“前端模块化”是“前端工程化”的重要一环。 “前端工程化”的目的是提升:【效率】、【质量】。 “前端模块化”方便多人开发,提升效率;方便维护,提升质量。
一、为什么要模块化
项目越来越大,JS文件越来越多,众多的JS文件要如何协调放置、使用?
<script src="./b.js"></script><script src="./a.js"></script><script src="./c.js"></script>......
- script过多,http加载缓慢
- 变量污染、命名冲突、模块成员可以被修改(其实是一件事情)
- 模块依赖关系不明确
- 模块加载先后顺序问题
- 未使用、未引用的代码,不方便在部署中去除(因为没法定义联系)
当一个事情过于庞大,需要多人一起完成。往往人们会进行仔细的分工,将工作均匀分配,有利于降低成本,提升质量。 一个单一的工种总是比较好培养的;一个人一生只做一件事情,更容易精通。 实现这种分工的第一步,也许就是将【任务/工作】拆分。
二、模块化的方案们
1、文件划分
2、文件划分 + 命名空间
3、文件划分 + 命名空间 + 立即执行函数(闭包)
4、CommonJS
5、AMD
6、CMD
7、ES6(import/export)
使用文件划分,无法解决我们的先后依赖关系。 我们需要更多的结构化的东西,帮我们进行索引。
三、CommonJS
使用于服务端的模块标准。
3.1 CommonJS比原始的文件划分好在哪里
=> 通过 index.html,引入不同的 script,最终他们还是在一个全局作用域。 => 最终,我们还是要暴露一个结果,给全局作用域使用。
单纯的文件划分是不完善的,因为他存在“模块标识冲突的问题”。
本质上的原因还是原始的文件划分,需要通过 windows 公开到全局。事实上在UMD(自适应的模块化,自动降级),如果不支持(ES6-import/AMD/CommonJS),也依旧是通过挂载在全局 windows 实现的。
完善的模块一定不会存在模块标识冲突的问题,且系统中的任何模块都应该能够无歧义的地引用其他模块 ————《高级JavaScript程序设计》——第四版
这里,我也想起了关于【产品文档】的设计:
【如果能够对一种设计,作出两种实现的解释,那就说明,这份文档说明是不够清晰的、准确的。】
这个时候,就需要找“产品经理”沟通一下了,这是我第二份正式工作的经验。
3.2 CommonJS做的事情
- 每个文件就是一个模块,有自己的作用域。
- 【在一个文件里面定义的变量、函数、类,都是私有的,对其他文件不可见。】
暴露出 module 和 require 这两个 API 给用户使用。
3.3 使用规范
通过 exports/module.exports 导出模块(每个文件首部执行了 var exports = module.exports)
注意,其实commonJS真正暴露的是 module 和 require 对象。 只不过在首部加上了 var exports = module.exports。 【真正的导出模块是 module.exports,exports只是module.exports一个拷贝(小弟)】 这也意味着,我们就算随意改变 exports,也不要去乱给 module.exports 赋值。(当然,这两个你都不应该随意去修改)
module.exports = {b: 1}exports = {a: 11}// 本文件最后导出 { b: 1 }
- 通过 require 引入模块
3.3.more 关于 require 的顺序
我们来看一个示例
- main.js:我们引入一个 ‘./test’ ``` const x = require(‘./test’) console.log(‘test’, require.cache)
console.log(‘x’, x)
- test/index.js
console.log(‘test’)
module.exports = { name: ‘我是index.js’ }
