剪辑自:https://zhuanlan.zhihu.com/p/44042528
本文翻译自GitHub博客上的原创文章,结尾有原文链接。文章没有晦涩的数学公式,而是通过实例一步一步讲解CRF的实现过程,是入门CRF非常非常合适的资料。
概述
该文章系列包括以下内容:
- 概念介绍 — 基于 BiLSTM-CRF模型中的命名实体识别任务中的CRF层解释
- 例子详解 — 用一个玩具的例子详细解释CRF是如何工作的
- Chainer实现 — 用基于Chainer包的代码实现CRF层
背景知识
你唯一需要了解的是什么叫命名实体识别。如果你不了解神经网络,CRF以及其他相关知识也没有关系,我会用通俗易懂的语言来解释清楚。
**
简介
在命名实体识别领域,基于神经网络的实现方法是非常流行和常用的。举个例子,该文讲述的用词嵌入和字嵌入的BiLSTM-CRF模型就是其中一种。我将以该模型为例解释CRF层的工作原理。
如果你不知道BiLSTM 和 CRF的实现细节,只需要记住他们是命名实体识别模型中两个不同的层。
**
开始之前
我们规定在数据集中有两类实体,人名和组织机构名称。所以,其实在我们的数据集中总共有5类标签:
- B-Person (人名的开始部分)
- I- Person (人名的中间部分)
- B-Organization (组织机构的开始部分)
- I-Organization (组织机构的中间部分)
- O (非实体信息)
此外,x 是包含了5个单词的一句话(w0,w1,w2,w3,w4)。还有,在句子x中[w0,w1]是人名,[w3]是组织机构名称,其他都是“O”。
BiLSTM-CRF 模型
先来简要的介绍一下该模型。
如下图所示:
首先,句中的每个单词是一条包含词嵌入和字嵌入的词向量,词嵌入通常是事先训练好的,字嵌入则是随机初始化的。所有的嵌入都会随着训练的迭代过程被调整。
其次,BiLSTM-CRF的输入是词嵌入向量,输出是每个单词对应的预测标签。
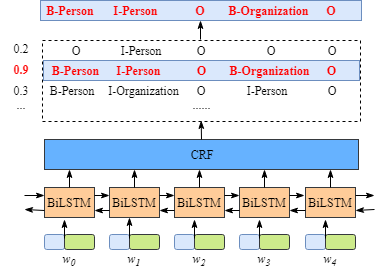
尽管不需要了解BiLSTM的实现细节,但为了更好的理解CRF层,我们还是需要知道一下BiLSTM的输出到底是什么意思。
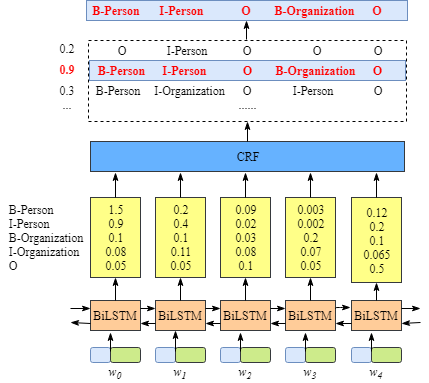
如上图所示,BiLSTM层的输入表示该单词对应各个类别的分数。如W0,BiLSTM节点的输出是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) and 0.05 (O)。这些分数将会是CRF层的输入。
所有的经BiLSTM层输出的分数将作为CRF层的输入,类别序列中分数最高的类别就是我们预测的最终结果。
1. 如果没有CRF层会是什么样
正如你所发现的,即使没有CRF层,我们照样可以训练一个基于BiLSTM的命名实体识别模型,如下图所示。
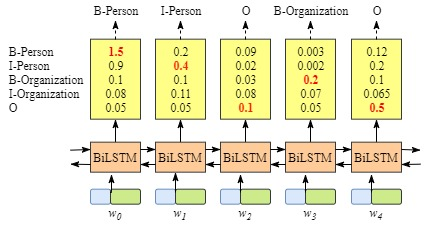
因为BiLSTM模型的结果是单词对应各类别的分数,我们可以选择分数最高的类别作为预测结果。如W0,“B-Person”的分数最高(1.5),那么我们可以选定“B-Person”作为预测结果。同样的,w1是“I-Person”, w2是“O”,w3是 “B-Organization” ,w4是 “O”。
尽管我们在该例子中得到了正确的结果,但实际情况并不总是这样。来看下面的例子。

