【数据结构与算法基础】代码仓库:https://github.com/jinrunheng/datastructure-and-algorithm
一:哈密尔顿回路和哈密尔顿路径
1859 年,爱尔兰数学家哈密尔顿(Hamilton)提出了一个“周游世界”的游戏:
在一个正十二面体的二十个顶点上,标注了伦敦,巴黎,莫斯科等世界著名大城市,正十二面体的棱表示连接着这些城市的路线。要求游戏参与者从某个城市出发,把所有的城市都走过一次,且仅走过一次,然后回到出发点。这就是著名的哈密尔顿回路问题。
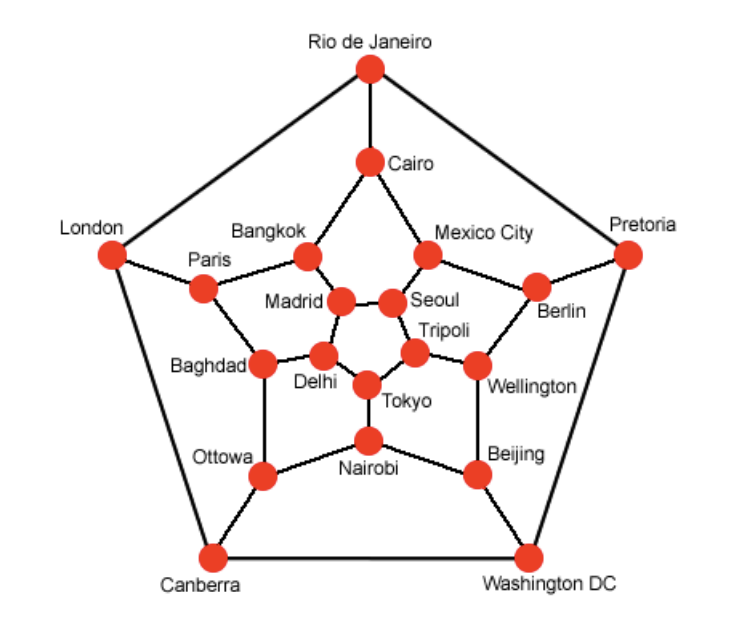
简而言之,哈密尔顿回路是指,从图中的一个顶点出发,沿着边行走,经过每个顶点恰好一次,之后再回到出发点。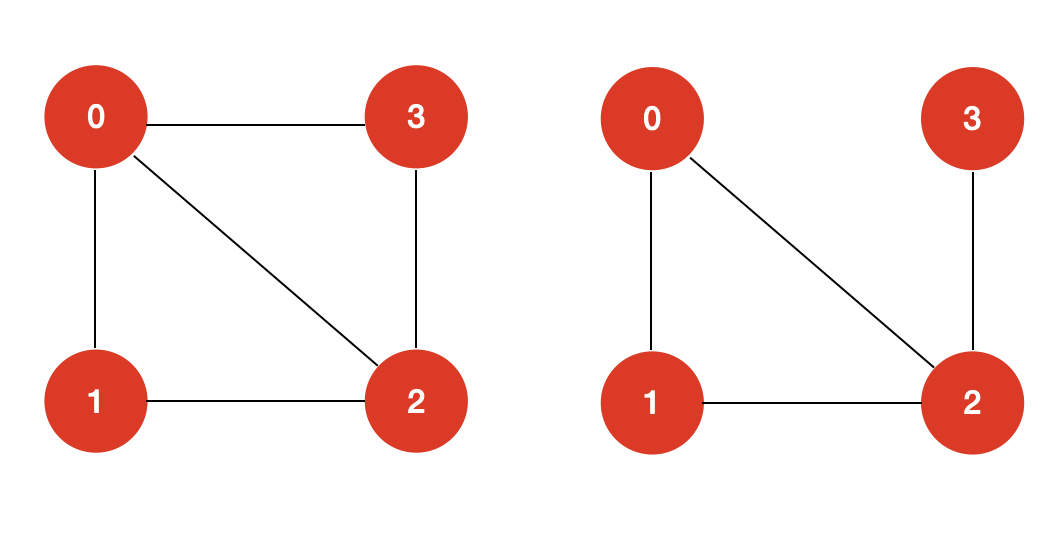
对于上面给出的示例图中,左图就存在哈密尔顿回路,而右图不存在哈密尔顿回路。
不过,右图是存在哈密尔顿路径的,哈密尔顿路径和哈密尔顿回路的定义只有一点不同,不同点在于哈密尔顿回路要求从起始点出发,遍历每个顶点且每个顶点仅遍历一次,并能回到起始点(回路);哈密尔顿路径则是要求从起始点出发,遍历图的每个顶点且每个顶点仅遍历一次,不需要能回到起始点,也就是说,起始点和终止点不要求有一条边。
对于右边这个图来说,0->1->2->3 和 3->2->1->0 都是可行的哈密尔顿路径,但是,由于顶点 0 和顶点 3 之间没有边,所以不构成哈密尔顿回路。
二:求解哈密尔顿回路
如何求解哈密尔顿回路?
