什么是垃圾
class C:def __init__(self):self.data = [x for x in range(10000)]self.child = Nonedef func():a = C()b = C()a.child = b
func函数中申明了A的两个实例对象,并且变量a,b分别指向这两个对象,且a引用了b指向的对象。当func函数运行结束,在python解释器内部无任何地方引用这两个对象,因此a, b 指向的两个对象变成了垃圾。这些对象也就是所谓的内存垃圾,python解释器有一套垃圾回收机制,确保内存中无用对象及空间及时被清理。
内存泄露是什么?如何避免?
内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
有__del__()函数的对象间的循环引用是导致内存泄露的主凶。不使用一个对象时使用: del object 来删除一个对象的引用计数就可以有效防止内存泄露问题。
通过Python扩展模块gc 来查看不能回收的对象的详细信息。
可以通过 sys.getrefcount(obj) 来获取对象的引用计数,并根据返回值是否为0来判断是否内存泄露
Python 使用标记清除(mark-sweep)算法和分代收集(generational),来启用针对循环引用的自动垃圾回收。
先来看标记清除算法。我们先用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。显而易见,这些节点的存在是没有任何意义的,自然的,我们就需要对它们进行垃圾回收。
当然,每次都遍历全图,对于 Python 而言是一种巨大的性能浪费。所以,在 Python 的垃圾回收实现中,标记清除算法使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象才有可能产生循环引用)。
而分代收集算法,则是将 Python 中的所有对象分为三代。刚刚创立的对象是第 0 代;经过一次垃圾回收后,依然存在的对象,便会依次从上一代挪到下一代。而每一代启动自动垃圾回收的阈值,则是可以单独指定的。当垃圾回收器中新增对象减去删除对象达到相应的阈值时,就会对这一代对象启动垃圾回收。
事实上,分代收集基于的思想是,新生的对象更有可能被垃圾回收,而存活更久的对象也有更高的概率继续存活。因此,通过这种做法,可以节约不少计算量,从而提高 Python 的性能。
1 引用计数
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少.引用计数为0时,该对象生命就结束了。
优点:
- 简单
- 实时性
缺点:
- 维护引用计数消耗资源
- 循环引用
2 标记-清除机制
基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放。
3 分代技术
分代回收的整体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长。
举例:当某些内存块M经过了3次垃圾收集的清洗之后还存活时,我们就将内存块M划到一个集合A中去,而新分配的内存都划分到集合B中去。当垃圾收集开始工作时,大多数情况都只对集合B进行垃圾回收,而对集合A进行垃圾回收要隔相当长一段时间后才进行,这就使得垃圾收集机制需要处理的内存少了,效率自然就提高了。在这个过程中,集合B中的某些内存块由于存活时间长而会被转移到集合A中,当然,集合A中实际上也存在一些垃圾,这些垃圾的回收会因为这种分代的机制而被延迟。