显然,这次的分类结果并不准确。
2. CRF层可以学习到句子的约束条件
CRF层可以加入一些约束来保证最终预测结果是有效的。这些约束可以在训练数据时被CRF层自动学习得到。
可能的约束条件有:
- 句子的开头应该是“B-”或“O”,而不是“I-”。
- “B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Organization”则是错误的。
- “O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
有了这些有用的约束,错误的预测序列将会大大减少。
3. CRF 层
CRF层中的损失函数包括两种类型的分数,而理解这两类分数的计算是理解CRF的关键。
- Emission score
第一个类型的分数是发射分数(状态分数)。这些状态分数来自BiLSTM层的输出。如下图所示,w0被预测为B-Person的分数是1.5.
为方便起见,我们给每个类别一个索引,如下表所示:

Xiyj代表状态分数,i是单词的位置索引,yj是类别的索引。根据上表,
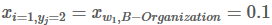
表示单词w1被预测为B−Organization的分数是0.1。
- 转移分数
我们用tyiyj来表示转移分数。例如,tB−Person,I−Person=0.9表示从类别B−Person→I−Person的分数是0.9。因此,我们有一个所有类别间的转移分数矩阵。
为了使转移分数矩阵更具鲁棒性,我们加上START 和 END两类标签。START代表一个句子的开始(不是句子的第一个单词),END代表一个句子的结束。
下表是加上START和END标签的转移分数矩阵。
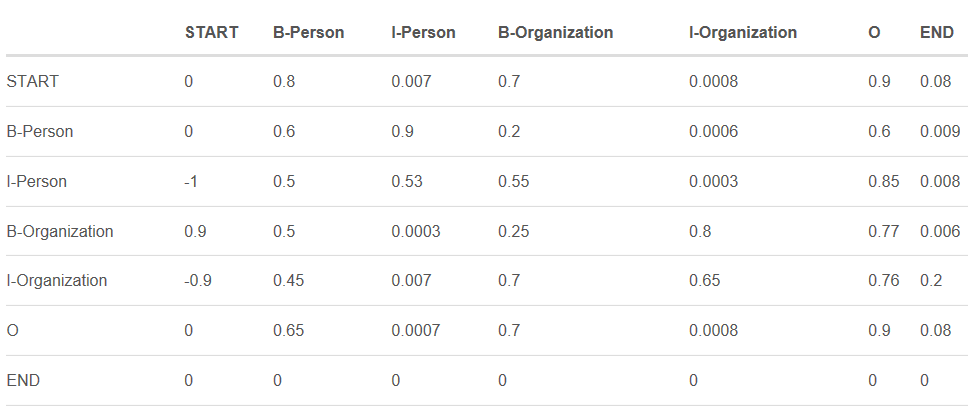
如上表格所示,转移矩阵已经学习到一些有用的约束条件:
- 句子的第一个单词应该是“B-” 或 “O”,而不是“I”。(从“START”->“I-Person 或 I-Organization”的转移分数很低)
- “B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Organization”则是错误的。(“B-Organization” -> “I-Person”的分数很低)
- “O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
要怎样得到这个转移矩阵呢?
实际上,转移矩阵是BiLSTM-CRF模型的一个参数。在训练模型之前,你可以随机初始化转移矩阵的分数。这些分数将随着训练的迭代过程被更新,换句话说,CRF层可以自己学到这些约束条件。
4. CRF损失函数
CRF损失函数由两部分组成,真实路径的分数和所有路径的总分数。真实路径的分数应该是所有路径中分数最高的。
例如,我们的数据集中有如下几种类别:

