组件
新版Flink JobManager包括 Dispatcher、ResourceManager、JobManager三部分。
0x01 ResourceManager
ResourceManager基类下面有四种实现:
- YARN
- Mesos
- Standalone-multi-job (Standalone 模式)
- Self-contained-single-job(Docker/Kubernetes 模式)
ResourceManager核心组件:Slot Manager
对外RPC调用
requestSlot 和 cancelSlotRequest 主要供 JobMaster 进行调用,而 sendSlotReport 和 notifySlotAvailable 则主要供 TaskExecutor 调用。ResourceManager 在接收到上述 RPC 调用后,会通过 SlotManager 完成具体的工作。
YarnResourceManager通过startNewWorker和stopWorker在TM不够时候申请和停止。
Slot Manager
管理和分配Slot
RM会缓存 TaskManager (container) 以便重复利用,并将一段时间未使用的空闲资源归还给集群。
在Yarn模式下,Slot不足SlotManager会通过ResourceActions#allocateResource(ResourceProfile)告知RM,RM可能申请新的TM。
四大功能:Slot注册、请求Slot、取消Slot请求、超时检测。
超时检测
SlotRequest超时检测和TM空闲检测。
TM空闲超时调用ResourceActions#releaseResource()释放。
0x02 Dispatcher
负责接收用户提供的作业,并且负责为这个新提交的作业拉起一个新的 JobManager及相关服务(包括REST endpoint等),在per-job运行模式下,Dispatcher将直接从Container工作目录加载JobGraph文件;在yarn-session运行模式下,Dispatcher将在接收客户端提交的Job(通过BlockServer接收JobGraph文件)
0x03 JobManager
JobManager核心组件:Checkpoint Coordinator、Slot Pool、ExecutionGraph、SlotSharingManager、Scheduler
SlotSharingGroup是软限制、CoLocationGroup是硬限制。
默认情况下SlotSharingGroup全在defalut组中。尽可能让所有subtask在一个Slot里。
CoLocationGroup限制JobVertex同一编号(每个subtask有个编号)的必须在一个Slot中。
CoLocationGroup通过CoLocationConstraint限制Slot共享,用户可以通过API自定义。
JobManager 会随 JobGraph 一起创建,并在作业结束后销毁。JobManager 的构造器可以接受一个 Savepoint 或 Checkpoint 来初始化作业,这为作业的容器化提供了基础。
