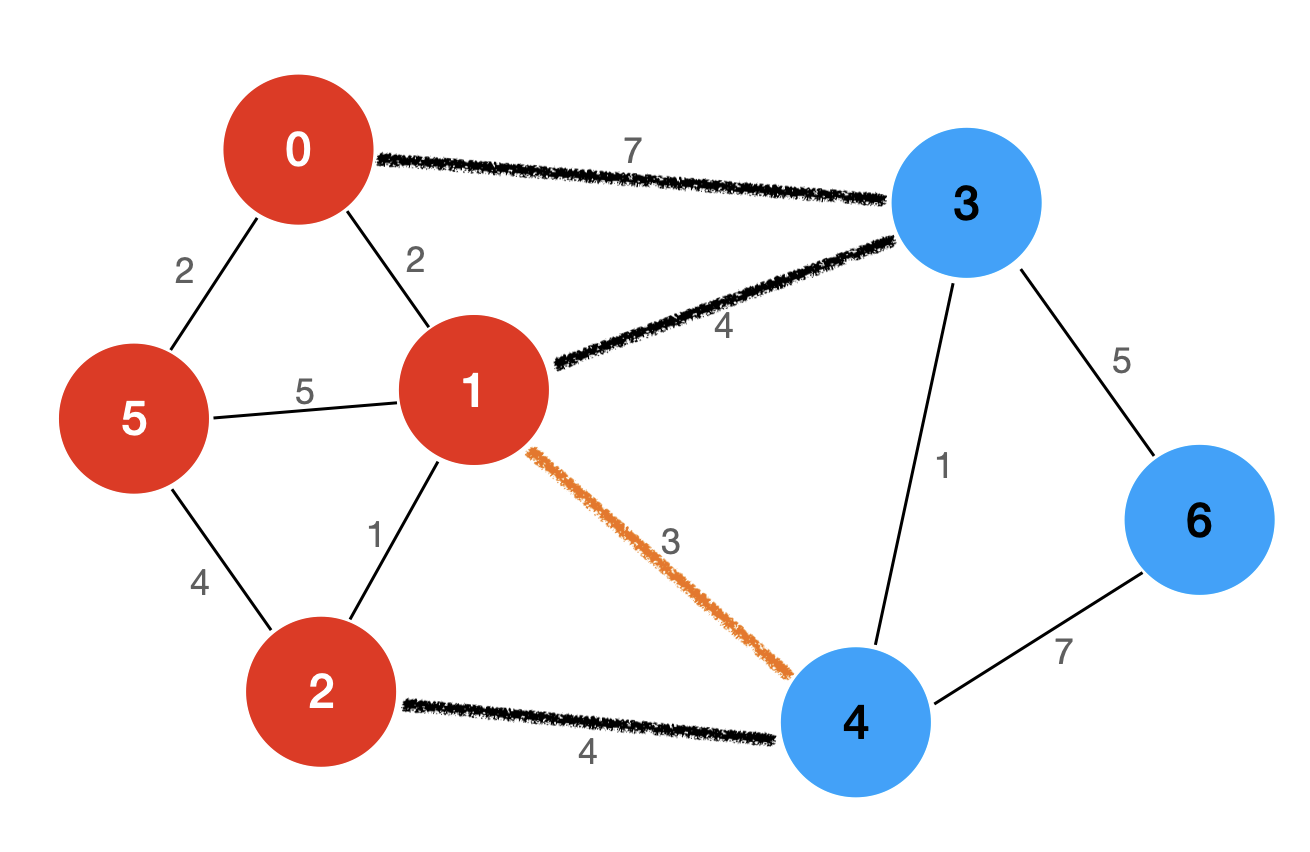
该图的切分中,1-4、1-3、0-3 和 2-4 这四条边为横切边,它们的权值分别为 3、4、7 和 4,这里面,1-4 这条边的权值最小,所以,根据切分定理,1-4 这条边一定是该图的最小生成树中的一条边。
切分定理该如何证明呢?
