hive不区分大小写,Spark、Parquet都区分
Spark中执行建表语句
CREATE TABLE luna_bar (ID_NO INT,USER_NAME STRING) partitioned by (pt string);
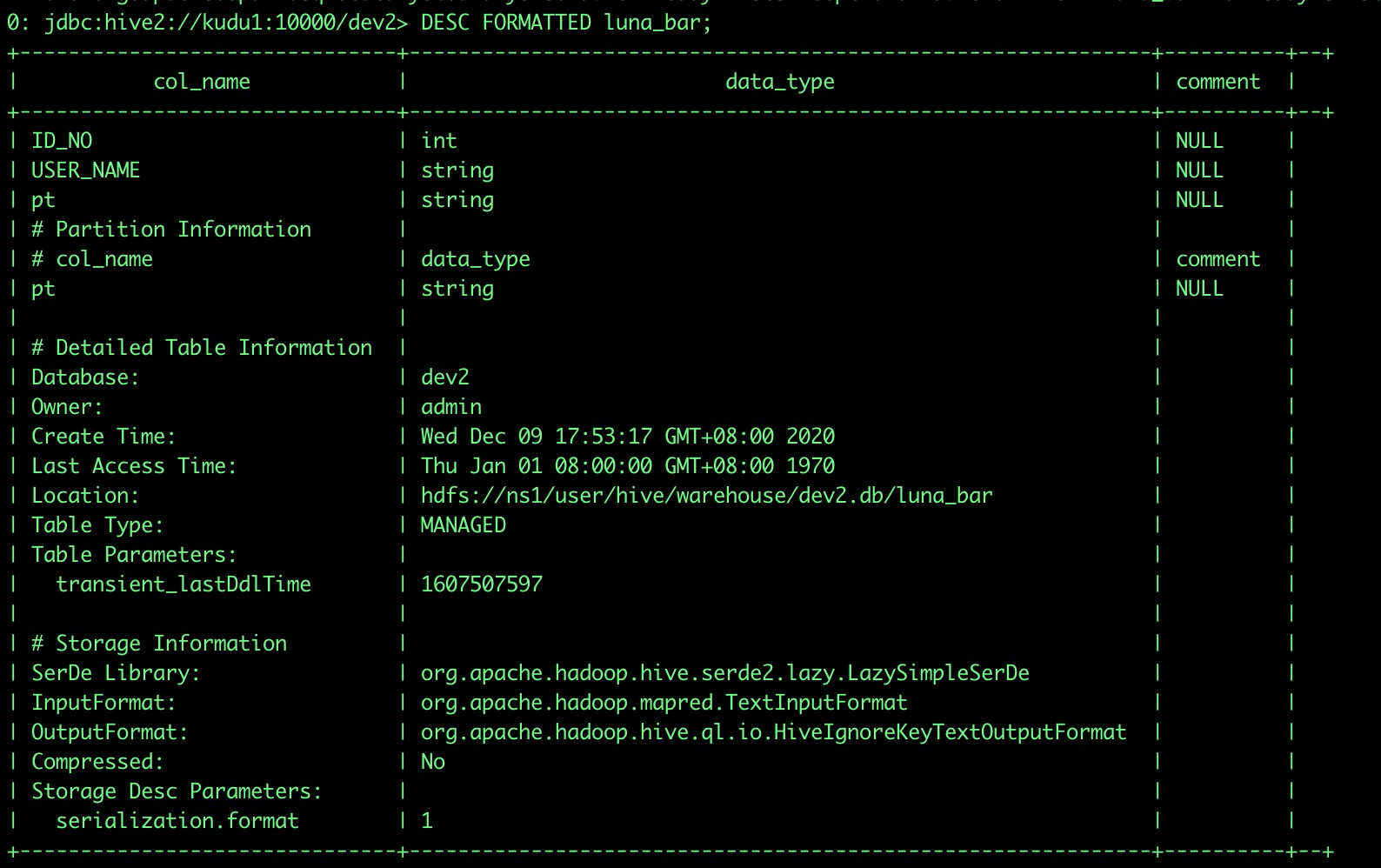
Hive执行相同建表语句
CREATE TABLE luna_foo (ID_NO INT,USER_NAME STRING) partitioned by (pt string);
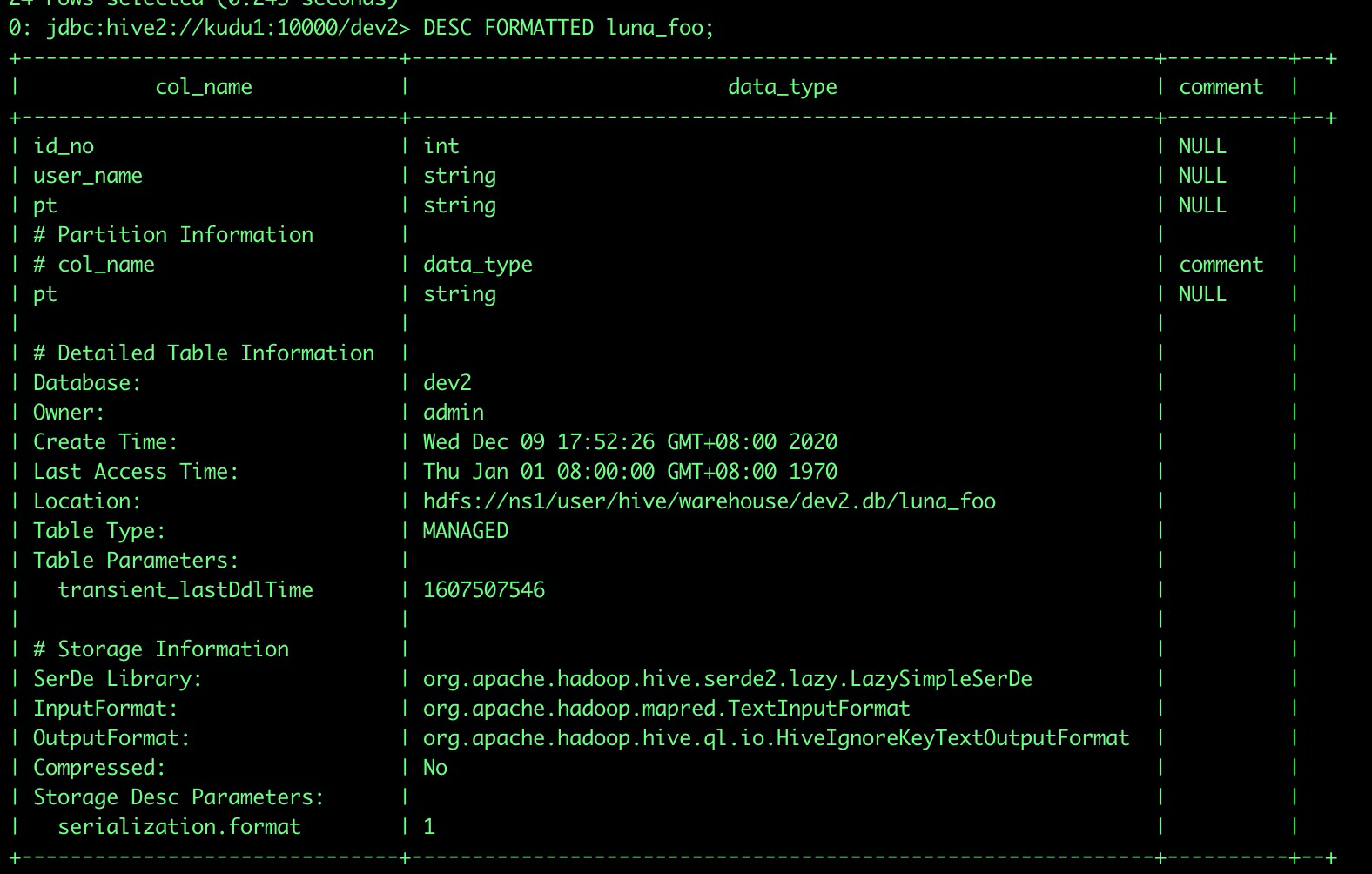
元数据写入
Hive大小写不敏感,建表的时候会把字段全转成小写再写入metastore数据库。
Spark会保留原来的大小写,写入数据库。
元数据读取
读的时候Hive读到metastore大写字段也会转成小写显示。
Metastore与Parquet元数据问题
# Metastore中是小写的话。可以加这个选项把大小写Parquet都读出来。spark.sql.hive.convertMetastoreParquet=false #默认是truespark.sql.hive.caseSensitiveInferenceMode=INFER_AND_SAVEspark.sql.parquet.mergeSchema=trueINFER_AND_SAVEINFER_ONLYNEVER_INFER

若有收获,就点个赞吧
0 人点赞