同样需要关注一下 AllocationID 和 SlotRequestID 的区别:AllocationID 是用来区分物理内存的分配,它总是和 AllocatedSlot 向关联的;而 SlotRequestID 是任务调度执行的时候请求 LogicalSlot,是和 LogicalSlot 关联的。
代码指定共享组:
someStream.filter(...).slotSharingGroup("group1");
Slot管理
PhysicalSlot和LogicSlot
PhysicalSlot实现是AllocatedSlot。
LogicSlot实现是SingleLogicalSlot。
SingleLogicalSlot 实现 PhysicalSlot.Payload接口,所以SingleLogicalSlot可以作为Payload装配到PhysicalSlot上。
SingleLogicalSlot类也有Payload属性,可以装配Execution类(实际就是Subtask)。
AllocationID和SlotRequestID
AllocationID和PhysicalSlot绑定,SlotRequestID和LogicSlot绑定。
TaskSlot
MultiTaskSlot和SingleTaskSlot两种实现。
TaskSlot🌲:
构建树形节点SingTaskSlot是叶子节点,MultiTaskSlot包含SingleTaskSlot。根节点为MultiTaskSlot有SlotContext属性代表PhysicalSlot。🌲中所有subtask都会在一个Slot中运行。区分叶子节点的是AbstractID(JobVertexID或CoLocationGroupID)
MultiTaskSlot作为根节点可以作为Payload装载到PhysicalSlot上。
SlotPool
SlotPool里都是Physical Slot
JobManager 有一个 SlotPool 来暂存 TaskManager 提供给它并被接受的 slot。JobManager 的调度器从这个 SlotPool 获取资源,因此即使 ResourceManager 不可用 JobManager 仍然可以使用已经分配给它的 slot。
当 SlotPool 无法满足一个资源请求时,它会向 ResourceManager 请求新的 slot。这时如果 ResourceManager 不可用,或者 ResourceManager 拒绝了请求,或者请求超时,都会导致 slot 请求失败。
SlotPool 会将未使用的 slot 归还给 ResourceManager。一个 slot 被视为未使用的标准是当作业已经完全处于运行状态时它未被使用。
向RM申请Slot
class SlotPoolImpl implements SlotPool {/** The book-keeping of all allocated slots. *///所有分配给当前 JobManager 的 slotsprivate final AllocatedSlots allocatedSlots;/** The book-keeping of all available slots. *///所有可用的 slots(已经分配给该 JobManager,但还没有装载 payload)private final AvailableSlots availableSlots;/** All pending