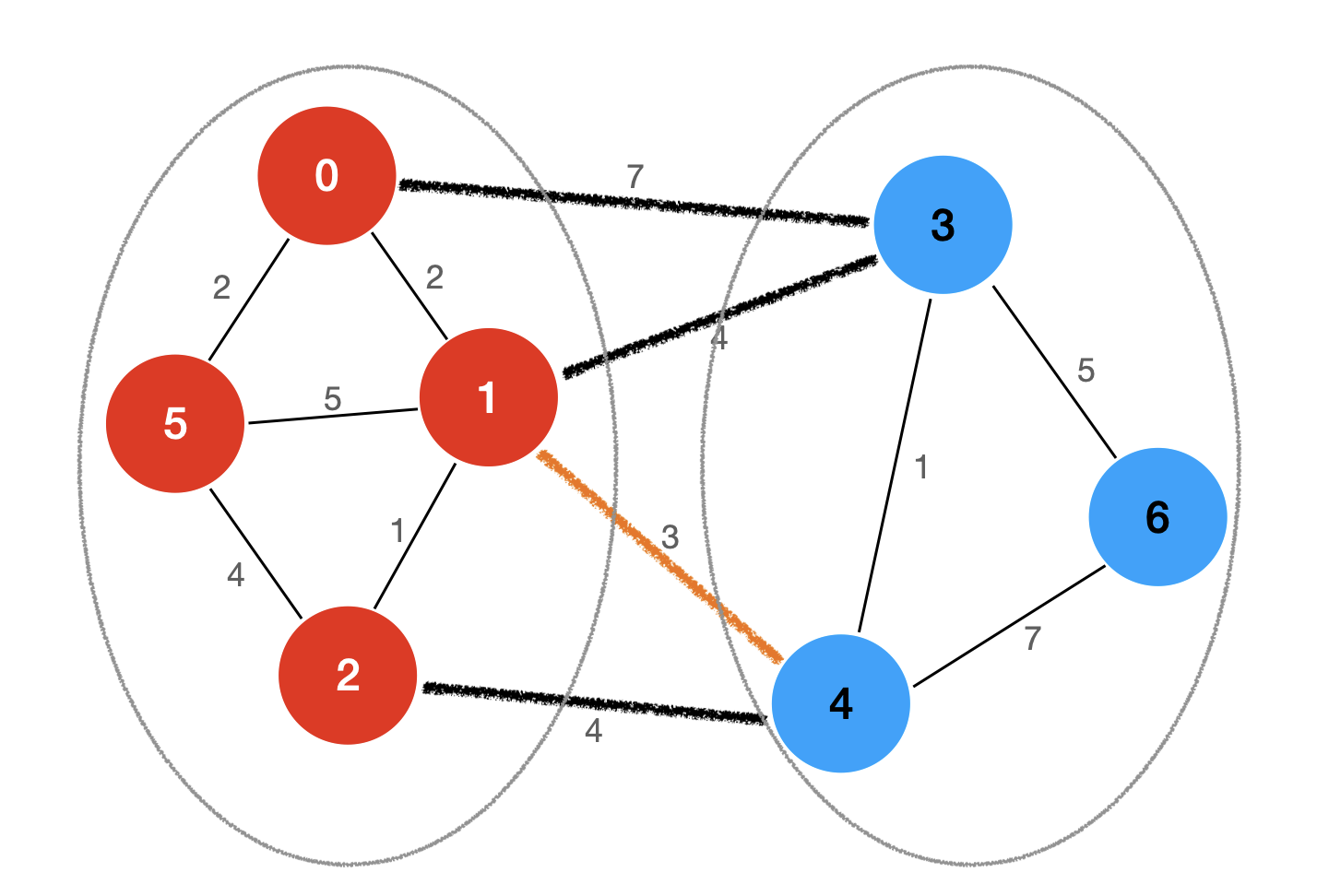
我们知道,最小生成树的所有顶点一定是联通的,所以,该切分的最小生成树对应的左边的四个顶点之间是联通的,右边的三个顶点也是联通的,左边和右边之间必然存在一条边使得左右两边可以联通。我们就不难想出,使得左右两边之间联通形成最小生成树的那条边,必然是横切边中权值最小的那条边。
所以,通过切分定理我们就知道了,Kruskal 算法每次都选择一个最短(权值最小)的边,在这条边没有使得当前的生成树形成环的前提下,我们每一次相当于是对该图一个切分,选择了最短的横切边,那么这条边就一定在最小生成树中!
