- 数据结构 树的遍历哪几种
- 数据结构 树的前序
- 数据结构 会图的算法吗 (直接说的不会)
- 数据库 连接种类:平时怎么用的连接
- 数据库 查询 优化
单表优化
1 表分区
2 增加缓存
3 字段设计:
- 单表不要有太多字段;
- varchar的长度尽量只分配真正需要的空间;
- 尽量使用timestamp而非datetime;
- 避免使用NULL,可以通过设置默认值解决;
4 索引优化
- 索引不是越多越好,针对性地简历索引,索引会加速查询,但对新增、修改、删除会造成一定影响;
- 值域很少的字段不适合键索引;
- 尽量不用UNIQUE,不要设置外键,由程序保障;
表拆分
1 垂直拆分
把一个字段较多的表,拆分成多个字段较少的表
2 水平拆分
分表分库
- 数据库 自己的数据库查询遇到哪些问题
- 数据库 忘了
- 网络 7层、4层网络模型的每层的常用协议
| OSI中的层 | 功能 | TCP/IP协议族 |
|---|---|---|
| 应用层 | 文件传输,电子邮件,文件服务,虚拟终端 | TFTP,HTTP,SNMP,FTP,SMTP,DNS,Telnet |
| 表示层 | 数据格式化,代码转换,数据加密 | 没有协议 |
| 会话层 | 解除或建立与别的接点的联系 | 没有协议 |
| 传输层 | 提供端对端的接口 | TCP,UDP |
| 网络层 | 为数据包选择路由 | IP,ICMP,RIP,OSPF,BGP,IGMP |
| 数据链路层 | 传输有地址的帧以及错误检测功能 | SLIP,CSLIP,PPP,ARP,RARP,MTU |
| 物理层 | 以二进制数据形式在物理媒体上传输数据 | ISO2110,IEEE802。IEEE802.2 |
| TCP/IP | |
|---|---|
| 应用层 | FTP 文件传送协议、Telnet 远程登录协议、 DNS 域名解析协议、 SMTP 邮件传送协议、 POP3 邮局协议、 HTTP协议 |
| 传输层 | TCP、UDP 、 UGP |
| 网络层 | IP ICMP网际控制报文协议 IGMP |
| 数据链路层 | ARP 地址解析协议 RARP逆地址解析 |
- 网络 路由查找过程(我回答成通过路由如何找到目标iP地址了)
路由寻址:在路由器中,由一个接口接受到的数据包,根据数据包所携带的目的地址,定向传输到另一个接口的过程
RIP协议:底层是贝尔曼福特算法,它选择路由的度量标准(metric)是跳数,最大跳数是15跳,如果大于15跳,它就会丢弃数据包。
OSPF协议:底层是迪杰斯特拉算法,是链路状态路由选择协议,它选择路由的度量标准是带宽,延迟。
- 网络 TCP/UDP区别
- UDP头部长度和最大长度
UDP:可发送的数据最大长度为 IP 包的最大长度减去 IP 头部和 UDP 头部的长度。不过,这个长度与 MTU、MSS 不是一个层面上的概念。MTU 和MSS 是基于以太网和通信线路上网络包的最大长度来计算的,而 IP 包的最大长度是由 IP 头部中的“全长”字段决定的。“全长”字段的长度为 16比特,因此从 IP 协议规范来看,IP 包的最大长度为 65 535 字节,再减去IP 头部和 UDP 头部的长度,就是 UDP 协议所能发送的数据最大长度。如果不考虑可选字段的话,一般来说 IP 头部为 20 字节,UDP 头部为 8 字节,因此 UDP 的最大数据长度为 65507 字节。当然,这么长的数据已经超过了以太网和通信线路的最大传输长度,因此需要让 IP 模块使用分片功能拆分之后再传输。分片有时候会带来组包错误,因此UDP的包长度不要超过MTU值,一般不建议超过1K
最大传输单元(MTU)是代表连接互联网的设备可以接受的最大数据包的度量单位
结论:数据包最大荷载是由网络设备的MTU决定的
- 网络 忘了还有个啥
- Linux 常用的查询指令
find
whereis
findwhereisls |grep <file_name> 可以模糊查找| grep管道
管道 输入|输出
管道一般用于 过滤, 特殊,扩展处理,不能单独使用 起辅助作用
ls ./ |grep xxx 过滤:需要通过管道查询出包含xxx的文件
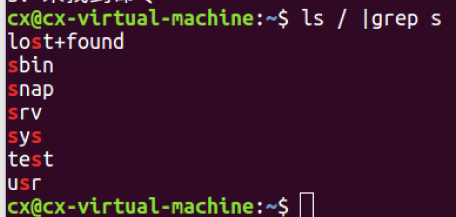
使用管道组合指令
ls / -l | wc -l 查询当前目录下的文件,list输出 | 统计行数
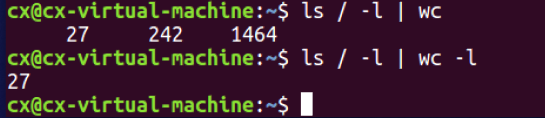
whereis <name>查看文件地址
- Linux Vim的使用 Vim
- Python OOP的三个特性
- Python 类的方法解析顺序算法
- Python 装饰器
- 反问
- 你们的技术栈和目前做啥(就回了两个技术的名字,听都听不懂。。。)
- 后面流程

若有收获,就点个赞吧
0 人点赞
