作者丨Ivan Yan
专栏| 我的机器学习笔记
https://zhuanlan.zhihu.com/p/82129871
简介
这两年BERT太火了,但是BERT模型是真的大,计算起来太慢了。知识蒸馏可以对模型进行压缩,迁移到小的模型。找了下是否有关于BERT的知识蒸馏的论文,然后看到了下面这篇论文,“Distilling Task-Specific Knowledge from BERT into Simple Neural Networks”。做法很简单,就是用知识蒸馏的方法,把BERT模型迁移到BiLSTM模型上。
链接:https://arxiv.org/abs/1903.12136
模型
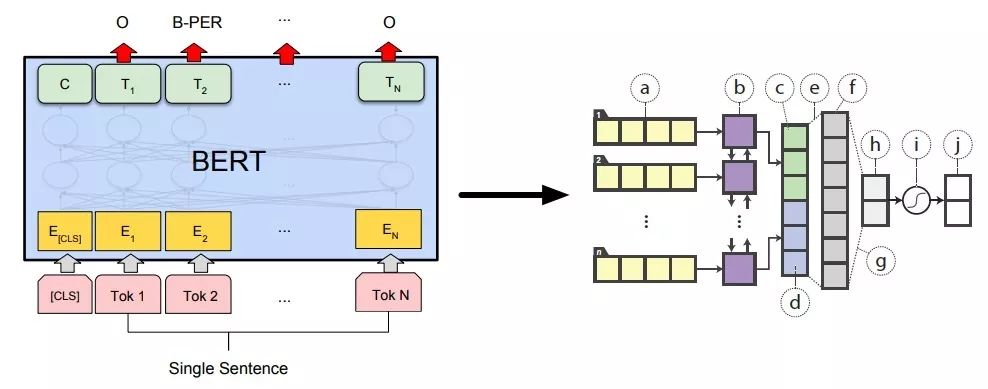
这篇文章的teacher网络是BERT模型。BERT模型的输入可以是一句话,做分类;或者两句话,做匹配;因此,针对这两种情况文章提出了2个模型,作为student网络。如下图所示:
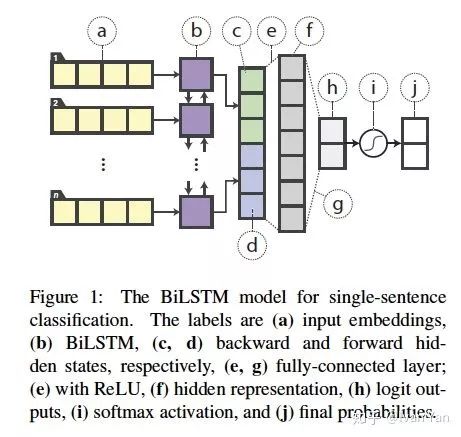
这个模型就是传统的biLSTM模型,输入词向量到biLSTM层,然后取最后一步的hidden states喂给全连接层,接softmax做分类。
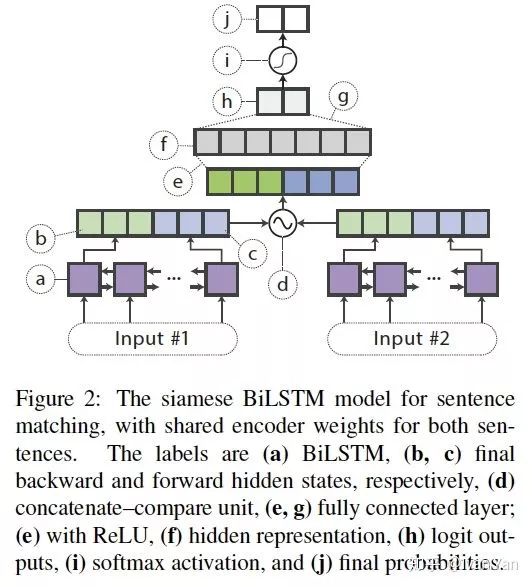
对于文本匹配,文章作者用的模型也很简单,并没有使用特别复杂的文本匹配模型作为student网络。取两个句子最后一步的biLSTM的hidden states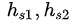 ,然后拼接成
,然后拼接成 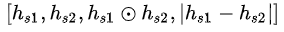
作为全连接层的输入,然后经过softmax得到匹配结果。  表示点乘。
表示点乘。
Distillation目标函数
模型已经介绍完了,下面介绍如何将BERT模型的知识迁移到biLSTM中。这里直接使用了teacher网络logits的输出,来作为student网络的distillation objective,而不是使用论文 “Distilling the Knowledge in a Neural Network”中的soft targets。具体公式如下所示:
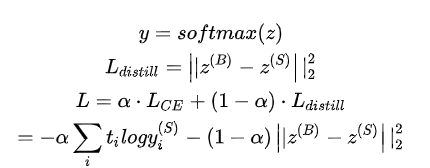
这里  和