- test/package.json
{ “main”: “self.js” }
- test/self.js
console.log(‘self.js’)
module.exports = { name: ‘我是self’ }
我们来看下最后的输出:<br />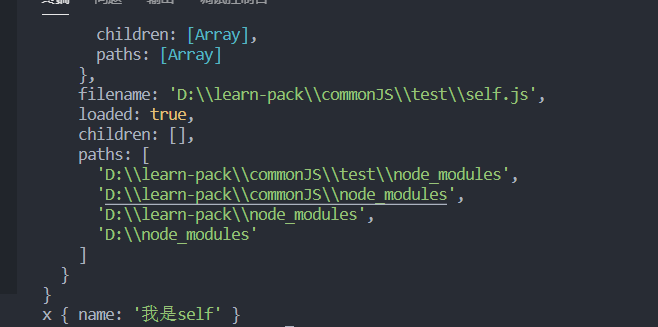<br />这里的require顺序其实是:<a name="qgijg"></a>#### 3.4 特性- Node内置模块优先,commonJS运行于Node,Node中有一些自己的模块(path/http)- Require用于载入,载入1次之后,就会缓存在内存中- Require顺序 => 缓存 => node_modules => package.json-"main"属性 => index.js- Module.exports负责导出<a name="Jyzgl"></a>#### 3.5 为什么说commonJS不适用浏览器<a name="SOtov"></a>##### 其实,根本原因是:【环境问题】> 浏览器没有 require/module 等的 API。<a name="ixge2"></a>##### 它是同步的,只有前置A加载了,才能进行后面的(容易造成阻塞 + 没有办法通知)【在浏览器中,常见的解决方案(低时延的诉求)】- 所有的模块打包在一个 闭包的 的文件中(减少请求)- 提前生成好依赖图<a name="HAmgw"></a>### 四、AMD> 为了实现浏览器上的诉求,采用AMD标准的框架诞生了,RequireJS是其中之一<a name="wYuSW"></a>#### 4.1 使用示例html
<!DOCTYPE html>
main.js
require([‘add’], function(math) { console.log(math.add(100, 200)) })
math.js
// math.js define(‘add’, function (add) { return { add: add }; });
add.js
define(function() { ‘use strict’; return { add: function(a, b) { console.log(‘hh’) return a + b } } });
> 从上述代码,我们可以看出:> AMD的模块化,通过 define 定义被依赖的模块,通过 require 引入我们需要的模块。<a name="zWnvb"></a>#### 4.2 更完善的使用案例html> 据说直接使用 data-main,可以省下一个 script 标签
<!DOCTYPE html>
config.js> 有一种 webpack 的配置项既视感哈哈,果然是前辈
requirejs.config({ baseUrl: ‘./‘, paths: { “jQ”: ‘libs/jquery’ } });
index.js> 大概明白了,所谓的“依赖前置”;但看到这里还是没有办法明白,它是如何实现异步的即时加载的?观察者模式??
require([‘./config’], () => { require([‘math’], function (math) { console.log(math.add(100, 200)) console.log(math.diff(400, 1)) console.log(math.multi(9, 9)) }) })
<a name="rp0Jx"></a>#### 4.3 使用规范- 一个文件只能有一个 define,第二个 define 无用- 通常define都返回对象,但其实其余的函数返回值也是可以的
define(function() { return function(a, b) { console.log(a + b) } });
