剪辑自:https://mp.weixin.qq.com/s/frW1O4SrTgaOgCXM5wUckA
机器学习中,有一个称为 “No Free Lunch” 的定理。
简单来说,与监督学习特别相关的这个定理,它指出没有万能算法,就是用一个算法能很好地解决每个问题。
例如,不能说神经网络总是比决策树更好,反之亦然。有许多因素在起作用,例如数据集的大小和结构。
那么,如果我遇到一个问题,首先应该尝试多种不同的算法来解决问题,同时使用保留的 “测试集” 数据评估绩效并选择最优的那个算法,然后 GitHub 搜索最优代码修改哈哈哈哈。
当然,如果需要打扫房屋,可以使用吸尘器、扫帚或拖把。你不会用铲子吧?
所以尝试的算法必须适合要解决的问题,这才是选择正确的机器学习任务的来源。

基本原则
有一个通用原则是所有用于预测建模的受监督机器学习算法的基础。
机器学习算法被描述为学习目标函数(f),该函数最好将输入变量(X)映射到输出变量(Y):Y = f(X)
这是一个简单的学习任务,我们想在给定新的输入变量(X)的情况下,对(Y)进行预测。但是不知道函数(f)。
机器学习的最常见类型是学习映射 Y = f(X)可以对新 X 预测到 Y,目标是尽可能进行最准确的预测。
对于初入机器学习领域,没有机器学习基础知识的新手,我会对常用的十大机器学习算法做简单介绍。
1-线性回归
线性回归可能是统计和机器学习中最著名和最易理解的算法之一。
主要与最小化模型的误差或做出尽可能准确的预测有关,但以可解释性为代价。我们将从许多不同领域(包括统计数据)中学习。
线性回归的表示法是一个方程,该方程通过找到称为系数(B),来描述输入变量(x)与输出变量(y)之间关系的线。
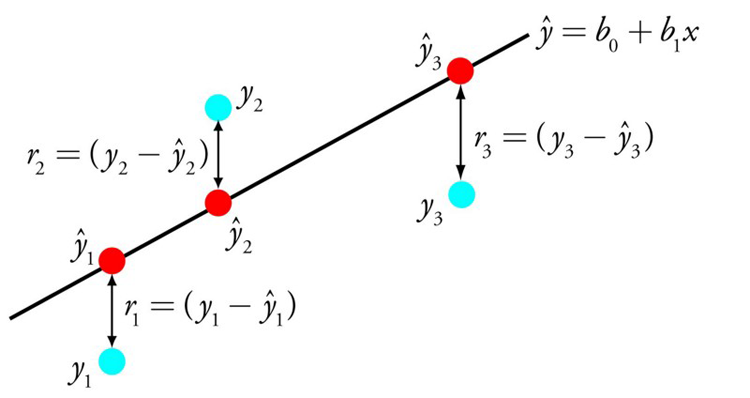
例如:y = B0 + B1 * x ,这不是一次函数吗?哈哈
给定输入 x,我们将预测 y,线性回归学习算法的目标是找到系数 B0 和 B1 的值, 例如用于普通最小二乘法和梯度下降优化的线性代数解。
2-LOGISTIC回归
逻辑回归是机器学习从统计领域 “借” 的另一种技术。它是二分类问题(具有两个类值的问题)的首选方法。
Logistic 回归类似于线性回归,因为目标是找到权重每个输入变量的系数的值。与线性回归不同,输出的预测使用称为对数函数的非线性函数进行变换。
逻辑函数看起来像一个大 S,它将任何值转换为 0 到 1 的范围。因为我们可以将规则应用于逻辑函数的输出为 0 和 1(例如,如果 IF 小于 0.5,则输出 1)并预测类别值。
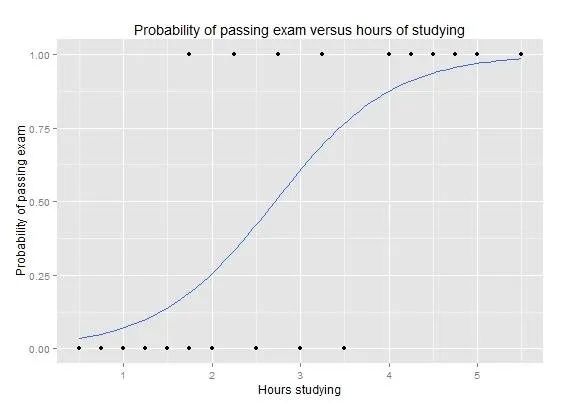
与线性回归一样,当去除与输出变量无关的属性以及相关的属性时,逻辑回归的效果更好。这是一个快速学习二进制分类问题并有效的模型
3-线性判别分析