四:Kruskal 算法的实现
并查集
在实现 Kruskal 算法之前,我们先来介绍一种数据结构:并查集。并查集在 Kruskal 算法中有着非常重要的作用。
并查集(UnionFind)是一种树型的数据结构。
并查集的主要功能有两个:
- 判断元素 A 所在的集合是否和元素 B 所在的集合是同一个集合
- 将元素 A 所在的集合与元素 B 所在的集合合并
并查集的初始化
并查集的初始化是将样本量为 N 的数据中每个元素构成一个单元素的集合。
每一个元素作为一个节点,同时自己指向自己,成为 标记节点 ,作为一个单元素构成的集合。
我们维护两个哈希表:
Map<Integer,Integer> map;Map<Integer,Integer> size;
第一个 Map 的 Key 存储当前节点的值,Value 存储该节点指向的父节点的值;第二个 Map 的 Key 存储当前节点的值,Value 存储该节点所在的集合共有多少元素。
并查集的初始化代码如下:
public Map<Integer,Integer> map;public Map<Integer,Integer> size;public UnionFind(int n){map = new HashMap<>();size = new HashMap<>();for(int i = 0; i < n; i++){// 最开始每个元素自己指向自己,自己成为根节点作为一个单元素构成的集合map.put(i,i);// 每个集合只有一个元素size.put(i,1);}}
判断 A 和 B 所在的集合是否为同一个集合
判断元素 A 和 B 所在的集合是否为同一个集合的方法很简单,我们只需要找到 A 所在的集合的根节点,找到 B 所在的集合的根节点,然后判断这两个元素的根节点是否为同一个节点即可。如果二者的根结点相同,就说明,A 和 B 在同一个集合当中。
我们初始化的map存储的key为这个节点自身,map存储的value为该节点的父节点。所以,我们很容易就可以写出寻找一个节点的根节点的代码:
public Node find(Node node){Node root = map.get(node);if(root != node){ // 因为根节点是自己指向自己的,所以找到根节点以后递归就会终止root = find(root);}return root;}
不过这样写代码会影响查询的效率
示例: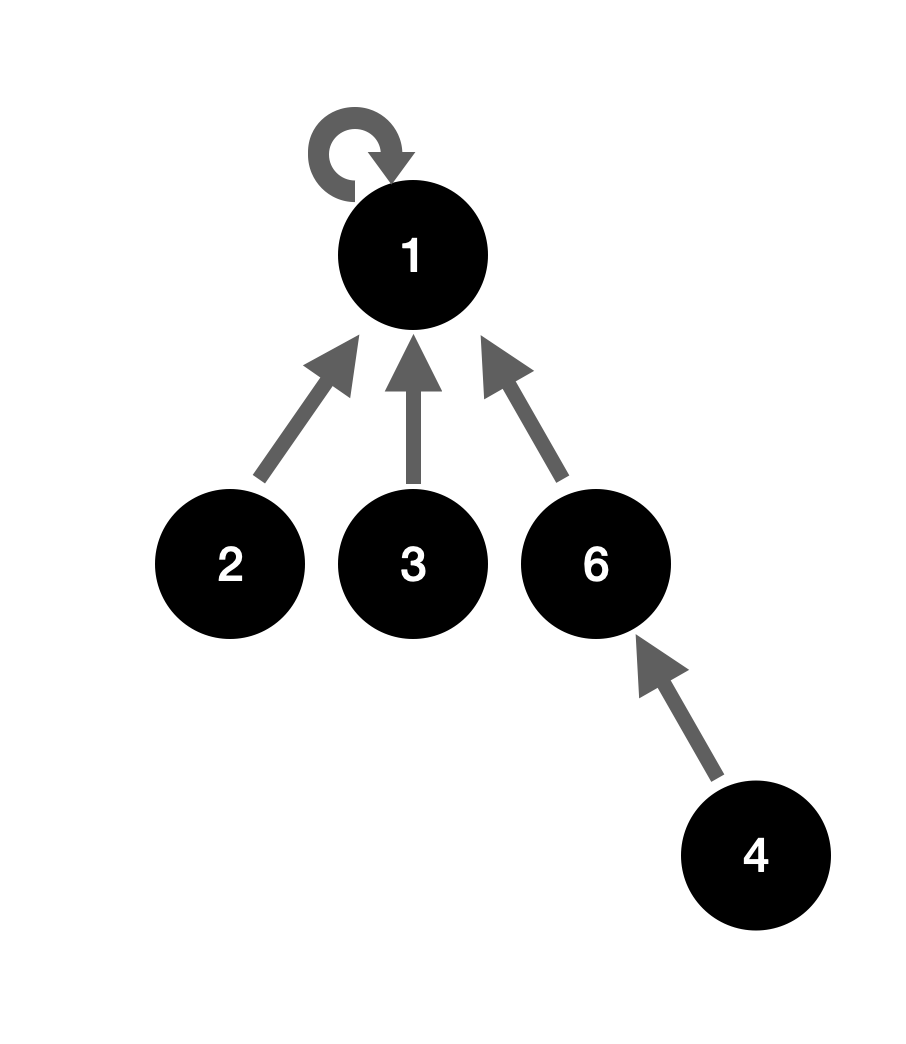
假设有并查集如下,我们需要查寻4和2的根节点
元素2只需要走一步就可以找到根节点,而元素4需要走两步才能找到根节点。