一个包含5个单词的句子,可能的类别序列如下:
- START B-Person B-Person B-Person B-Person B-Person END
- START B-Person I-Person B-Person B-Person B-Person END
- …..
- 10. START B-Person I-Person O B-Organization O END
- N. O O O O O O O
每种可能的路径的分数为Pi,共有N条路径,则路径的总分是
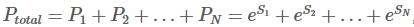 ,e是常数e。
,e是常数e。
如果第十条路径是真实路径,也就是说第十条是正确预测结果,那么第十条路径的分数应该是所有可能路径里得分最高的。
根据如下损失函数,在训练过程中,BiLSTM-CRF模型的参数值将随着训练过程的迭代不断更新,使得真实路径所占的比值越来越大。
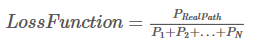
现在的问题是:
- 怎么定义路径的分数?
- 怎么计算所有路径的总分?
- 当计算所有路径总分时,是否需要列举出所有可能的路径?(答案是不需要)
- 真实路径分数
计算真实路径分数,eSi,是非常容易的。
我们先集中注意力来计算Si
以“START B-Person I-Person O B-Organization O END”这条真实路径来说:
句子中有5个单词,w1,w2,w3,w4,w5
加上START和END 在句子的开始位置和结束位置,记为,w0,w6
Si = EmissionScore + TransitionScore
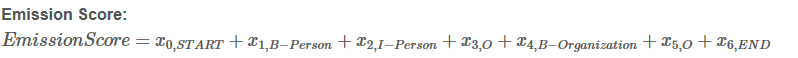
这些分数来自BiLSTM层的输出,至于x0,START 和x6,END ,则设为0。
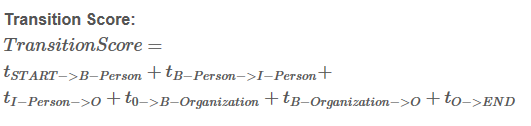
这些分数来自于CRF层,将这两类分数加和即可得到Si 和 路径分数eSi
所有路径的总分
如何计算所有路径的总分呢?我们将以一个玩具的例子详细讲解。
这部分是最重要的并且也是比较难的,但不用担心,我将用玩具的例子尽可能简单的讲清楚里面的细节。
Step 1
我们定义的损失函数如下:**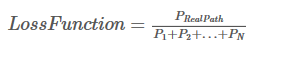
现在我们把它变成对数损失函数: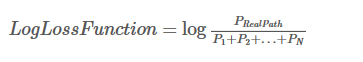
由于我们的训练目标通常是最小化损失函数,所以我们加上负号:
前面我们已经很清楚如何计算真实路径得分,现在我们需要找到一个方法去计算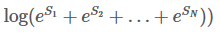
Step 2:回忆一下状态分数 和 转移分数
为了简化问题,我们假定我们的句子只有3个单词组成:**
X = [w0, w1 ,w2]
另外,我们只有两个类别:
LabelSet = {l1, l2}
状态分数如下:
转移矩阵如下: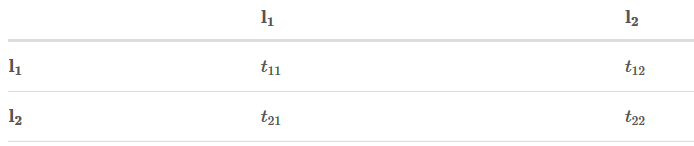
Step 3:开始奋斗!(纸和笔准备好!)
记住:我们的目标是:
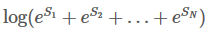
整个过程是一个分数的积聚过程。它的实现思想有点像动态规划。首先,w0所有路径的总分先被计算出来,然后,我们计算w0 -> w1的所有路径的得分,最后计算w0 -> w1 -> w2的所有路径的得分,也就是我们需要的结果。
接下来,你会看到两个变量:obs和 previous。Previous存储了之前步骤的结果,obs代表当前单词所带的信息。
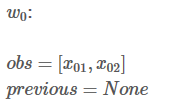
如果我们的句子只有一个单词,我们就没有之前步骤的结果,所以Previous 是空。我们只能观测到状态分数 obs =【x01,x02】
W0 的所有路径总分就是: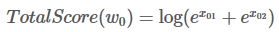
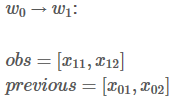
(请集中注意)