'''cpython 中的垃圾回收机制 算法采用 引用计数 reference counting'''# a = 1 # 此时a的计数器+1# b = a # 此时a的计数器继续+1 =2# del a # 此时a的计数器 -1 = 1 等于0的时候回收a = object()b =adel aprint(b) # <object object at 0x7ff1ef5930c0>print(a) # NameError: name 'a' is not defined
import sysa = []# 两次引用,一次来自 a,一次来自 getrefcountprint(sys.getrefcount(a))def func(a):# 四次引用,a,python 的函数调用栈,函数参数,和 getrefcountprint(sys.getrefcount(a))func(a)# 两次引用,一次来自 a,一次来自 getrefcount,函数 func 调用已经不存在print(sys.getrefcount(a))242
如果想手动释放内存,应该怎么做呢?方法同样很简单,只需要先调用 del a 来删除一个对象,然后强制调用 gc.collect() 即可手动启动垃圾回收。例如:
import gcshow_memory_info('initial')a = [i for i in range(10000000)]show_memory_info('after a created')del agc.collect()show_memory_info('finish')print(a)输出结果为:initial memory used: 48.1015625 MBafter a created memory used: 434.3828125 MBfinish memory used: 48.33203125 MBNameError Traceback (most recent call last)<ipython-input-12-153e15063d8a> in <module>1112 show_memory_info('finish')---> 13 print(a)NameError: name 'a' is not defined
垃圾回收机制剖析
1 白话垃圾回收
1.1 refchain
在python的源码中有一个名为 refchain 的 环状双向链表 。python程序中一旦创建对象都会把这个对象添加到refchain这个链表中,也就是说他保存着所有的对象。
age,name = 18,'ck`

1.2 引用计数器
在refchain中的所有对象内部都有一个 ob_refcnt 来保存当前对象的引用计数器,顾名思义就是自己被引用的次数。
age,name = 18,'ck'nikcname = name
上述代码表示内存中有18和’ck’两个值,他们的引用计数器分别是:1,2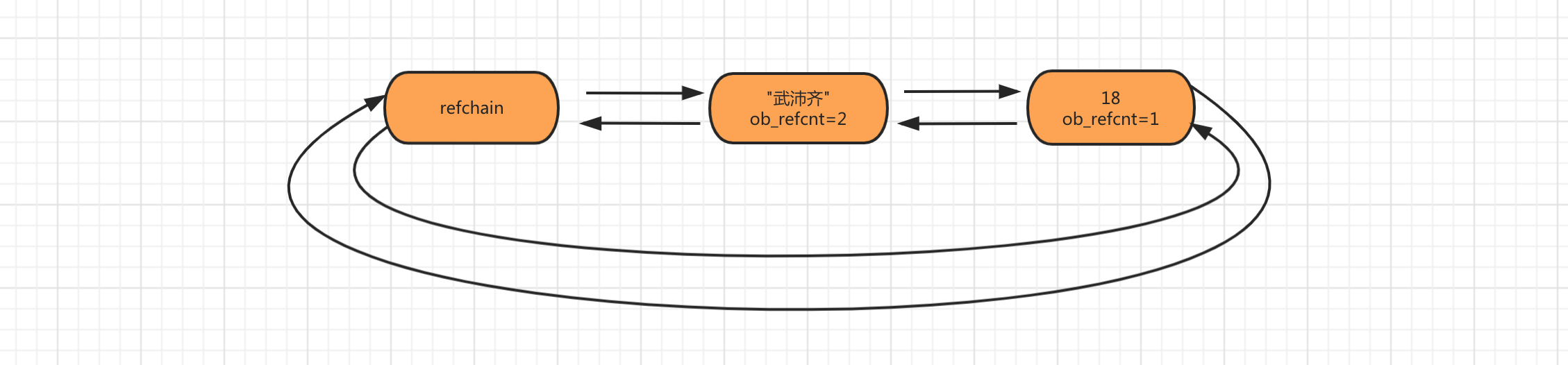