随着并查集的数据量越来越大,有可能就会导致树的高度越来越高,查询速率越来越慢。为了提升下次查询的效率,我们需要做树的扁平化处理。我们在查询后知道,节点4的根节点为1;所以,我们在查询到4的根节点之后,直接让4指向根节点1,然后再返回根节点,这种处理就是扁平化处理。
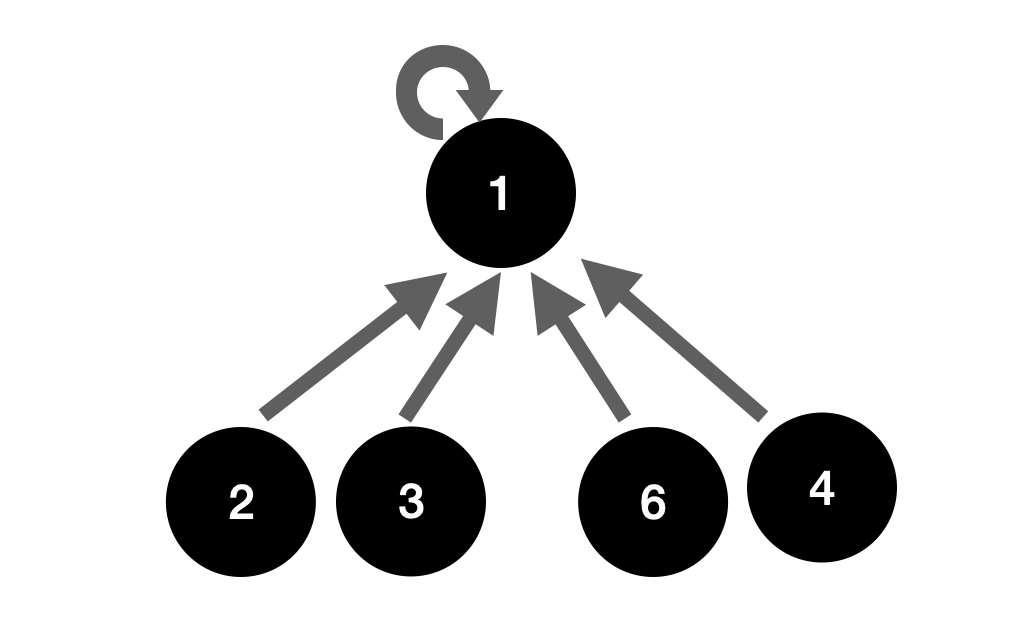
处理方式很简单,只需要添加一句代码即可:
public Node find(Node node){Node root = map.get(node);if(root != node){ // 因为根节点是自己指向自己的,所以找到根节点以后递归就会终止root = find(root);}map.put(node,root); // 扁平化处理return root;}
在解决了查询元素的根结点的逻辑后,查询 A 和 B 所在的集合是否为同一集合的代码就非常简单了:
public boolean isSameSet(int p, int q) {return find(p) == find(q);}
合并 A 和 B 所在的集合
并查集的另一个重要的功能就是合并 A 和 B 元素所在的集合。
已知:节点a所在集合的根节点aRoot,节点b所在的集合的根节点bRoot;以及,节点a所在的集合的元素数量aSize与节点b所在的集合的元素数量bSize。
如果,aSize < bSize,那么我们就让节点a所在的集合向节点b所在的集合合并。
如果,bSize < aSize,那么我们就让节点b所在的集合向节点a所在的集合合并。
代码如下:
public void union(int p,int q){int pRoot = find(p);int qRoot = find(q);if(pRoot != qRoot){int pSize = size.get(pRoot);int qSize = size.get(qRoot);if(pSize < qSize){map.put(pRoot,qRoot);size.put(qRoot,pSize + qSize);}else {map.put(qRoot,pRoot);size.put(pRoot,qSize + pSize);}}}
Kruskal 算法
我们的 Kruskal 算法逻辑流程如下:
- 判断图是否是一个联通图,即判断该图的联通分量是否为 1,如果该图不是一个联通图,就没有最小生成树
- 遍历图中所有的边,将所有的边添加到一个集合 edges 中,按照边权值的大小进行排序
- 初始化并查集,N 为图的顶点的个数
- 遍历集合 edges,对每一条边 edge 的两个顶点进行判断:
- 如果这两个顶点不在一个集合中,说明这两个顶点所在的集合不联通,我们就将这条边添加到最小生成树的结果集中,并合并这两个顶点所在的集合;
- 如果这两个顶点在一个集合中,就说明如果向当前的生成树中添加了这条边后将会产生环,即:不满足生成树的定义
代码如下:
import java.util.ArrayList;import java.util.Collections;import java.util.List;public class Kruskal {private WeightedGraph G;private List<WeightedEdge> minimumSpanningTree;public Kruskal(WeightedGraph G) {this.G = G;minimumSpanningTree = new ArrayList<>();// 判断图的联通分量是否为 1;如果大于 1 则直接返回,说明该图没有最小生成树CC cc = new CC(G);if (cc.count() > 1) return;// KruskalList<WeightedEdge> edges = new ArrayList<>();for (int v = 0; v < G.V(); v++)for (int w : G.adj(v))if (v < w)edges.add(new WeightedEdge(v, w, G.getWeight(v, w)));Collections.sort(edges);UnionFind unionFind = new UnionFind(G.V());for (WeightedEdge edge : edges) {int v = edge.getV();int w = edge.getW();if (!unionFind.isSameSet(v, w)) {minimumSpanningTree.add(edge);unionFind.union(v, w);}}}/*** 返回最小生成树的结果集** @return*/public List<WeightedEdge> result() {return minimumSpanningTree;}}
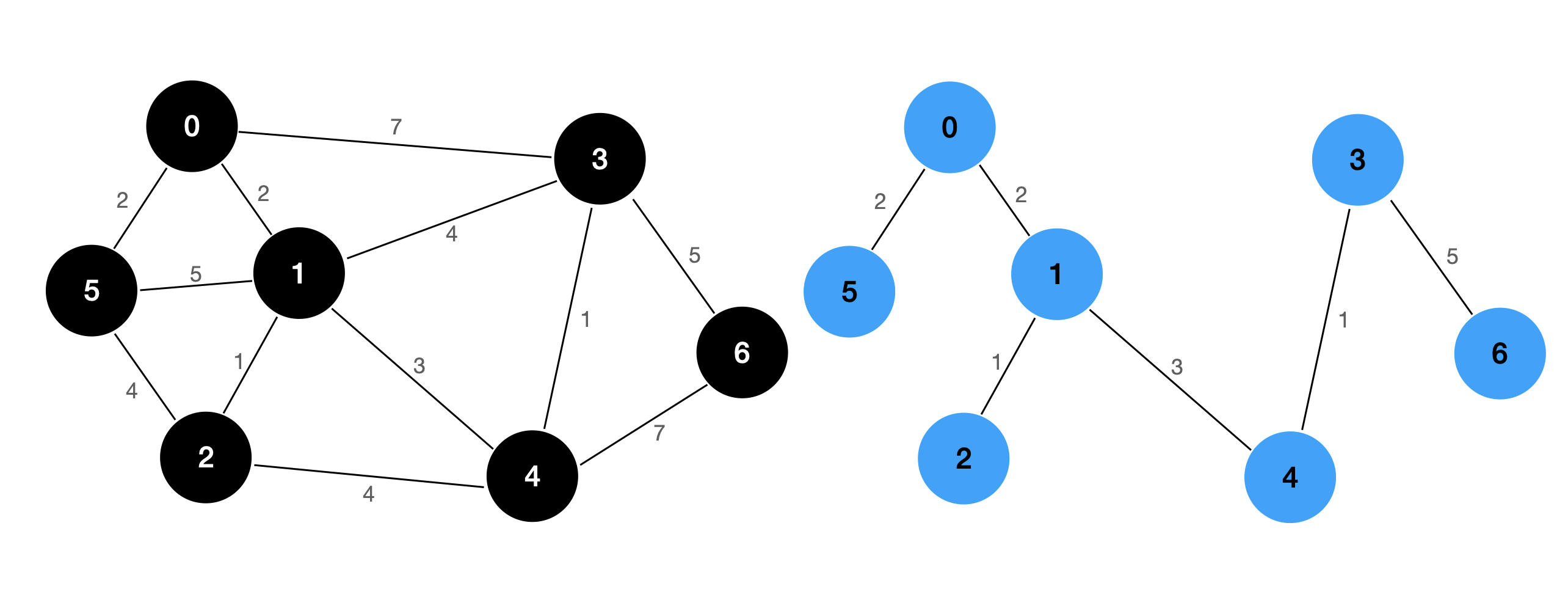
上图中,右图为左图的最小生成树,我们对左边的图进行测试:
测试程序返回的输出结果为:
[(1-2:1), (3-4:1), (0-1:2), (0-5:2), (1-4:3), (3-6:5)]
可以看到,我们的验证结果是正确的。
五:Prim 算法