你可能疑惑为啥要扩展previous 和 obs 矩阵呢?因为这样操作可以是接下来的计算相当高效,你很快就能意会到这点。

实际上,第二次迭代过程也就完成了。
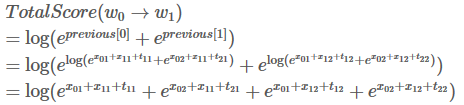
发现了吗,这其实就是我们的目标,
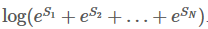
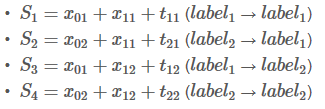
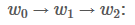
读到这边,差不多就大功告成了。这一步,我们再重复一次之前的步骤。
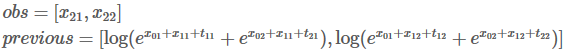

跟上一步骤一样。我们用新的previous计算总分: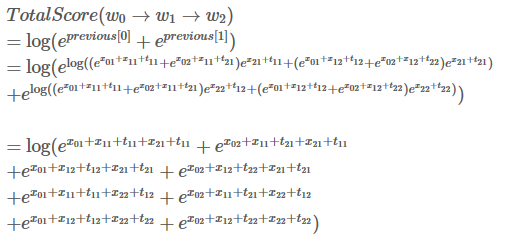
完结,撒花!
我们最终得到了我们的目标,
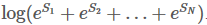
,我们的句子中共有3个单词和两个类别,所以共有8条路径。
对句子的单词词性做预测
在之前章节我们学习了BiLSTM-CRF模型的基本结构和CRF的损失函数。现在你可以用各种开源框架搭建你自己的BiLSTM-CRF模型(Keras, Chainer, TensorFlow等)。用这些框架最爽的事情就是你不用自己实现反向传播这个过程,并且有的框架已经实现CRF层,这样只需要添加一行代码就能在你的模型中实现CRF过程。
本章我们会探索如何用我们训练好的模型去预测一个句子每个单词的词性。
Step 1:BiLSTM-CRF模型得到的发射分数和转移分数
假定我们的句子共3个单词组成:
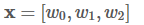
并且,我们已经从我们的模型中得到了发射分数和转移分数,如下:
转移矩阵: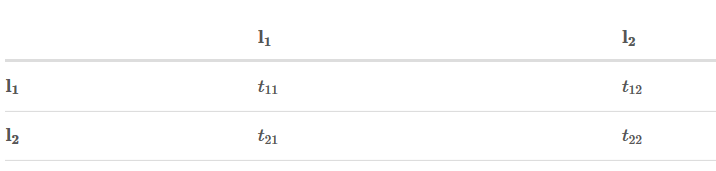
Step 2:开始预测
如果你熟悉Viterbi算法,理解这一步的知识点将会非常容易。当然,如果你不熟悉也无所谓,整个预测过程和之前求所有路径总分的过程非常类似。我将逐步解释清楚,我们先从左到右的顺序来运行预测算法。
你将会看到两类变量:obs 和 previous。Previous存储了上一个步骤的最终结果,obs代表当前单词包含的信息(发射分数)。
Alpha0 是历史最佳的分数 ,alpha1 是最佳分数所对应的类别索引。这两类变量的详细信息待会会做说明。先来看下面的图片:你可以把这两类变量当做狗狗去森林里玩耍时在路上做的标记,这些标记可以帮助狗狗找到回家的路。
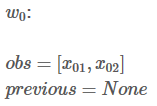
现在,我们来观测第一个单词W0,很显然,W0所对应的最佳预测类别是非常容易知道的。比如,如果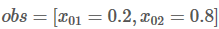 , 显然,最佳预测结果是l2。
, 显然,最佳预测结果是l2。
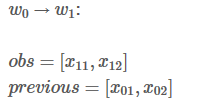