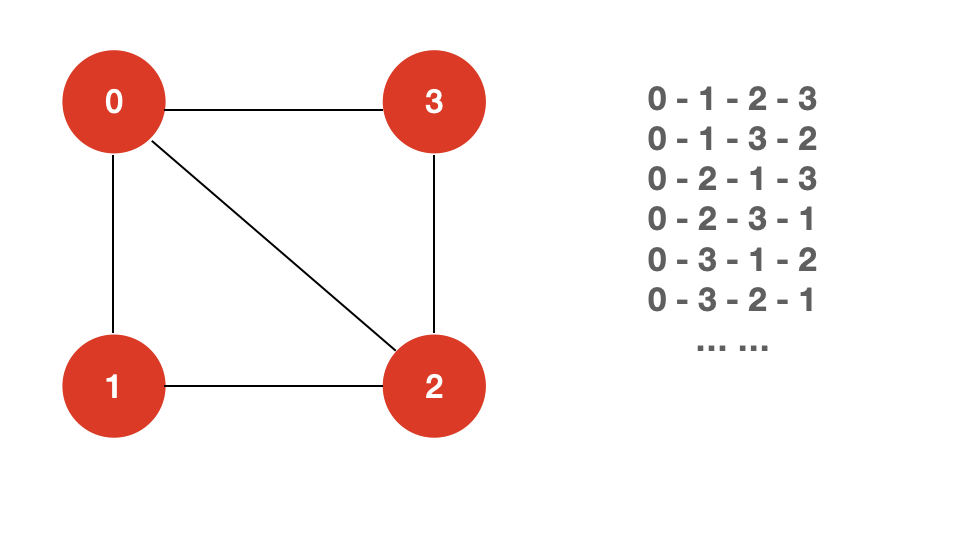
我们能想到最简单的方法就是暴力求解。类似于求解全排列问题,我们遍历图的每一个顶点 v,然后从 v 开始出发,看是否能够找到一条哈密尔顿回路。
我们知道,全排列问题的时间复杂度为 O(n!)。O(n!) 并不是一个多项式级别的复杂度。像 O(1),O(nlogn),O(n2) 这种级别的复杂度都是多项式级的复杂度,而像 O(an),O(n!) 这样的复杂度是非多项式级的,其复杂度之高,往往在数据量极大的情况下,计算机是不能承受的。
像哈密尔顿回路问题,目前除了暴力求解这种方法之外,我们还没有找到一种多项式级别的算法来求解这道问题,通常像这种问题被称为 NP(Non-deterministic Polynomial) 难的问题。
求解哈密尔顿回路的算法采用回溯的思想来简化暴力破解,过程模拟在 PPT 中:
代码如下:
package com.github.datastructureandalgorithm.graph.chapter9;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class HamiltonLoop {private Graph G;private boolean[] visited;private int[] pre;private int end; // end 表示 哈密尔顿回路是从 0 开始遍历到 end,end 是哈密尔顿回路的最后一个顶点public HamiltonLoop(Graph G) {this.G = G;visited = new boolean[G.V()];pre = new int[G.V()];end = -1;dfs(0, 0);}/*** 对图进行深度优先遍历** @param v*/private boolean dfs(int v, int parent) {visited[v] = true;pre[v] = parent;for (int w : G.adj(v)) {if (!visited[w]) {if (dfs(w, v)) return true;} else if (w == 0 && allVisited()) {end = v;return true;}}visited[v] = false;return false;}private boolean allVisited() {for (boolean b : visited)if (!b) return false;return true;}/*** 获取哈密尔顿回路** @return*/public List<Integer> result() {List<Integer> res = new ArrayList<>();if (end == -1) return res;int cur = end;while (cur != 0) {res.add(cur);cur = pre[cur];}res.add(0);Collections.reverse(res);return res;}}
上面的代码中,我们的 allVisited 方法需要遍历一次 visited 数组。我们可以对我们的代码进行改进,设置一个变量 left,表示还有多少个顶点没有遍历到,每次的 dfs 过程中,都维护这个变量,直到 left == 0 时,说明所有的顶点都被遍历过了,改进的代码如下:
package com.github.datastructureandalgorithm.graph.chapter9;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class HamiltonLoop2 {private Graph G;private boolean[] visited;private int[] pre;private int end;private int left;public HamiltonLoop2(Graph G) {this.G = G;visited = new boolean[G.V()];pre = new int[G.V()];end = -1;left = G.V();dfs(0, 0);}/*** 对图进行深度优先遍历** @param v* @param parent* @return*/private boolean dfs(int v, int parent) {visited[v] = true;pre[v] = parent;left--;for (int w : G.adj(v)) {if (!visited[w]) {if (dfs(w, v)) return true;} else if (w == 0 && left == 0) {end = v;return true;}}visited[v] = false;left++;return false;}/*** 获取哈密尔顿回路** @return*/public List<Integer> result() {List<Integer> res = new ArrayList<>();if (end == -1) return res;int cur = end;while (cur != 0) {res.add(cur);cur = pre[cur];}res.add(0);Collections.reverse(res);return res;}}
三:求解哈密尔顿路径
求解哈密尔顿路径和求解哈密尔顿回路的算法整体框架是基本一致的。
对于求解哈密尔顿路径来说,起始点是谁很重要,同一个图,从有的起始点出发就存在哈密尔顿路径,从有的起始点出发就不存在哈密尔顿路径。所以,我们在算法设计中,构造函数需要用户显示地传入起始点。
我们的哈密尔顿路径求解的算法类 HamiltonPath 的构造函数是这样的:
public HamiltonPath(Graph G,int s)