Prim 算法也可以解决最小生成树问题。相比于 Kruskal 算法,Prim 算法不需要使用并查集来判断当前的边是否构成了环,它巧妙地运用了切分定理。
Prim 算法的执行流程如下:
从第一个顶点开始,该顶点与图中其他顶点构成了一个切分,我们找到当前切分最短的横切边。然后不断扩展切分,直到没有切分时,就找到了图的最小生成树。详细的过程可以参考下面的 PPT:
六:Prim 算法的实现
优先队列
在实现 Prim 算法之前,我们也需要了解一种数据结构,那就是优先队列(PriorityQueue)。
优先队列是是一种特殊的队列。在优先队列中每个元素都有各自的优先级,优先级最高的元素最先得到服务;优先级相同的元素按照其在优先队列中的顺序得到服务。而优先队列往往使用堆来实现。
对于优先队列这样一种数据结构,我们并不需要像并查集一样去自己手动实现。几乎所有语言的标准库中,都有优先队列这样一种数据结构。
在 Java 中,PriorityQueue 默认的底层实现是最小堆。
我们来看一个示例程序:
import java.util.PriorityQueue;import java.util.Queue;public class PriorityQueueTest {@Testvoid test(){Queue<Integer> pq = new PriorityQueue<>();pq.offer(3);pq.offer(2);pq.offer(1);while(!pq.isEmpty())System.out.println(pq.poll());}}
�
该程序输出的结果为:
123
Prim 算法
Prim 算法逻辑流程如下:
- 判断图是否是一个联通图,即判断该图的联通分量是否为 1,如果该图不是一个联通图,就不存在最小生成树
- 初始化一个布尔型数组 visited,长度为图中顶点的个数。对应上面的 PPT ,true 表示节点的颜色为蓝色,false 表示节点的颜色为黑色
- 初始化优先队列,队列中存放的是当前切分所有的横切边,在不断扩展切分,直到没有切分时,此时的优先队列为空,也就找到了最小生成树
- 将第一个顶点渲染为蓝色(
visited[0] = true),与这个顶点相连的所有的边都是横切边,我们将所有的边都加入到优先队列中 - 将优先队列的首个元素出队
- 如果出队的边的两个顶点均为蓝色,则跳过
- 否则,就将该边添加到最小生成树的结果集中
- 将新添加的边的另一个顶点 p 渲染为蓝色
- 找到顶点 p 所有的相邻顶点,如果相邻顶点 w 不是蓝色,就将 p-w 这条边添加到优先队列中
- 循环上述操作,直至优先队列为空,也就找到了最小生成树
Prim 算法的 Java 代码