更多使用规范可参考:<br />[https://blog.csdn.net/sanxian_li/article/details/39394097](https://blog.csdn.net/sanxian_li/article/details/39394097)<a name="UcwA1"></a>#### 4.4 原理> 为什么它能够实现异步?是使用了“观察者”模式吗?> 答案:是的,它使用 addEventListener,而 addEventListener 本身就是“观察者”模式的一种实现。> 源码地址:[https://github.com/requirejs/requirejs/blob/master/require.js](https://github.com/requirejs/requirejs/blob/master/require.js)> 2000 行代码附上大佬的源码解释链接:[https://www.cnblogs.com/zhiyishou/p/4770013.html?utm_source=tuicool](https://www.cnblogs.com/zhiyishou/p/4770013.html?utm_source=tuicool)<br />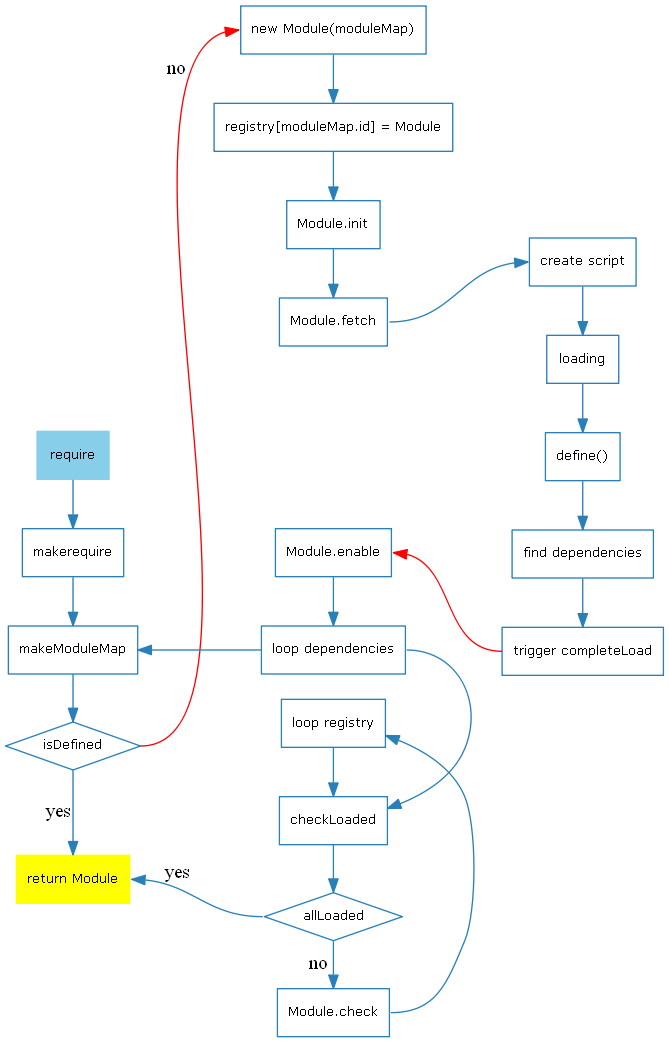<a name="B9zr3"></a>##### 先说下它用到了什么思想和知识点?- 事件循环> 50ms,轮询一次,check依赖是否都加载好了
checkLoadedTimeoutId = setTimeout(function () {checkLoadedTimeoutId = 0;checkLoaded();}, 50);
- 观察者模式- script的defer和async<a name="s9Opg"></a>##### 参与元素:- depCount - 用于计算依赖的数目是否加载完毕- nextTick
req.nextTick = typeof setTimeout !== ‘undefined’ ? function (fn) { setTimeout(fn, 4); } : function (fn) { fn(); };
<a name="erCzu"></a>##### 思路:- 确定入口(通过 data-main)- 确定关系,生成依赖图谱(依赖树)- 执行依赖项的加载(通过50ms轮询的方式确立所有依赖项是否被加载完毕)- 向入口回调(依赖加载完毕,depCount === 0)> 仔细想来,和webpack的思想其实很像,不过和打包工具的比较又是另一类事情了<a name="F5pND"></a>##### 其他:RequireJS的代码用 r.js 来打包,其实还是冗杂了大量的代码,没有像 webpack 那样实现分片。<br />我很好奇的是,RequireJS当时研究的人,并没有今日研究 Webpack 的多,也许是:- 它地位保持的时间较短- 互联网不是那么发达- 前端网红的气氛还没有形成- 有更多其他的事情要研究,比如 Node.js- 它的地位,并没有如今 Webpack 高<a name="c0gKX"></a>### 五、CMD> CMD是Sea.js在发展中,慢慢形成的规范。> CMD一开始优于AMD,不过后期AMD渐渐也实现了CMD的优点。> 所以,其实,【AMD和CMD是近似的】。
define(function(require, exports, module) {
var a = require(‘./a’)
a.doSomething()
var b = require(‘./b’)
b.doSomething()
})
```
早期的AMD是,一开始就要定好所有依赖的顺序图谱——即所谓的“依赖前置”,要求开发者把所有的依赖关系都理清楚。(看看,webpack就不这样,减少了开发人员的工作量和难度)
CMD的思想是,减少开发者的工作量,你不需要面面俱到地熟悉依赖图谱,才能进行开发。
六、ES6之import/export
6.1 和commonJS的差异

若有收获,就点个赞吧
0 人点赞