和 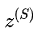 是teacher和student网络的logits,使用MSE(mean-squared-error)来作为
是teacher和student网络的logits,使用MSE(mean-squared-error)来作为 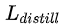
的损失函数。t是真实标签。
在distillation过程中,小数据集可能无法完全的表达teacher网络的知识。因此,文中提出了三种数据增强的方法来人为的扩充数据集,防止过拟合。
- Masking 使用[mask]标签来随机替换一个单词,例如“I love the comedy”替换为” I [mask] the comedy”。
- POS-guided word replacement 将一个单词替换为相同POS标签的随机单词。例如,“What do pigs eat?”替换为”How do pigs eat?”。
- n-gram sampling 随机采用n-gram,n从1到5,并丢弃其它单词。
实验结果
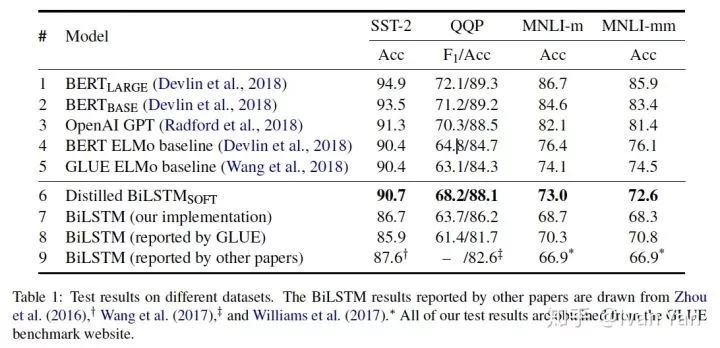
上表显示了模型的结果,可以看出加入知识蒸馏之后,模型的结果确实比单纯地使用BiLSTM的结果好,在SST-2和QQP上居然比ELMo要好。可以确定的是这样做确实可以将BERT中的知识迁移到BiLSTM中。但是BiLSTM模型的表达能力比BERT弱很多。显然有些知识是无法从BERT中迁移到BiLSTM中的,例如两个句子之间的co-attention信息和长距离依赖信息。
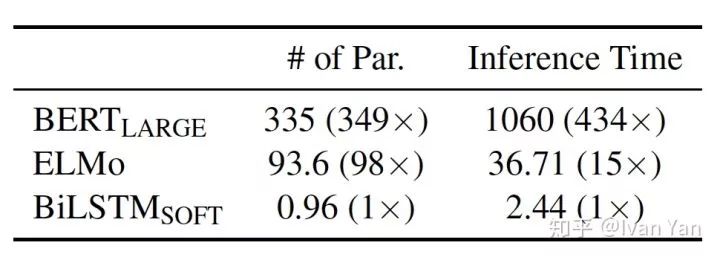
上图显示了网络的inference时间,可以看到相比于BERT参数减少了98倍,速度加快了434倍。
这篇文章展示了如何将BERT的知识迁移到其它网络中(BiLSTM)。对与离线的数据处理,由于时间要求不高,现在一般会采用BERT模型,或者BERT的改进模型,因为效果确实比其它模型有很大的提升,基本可以无脑上BERT。对于线上的任务,BERT的inference确实太慢了。这篇文章的思路可以借鉴一下,实现也很简单,就是加一个
损失。这篇文章的效果,我自己还没试过,具体效果是否有文章这么好,还不知道。但对没有预训练的网络,应该会有一定的效果提升。

若有收获,就点个赞吧
0 人点赞