Logistic 回归是传统上仅限于两类分类问题的分类算法。如果是多分类,则线性判别分析算法(LDA)就是很重要的算法了。
LDA 的表示非常简单,它由数据的统计属性组成,这些属性是针对每个类别计算的。对于单个输入变量,这包括:
- 每个类别的平均值。
- 计算所有类别的方差
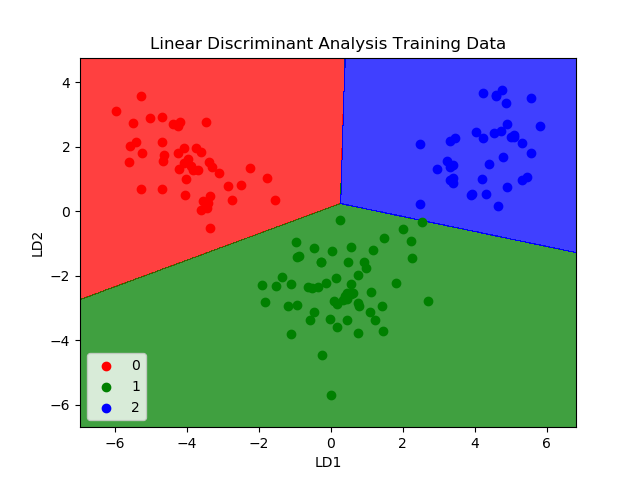
通过为每个类别计算一个区分值并为具有最大值的类别进行预测来进行预测。
该算法的前提是:数据具有高斯分布(钟形曲线),因此最好在操作之前从数据中删除异常值。
4-分类和回归树
决策树是用于预测建模机器学习的重要算法类型。
决策树模型的表示形式是二叉树。这是来自算法和数据结构的二叉树,没有什么花哨的。每个节点代表一个输入变量(x)和该变量的分割点(假设变量是数字)。
树的叶节点包含用于进行预测的输出变量(y)。通过遍历树的拆分直到到达叶节点并在该叶节点输出类值来进行预测。
树学习速度很快,做出预测的速度也非常快。它们对于许多问题通常也很准确,不需要为数据做任何特殊预处理。
5-朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种简单但功能强大的预测建模算法。
该模型由两种类型的概率组成,可以直接从您的训练数据中计算出:
1)每个类别的概率;
2)给定每个 x 值的每个类别的条件概率。
开始计算,概率模型可用于使用贝叶斯定理对新数据进行预测。当你的数据是实值时,通常会假设一个高斯分布(钟形曲线),以便可以轻松地估计这些概率。
朴素贝叶斯之所以被称为朴素,是因为它假定每个输入变量都是独立的。这是一个很强的假设,对于真实数据来说是不现实的,尽管如此,该技术对于大量复杂问题非常有效。
6 - K近邻
KNN 算法非常简单且非常有效。KNN 的模型表示是整个训练数据集。简单吧?
通过搜索整个训练集中的 K 个最相似实例并汇总这 K 个实例的输出变量,可以对新数据点进行预测。
对于回归问题,这可能是平均输出变量,对于分类问题,这可能是最常见的类别值。
诀窍在于如何确定数据实例之间的相似性。如果您的属性都具有相同的比例(例如,都是距离数据),最简单的方法是使用欧几里得距离,您可以根据每个输入变量之间的差异直接计算一个数字。
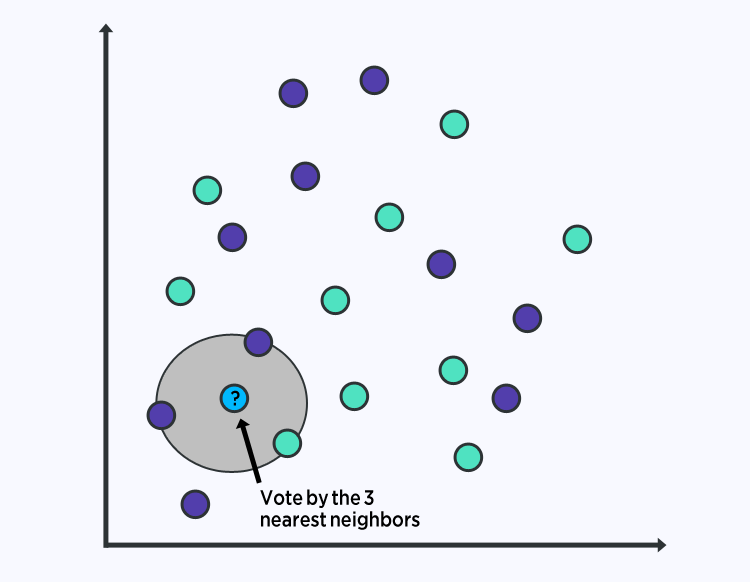
KNN 可能需要大量内存或空间来存储所有数据,因为它把所有数据都遍历了。您还可以随着时间的训练数据,以保持预测的准确性。
距离或紧密度的概念可能会分解为非常高的维度(许多输入变量),这可能会对问题的算法性能产生负面影响。所以对于数据的输入就至关重要。
7- 矢量化学习
K 最近的缺点是需要整个训练数据集。学习向量量化算法(简称 LVQ)是一种人工神经网络算法,可让选择要需要的训练实例数量。
LVQ 的表示形式是向量的集合。这些是在最开始开始时随机选择的,适用于在学习算法的多次迭代中最好地总结训练数据集。