看到这里,你可能好奇这跟之前求所有路径分数的算法没什么区别,别急,你马上就会看到不同之处啦!
在下一次迭代前更改previous的值:
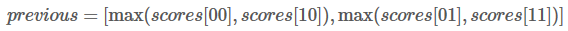
举个例子,如果我们的得分如下:
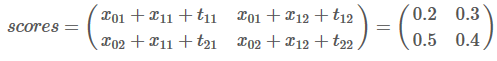
那么我们的previous应该是:
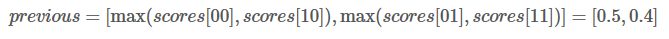
这是什么意思呢?其实也就是说previous存储的是当前单词对应各类别的最佳路径得分。W1被预测为L1类别的最高分是0.5,路径是L2->L1,W1被预测为L2类别的最高分是0.4,路径是L2->L2。
这边,我们有两个变量来储存历史信息,alpha0 和 alpha1.
在本次迭代中,我们将最佳分数存储到alpha0 :
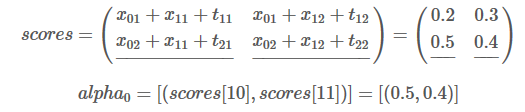
同时,最佳分数所对应的类别索引存储到alpha1:
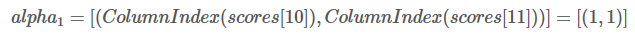
类别L1的索引是0,L2的索引是1,所以(1,1)=(L2,L2)。表示当前最佳分数0.5对应的路径是L2->L1,最佳分数0.4对应的路径是L2->L2。(1,1)可以理解为前一单词分别对应的类别索引。

上面scores有错误,应该是0.5+x21+t11 等
更改previous的值:
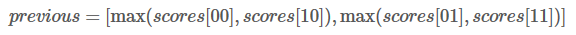
假如我们的得分是:
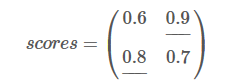
现在我们的previous是:
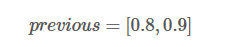
现在,我们选取previous[0] 和previous[1]中最大的分数作为最佳路径。也就是0.9对应的路径是我们的预测结果。
同时,每个类别对应的最大得分添加到alpha0 和 alpha1中:

Step 3:根据最大得分找到最佳路径
这是最后一步,alpha0 和 alpha1将被用来找到最佳路径。
先看alpha0,alpha0中最后一个单词对应的类别得分分别是0.8 和 0.9,那么0.9对应的类别L2就是最佳预测结果。再看alpha1,L2对应的索引是0, “0”表示之前一个单词对应的类别是L1,所以W1-W2的最佳路径是: L1->L2
接着往前推,alpha1=(1,1),我们已经知道W1的预测结果是L1,对应的索引是0,(1,1)[0] = 1,所以W0对应的类别是L2。
所以我们预测的最佳路径是 L2-> L1 -> L2 。
原始文章链接:
- https://createmomo.github.io/2017/09/12/CRF_Layer_on_the_Top_of_BiLSTM_1/
- https://createmomo.github.io/2017/09/23/CRF_Layer_on_the_Top_of_BiLSTM_2/
- https://createmomo.github.io/2017/10/08/CRF-Layer-on-the-Top-of-BiLSTM-3/
- https://createmomo.github.io/2017/10/17/CRF-Layer-on-the-Top-of-BiLSTM-4/
- https://createmomo.github.io/2017/11/11/CRF-Layer-on-the-Top-of-BiLSTM-5/
- https://createmomo.github.io/2017/11/24/CRF-Layer-on-the-Top-of-BiLSTM-6/

若有收获,就点个赞吧
0 人点赞
