什么是时间序列
时间序列,就是按照时间先后进行排序的一组数据。
时间序列分为两部分:
 都是一个随机变量。
都是一个随机变量。
- n: 随机变量的个数(时间点的个数)。
 : 按时间先后排列的n个时刻。
: 按时间先后排列的n个时刻。 : 在
: 在 时刻对应的随机变量。
时刻对应的随机变量。 : 自然数集。
: 自然数集。
如果我们按照时间顺序将随机变量进行排列,则时间序列可以表示为: 或者简单表示为
或者简单表示为
 : 所有的时刻。
: 所有的时刻。- 而每个随机变量的观测值表示:

我们对这组有序的数据进行观察,研究并发现其发展变化的规律,预测其将来的走势,就是时间序列分析。我们要研究时间序列 ,实际就是要分析观测值序列
,实际就是要分析观测值序列 的性质,进而来推断
的性质,进而来推断 的性质。
的性质。
分布函数定义
对于时间序列 ,其联合分布函数定义如下:
,其联合分布函数定义如下:
- n: 随机变量的个数(随机向量的维度)。
 : 任意n时刻。
: 任意n时刻。 : n个随机变量。
: n个随机变量。 :任意n个实数。
:任意n个实数。
当n为1时,一维分布函数为:
当n为2时,二维分布函数为:
而这些有限维分布函数构成的全体
就称为时间序列 的概率分布族。
的概率分布族。
分布函数的意义与局限
意义
我们要研究时间序列,首先要清楚时间序列的分布函数,以为分布函数能够完全决定随机变量的统计特征。例如正态分布,二项分布等。因此,如果我们能够确定时间序列的分布函数,则时间变量中各个随机变量的统计特征,自然也就能够确定了。
局限
尽管分布函数对时间序列来说时非常重要的,然而,要确定序列的分布时非常困难的,这需要涉及非常复杂的数学运算,因此,分布函数对于时间序列来说,往往只具有理论意义。故我们改用计算时间序列的特征统计量(低阶矩),来研究时间序列的性质。
特征统计量
均值
给定时间序列 ,任意t时刻的随机变量为
,任意t时刻的随机变量为 ,其分布函数为
,其分布函数为 ,如果:
,如果:
则随机变量 的均值存在,称
的均值存在,称 为序列
为序列 在t时刻的均值函数.
在t时刻的均值函数.
方差
如果
则随机变量 的方差存在,称
的方差存在,称 为序列
为序列 在t时刻的方差函数.
在t时刻的方差函数.
根据数学期望定理:
因此可以得出:
自协方差
 ,自协方差函数为:
,自协方差函数为:
自相关系数
给定任意的 ,自相关系数函数为:
,自相关系数函数为:
从自协方差(自相关系数)的定义可知,自协方差(自相关系数)与协方差(自相关系数)的概念是一样的,只不过,协方差与相关系数描述的是两个事件的关系,而自协方差与自相关系数描述的是同一个事件在两个不同时刻的关系.形象的说,就是度量自己过去的行为对自己现在的影响.
时间序列类别
根据时间序列的稳定性,我们可以将时间序列进行如下分类:
- 平稳时间序列
- 严平稳时间序列
- m阶平稳时间序列
- 宽平稳时间序列
-
严平稳时间序列
给定时间序列
 如果有:
如果有:
则时间序列 为严平稳时间序列.
为严平稳时间序列. n: 随机变量的个数.
 : 任意选择的n个时刻.
: 任意选择的n个时刻. : 时间间隔(偏移量).
: 时间间隔(偏移量).- N: 自然数集.
- Z:整数集.
从定义可以看出,严平稳时间序列的分布函数不会随着时间的推移而发生变化.另外,随机变量的统计性质是由其分布函数(或概率密度函数)决定的,因此,也可以说,严平稳时间序列所有的统计性质(均值,方差等)都不会随着时间的推移而发生变化.
m阶平稳时间序列
给定时间序列 如果有:
如果有:
则时间序列 为m阶平稳时间序列.
为m阶平稳时间序列.
由定义可知,严平稳时间序列与m阶平稳时间序列的区别仅在于随机变量个数的上限不同,当 时,m阶平稳时间序列就是严平稳时间序列.
时,m阶平稳时间序列就是严平稳时间序列.
宽平稳时间序列
宽平稳,也叫弱平稳或二阶平稳,是m阶平稳的一种特例(m=2).如果时间序列 满足:
满足:
- 任意时刻的均值为常数


- 任意时刻的方差有界,即方差存在.