除了这一点外,求解哈密尔顿路径只需要保证,从起始点开始,所有的点被遍历过且仅被遍历一次,并不需要起始点和终止点之间有边。
所以,在 dfs 的逻辑中,我们只需要改变递归的终止条件即可:
// 不需要保证终止点 v 和 起始点 s 存在一条边,即: G.hasEdge(v, s)if(left == 0 /*&& G.hasEdge(v, s)*/){end = v;return true;}
代码如下:
package com.github.datastructureandalgorithm.graph.chapter9;import java.util.ArrayList;import java.util.Collections;import java.util.List;public class HamiltonPath {private Graph G;private int s;private boolean[] visited;private int[] pre;private int end;private int left;public HamiltonPath(Graph G, int s) {this.G = G;this.s = s;visited = new boolean[G.V()];pre = new int[G.V()];end = -1;this.left = G.V();dfs(s, s);}private boolean dfs(int v, int parent) {visited[v] = true;pre[v] = parent;left--;if (left == 0) {end = v;return true;}for (int w : G.adj(v)) {if (!visited[w]) {if (dfs(w, v)) return true;}}visited[v] = false;left++;return false;}/*** 返回哈密尔顿路径** @return*/public List<Integer> result() {List<Integer> res = new ArrayList<>();if (end == -1) return res;int cur = end;while (cur != s) {res.add(cur);cur = pre[cur];}res.add(s);Collections.reverse(res);return res;}}
四:LeetCode 上的哈密尔顿问题:不同路径III
本题是一道经典的求解哈密尔顿路径问题,使用经典的回溯法即可解决,就不再赘述了,详情请见代码:
class Solution {private int[][] grid;private int r, c;private boolean[][] visited;private int left;private int start;private int end;private int[][] dirs = {{-1, 0}, {0, 1}, {1, 0}, {0, -1}};public int uniquePathsIII(int[][] grid) {this.grid = grid;this.r = grid.length;this.c = grid[0].length;this.visited = new boolean[r][c];this.left = r * c;for (int i = 0; i < r; i++)for (int j = 0; j < c; j++)if (grid[i][j] == 1) {start = i * c + j;grid[i][j] = 0;} else if (grid[i][j] == 2) {end = i * c + j;grid[i][j] = 0;} else if (grid[i][j] == -1) {left--;}return dfs(start);}int dfs(int s) {int x = s / c;int y = s % c;visited[x][y] = true;left--;if (s == end && left == 0) {// 回溯visited[x][y] = false;left++;return 1;}int res = 0;for (int d = 0; d < 4; d++) {int nextX = x + dirs[d][0];int nextY = y + dirs[d][1];if (isValid(nextX, nextY) && !visited[nextX][nextY] && grid[nextX][nextY] != -1) {int next = nextX * c + nextY;res += dfs(next);}}// 回溯visited[x][y] = false;left++;return res;}private boolean isValid(int x, int y) {return x >= 0 && x < r && y >= 0 && y < c;}}
五:状态压缩
哈密尔顿回路状态压缩代码链接🔗
哈密尔顿路径状态压缩代码链接🔗
在我们的代码中,一直都使用布尔型的 visited 数组来记录图中的每一个顶点是否有被遍历过。在算法面试中,对于像哈密尔顿回路/路径这样的 NP 难问题,通常都会有输入限制,一般情况下,求解问题中给定的图不会超过 30 个顶点。
我们可以使用状态压缩的思想,将 visited 数组简化成一个数字。我们知道一个 int 型的数字有 32 位,每一位不是 1 就是 0,这正好对应了布尔型的 true 和 false。
来看一下我们的代码:
我们的 dfs 中,涉及到 visited 数组的操作共有三处,这三处对布尔型数组的赋值操作可以转换为位运算的操作:
如果第 i 位为 0,设为 1;
visited + (1 << i);
看其第 i 位是否为 1;
visited & (1 << i) == 0 ?