当值被多次引用时候,不会在内存中重复创建数据,而是引用计数器+1 。 当对象被销毁时候同时会让引用计数器-1,如果引用计数器为0,则将对象从refchain链表中摘除,同时在内存中进行销毁(暂不考虑缓存等特殊情况)。
age = 18number = age # 对象18的引用计数器 + 1del age # 对象18的引用计数器 - 1def run(arg):print(arg)# 刚开始执行函数时,对象18引用计数器 + 1,# 当函数执行完毕之后,对象18引用计数器 - 1 。run(number)num_list = [11, 22, number] # 对象18的引用计数器 + 1
1.3 标记清除 & 分代回收
基于引用计数器进行垃圾回收非常方便和简单,但是他还存在 循环引用 的问题,导致无法正常的回收一些数据,
例如:
v1 = [11,22,33] # refchain中创建了一个列表对象,由于v1=对象,所以列表对象引用计数器为1v2 = [44,55,66] # refchain中再创建一个列表对象,因为v2=对象,所以列表对象引用计数器为1v1.append(v2) # v2追加到v1中,则v2对应的[44,55,66]对象的引用计数器+1=2v2.append(v1) # v1追加到v2中,则v1对应的[11,22,33]对象的引用计数器+1=2del v1 # 计数器-1del v2 # 计数器-1
对于上述代码会发现,执行del操作之后,没有变量再会去使用那两个列表对象,但由于循环引用的问题,他们的引用计数器不为0,所以他们的状态:永远不会被使用、也不会被销毁。项目中如果这种代码太多,就会导致内存一直被消耗,直到内存被耗尽,程序崩溃。
为了解决循环引用的问题,引入了标记清除技术,专门针对那些可能存在循环引用的对象进行特殊处理,可能存在循环应用的类型有:列表、元组、字典、集合、自定义类等那些能进行数据嵌套的类型。
标记清除:
创建特殊链表专门用于保存列表、元组、字典、集合、自定义类对象,之后再去检查这个链表中的对象是否存在循环引用。如果存在则让双方的引用计数器都-1
分代回收
对标记清除中的链表进行优化,将那些可能存在循环引用的对象拆分到3个链表,链表称为0/1/2三代,每代都可以存储对象和阈值,当达到阈值时,就会对相对应的链表中的每一个对象做一次扫描,清除循环引用各自减1并且销毁引用计数器为0的对象。
// 分代的C源码#define NUM_GENERATIONS 3struct gc_generation generations[NUM_GENERATIONS] = {/* PyGC_Head, threshold, count */{{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代{{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代{{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代};
特别注意:0代和1、2代的threshold和count表示的意义不同。
- 0代,count表示0代链表中对象的数量,threshold表示0代链表对象个数阈值,超过则执行一次0代扫描检查。
- 1代,count表示1代链表扫描的次数,threshold表示1代链表扫描的次数阈值,超过则执行一次1代扫描检查。