- 自协方差与自相关系数仅与时间间隔有关,而与时间起止点无关.即只要时间间隔相同,自协方差就相同.
 或者,我们也可以表示为:
或者,我们也可以表示为:
则时间序列 为宽平稳时间序列.
为宽平稳时间序列.
因为宽平稳序列的自协方差与自相关系数仅与时间间隔 有关,我们可以定义延迟
有关,我们可以定义延迟 期自协方差(自相关系数)为:
期自协方差(自相关系数)为:

平稳时间序列的意义
直观意义
如果时间序列是平稳的,则具有如下的特性:
- 任意时刻的均值为常数
- 任意时刻的方差为常数
- 自协方差与自相关系数仅与时间间隔有关,而与时间的起止无关.
由平稳时间序列的特征可知,只有平稳时间序列,才具有稳定的统计量,我们才能根据现在的行为,去预测未来的发展走势(未来与现在具有相同的行为).因此,只有平稳时间序列,我们才更容易通过建模来实现预测.
统计意义
在常规的结构化数据中,我们很容易计算每个随机变量的统计量(均值,方差等),或者根据现有的样本数据去训练模型,样本的数量越多,往往效果越好.
然而,对于时间序列来说,情况却不容乐观.由于时间序列的不可重复性,我们在某一时刻,永远都只能取一个观测值,也就是说,对于时间序列,我们只有一个样本.
一个随机变量,只能去一个观测值,这对估计随机变量的统计量带来了极大的难度,但是,如果是平稳时间序列,难度就大大降低.因为在平稳时间序列中,均值,方差为常数,自协方差与自相关系数只与时间间隔 相关,这就为我们计算带来了很大的便利.
相关,这就为我们计算带来了很大的便利.
统计量计算
均值
对于平稳时间序列,均值不随时间的推移而发生改变

-
方差
自协方差
自协方差的计算公式为:

对于平稳时间序列,自协方差只与延迟的期数 有关,而与时间起止点无关.令
有关,而与时间起止点无关.令 (时间间隔)有
(时间间隔)有

很明显,当 时,自协方差就是方差.
时,自协方差就是方差.
自相关系数

对于平稳时间序列,自相关系数只与延迟的期数 有关,而与时间起止点无关.令
有关,而与时间起止点无关.令 (时间间隔),有:
(时间间隔),有:

平稳检测
绘制时间序列图像
ADF检验
ADF(Aufmented Disckey Fuller)检验,通过统计学中的假设检验的方式,来检验序列
 是否为平稳时间序列,该检验的原假设与备则假设如下:
是否为平稳时间序列,该检验的原假设与备则假设如下:
原假设: 为非平稳序列.
为非平稳序列.
备则假设: 为平稳序列.
为平稳序列.
statsmodels模块下的ADF检验from statsmodels.tsa.stattools import adfulleradfuller(df3['level'].values)
返回数据
(-6.183507098531215,6.370732786043653e-08,16,653,{'1%': -3.4404038931945276,'5%': -2.865976260062519,'10%': -2.5691324834372633},6961.083391558053)
返回元组的第一个值是P值,值越大,说明序列非平稳的概率越大.
pmdarima模块下的ADF检验import pmdarima as pmadf = pm.arima.ADFTest()adf.should_diff(df3['level'].values)
返回值
(0.01, False)
是否需要差分运算,True表示需要差分,即序列为非平稳,False表示不需要差分,即序列平稳.
KPSS检验
KPSS(Kwiatkowski-Phillips-Schmidt-Shin)检验,该检验的原假设与备择假设如下:
原假设: 为平稳序列.
为平稳序列.
备择假设: 为非平稳序列.
为非平稳序列.
说明: KPSS设定的原假设与备择假设与ADF检验是相反的.
- KPSS返回的P范围为[0.01, 1],如果真实的P值不在该范围,会返回临界值
- pmdarima与statsmodels都提供该检验的功能.
kpss = pm.arima.KPSSTest()kpss.should_diff(df3['level'].values)# 返回值与ADFTest返回值类似#(0.1, False)
PP检验
PP(Phillips-Perron)检验,该检验的原假设与备择假设如下:
原假设: 为非平稳序列
为非平稳序列
备择假设: 为平稳序列
为平稳序列pp = pm.arima.PPTest()kpss.should_diff(df3['level'].values)
周期性检验-CH检验
CH(Canova-Hansen)检验,用来检验序列是否具有周期性.CH检验适用于周期较长(周期含有观测值较多,通常超过20),并且整个序列中,包含周期次数较少的情况(通常不超过3个周期).# 观测量m = 688# 创建CHTest检验对象,检验周期为mch = pm.arima.CHTest(m)# 评估序列是否具有指定的周期性.# 返回0表示,无周期性,返回1或更大表示具有周期性(周期差分)ch.estimate_seasonal_differencing_term(df3['level'].values)
周期性检验-OCSB检验
OCSB(Osorn, Chui, Smith, Birchenhall)检验,用来检验序列是否具有周期性.相对于CH检验,该检验的实用性更强,应用更广泛些.ocsb = pm.arima.OCSBTest(m)ocsb.estimate_seasonal_differencing_term(df3['level'].values)
纯随机序列
如果一个序列的序列之间没用任何相关性,我们就称这种序列为纯随机序列。给定时间序列 ,如果序列满足如下性质:
,如果序列满足如下性质:


- 均值为常数

 。
。
- 方差为常数
 ,且任意两个同时时刻,协方差为0。
,且任意两个同时时刻,协方差为0。


则改序列为纯随机序列,特别的,如果一个纯随机序列的均值为0,则称为白噪声序列。
纯随机序列的意义
- 在时间序列分析之前,验证时间序列是否为纯随机序列。
- 如果是纯随机序列,则表示序列没用任何分析价值,可以提前停止。
- 在建模拟合之后,模型残差序列应该是均值为0的纯随机序列(白噪声序列)。
- 如果残差序列不是白噪声序列,意味着序列中有某些信息没有提取,拟合不充分。
能做时间序列模型的条件是数据具有平稳性
平稳性就是要求经由样本时间序列所得到的拟合曲线在未来一段时间内仍能顺着现有的形态惯性地延续下去。
平稳性要求序列的均值、方差和协方差不发生明显变化,通常从三个方面分析:
均值不应该是关于时间t的函数,而应该是一个常数。
方差不应该是时间的函数,即方差需要有:同方差性。
当序列不平稳时可以通过差分使时间序列变平稳AR
描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测。
yt是当前值 u是常数项 P是阶数 ri是自相关系数 et是误差。
自回归模型的限制
- 自回归模型是用自身的数据进行预测
- 必须具有平稳性
- 必须具有相关性,如果自相关系数(φi)小于0.5,则不宜采用
- 自回归只适用于预测与自身前期相关的现象
MA
移动平均模型关注的是自回归模型中的误差项的累加
移动平均法能有效地消除预测中的随机波动ARMA
ARMA是自回归模型和移动平均模型的结合差分
所谓差分,就是使用当前序列 的每个观测值
的每个观测值 与之前的观测值
与之前的观测值 进行差值运算,从而会获取一个新的序列。
进行差值运算,从而会获取一个新的序列。
对观测值 进行一次求差而获取新的序列
进行一次求差而获取新的序列 ,称为一阶差分。
,称为一阶差分。
在一阶差分
 的基础上,再进行一次差分而得到序列
的基础上,再进行一次差分而得到序列 ,称二阶差分。
,称二阶差分。
以此类推,我们可以进行n阶差分,从而获取序列

