ZKFailoverController
NameNode上运行的独立进程,进程名zkfc。 内部包含HealthMonitor 和 ActiveStandbyElector。
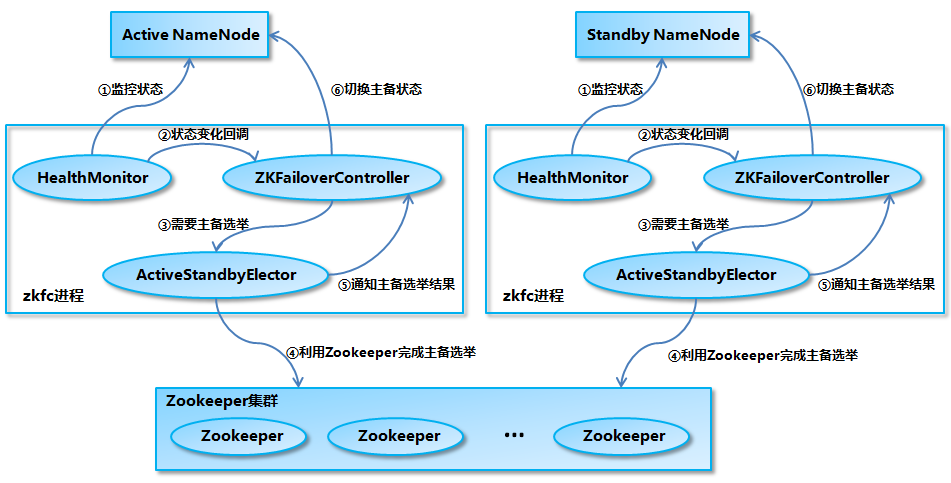
主备切换流程
- HealthMonitor 初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。
- HealthMonitor 如果检测到 NameNode 的健康状态发生变化,会回调 ZKFailoverController 注册的相应方法进行处理。
- 如果 ZKFailoverController 判断需要进行主备切换,会首先使用 ActiveStandbyElector 来进行自动的主备选举。
- ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举。
- ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 的相应方法来通知当前的 NameNode 成为主 NameNode 或备 NameNode。
- ZKFailoverController 调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或 Standby 状态。
HealthMonitor
ActiveStandbyElector
/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock
选主成功:ActiveStandbyElector调用ZKFailoverController.becomeActive调用RPC HAServiceProtocol.transitionToActive将NN设置成Active。
选主失败:ActiveStandbyElector调用ZKFailoverController.becomeActive调用RPC HAServiceProtocol.transitionToStandby将NN设置成Standby。
防脑裂
如果 ActiveStandbyElector 选主成功之后,发现了上一个 Active NameNode 遗留下来的/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb 节点 (见“ActiveStandbyElector 实现分析”一节“防止脑裂”部分所述),那么 ActiveStandbyElector 会首先回调 ZKFailoverController 注册的 fenceOldActive 方法,尝试对旧的 Active NameNode 进行 fencing,在进行 fencing 的时候,会执行以下的操作:
- 首先尝试调用这个旧 Active NameNode 的 HAServiceProtocol RPC 接口的 transitionToStandby 方法,看能不能把它转换为 Standby 状态。
- 如果 transitionToStandby 方法调用失败,那么就执行 Hadoop 配置文件之中预定义的隔离措施,Hadoop 目前主要提供两种隔离措施,通常会选择 sshfence:
- sshfence:通过 SSH 登录到目标机器上,执行命令 fuser 将对应的进程杀死;
- shellfence:执行一个用户自定义的 shell 脚本来将对应的进程隔离;
只有在成功地执行完成 fencing 之后,选主成功的 ActiveStandbyElector 才会回调 ZKFailoverController 的 becomeActive 方法将对应的 NameNode 转换为 Active 状态,开始对外提供服务。
QJM
QJM主要保存Editlog,并不保存FSImage文件。FSImage还在NN本地磁盘。QJM基本思想来之Paxos算法,多个JournalNode节点村粗edit log。每个JournalNode保存同样edit log副本。每次NN写editlog,除了向本地还会并行向JN中的每个节点写,只要半数以上JN节点返回成功就认为成功。
Active NN向JN集群写,Standby NN向JN集群读。
Standy读JournalNode集群过程
Standby会启动EditLogTailer线程。定时调用EditLogTailer.doTailEdits从JN集群同步edit log。同步下来的edit log会合并到内存文件系统镜像中(并不会把edit log写入本地磁盘)。
从JN集群同步的edit log都是出于finalized状态的segment。
Standby定时从JN同步,会落后于Active的内存中文件系统镜像,所以Standby NameNode 在转换为 Active NameNode 的时候需要把落后的 edit log 补上来。
硬伤
Epoch
每次主备切换 Epoch会加一。实际是一种fencing机制,防止脑裂。
生成新Epoch步骤
Active NN 向JournalNode集群发送 getJournalState 远程调用,每个JournalNode返回自己保存的最近Epoch(lastPromisedEpoch)。
NN收到过半JN返回Epoch后,选择最大的加一,作为新的Epoch。向所有JN发送newEpoch远程调用,将新Epoch发给各个JN。
JN收到后检查是否比本地 的大,如果比本地大则更新为新的值。并向NN返回本地edit log 最新segment的起始事务id(为后续数据恢复做准备)。如果小于本地则向NN返回错误。
NN收到过半JN对newEpoch的响应则认为成功。
Epoch作用
NN向JN提交edit log都会带上Epoch。如果原来Active恢复正常,向JN写,JN与本地Epoch值对比,发现提交的Epoch小于本地,那么将拒绝写入。这样就可防止脑裂。
Recovery
(SegmentRecoveryComparator算法:优先选择Finalized Segment,再次选择JournalNode端可见最大Epoch的Segment,最后比较endTxId最大者)
每隔 1000*Math.min(checkpointCheckPeriod, checkpointPeriod)秒
Standby 上传 fsp_w_picpath 到Active
<property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://hadoop0:8485;hadoop1:8485;hadoop2:8485/cluster</value></property><property><name>dfs.journalnode.edits.dir</name><value>/var/hadoop/journal</value></property>
参考
https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/index.html
https://hexiaoqiao.github.io/blog/2018/03/30/the-analysis-of-basic-principle-of-hdfs-ha-using-qjm/

若有收获,就点个赞吧
0 人点赞