2代,count表示2代链表扫描的次数,threshold表示2代链表扫描的次数阈值,超过则执行一2代扫描检查。
1.4 情景模拟
根据C语言底层并结合图来讲解内存管理和垃圾回收的详细过程。
第一步:当创建对象age=19时,会将对象添加到refchain链表中。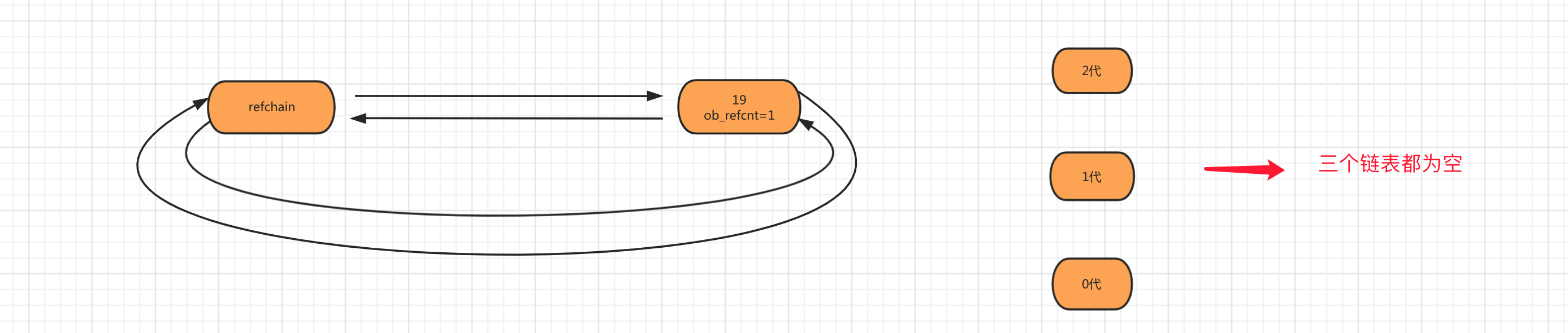
第二步:当创建对象num_list = [11,22]时,会将列表对象添加到 refchain 和 generations 0代中。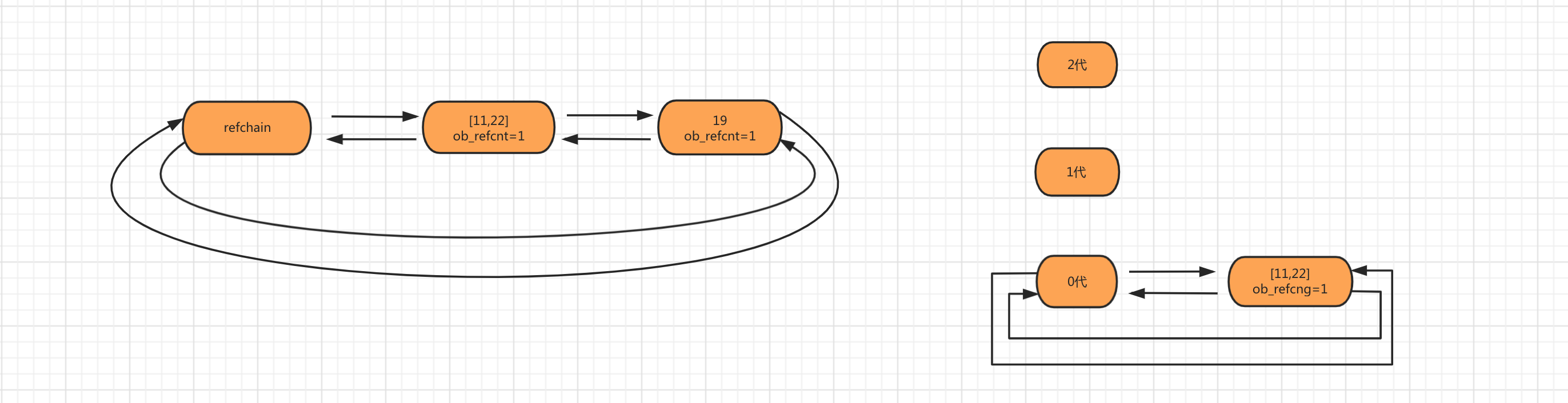
第三步:新创建对象使generations的0代链表上的对象数量大于阈值700时,要对链表上的对象进行扫描检查。
当0代大于阈值后,底层不是直接扫描0代,而是先判断2、1是否也超过了阈值。如果2、1代未达到阈值,则扫描0代,并让1代的 count + 1 。
- 如果2代已达到阈值,则将2、1、0三个链表拼接起来进行全扫描,并将2、1、0代的count重置为0.
- 如果1代已达到阈值,则讲1、0两个链表拼接起来进行扫描,并将所有1、0代的count重置为0.
对拼接起来的链表在进行扫描时,主要就是剔除循环引用和销毁垃圾,详细过程为:
- 扫描链表,把每个对象的引用计数器拷贝一份并保存到
gc_refs中,保护原引用计数器。- 再次扫描链表中的每个对象,并检查是否存在循环引用,如果存在则让各自的
gc_refs减 1 。- 再次扫描链表,将
gc_refs为 0 的对象移动到unreachable链表中;不为0的对象直接升级到下一代链表中。- 处理
unreachable链表中的对象的 析构函数 和 弱引用,不能被销毁的对象升级到下一代链表,能销毁的保留在此链表。
- 析构函数,指的就是那些定义了
__del__方法的对象,需要执行之后再进行销毁处理。- 弱引用,
- 最后将
unreachable中的每个对象销毁并在refchain链表中移除(不考虑缓存机制)。至此,垃圾回收的过程结束。
1.5 缓存机制
因为反复的创建和销毁会使程序的执行效率变低。Python中引入了“缓存机制”机制。
例如:引用计数器为0时,不会真正销毁对象,而是将他放到一个名为 free_list 的链表中,之后会在创建对象时不会再冲重新开辟内存,而是在 free_list 中将之前的对象来重置内部的值来使用。
- float类型,维护的 free_list 链表最多可缓存100个float对象
v1 = 3.14 # 开辟内存来存储float对象,并将对象添加到refchain链表print(id(v1)) # 内存地址:del v1 # 引用计数器-1,如果为0则在rechain链表中移除,不销毁对象,而是将对象添加到float的free_list.v2 = 9.999 # 优先去free_list中获取对象,并重置为9.999,如果free_list为空才重新开辟内存。print(id(v2))
# 注意:引用计数器为0时,会先判断free_list中缓存个数是否满了,未满则将对象缓存,已满则直接将对象销毁。
-str类型,维护 unicode_latin1[256] 链表,内部将所有的 ascii 字符缓存起来,以后使用时可以不需要反复创建

若有收获,就点个赞吧
0 人点赞