注意: 差分并非不是越多越好,通常情况下,二阶差分就能够有效的提取序列中的信息。差分的作用与意义
差分的作用是非常重要的,在非平稳时间序列上,我们可以通过差分运算有效提取序列中的趋势效应或季节效应,从而讲非平稳序列转换成平稳序列。ARIMA
I是差分模型,ARIMA是经过差分后的ARMA模型,保证了数据的稳定性。ARIMA模型参数
ARIMA模型含有三个参数:p,d,q。
p—代表预测模型中采用的时序数据本身的滞后数(lags) ,也叫做AR/Auto-Regressive项。
d—代表时序数据需要进行几阶差分化,才是稳定的,也叫Integrated项。
q—代表预测模型中采用的预测误差的滞后数(lags),也叫做MA/Moving Average项。参数p、q的确认

截尾是指从某个开始非常小(不显著非零)。实战—-模拟随时间变化北海潮汐数据的变化
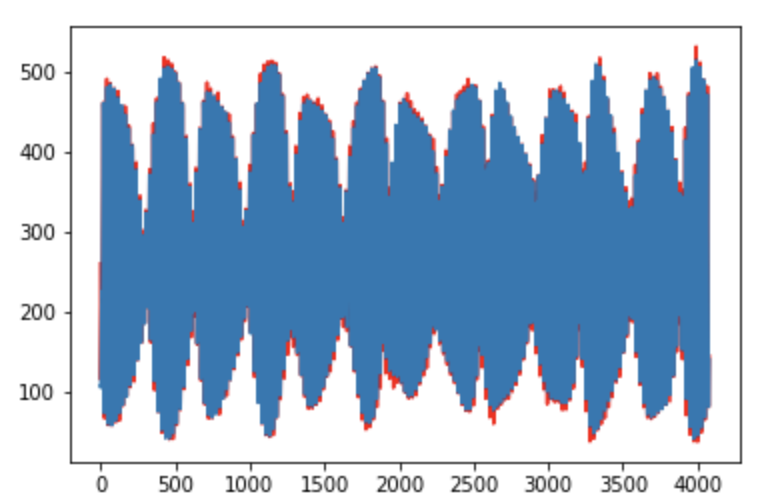
import pandas as pdimport numpy as npfrom matplotlib import pyplot as pltfrom statsmodels.tsa.arima_model import ARIMA, ARMAfrom statsmodels.graphics.tsaplots import plot_acf,plot_pacffrom statsmodels import api as smfrom statsmodels.graphics.api import qqplotdf1 = pd.read_csv('../../../test_data/test_data.csv')# 将字符串时间改成时间序列df1['time'] = pd.to_datetime(df1['time'])# 将时间设置成索引df2 = df1.set_index(keys='time')# 时间重采样 1Hdf3 = df2.resample("1H").mean()# 需不需要做差分结合数据来看# stock_train = df3.diff()# 不需要做差分stock_train = df3stock_train.plot(figsize=(12,8))plt.legend(bbox_to_anchor=(1.25,0.5))plt.title('Stock Close')# ACFacf = plot_acf(stock_train,lags=20)plt.title("ACF")acf.show()

pacf = plot_pacf(stock_train,lags=20)plt.title("PACF")pacf.show()

# 确定模型model = ARMA(df3,order=(3, 5),freq='1H')result = model.fit()# 预测res = result.predict(start='2019-07-02 23:00:00', end='2019-12-03 23:00:00',dynamic=False)# 拟合情况plt.plot([i for i in range(len(res))], res, color='r')plt.plot([i for i in range(len(stock_train.values))], stock_train.values)


若有收获,就点个赞吧
0 人点赞
