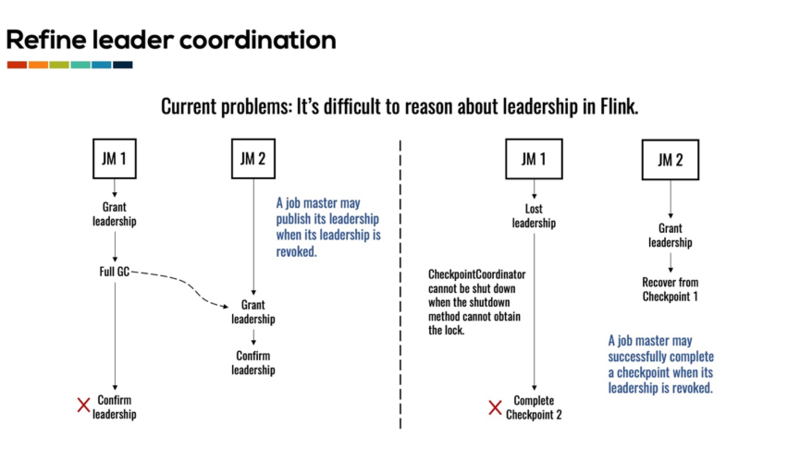
如上图左侧所示,当 JM1 获得 leader 之后,其需要在 Zookeeper 发布其地址以供其他节点来发现自己。但如果在其发布地址之前,JM1 发生了 Full GC,那么集群就可以陷入混乱之中。其长时间的 GC 可能会导致其丢失 leader 以及和 Yarn 之间的心跳连接。此时一个新的 master 节点, JM2, 可能会被 Yarn 拉起。JM2 在获得 leader 之后会将其地址发布在集群中。当如果此时 JM1 从 Full GC 中恢复过来,并继续执行之前的代码,将其地址发布在集群中,那么 JM1 的地址将会覆盖 JM2 的地址导致集群混乱。
另一个由于 leader 选举导致的常见问题是 checkpoint 的并发访问。当一个 master 丢失 leader 节点之后,其需要立即停止其所有正在进行的工作并退出。但是如果此时旧 master 的 Checkpoint Coordinator 正在完成 checkpoint,那么退出方法将无法获取到锁而执行。此时,在已经丢失了 leader 的情况下,旧 master 仍然有机会完成一个新的 checkpoint。而此时,新 master 却会从一个较旧的 checkpoint 进行恢复。目前 Flink 使用了许多 tricky 的方法来保证多个 master 节点对 checkpoint 的并发访问不会导致作业无法从故障中恢复,但这些方法也导致我们目前无法对失败的 checkpoint 进行有效的脏数据清理。
腾讯 Flink 实践:实时计算平台 Oceanus 建设历程
什么时候用transient关键字
不加transient的变量会在生成DAG图的时候初始化。然后序列化后分发到各个节点。
加transient后不会初始化默认值。各个节点收到数据反序列化对象后,通过调用RichFunction里的open函数,其他Flink里的interface也可能有类似的初始化函数。通过这些初始化函数来给transient修饰的变量初始化值。
https://stackoverflow.com/questions/55222822/when-to-use-transient-when-not-to-in-flink
enableObjectReuse
必须要确保下游Function只有一种,或者下游的Function均不会改变对象内部的值。否则可能会有线程安全的问题。
JDK版本
至少1.8_u51
Keytab重命名问题
Flink在提交到Yarn作业的时候会将配置文件里的Keytab在容器里重新命名成krb5.keytab。

若有收获,就点个赞吧
0 人点赞
