作者丨Ivan Yan
专栏| 我的机器学习笔记
https://zhuanlan.zhihu.com/p/81467832
最新在看知识蒸馏的文章,主要是现在的深度学习模型越来越大,例如BERT。在线下处理数据,对时间要求不高的话,还能接受,能跑完就好。但是线上运行,对延迟要求高的话,像BERT这样的大模型,就很难满足要求。因此,就找了找模型压缩的方法。
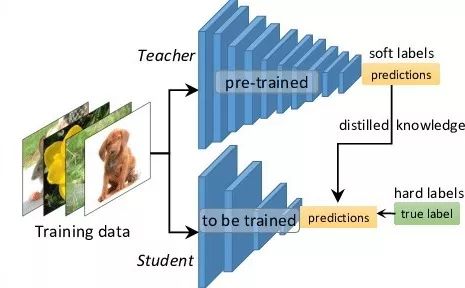
知识蒸馏被广泛的用于模型压缩和迁移学习当中。开山之作应该是”Distilling the Knowledge in a Neural Network“。这篇文章中,作者的motivation是找到一种方法,把多个模型的知识提炼给单个模型。
文章的标题是Distilling the Knowledge in a Neural Network,那么说明是神经网络的知识呢?一般认为模型的参数保留了模型学到的知识,因此最常见的迁移学习的方式就是在一个大的数据集上先做预训练,然后使用预训练得到的参数在一个小的数据集上做微调(两个数据集往往领域不同或者任务不同)。例如先在Imagenet上做预训练,然后在COCO数据集上做检测。在这篇论文中,作者认为可以将模型看成是黑盒子,针对特定模型的输入,得到的输出结果就是知识。因此,我们可以先训练好一个teacher网络,然后将teacher的网络的输出结果 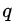 作为student网络的目标,训练student网络,使得student网络的结果
作为student网络的目标,训练student网络,使得student网络的结果 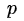 接近
接近 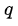 ,因此,我们可以将损失函数写成
,因此,我们可以将损失函数写成
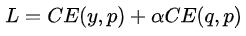
这里CE是交叉熵(Cross Entropy),y是真实标签的onehot编码,q是teacher网络的输出结果,p是student网络的输出结果。
但是,直接使用teacher网络的softmax的输出结果 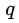 ,可能不大合适。因此,一个网络训练好之后,对于正确的答案会有一个很高的置信度。例如,在MNIST数据中,对于某个2的输入,对于2的预测概率会很高,而对于2类似的数字,例如3和7的预测概率为
,可能不大合适。因此,一个网络训练好之后,对于正确的答案会有一个很高的置信度。例如,在MNIST数据中,对于某个2的输入,对于2的预测概率会很高,而对于2类似的数字,例如3和7的预测概率为 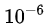 和
和 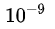 。这样的话,teacher网络学到数据的相似信息(例如数字2和3,7很类似)很难传达给student网络。由于它们的概率值接近0。因此,文章提出了soft target,公式如下所示:
。这样的话,teacher网络学到数据的相似信息(例如数字2和3,7很类似)很难传达给student网络。由于它们的概率值接近0。因此,文章提出了soft target,公式如下所示:
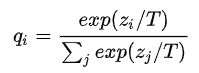
这里 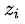 是神经网络softmax前的输出logit。如果将T取1,这个公式就是softmax,根据logit输出各个类别的概率。如果T接近于0,则最大的值会越近1,其它值会接近0,近似于onehot编码。如果T越大,则输出的结果的分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用。如果T等于无穷,就是一个均匀分布。
是神经网络softmax前的输出logit。如果将T取1,这个公式就是softmax,根据logit输出各个类别的概率。如果T接近于0,则最大的值会越近1,其它值会接近0,近似于onehot编码。如果T越大,则输出的结果的分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用。如果T等于无穷,就是一个均匀分布。
最终文章根据上述的损失函数对网络进行训练。
- 在MNIST这个数据集上,先使用大的网络进行训练,测试集错误67个,小网络训练,测试集错误146个。加入soft targets到目标函数中,相当于正则项,测试集的错误降低到了74个。这证明了teacher网络确实把知识转移到了student网络,使得结果变好了。
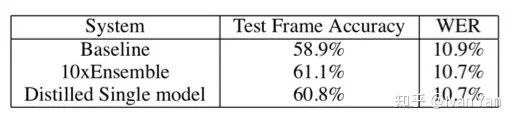
- 第二个实验是在speech recognition领域,使用不同的参数训练了10个DNN,对这10个模型的预测结果求平均作为emsemble的结果,相比于单个模型有一定的提升。然后将这10个模型作为teacher网络,训练student网络。得到的Distilled Single model相比于直接的单个网络,也有一定的提升,结果见下表:
结论
知识蒸馏,可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。知识蒸馏,可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能;也可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近emsemble的结果。

若有收获,就点个赞吧
0 人点赞