requests waiting for slots. *///所有处于等待状态的slot request(已经发送请求给 ResourceManager)private final DualKeyMap<SlotRequestId, AllocationID, PendingRequest> pendingRequests;/** The requests that are waiting for the resource manager to be connected. *///处于等待状态的 slot request (还没有发送请求给 ResourceManager,此时没有和 ResourceManager 建立连接)private final HashMap<SlotRequestId, PendingRequest> waitingForResourceManager;}
CheckpointCoordinator
在不开启 Checkpoint 的情况下,Flink 依然会初始化 CheckpointCoordinator,并且在 HDFS 上创建对应的 Checkpoint 目录,目的是支持Savepoint。
ScheduleMode
流是Eager模式,批是LAZY_FROM_SOURCES模式。
/*** The ScheduleMode decides how tasks of an execution graph are started.*/public enum ScheduleMode {/** Schedule tasks lazily from the sources. Downstream tasks are started once their input data are ready */LAZY_FROM_SOURCES(true),/*** Same as LAZY_FROM_SOURCES just with the difference that it uses batch slot requests which support the* execution of jobs with fewer slots than requested. However, the user needs to make sure that the job* does not contain any pipelined shuffles (every pipelined region can be executed with a single slot).*/LAZY_FROM_SOURCES_WITH_BATCH_SLOT_REQUEST(true),/** Schedules all tasks immediately. */EAGER(false);private final boolean allowLazyDeployment;ScheduleMode(boolean allowLazyDeployment) {this.allowLazyDeployment = allowLazyDeployment;}/*** Returns whether we are allowed to deploy consumers lazily.*/public boolean allowLazyDeployment() {return allowLazyDeployment;}}