import java.util.ArrayList;import java.util.List;import java.util.PriorityQueue;import java.util.Queue;public class Prim {private WeightedGraph G;private List<WeightedEdge> minimumSpanningTree;public Prim(WeightedGraph G) {this.G = G;minimumSpanningTree = new ArrayList<>();// 判断该图的联通分量是否为 1,如果大于 1 说明不存在最小生成树CC cc = new CC(G);if (cc.count() > 1) return;// Prim// true 表示为蓝色的顶点 false 表示为黑色的顶点boolean[] visited = new boolean[G.V()];visited[0] = true;Queue<WeightedEdge> pq = new PriorityQueue<>(); // 最小堆for (int w : G.adj(0))pq.offer(new WeightedEdge(0, w, G.getWeight(0, w)));while (!pq.isEmpty()) {WeightedEdge minEdge = pq.remove();if (visited[minEdge.getV()] && visited[minEdge.getW()])continue;minimumSpanningTree.add(minEdge);int p = visited[minEdge.getV()] ? minEdge.getW() : minEdge.getV();visited[p] = true;for (int w : G.adj(p))if (!visited[w])pq.offer(new WeightedEdge(w, p, G.getWeight(w, p)));}}/*** 返回最小生成树的结果集** @return*/public List<WeightedEdge> result() {return minimumSpanningTree;}}
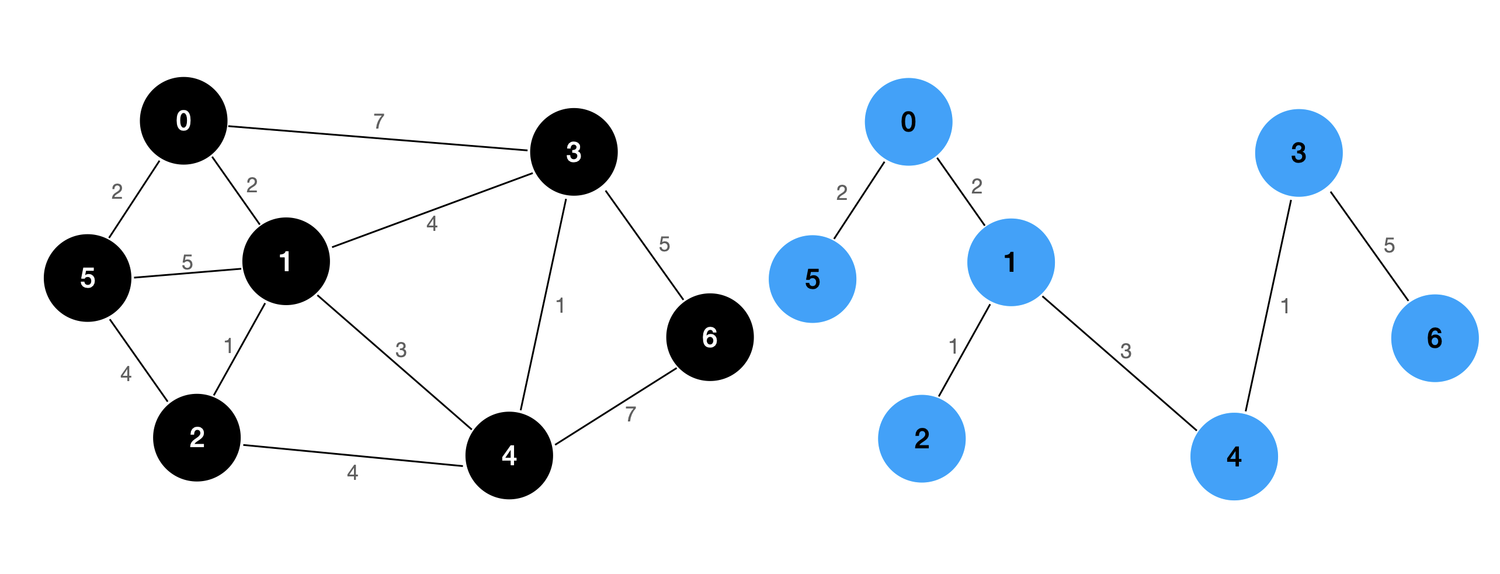
我们依旧使用左图进行测试,右图为左图的最小生成树。
测试程序返回的输出结果为:
[(0-1:2), (2-1:1), (0-5:2), (4-1:3), (3-4:1), (6-3:5)]
可以看到,我们的 Prim 算法的验证结果是正确的。

若有收获,就点个赞吧
0 人点赞