如果第 i 位为 1,设为 0;
visited - (1 << i) == 0;
具体改动代码请参考链接。
六:记忆化搜索
我们来看一下,我们当前的算法类有什么问题:
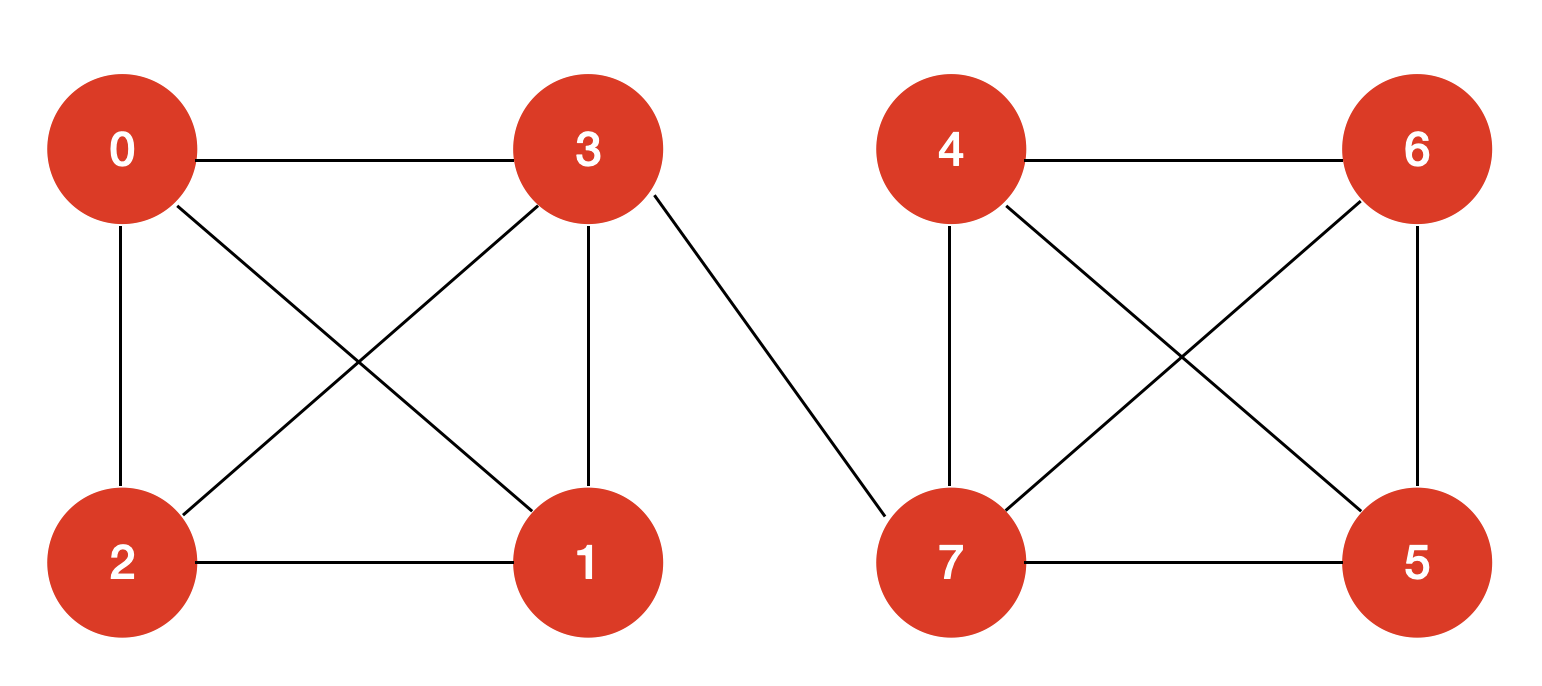
对于上面这个图来说,因为顶点 3 和顶点 4 之间只有一条边,所以肯定是不会构成一条哈密尔顿回路的。
但是我们的回溯算法在遍历顶点时,不会提前返回结果,譬如:
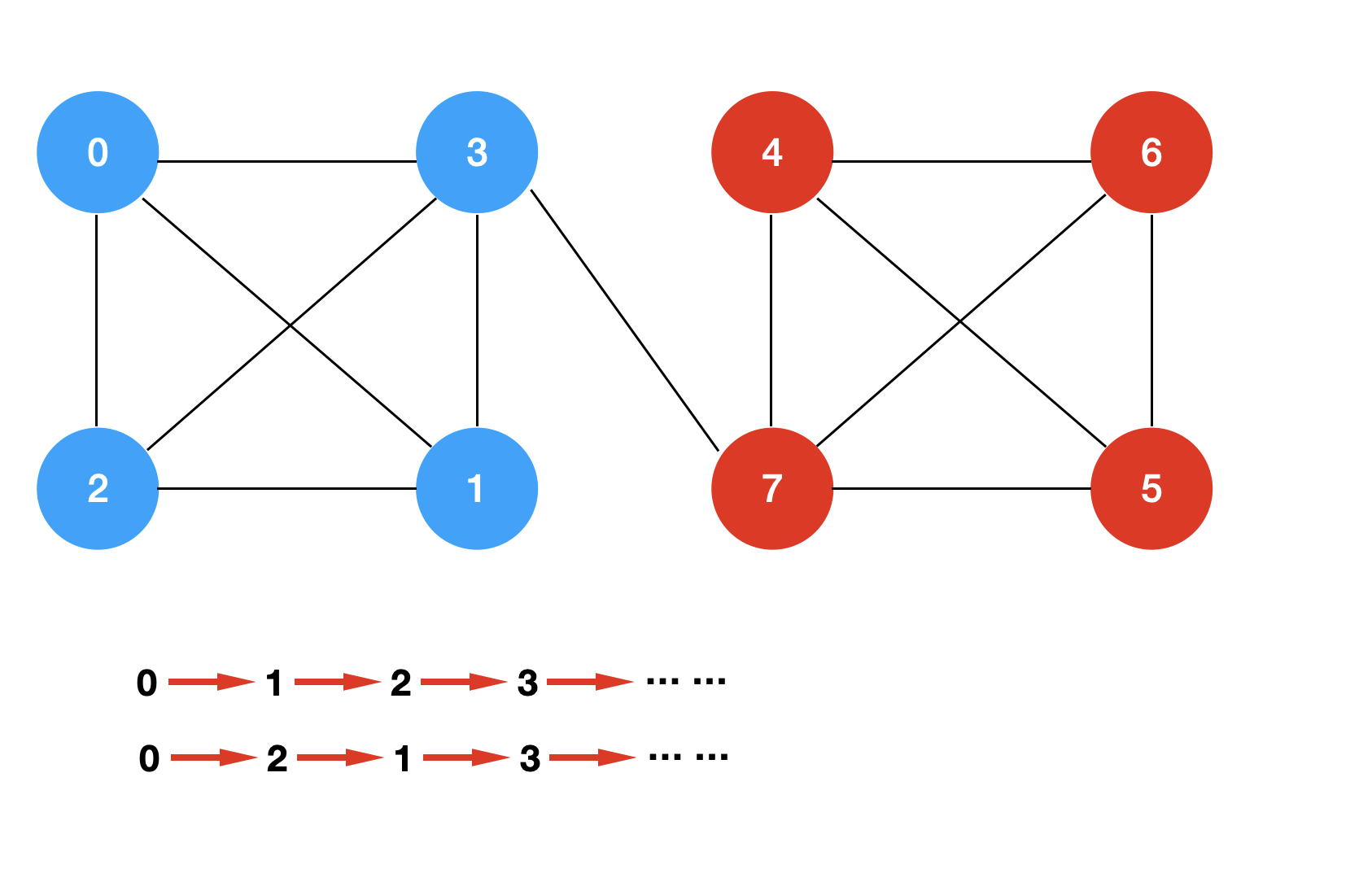
依次遍历 0 -> 1 -> 2 -> 3 … 这些顶点,图中,0,1,2,3 这些顶点都已经被访问过,所以我对这些顶点标记为蓝色;我们发现找不到一条哈密尔顿回路。
而下一次的遍历,则会依次遍历 0 -> 2 -> 1 -> 3 这些顶点,我们遍历左侧的图的最后一个顶点仍然为 3,且左侧的四个顶点都已经被遍历过。这个时候我们知道,其实可以提前返回结果,但是我们的算法类不具有这个功能。
要想实现提前返回这个功能,就需要在我们设计的算法类中加入记忆化搜索。
实现记忆化搜索非常简单,在我们设计算法类中,再开辟一个数组memory[1 << G.V()][G.V()] 对应着 dfs 的方法签名中的 dfs(visited,v)。我们开辟的 memory 将会记录 visited 和 v 这个组合有没有计算过,像上面给定的示例,两次遍历中,左侧的四个顶点都已经被访问过了,且最后遍历都落到了 3 这个顶点,我们在第一次遍历时,就可以记录这个状态,等到第二次遍历时,发现这个状态已经出现过,就可以避免重复遍历。
添加了记忆化搜索的时间复杂度和回溯法的时间复杂度不同,记忆化搜索的时间复杂度为: 相比于回溯法的
相比于回溯法的  来讲实际上各有利弊,因为我们的回溯法中也有剪枝的过程。但是,整体上来讲,随着 n 的不断增大,
来讲实际上各有利弊,因为我们的回溯法中也有剪枝的过程。但是,整体上来讲,随着 n 的不断增大, 的复杂度是要高于