学习之后,可以像使用 K 近邻一样,使用数据进行预测。通过计算每个向量与新数据实例之间的距离,可以找到最相似的数据向量(最佳匹配的向量)。然后返回最佳匹配的类值作为预测。记得数据归一化,获得的效果更好。
8-支持向量机
支持向量机可能是最受欢迎的机器学习算法之一。
超平面是分割输入变量空间的线。
在 SVM 中,选择一个超平面以按类别(类别 0 或类别 1)最好地分隔输入变量空间中的点。
在二维图中,您可以将其可视化为一条线,并假设所有输入点都可以被这条线完全隔开。SVM 学习算法找到超平面对类进行最佳分离的系数。
超平面和最近的数据点之间的距离称为边距。可以将这两个类别分开的最佳或最佳超平面是边距最大的线。
仅这些点与定义超平面和分类器的构造有关。这些点称为支持向量。
在实践中,使用优化算法来找到使余量最大化的系数的值。
SVM 可能是功能最强大的即用型分类器之一,使用频率很高。
9-BAGGING和随机森林
随机森林是最流行,功能最强大的机器学习算法之一。这是一种称为 Bootstrap 聚类或 BAGGING 的集成机器学习算法。
您需要对数据进行大量采样,计算平均值,然后对所有平均值取平均值,以便更好地估算真实平均值。
在 bagging 中,使用相同的方法,但用于估计整个统计模型(最常见的是决策树)。获取训练数据的多个样本,然后为每个数据样本构建模型。当你需要对新数据进行预测时,每个模型都将进行预测,并对预测取平均值以对真实输出值进行更好的估计。
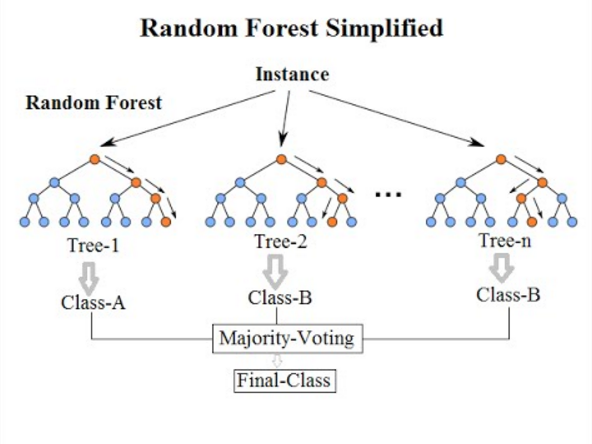
随机森林是对这种方法的一种调整,在该方法中将创建决策树,不是选择最佳的拆分点。
因此,为每个数据样本创建的模型与原先的模型相比,差异更大。将他们的预测结合起来可以更好地估计真实的基础输出值。
10-BOOSTING和ADABOOST

Boosting 是一种集成技术,尝试从多个弱分类器创建强分类器。这是通过从训练数据构建模型,然后创建第二个模型来尝试纠正第一个模型中的错误来完成的。添加模型,直到完美预测训练集或添加最大数量的模型为止。
AdaBoost 是为二进制分类开发的第一个真正成功的增强算法。这是了解增强的最佳起点。现代的增强方法基于 AdaBoost,最著名的是随机梯度增强机.
AdaBoost 与决策树一起使用。
创建第一棵树后,将在每个训练实例上使用该树的性能来加权要创建的下一棵树应注意每个训练实例的关注程度。
难以预测的训练数据的权重更高,而易于预测的实例的权重更低。依次创建模型,每个模型都会更新训练实例上的权重,这些权重会影响序列中下一棵树执行的学习。构建完所有树之后,对新数据进行预测,并根据训练数据的准确性对每棵树的性能进行加权。
由于该算法在纠正错误方面投入了很多精力,因此删除异常值和数据去噪非常重要。

若有收获,就点个赞吧
0 人点赞