0x04 WebServer
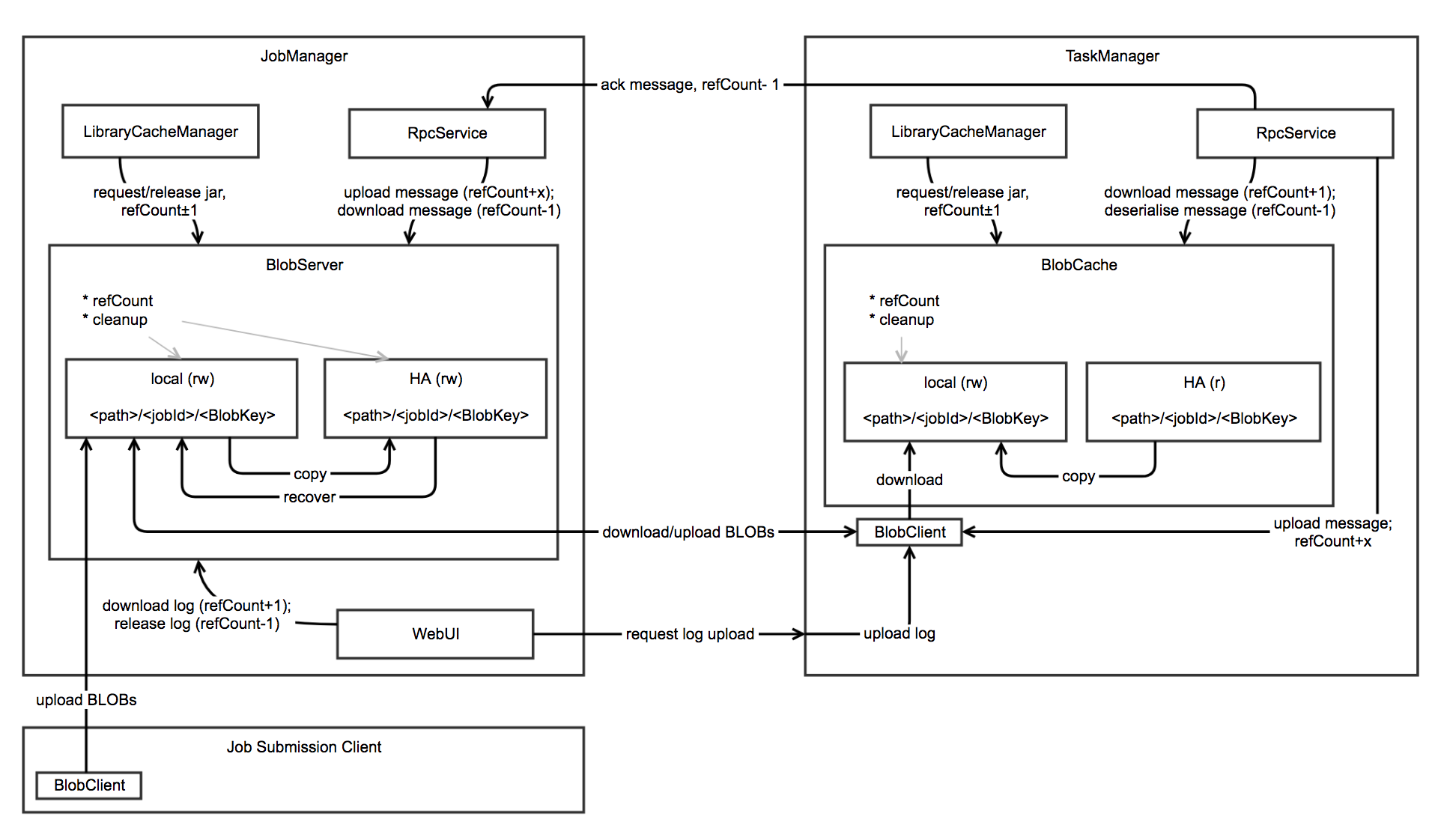
BolbServer
线程,管理二进制大文件。
存三种类型文件:jar包、高负荷RPC消息、TM日志文件。
两类:PERMANENT_BLOB(和job生命周期一致,可恢复,会上传HDFS)、TRANSIENT_BLOB(生命周期用户自行管理,不可恢复,不上传HDFS)
BlobStore:一个interface。HDFS、S3、FTP等实现
${high-availability.storageDir}/${applicationid}/blob/job${jobid}
${high-availability.storageDir}/${application_id}/blob/job${job_id}/${blob_key}
blob.storage.directory 默认 java.io.tmpdir(/tmp)Blob本地存储目录
BlobClient
优先使用本地文件;再从HDFS中获取;最后才尝试从BlobServer下载。
HA
ZK和HDFS存储数据以便主备切换,JobGraph要存起来。
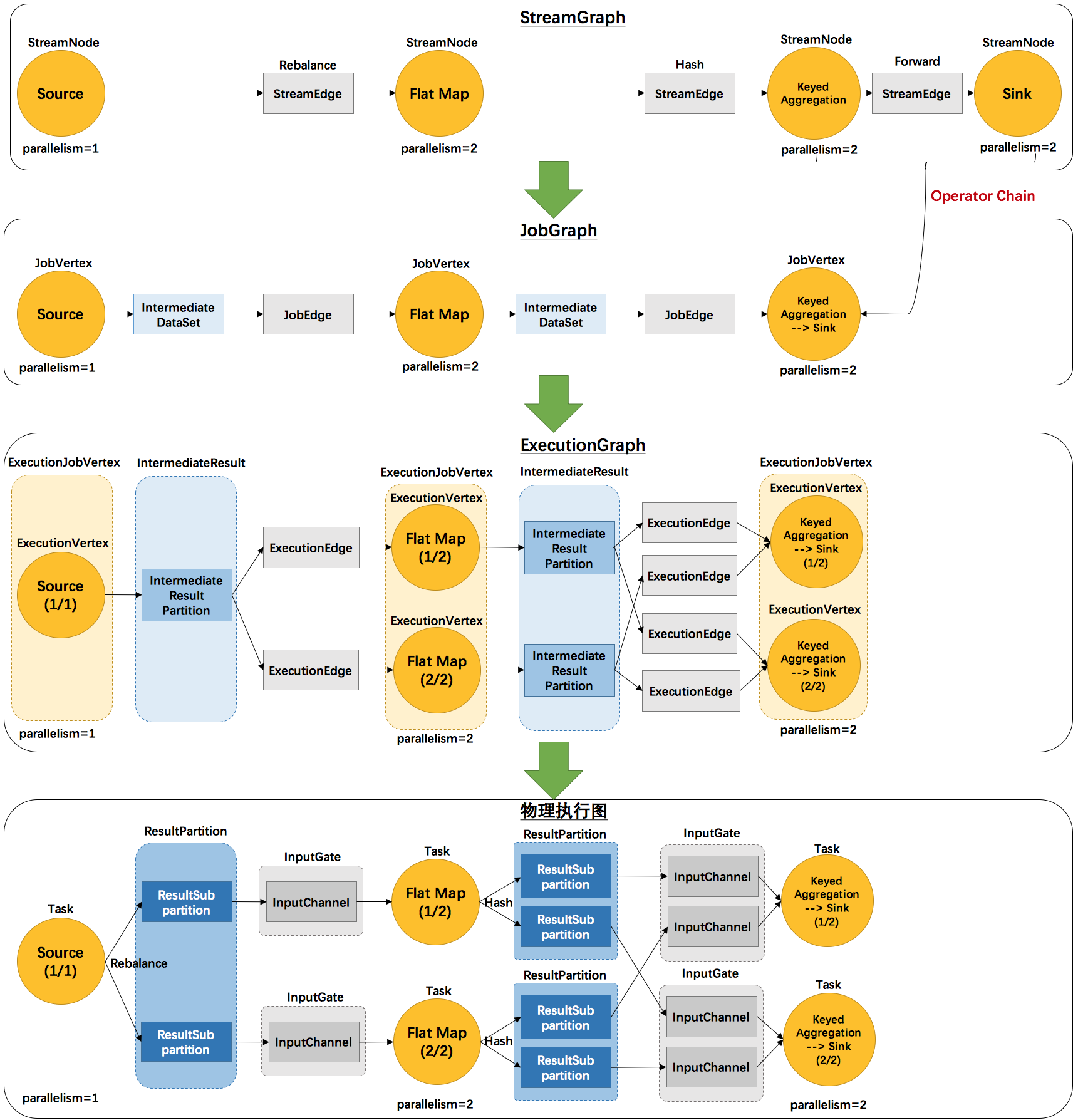
Graph
StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
第⼀层:Program -> StreamGraph
Operator节点生成Transform,组成的图。
第⼆层:StreamGraph -> JobGraph
operator chain到一起,生成用于CheckPoint的JobVertexID
Task组成的图。
JobGraph在Client端生成提交到集群。
operator chain条件:
- 上下游的并行度一致
- 下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
- 上下游节点都在同一个 slot group 中
- 下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
- 上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
- 两个节点间数据分区方式是 forward
- 用户没有禁用 chain
第三层:JobGraph -> ExecutionGraph
subtask组成的图。
ExecutionGraph开始考虑并发。JobManager创建。调度层面最重要的数据结构。
第四层:ExecutionGraph -> 物理执⾏计划
物理执⾏计划是ExecutionGraph被JobManager调度后,装配到Slot后,并不是真正的图。
ResultSubpartition由下游并行度决定,InputChannel和ResultSubpartition一一相连
ResultPartition、InputGate
Off-heap Memory -> NetworkBufferPool -> LocalBufferPool -> ResultSubPartition
NetworkBufferPool由TaskManager共享
参考

若有收获,就点个赞吧
0 人点赞