的复杂度是要高于  的。
的。
现在,我们针对于 LeetCode 980. 不同路径 III 这个问题,来添加上记忆化搜索,看一下执行的效率如何。
import java.util.Arrays;/*** LeetCode 980.不同路径 III:https://leetcode-cn.com/problems/unique-paths-iii/* <p>* 添加了对 visited 状态压缩的优化* 添加了记忆化搜索*/public class Solution2 {private int[][] grid;private int r, c;private int left;private int start;private int end;private int[][] dirs = {{-1, 0}, {0, 1}, {1, 0}, {0, -1}};private int[][] memory;public int uniquePathsIII(int[][] grid) {this.grid = grid;this.r = grid.length;this.c = grid[0].length;this.left = r * c;int visited = 0;this.memory = new int[1 << r * c][r * c];for (int i = 0; i < memory.length; i++)Arrays.fill(memory[i], -1);for (int i = 0; i < r; i++)for (int j = 0; j < c; j++)if (grid[i][j] == 1) {start = i * c + j;grid[i][j] = 0;} else if (grid[i][j] == 2) {end = i * c + j;grid[i][j] = 0;} else if (grid[i][j] == -1) {left--;}return dfs(visited, start);}int dfs(int visited, int s) {// 说明该状态已经被记录过if (memory[visited][s] != -1)return memory[visited][s];visited += (1 << s);left--;if (s == end && left == 0) {// 回溯visited -= (1 << s);left++;memory[visited][s] = 1;return 1;}int res = 0;int x = s / c;int y = s % c;for (int d = 0; d < 4; d++) {int nextX = x + dirs[d][0];int nextY = y + dirs[d][1];int next = nextX * c + nextY;if (isValid(nextX, nextY) && (visited & (1 << next)) == 0 && grid[nextX][nextY] != -1) {res += dfs(visited, next);}}// 回溯visited -= (1 << s);left++;memory[visited][s] = res;return res;}private boolean isValid(int x, int y) {return x >= 0 && x < r && y >= 0 && y < c;}}
在我的电脑上,使用回溯算法的执行效率为:

添加了记忆化搜索之后,算法的执行效率为:
对于 LeetCode 上这道问题,添加了记忆化搜索之后,我们提交的代码执行时间实际上是更慢了,原因就在于,我们开辟 memory 数组的时间上。虽然我们的算法解决了重复遍历的情况,但是对于没有那么多重复的情况下,我们的记忆化搜索也不一定有回溯更快,这一点望大家可以了解。

若有收获,就点个赞吧
0 人点赞
